Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
Bu öğreticide, hangi banka müşterilerinin ayrılacağını tahmin etmek için en iyi makine öğrenmesi modellerini seçmek için birden çok makine öğrenmesi modeli eğitmeyi öğreneceksiniz.
Bu öğreticide şunları yapacaksınız:
- Rastgele Orman ve LightGBM modellerini eğitin.
- Eğitilen makine öğrenmesi modellerini, kullanılan hiperaparametreleri ve değerlendirme ölçümlerini günlüğe kaydetmek için Microsoft Fabric'in MLflow çerçevesiyle yerel tümleştirmesini kullanın.
- Eğitilen makine öğrenmesi modelini kaydedin.
- Doğrulama veri kümesinde eğitilen makine öğrenmesi modellerinin performanslarını değerlendirin.
MLflow, makine öğrenmesi yaşam döngüsünü İzleme, Modeller ve Model Kayıt Defteri gibi özelliklerle yönetmeye yönelik açık kaynak bir platformdur. MLflow, Doku Veri Bilimi deneyimiyle yerel olarak tümleştirilmiştir.
Önkoşullar
Microsoft Fabric aboneliği alın. Alternatif olarak, ücretsiz bir Microsoft Fabric deneme sürümüne kaydolun.
Giriş sayfanızın sol alt köşesindeki deneyim değiştiriciyi kullanarak Fabric'e geçin.

Bu, öğretici serisinin 5. bölümünün 3. bölümüdür. Bu öğreticiyi tamamlamak için önce şunları tamamlayın:
- 1. Bölüm: Apache Spark kullanarak bir Microsoft Fabric lakehouse'a veri alma.
- 2. Bölüm: Veriler hakkında daha fazla bilgi edinmek için Microsoft Fabric not defterlerini kullanarak verileri keşfedin ve görselleştirin.
Not defterinde birlikte izleyin
3-train-evaluate.ipynb , bu öğreticiye eşlik eden not defteridir.
Bu öğreticiyle ilişkili not defterini açmak için, not defterini çalışma alanınıza aktarmak üzere sisteminizi veri bilimi öğreticilerine hazırlama başlığındaki yönergeleri izleyin.
Bu sayfadaki kodu kopyalayıp yapıştırmayı tercih ederseniz, yeni bir not defteri oluşturabilirsiniz.
Kod çalıştırmaya başlamadan önce not defterine bir göl evi eklediğinizden emin olun.
Önemli
1. ve 2. kısımda kullandığınız göl eviyle aynı göle ekleyin.
Özel kitaplıkları yükleme
Bu not defteri için kullanarak imbalanced-learn (olarak imblearniçeri aktarıldı) %pip installyükleyeceksiniz. Imbalanced-learn, dengesiz veri kümeleriyle ilgilenirken kullanılan Yapay Azınlık Oversampling Technique (SMOTE) kitaplığıdır. PySpark çekirdeği sonrasında yeniden başlatılır %pip install, bu nedenle başka hücreler çalıştırmadan önce kitaplığı yüklemeniz gerekir.
Kitaplığı kullanarak SMOTE'ye imblearn erişeceksiniz. Şimdi satır içi yükleme özelliklerini (örneğin, %pip, %conda) kullanarak yükleyin.
# Install imblearn for SMOTE using pip
%pip install imblearn
%pip install scikit-learn==1.6.1
%pip install "mlflow==2.12.2"
Önemli
Not defterini her yeniden başlattığınızda bu yüklemeyi çalıştırın.
Not defterine bir kitaplık yüklediğinizde, çalışma alanında değil, yalnızca not defteri oturumu boyunca kullanılabilir. Not defterini yeniden başlatırsanız kitaplığı yeniden yüklemeniz gerekir.
Sık kullandığınız bir kitaplığınız varsa ve bunu çalışma alanınızdaki tüm not defterleri için kullanılabilir hale getirmek istiyorsanız, bu amaçla bir Doku ortamı kullanabilirsiniz. Bir ortam oluşturabilir, kitaplığı buna yükleyebilir ve çalışma alanı yöneticiniz ortamı varsayılan ortamı olarak çalışma alanına ekleyebilir. Bir ortamı varsayılan çalışma alanı olarak ayarlama hakkında daha fazla bilgi için bkz . Yönetici, çalışma alanı için varsayılan kitaplıkları ayarlar.
Mevcut çalışma alanı kitaplıklarını ve Spark özelliklerini bir ortama geçirme hakkında bilgi için bkz . Çalışma alanı kitaplıklarını ve Spark özelliklerini varsayılan ortama geçirme.
Verileri yükleme
Herhangi bir makine öğrenmesi modelini eğitmadan önce, önceki not defterinde oluşturduğunuz temizlenmiş verileri okumak için delta tablosunu göl evinden yüklemeniz gerekir.
import pandas as pd
SEED = 12345
df_clean = spark.read.format("delta").load("Tables/df_clean").toPandas()
MLflow kullanarak modeli izlemek ve günlüğe kaydetmek için deneme oluşturma
Bu bölümde deneme oluşturma, makine öğrenmesi modeli ve eğitim parametrelerini belirtme ve ölçümleri puanlama, makine öğrenmesi modellerini eğitme, bunları günlüğe kaydetme ve eğitilen modelleri daha sonra kullanmak üzere kaydetme işlemleri gösterilmektedir.
import mlflow
# Setup experiment name
EXPERIMENT_NAME = "bank-churn-experiment-SBM" # MLflow experiment name
MLflow otomatik kaydetme özelliklerini genişleten otomatik kaydetme, eğitilirken bir makine öğrenmesi modelinin giriş parametrelerinin ve çıkış ölçümlerinin değerlerini otomatik olarak yakalayarak çalışır. Bu bilgiler daha sonra çalışma alanınıza kaydedilir ve burada MLflow API'leri veya çalışma alanınızdaki ilgili deneme kullanılarak erişilebilir ve görselleştirilebilir.
İlgili adlarına sahip tüm denemeler günlüğe kaydedilir ve parametrelerini ve performans ölçümlerini izleyebilirsiniz. Otomatik kaydetme hakkında daha fazla bilgi edinmek için bkz . Microsoft Fabric'te otomatik kaydetme.
Deneme ve otomatik kaydetme belirtimlerini ayarlama
mlflow.set_experiment(EXPERIMENT_NAME)
mlflow.autolog(exclusive=False)
scikit-learn ve LightGBM'i içeri aktarma
Verileriniz yerindeyse artık makine öğrenmesi modellerini tanımlayabilirsiniz. Bu not defterine Rastgele Orman ve LightGBM modelleri uygulayacaksınız. Modelleri birkaç kod satırı içinde uygulamak için ve scikit-learn kullanınlightgbm.
# Import the required libraries for model training
from sklearn.model_selection import train_test_split
from lightgbm import LGBMClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, f1_score, precision_score, confusion_matrix, recall_score, roc_auc_score, classification_report
Eğitim, doğrulama ve test veri kümelerini hazırlama
train_test_split verileri eğitim, doğrulama ve test kümelerine bölmek için işlevini scikit-learn kullanın.
y = df_clean["Exited"]
X = df_clean.drop("Exited",axis=1)
# Split the dataset to 60%, 20%, 20% for training, validation, and test datasets
# Train-Test Separation
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, random_state=SEED)
# Train-Validation Separation
X_train, X_val, y_train, y_val = train_test_split(X_train, y_train, test_size=0.25, random_state=SEED)
Test verilerini delta tablosuna kaydetme
Test verilerini bir sonraki not defterinde kullanmak üzere delta tablosuna kaydedin.
table_name = "df_test"
# Create PySpark DataFrame from Pandas
df_test=spark.createDataFrame(X_test)
df_test.write.mode("overwrite").format("delta").save(f"Tables/{table_name}")
print(f"Spark test DataFrame saved to delta table: {table_name}")
Azınlık sınıfına yönelik yeni örnekleri sentezlemek için eğitim verilerine SMOTE uygulama
Bölüm 2'deki veri keşfi, 10.000 müşteriye karşılık gelen 10.000 veri noktasından yalnızca 2.037 müşterinin (%20 civarında) bankadan ayrıldığını gösterdi. Bu, veri kümesinin yüksek düzeyde dengesiz olduğunu gösterir. Dengesiz sınıflandırmayla ilgili sorun, bir modelin karar sınırını etkili bir şekilde öğrenemeyecek kadar az azınlık sınıfı örneği olmasıdır. SMOTE, azınlık sınıfı için yeni örnekleri sentezlemek için en yaygın kullanılan yaklaşımdır. SMOTE hakkında buradan ve buradan daha fazla bilgi edinin.
İpucu
SMOTE'nin yalnızca eğitim veri kümesine uygulanması gerektiğini unutmayın. Makine öğrenmesi modelinin üretimdeki durumu temsil eden özgün verilerde nasıl performans göstereceğinin geçerli bir tahminini elde etmek için test veri kümesini özgün dengesiz dağıtımında bırakmanız gerekir.
from collections import Counter
from imblearn.over_sampling import SMOTE
sm = SMOTE(random_state=SEED)
X_res, y_res = sm.fit_resample(X_train, y_train)
new_train = pd.concat([X_res, y_res], axis=1)
İpucu
Bu hücreyi çalıştırdığınızda görüntülenen MLflow uyarı iletisini güvenle yoksayabilirsiniz.
ModuleNotFoundError iletisi görürseniz, kitaplığı yükleyen bu not defterindeki ilk hücreyi çalıştırmayı imblearn kaçırdınız. Not defterini her yeniden başlattığınızda bu kitaplığı yüklemeniz gerekir. Geri dönün ve bu not defterindeki ilk hücreden başlayarak tüm hücreleri yeniden çalıştırın.
Model eğitimi
- Maksimum 4 ve 4 özellik derinliğine sahip Rastgele Orman kullanarak modeli eğitin
mlflow.sklearn.autolog(registered_model_name='rfc1_sm') # Register the trained model with autologging
rfc1_sm = RandomForestClassifier(max_depth=4, max_features=4, min_samples_split=3, random_state=1) # Pass hyperparameters
with mlflow.start_run(run_name="rfc1_sm") as run:
rfc1_sm_run_id = run.info.run_id # Capture run_id for model prediction later
print("run_id: {}; status: {}".format(rfc1_sm_run_id, run.info.status))
# rfc1.fit(X_train,y_train) # Imbalanaced training data
rfc1_sm.fit(X_res, y_res.ravel()) # Balanced training data
rfc1_sm.score(X_val, y_val)
y_pred = rfc1_sm.predict(X_val)
cr_rfc1_sm = classification_report(y_val, y_pred)
cm_rfc1_sm = confusion_matrix(y_val, y_pred)
roc_auc_rfc1_sm = roc_auc_score(y_res, rfc1_sm.predict_proba(X_res)[:, 1])
- Maksimum 8 ve 6 özellik derinliğine sahip Rastgele Orman kullanarak modeli eğitin
mlflow.sklearn.autolog(registered_model_name='rfc2_sm') # Register the trained model with autologging
rfc2_sm = RandomForestClassifier(max_depth=8, max_features=6, min_samples_split=3, random_state=1) # Pass hyperparameters
with mlflow.start_run(run_name="rfc2_sm") as run:
rfc2_sm_run_id = run.info.run_id # Capture run_id for model prediction later
print("run_id: {}; status: {}".format(rfc2_sm_run_id, run.info.status))
# rfc2.fit(X_train,y_train) # Imbalanced training data
rfc2_sm.fit(X_res, y_res.ravel()) # Balanced training data
rfc2_sm.score(X_val, y_val)
y_pred = rfc2_sm.predict(X_val)
cr_rfc2_sm = classification_report(y_val, y_pred)
cm_rfc2_sm = confusion_matrix(y_val, y_pred)
roc_auc_rfc2_sm = roc_auc_score(y_res, rfc2_sm.predict_proba(X_res)[:, 1])
- LightGBM kullanarak modeli eğitin
# lgbm_model
mlflow.lightgbm.autolog(registered_model_name='lgbm_sm') # Register the trained model with autologging
lgbm_sm_model = LGBMClassifier(learning_rate = 0.07,
max_delta_step = 2,
n_estimators = 100,
max_depth = 10,
eval_metric = "logloss",
objective='binary',
random_state=42)
with mlflow.start_run(run_name="lgbm_sm") as run:
lgbm1_sm_run_id = run.info.run_id # Capture run_id for model prediction later
# lgbm_sm_model.fit(X_train,y_train) # Imbalanced training data
lgbm_sm_model.fit(X_res, y_res.ravel()) # Balanced training data
y_pred = lgbm_sm_model.predict(X_val)
accuracy = accuracy_score(y_val, y_pred)
cr_lgbm_sm = classification_report(y_val, y_pred)
cm_lgbm_sm = confusion_matrix(y_val, y_pred)
roc_auc_lgbm_sm = roc_auc_score(y_res, lgbm_sm_model.predict_proba(X_res)[:, 1])
Model performansını izlemek için deneme yapıtı
Deneme çalıştırmaları, çalışma alanından bulunabilen deneme yapıtına otomatik olarak kaydedilir. Bunlar, denemeyi ayarlamak için kullanılan ada göre adlandırılır. Eğitilen tüm makine öğrenmesi modelleri, çalıştırmaları, performans ölçümleri ve model parametreleri günlüğe kaydedilir.
Denemelerinizi görüntülemek için:
Sol panelde çalışma alanınızı seçin.
Aradığınız denemeyi bulmayı kolaylaştırmak için sağ üst kısımda yalnızca denemeleri gösterecek şekilde filtreleyin.
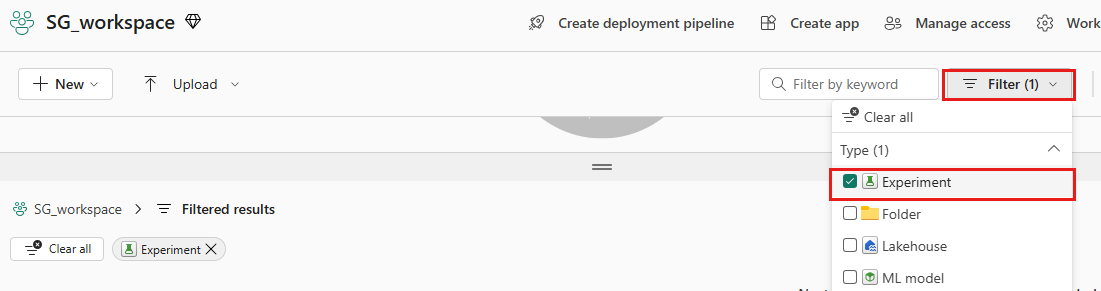
Bu örnekte bank-churn-experiment adlı deneme adını bulun ve seçin. Denemeyi çalışma alanınızda görmüyorsanız tarayıcınızı yenileyin.
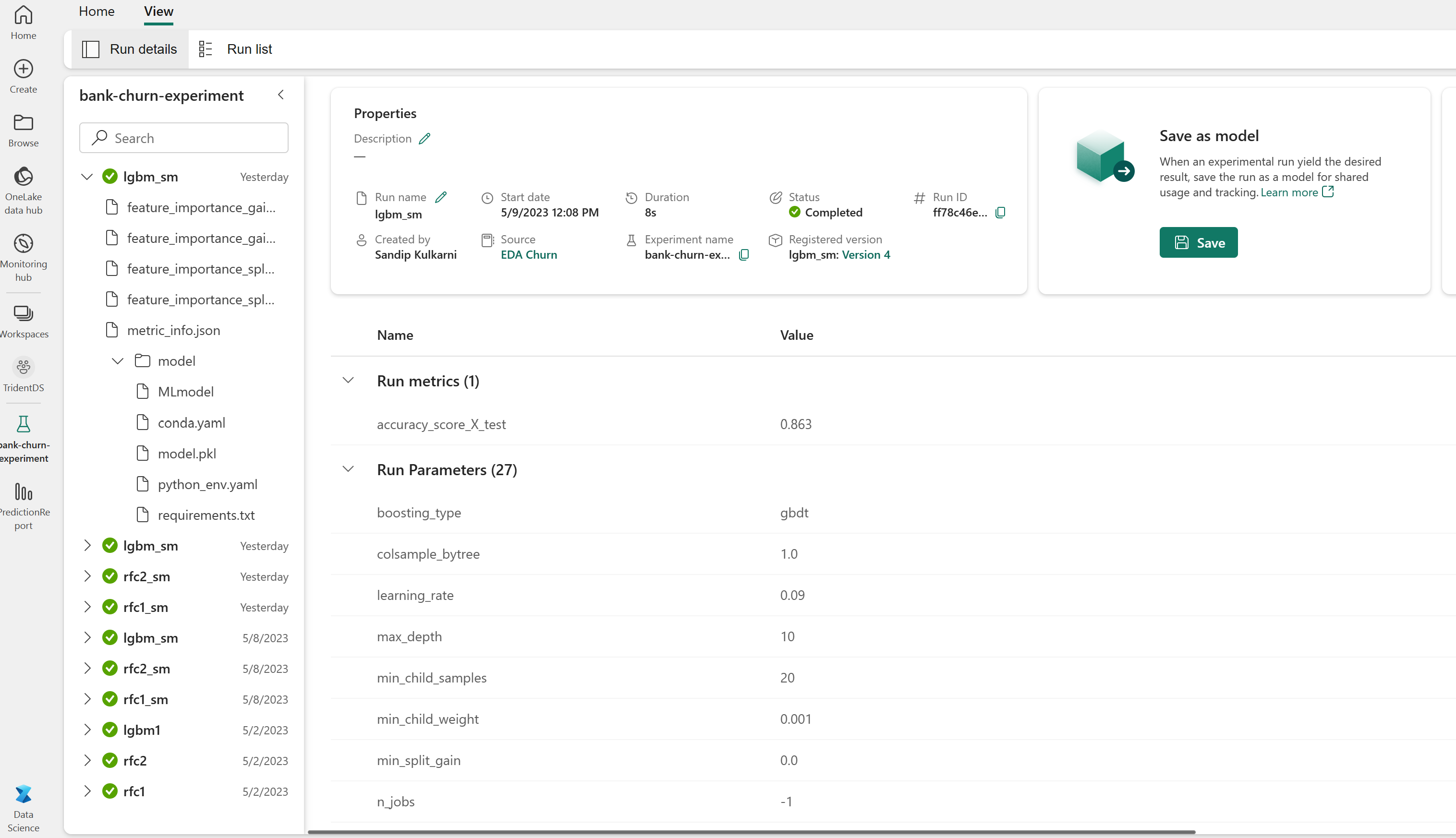


Doğrulama veri kümesinde eğitilen modellerin performanslarını değerlendirme
Makine öğrenmesi modeli eğitimini tamamladıktan sonra, eğitilen modellerin performansını iki şekilde değerlendirebilirsiniz.
Çalışma alanından kaydedilen denemeyi açın, makine öğrenmesi modellerini yükleyin ve ardından doğrulama veri kümesinde yüklü modellerin performansını değerlendirin.
# Define run_uri to fetch the model # mlflow client: mlflow.model.url, list model load_model_rfc1_sm = mlflow.sklearn.load_model(f"runs:/{rfc1_sm_run_id}/model") load_model_rfc2_sm = mlflow.sklearn.load_model(f"runs:/{rfc2_sm_run_id}/model") load_model_lgbm1_sm = mlflow.lightgbm.load_model(f"runs:/{lgbm1_sm_run_id}/model") # Assess the performance of the loaded model on validation dataset ypred_rfc1_sm_v1 = load_model_rfc1_sm.predict(X_val) # Random Forest with max depth of 4 and 4 features ypred_rfc2_sm_v1 = load_model_rfc2_sm.predict(X_val) # Random Forest with max depth of 8 and 6 features ypred_lgbm1_sm_v1 = load_model_lgbm1_sm.predict(X_val) # LightGBMDoğrulama veri kümesinde eğitilen makine öğrenmesi modellerinin performansını doğrudan değerlendirin.
ypred_rfc1_sm_v2 = rfc1_sm.predict(X_val) # Random Forest with max depth of 4 and 4 features ypred_rfc2_sm_v2 = rfc2_sm.predict(X_val) # Random Forest with max depth of 8 and 6 features ypred_lgbm1_sm_v2 = lgbm_sm_model.predict(X_val) # LightGBM
Tercihinize bağlı olarak her iki yaklaşım da uygundur ve aynı performansları sunmalıdır. Bu not defterinde, Microsoft Fabric'teki MLflow otomatik kaydetme özelliklerini daha iyi göstermek için ilk yaklaşımı seçeceksiniz.
Karışıklık Matrisi'ni kullanarak Doğru/Yanlış Pozitifleri/Negatifleri Göster
Ardından, doğrulama veri kümesini kullanarak sınıflandırmanın doğruluğunu değerlendirmek için karışıklık matrisini çizmek için bir betik geliştireceksiniz. Karışıklık matrisi SynapseML araçları kullanılarak çizilebilir ve burada sağlanan Sahtekarlık Algılama örneğinde gösterilmiştir.
import seaborn as sns
sns.set_theme(style="whitegrid", palette="tab10", rc = {'figure.figsize':(9,6)})
import matplotlib.pyplot as plt
import matplotlib.ticker as mticker
from matplotlib import rc, rcParams
import numpy as np
import itertools
def plot_confusion_matrix(cm, classes,
normalize=False,
title='Confusion matrix',
cmap=plt.cm.Blues):
print(cm)
plt.figure(figsize=(4,4))
plt.rcParams.update({'font.size': 10})
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=45, color="blue")
plt.yticks(tick_marks, classes, color="blue")
fmt = '.2f' if normalize else 'd'
thresh = cm.max() / 2.
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, format(cm[i, j], fmt),
horizontalalignment="center",
color="red" if cm[i, j] > thresh else "black")
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')
- Maksimum 4 ve 4 özellik derinliğine sahip Rastgele Orman Sınıflandırıcı için Karışıklık Matrisi
cfm = confusion_matrix(y_val, y_pred=ypred_rfc1_sm_v1)
plot_confusion_matrix(cfm, classes=['Non Churn','Churn'],
title='Random Forest with max depth of 4')
tn, fp, fn, tp = cfm.ravel()
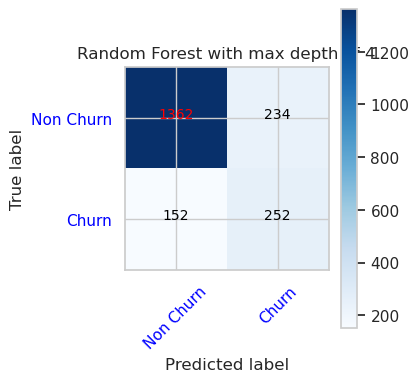
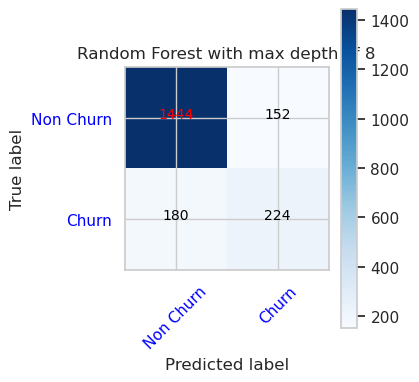
- Maksimum 8 ve 6 özellik derinliğine sahip Rastgele Orman Sınıflandırıcı için Karışıklık Matrisi
cfm = confusion_matrix(y_val, y_pred=ypred_rfc2_sm_v1)
plot_confusion_matrix(cfm, classes=['Non Churn','Churn'],
title='Random Forest with max depth of 8')
tn, fp, fn, tp = cfm.ravel()
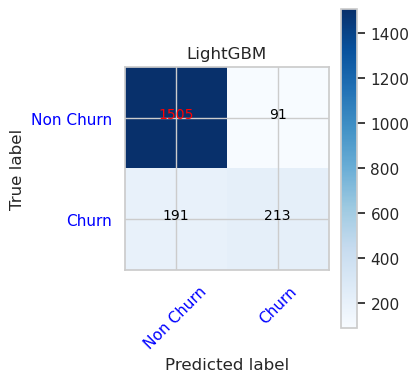
- LightGBM için Karışıklık Matrisi
cfm = confusion_matrix(y_val, y_pred=ypred_lgbm1_sm_v1)
plot_confusion_matrix(cfm, classes=['Non Churn','Churn'],
title='LightGBM')
tn, fp, fn, tp = cfm.ravel()