Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
Verileri temizlemek için işlevsel bağımlılıkları kullanın. Anlam modelindeki bir sütun (Power BI veri kümesi) başka bir sütuna bağımlı olduğunda işlevsel bağımlılık vardır. Örneğin, bir ZIP code sütun bir sütundaki city değeri belirleyebilir. İşlevsel bağımlılık, bir DataFrame içinde iki veya daha fazla sütunun değerleri arasında bire-çok ilişki olarak ortaya çıkar. Bu öğreticide, işlevsel bağımlılıkların veri kalitesi sorunlarını algılamaya nasıl yardımcı olduğunu göstermek için Synthea veri kümesi kullanılır.
Bu öğreticide şunların nasıl yapılacağını öğreneceksiniz:
- Anlamsal modelde işlevsel bağımlılıklar hakkında hipotezler oluşturmak için etki alanı bilgilerini uygulayın.
- Semantic Link Python kitaplığının (SemPy) veri kalitesi analizini otomatik hale getiren bileşenleri hakkında bilgi edinin. Bu bileşenler şunlardır:
-
FabricDataFrame— ek semantik bilgiler içeren pandas benzeri bir yapı. - İşlevsel bağımlılıklar hakkındaki hipotezleri değerlendirmeyi otomatik hale getiren ve anlamsal modellerinizdeki ihlalleri tanımlayan işlevler.
-
Önkoşullar
Microsoft Fabric aboneliği alın. Alternatif olarak, ücretsiz bir Microsoft Fabric deneme sürümüiçin kaydolun.
Giriş sayfanızın sol alt köşesindeki deneyim değiştiriciyi kullanarak Fabric'e geçin.

- Gezinti bölmesinde Çalışma Alanları'nı ve ardından çalışma alanınızı seçerek geçerli çalışma alanı olarak ayarlayın.
Not defterinde birlikte izleyin
Bu öğreticiyi izlemek için data_cleaning_functional_dependencies_tutorial.ipynb not defterini kullanın.
Bu öğreticiye eşlik eden not defterini açmak için, sisteminizi veri bilimi öğreticilerine hazırlama başlığındaki yönergeleri izleyerek not defterini çalışma alanınıza içeri aktarın.
Bu sayfadaki kodu kopyalayıp yapıştırmayı tercih ederseniz, yeni bir not defteri oluşturabilirsiniz.
Kod çalıştırmaya başlamadan önce not defterine bir göl evi eklediğinizden emin olun.
Dizüstü bilgisayarı kur
Bu bölümde, bir not defteri ortamı ayarlarsınız.
Spark sürümünüzü denetleyin. Microsoft Fabric'te Spark 3.4 veya üzerini kullanıyorsanız, Anlam Bağlantısı varsayılan olarak eklenir, bu nedenle yüklemeniz gerekmez. Spark 3.3 veya önceki bir sürümünü kullanıyorsanız veya en son Anlam Bağlantısına güncelleştirmek istiyorsanız aşağıdaki komutu çalıştırın.
%pip install -U semantic-linkBu not defterinde kullandığınız modülleri içeri aktarın.
import pandas as pd import sempy.fabric as fabric from sempy.fabric import FabricDataFrame from sempy.dependencies import plot_dependency_metadataÖrnek verileri indirin. Bu öğreticide sentetik tıbbi kayıtların Synthea veri kümesini kullanın (basitlik için küçük sürüm).
download_synthea(which='small')
Verileri keşfetme
'ı, providers.csv dosyasının içeriğiyle başlatın.providers = FabricDataFrame(pd.read_csv("synthea/csv/providers.csv")) providers.head()Otomatik algılanan işlevsel bağımlılıkların grafiğini çizerek SemPy'nin
find_dependenciesişleviyle ilgili veri kalitesi sorunlarını denetleyin.deps = providers.find_dependencies() plot_dependency_metadata(deps)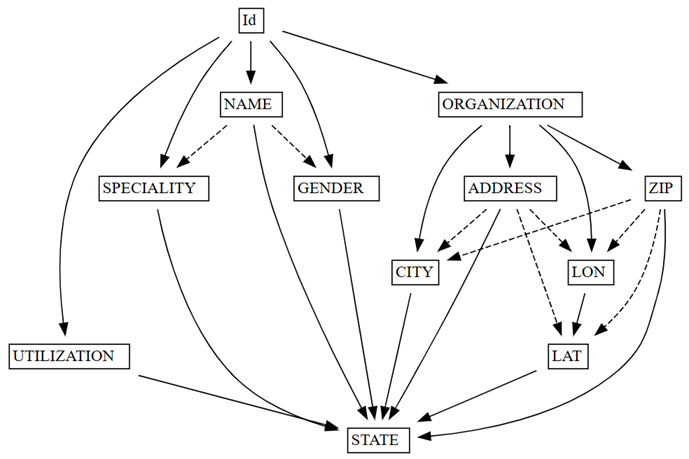
Graf,
Id'ünNAMEveORGANIZATION'yi belirlediğini gösterir. Benzersiz olduğundan bu sonuç beklenirId.Onaylayın ki
Idbenzersizdir.providers.Id.is_uniqueKod,
Truebenzersiz olduğunu onaylamak içinIddöndürür.

İşlevsel bağımlılıkları derinlemesine analiz etme
İşlevsel bağımlılıklar grafiği, beklendiği gibi ORGANIZATION'ın ADDRESS ve ZIP'yi belirlediğini gösterir. Ancak, ZIPCITYde belirlemesini bekleyebilirsiniz, ancak kesikli ok bağımlılığın yalnızca yaklaşık olduğunu ve veri kalitesi sorununa işaret ettiğini gösterir.
Grafikte başka özellikler de vardır. Örneğin, NAMEGENDER, Id, SPECIALITYveya ORGANIZATIONbelirlemez. Bu özelliklerin her biri araştırılmaya değer olabilir.
-
ZIPveCITYarasındaki yaklaşık ilişkiye daha derinlemesine bakış atın ve ihlalleri listelemek için SemPy'ninlist_dependency_violationsişlevini kullanın.
providers.list_dependency_violations('ZIP', 'CITY')
- SemPy'nin
plot_dependency_violationsgörselleştirme işleviyle bir grafik çizin. İhlal sayısı azsa bu grafik yararlıdır:
providers.plot_dependency_violations('ZIP', 'CITY')
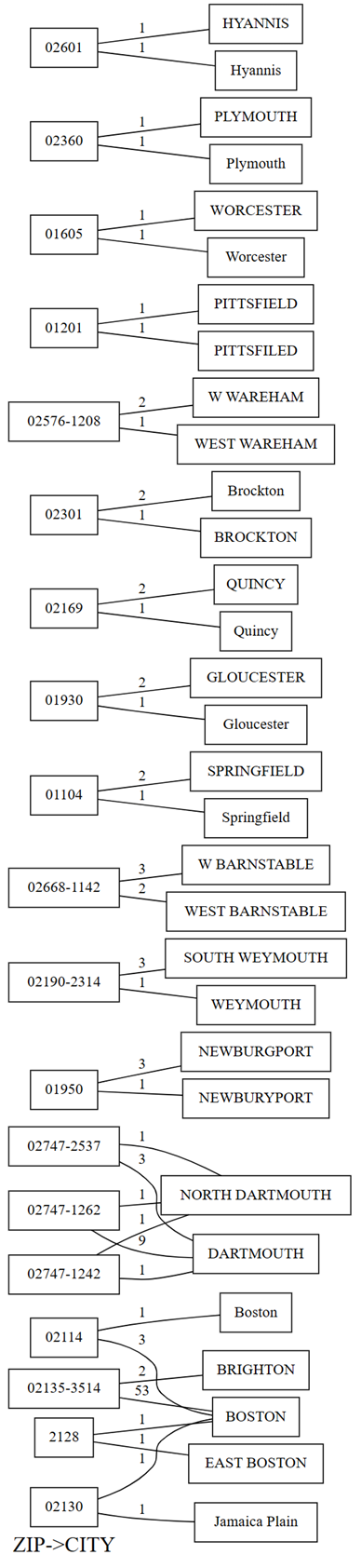
Bağımlılık ihlallerinin çizimi, sol taraftaki için değerleri ZIP ve sağ taraftaki için değerleri CITY gösterir. Kenar, çizimin sol tarafındaki bir posta kodunu, bu iki değeri içeren bir satır varsa, sağ taraftaki bir şehirle bağlar. Kenarlara bu tür satırların sayısıyla ek açıklama eklenir. Örneğin, önceki çizimde ve aşağıdaki kodda gösterildiği gibi 02747-1242 posta koduna sahip iki satır, biri "NORTH DARTHMOUTH" şehirli ve diğeri "DARTHMOUTH" şehirli iki satır vardır:
- Aşağıdaki kodu çalıştırarak çizimden gözlemleri onaylayın:
providers[providers.ZIP == '02747-1242'].CITY.value_counts()
Grafik,
CITY"DARTHMOUTH" olan satırlar arasında, dokuz satırınZIP02747-1262 olduğunu da gösteriyor. Bir satırda 02747-1242 numarasına sahip birZIPvardır. Bir satırdaZIPnumarası 02747-2537 olan bir değer bulunmaktadır. Aşağıdaki kodla bu gözlemleri onaylayın:providers[providers.CITY == 'DARTHMOUTH'].ZIP.value_counts()"DARTMOUTH" ile ilişkili başka posta kodları da vardır, ancak bu posta kodları veri kalitesi sorunlarına işaret etmedikleri için bağımlılık ihlalleri grafiğinde gösterilmez. Örneğin, "02747-4302" posta kodu benzersiz olarak "DARTMOUTH" ile ilişkilendirilir ve bağımlılık ihlalleri grafiğinde gösterilmez. Aşağıdaki kodu çalıştırarak onaylayın:
providers[providers.ZIP == '02747-4302'].CITY.value_counts()
SemPy ile algılanan veri kalitesi sorunlarını özetleme
Bağımlılık ihlalleri grafiğinde bu anlam modelindeki çeşitli veri kalitesi sorunları gösterilmektedir:
- Bazı şehir adları büyük harftir. Bu sorunu düzeltmek için dize yöntemlerini kullanın.
- Bazı şehir adlarının "Kuzey" ve "Doğu" gibi niteleyicileri (veya ön ekleri) vardır. Örneğin, "2128" Posta Kodu bir kez "DOĞU BOSTON" ve bir kez "BOSTON" ile eşlenir. "NORTH DARTMOUTH" ve "DARTMOUTH" arasında benzer bir sorun oluşur. Bu niteleyicileri bırakın veya posta kodlarını en sık görüldükleri şehre eşleyin.
- Bazı şehir adlarında "PITTSFIELD" ile "PITTSFILED" ve "NEWBURGPORT" ve "NEWBURYPORT" gibi yazım hataları vardır. "NEWBURYPORT" için en yaygın oluşumu kullanarak bu yazım hatasını düzeltin. "PITTSFIELD" için, her biri tek bir oluşumla, dış bilgi veya dil modeli olmadan otomatik kesinleştirme çok daha zordur.
- Bazen, "Batı" gibi ön ekler tek harfli "W" olarak kısaltılır. "W" ifadesinin tüm oluşumları "Batı" anlamına geliyorsa "W" yerine "Batı" yazın.
- Posta Kodu "02130" bir kez "BOSTON" ve bir kez "Jamaica Plain" ile eşleştirir. Bu sorunu düzeltmek kolay değildir. Daha fazla veriyle, en yaygın olayı hedefleyerek eşleme yapın.
Verileri temizleme
Başlık biçimine dönüştürerek büyük harf kullanımını düzeltin.
providers['CITY'] = providers.CITY.str.title()Daha az belirsizlik olduğunu onaylamak için ihlal algılamayı yeniden çalıştırın.
providers.list_dependency_violations('ZIP', 'CITY')
Verileri el ile daraltın veya SemPy'nin drop_dependency_violations işlevini kullanarak sütunlar arasındaki işlevsel kısıtlamaları ihlal eden satırları bırakın.
Determinant değişkeninin her değeri için, drop_dependency_violations bağımlı değişkenin en yaygın değerini seçer ve diğer değerlerle tüm satırları bırakır. Bu işlemi yalnızca bu istatistiksel buluşsal yöntemin verileriniz için doğru sonuçlar verdiğine eminseniz uygulayın. Aksi takdirde, algılanan ihlalleri işlemek için kendi kodunuzu yazın.
drop_dependency_violationsveZIPsütunlarındaCITYişlevini çalıştırın.providers_clean = providers.drop_dependency_violations('ZIP', 'CITY')ve
ZIParasındakiCITYbağımlılık ihlallerini listeleyin.providers_clean.list_dependency_violations('ZIP', 'CITY')
Kod, işlev kısıtlaması ZIP -> CITYihlali olmadığını belirtmek için boş bir liste döndürür.
İlgili içerik
Anlamsal bağlantı veya SemPy için diğer öğreticilere bakın:
- Öğreticisi: Örnek anlamsal modelde işlevsel bağımlılıkları çözümleme
- Eğitim: Jupyter not defterinden Power BI ölçülerini ayıklama ve hesaplama
- Öğretici: Anlamsal bağlantı kullanarak anlamsal modeldeki ilişkileri bulma
- Öğretici: Anlam bağlantısı kullanarak Synthea veri kümesindeki ilişkileri bulma
- Kılavuz: SemPy ve Great Expectations (GX) kullanarak verileri doğrulama