Öğretici: Anlamsal modelde işlevsel bağımlılıkları analiz etme
Bu öğreticide, bir Power BI analisti tarafından yapılan ve anlamsal modeller (Power BI veri kümeleri) biçiminde depolanan önceki işleri temel alacaktır. Microsoft Fabric'teki Synapse Veri Bilimi deneyiminde SemPy (önizleme) kullanarak DataFrame sütunlarında bulunan işlevsel bağımlılıkları analiz edebilirsiniz. Bu analiz, daha doğru içgörüler elde etmek için önemli olmayan veri kalitesi sorunlarını keşfetmeye yardımcı olur.
Bu öğreticide aşağıdakilerin nasıl yapılacağını öğreneceksiniz:
- Anlamsal modelde işlevsel bağımlılıklar hakkındaki hipotezleri formüle etmek için etki alanı bilgisi uygulayın.
- Power BI ile tümleştirmeyi destekleyen ve veri kalitesi analizini otomatikleştirmeye yardımcı olan anlamsal bağlantının Python kitaplığının (SemPy) bileşenleri hakkında bilgi edinin. Bu bileşenler şunlardır:
- FabricDataFrame - ek anlam bilgileriyle geliştirilmiş pandas benzeri bir yapı.
- Doku çalışma alanından not defterinize anlamsal modeller çekmek için kullanışlı işlevler.
- İşlevsel bağımlılıklar hakkındaki hipotezlerin değerlendirilmesini otomatik hale getiren ve anlamsal modellerinizdeki ilişki ihlallerini tanımlayan kullanışlı işlevler.
Önkoşullar
Microsoft Fabric aboneliği alın. Alternatif olarak, ücretsiz bir Microsoft Fabric deneme sürümüne kaydolun.
Synapse Veri Bilimi deneyimine geçmek için giriş sayfanızın sol tarafındaki deneyim değiştiriciyi kullanın.

Çalışma alanınızı bulmak ve seçmek için sol gezinti bölmesinden Çalışma Alanları'nı seçin. Bu çalışma alanı, geçerli çalışma alanınız olur.
Fabric-samples GitHub deposundan Customer Profitability Sample.pbix anlam modelini indirin ve çalışma alanınıza yükleyin.
Not defterinde birlikte izleyin
Powerbi_dependencies_tutorial.ipynb not defteri bu öğreticiye eşlik eder.
Bu öğreticide eşlik eden not defterini açmak için, not defterini çalışma alanınıza aktarmak üzere Sisteminizi veri bilimi öğreticilerine hazırlama başlığındaki yönergeleri izleyin.
Bu sayfadaki kodu kopyalayıp yapıştırmayı tercih ederseniz, yeni bir not defteri oluşturabilirsiniz.
Kod çalıştırmaya başlamadan önce not defterine bir göl evi eklediğinizden emin olun.
Not defterini ayarlama
Bu bölümde, gerekli modüller ve verilerle bir not defteri ortamı ayarlarsınız.
Not defterindeki
%pipsatır içi yükleme özelliğini kullanarak PyPI'den yükleyinSemPy:%pip install semantic-linkDaha sonra ihtiyacınız olacak modüllerin gerekli içeri aktarmalarını gerçekleştirin:
import sempy.fabric as fabric from sempy.dependencies import plot_dependency_metadata
Verileri yükleme ve ön işleme
Bu öğreticide standart örnek bir anlam modeli Customer Profitability Sample.pbix kullanılmıştır. Anlamsal modelin açıklaması için bkz . Power BI için Müşteri Kârlılığı örneği.
SemPy'nin işlevini kullanarak Power BI verilerini FabricDataFrames'e
read_tableyükleyin:dataset = "Customer Profitability Sample" customer = fabric.read_table(dataset, "Customer") customer.head()StateTabloyu bir FabricDataFrame'e yükleyin:state = fabric.read_table(dataset, "State") state.head()Bu kodun çıkışı pandas DataFrame gibi görünse de pandas üzerinde bazı yararlı işlemleri destekleyen adlı bir
FabricDataFrameveri yapısı başlatmış olmanız gerekir.veri türünü
customerdenetleyin:type(customer)Çıkış, '' türünde
sempy.fabric._dataframe._fabric_dataframe.FabricDataFrameolduğunucustomeronaylar.ve
stateDataFrames'ecustomerkatılın:customer_state_df = customer.merge(state, left_on="State", right_on="StateCode", how='left') customer_state_df.head()
İşlevsel bağımlılıkları tanımlama
İşlevsel bağımlılık, bir DataFrame içindeki iki (veya daha fazla) sütundaki değerler arasında bire çok ilişki olarak kendini gösterir. Bu ilişkiler, veri kalitesi sorunlarını otomatik olarak algılamak için kullanılabilir.
Sütunlardaki değerler arasındaki mevcut işlevsel bağımlılıkları belirlemek için birleştirilmiş DataFrame'de SemPy'nin
find_dependenciesişlevini çalıştırın:dependencies = customer_state_df.find_dependencies() dependenciesSemPy'nin işlevini kullanarak tanımlanan bağımlılıkları görselleştirin
plot_dependency_metadata:plot_dependency_metadata(dependencies)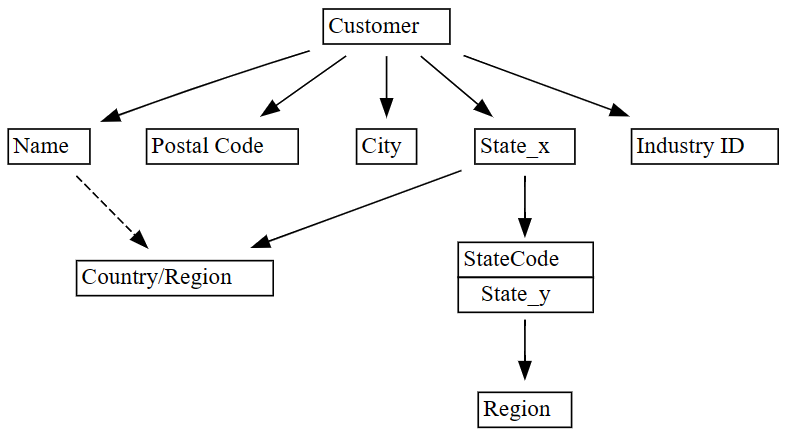
Beklendiği gibi, işlevsel bağımlılıklar grafiği sütunun
Customer,Postal CodeveNamegibiCitybazı sütunları belirlediğini gösterir.Şaşırtıcı bir şekilde, grafik ile arasında
CityPostal Codeişlevsel bir bağımlılık göstermez, çünkü büyük olasılıkla sütunlar arasındaki ilişkilerde birçok ihlal vardır. Belirli sütunlar arasındaki bağımlılık ihlallerini görselleştirmek için SemPy'ninplot_dependency_violationsişlevini kullanabilirsiniz.

Kalite sorunları için verileri keşfetme
SemPy'nin
plot_dependency_violationsgörselleştirme işleviyle bir grafik çizin.customer_state_df.plot_dependency_violations('Postal Code', 'City')
Bağımlılık ihlallerinin çizimi, sol taraftaki için değerleri
Postal Codeve sağ taraftaki için değerleriCitygösterir. Bu iki değeri içeren birPostal Codesatır varsa kenar, sol taraftakiCitybir ile sağ taraftaki bir satırı bağlar. Kenarlara bu tür satırların sayısıyla ek açıklama eklenir. Örneğin, posta kodu 20004 olan biri "Kuzey Kulesi" ve diğeri "Washington" şehirli iki satır vardır.Ayrıca çizimde birkaç ihlal ve birçok boş değer gösterilir.
için
Postal Codeboş değer sayısını onaylayın:customer_state_df['Postal Code'].isna().sum()Posta kodu için 50 satırda NA bulunur.
Boş değerlerle satırları bırakın. Ardından işlevini kullanarak
find_dependenciesbağımlılıkları bulun. SemPy'nin iç çalışmalarına bir bakış sunan ek parametreyeverbose=1dikkat edin:customer_state_df2=customer_state_df.dropna() customer_state_df2.find_dependencies(verbose=1)ve
CityiçinPostal Codekoşullu entropi 0,049'dir. Bu değer, işlevsel bağımlılık ihlalleri olduğunu gösterir. İhlalleri düzeltmeden önce, bağımlılıkları görmek için koşullu entropi üzerindeki eşiği varsayılan değerinden0.01değerine0.05yükseltin. Düşük eşikler daha az bağımlılıkla (veya daha yüksek seçiciliğe) neden olur.Koşullu entropi üzerindeki eşiği varsayılan değerinden değerine yükseltin
0.010.05:plot_dependency_metadata(customer_state_df2.find_dependencies(threshold=0.05))
Diğer varlıkların değerlerini hangi varlığın belirlediği hakkında etki alanı bilgisi uygularsanız, bu bağımlılıklar grafiği doğru görünür.
Algılanan diğer veri kalitesi sorunlarını keşfedin. Örneğin, bir kesikli ok ile birleşir
CityveRegionbu, bağımlılığın yalnızca yaklaşık olduğunu gösterir. Bu yaklaşık ilişki kısmi işlevsel bağımlılık olduğu anlamına gelebilir.customer_state_df.list_dependency_violations('City', 'Region')Belirsiz
Regionbir değerin ihlale neden olduğu durumların her birine daha yakından bakın:customer_state_df[customer_state_df.City=='Downers Grove']Sonuç, Downers Grove şehrinin Illinois ve Nebraska'da oluştuğunu göstermektedir. Ancak Downer's Grove, Nebraska değil, Illinois'de bulunan bir şehirdir.
Fremont şehrine bir göz atın:
customer_state_df[customer_state_df.City=='Fremont']California'da Fremont adında bir şehir var. Ancak, Texas için arama motoru Fremont'ı değil Premont'ı döndürür.
Bağımlılık ihlallerinin özgün grafiğindeki noktalı çizgiyle belirtildiği gibi ve
Country/RegionarasındakiNamebağımlılık ihlallerini görmek de şüphelidir (boş değerlere sahip satırları bırakmadan önce).customer_state_df.list_dependency_violations('Name', 'Country/Region')SDI Design olarak bir müşterinin Birleşik Devletler ve Kanada gibi iki bölgede mevcut olduğu görülüyor. Bu durum anlamsal bir ihlal olmayabilir, ancak yalnızca yaygın olmayan bir durum olabilir. Yine de yakından bakmak faydalı olabilir:
Müşterinin SDI Tasarımına daha yakından bakın:
customer_state_df[customer_state_df.Name=='SDI Design']Daha fazla inceleme, aslında aynı ada sahip iki farklı müşteri (farklı sektörlerden) olduğunu göstermektedir.

Keşif veri analizi heyecan verici bir süreçtir ve veri temizleme de öyle. Verilere nasıl baktığınıza, ne sormak istediğinize vb. bağlı olarak her zaman verilerin gizlendiği bir şey vardır. Anlamsal bağlantı, verilerinizle daha fazlasını elde etmek için kullanabileceğiniz yeni araçlar sağlar.
İlgili içerik
Anlamsal bağlantı / SemPy için diğer öğreticilere göz atın:
- Öğretici: İşlevsel bağımlılıklarla verileri temizleme
- Öğretici: Jupyter not defterinden Power BI ölçülerini ayıklama ve hesaplama
- Öğretici: Anlamsal bağlantıyı kullanarak anlamsal modeldeki ilişkileri bulma
- Öğretici: Anlamsal bağlantıyı kullanarak Synthea veri kümesindeki ilişkileri bulma
- Öğretici: SemPy ve Great Expectations (GX) kullanarak verileri doğrulama (önizleme)
Geri Bildirim
Çok yakında: 2024 boyunca, içerik için geri bildirim mekanizması olarak GitHub Sorunları’nı kullanımdan kaldıracak ve yeni bir geri bildirim sistemiyle değiştireceğiz. Daha fazla bilgi için bkz. https://aka.ms/ContentUserFeedback.
Gönderin ve geri bildirimi görüntüleyin