Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
Bu öğreticide, veri görselleştirme tekniklerini kullanarak temel özelliklerini özetlerken verileri incelemek ve araştırmak için keşif veri analizi (EDA) gerçekleştirmeyi öğreneceksiniz.
Veri çerçeveleri ve diziler üzerinde görsel oluşturmak için üst düzey bir arabirim sağlayan bir Python veri görselleştirme kitaplığı olan seabornkullanacaksınız.
seabornhakkında daha fazla bilgi için bkz. Seaborn: İstatistiksel Veri Görselleştirme.
Ayrıca keşif veri analizi ve temizleme işlemleri gerçekleştirmek için size etkileyici bir deneyim sağlayan, not defteri tabanlı bir araç olan Data Wrangler'ı da kullanacaksınız.
Bu öğreticideki ana adımlar şunlardır:
- Lakehouse'taki bir delta tablosundan saklanan verileri okuyun.
- Spark DataFrame'i Python görselleştirme kitaplıklarının desteklediği Pandas DataFrame'e dönüştürün.
- İlk veri temizleme ve dönüştürme işlemlerini gerçekleştirmek için Data Wrangler kullanın.
-
seabornkullanarak keşif veri analizi gerçekleştirin.
Önkoşullar
Microsoft Fabric aboneliği alın. Alternatif olarak, ücretsiz Microsoft Fabric deneme sürümünekaydolun.
Microsoft Fabricoturumunu açın.
Giriş sayfanızın sol alt köşesindeki deneyim değiştiriciyi kullanarak Fabric'e geçin.

Bu, öğretici serisindeki 5'in 2. bölümüdür. Bu eğitimi tamamlamak için önce şunları yapın:
- Bölüm 1: Apache Sparkkullanarak bir Microsoft Fabric lakehouse'a veri yükleme.
Not defterini takip edin
2-explore-cleanse-data.ipynb bu öğreticiye eşlik eden not defteridir.
Bu öğreticide eşlik eden not defterini açmak için, Not defterini çalışma alanınıza aktarmak sisteminizi veri bilimi öğreticilerine hazırlama başlığındaki yönergeleri izleyin.
Bu sayfadaki kodu kopyalayıp yapıştırmayı tercih ederseniz, yeni bir not defteri oluşturabilirsiniz.
Kod çalıştırmaya başlamadan önce not defteri bir göl evi eklemeyi unutmayın.
Önemli
Bölüm 1'de kullandığınız aynı göl evini bağlayın.
Lakehouse'dan ham verileri okuma
Lakehouse'un Dosyalar bölümünden ham verileri okuyun. Bu verileri önceki not defterine yüklemişsiniz. Bu kodu çalıştırmadan önce Bölüm 1'de kullandığınız lakehouse'u bu not defterine eklediğinizden emin olun.
df = (
spark.read.option("header", True)
.option("inferSchema", True)
.csv("Files/churn/raw/churn.csv")
.cache()
)
Veri kümesinden pandas DataFrame oluşturma
Daha kolay işleme ve görselleştirme için spark DataFrame'i pandas DataFrame'e dönüştürün.
df = df.toPandas()
Ham verileri görüntüleme
displayile ham verileri keşfedin, bazı temel istatistikler yapın ve grafik görünümlerini gösterin. Veri analizi ve görselleştirme için önce Numpy, Pnadas, Seabornve Matplotlib gibi gerekli kitaplıkları içeri aktarmanız gerektiğini unutmayın.
import seaborn as sns
sns.set_theme(style="whitegrid", palette="tab10", rc = {'figure.figsize':(9,6)})
import matplotlib.pyplot as plt
import matplotlib.ticker as mticker
from matplotlib import rc, rcParams
import numpy as np
import pandas as pd
import itertools
display(df, summary=True)
# Code generated by Data Wrangler for pandas DataFrame
def clean_data(df):
# Drop duplicate rows in columns: 'CustomerId', 'RowNumber'
df = df.drop_duplicates(subset=['CustomerId', 'RowNumber'])
# Drop rows with missing data across all columns
df = df.dropna()
# Drop columns: 'CustomerId', 'RowNumber', 'Surname'
df = df.drop(columns=['CustomerId', 'RowNumber', 'Surname'])
return df
df_clean = clean_data(df.copy())
df_clean.head()
İlk veri temizleme işlemini gerçekleştirmek için Data Wrangler kullanma
Not defterinizdeki pandas Dataframe'leri keşfetmek ve dönüştürmek için Data Wrangler'ı doğrudan not defterinden başlatın.
Not
Not defteri çekirdeği meşgulken veri Wrangler açılamıyor. Data Wrangler başlatılmadan önce hücre yürütmenin tamamlanması gerekir.
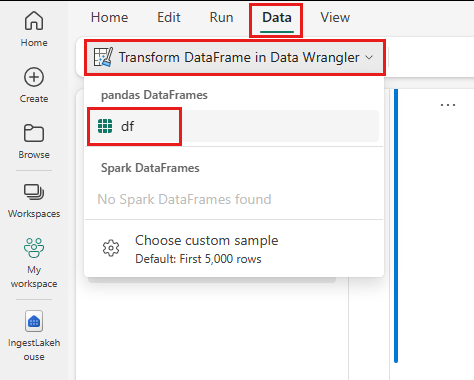
- Not defteri şeridi Veri sekmesinin altında Veri Wrangler'ı başlatseçin. Düzenleme için etkinleştirilmiş pandas DataFrame'lerin listesini görürsünüz.
- Data Wrangler'da açmak istediğiniz DataFrame'i seçin. Bu not defteri yalnızca bir DataFrame içerdiğinden
dfdfseçin.
Data Wrangler başlatılır ve verilerinize açıklayıcı bir genel bakış oluşturur. Ortadaki tabloda her veri sütunu gösterilir. Tablonun yanındaki Özeti panelinde DataFrame hakkındaki bilgiler gösterilir. Tabloda bir sütun seçtiğinizde, özet seçili sütun hakkındaki bilgilerle güncelleştirilir. Bazı durumlarda, görüntülenen ve özetlenen veriler DataFrame'inizin kesilmiş bir görünümü olur. Bu durumda, özet bölmesinde uyarı görüntüsü görürsünüz. Durumu açıklayan metni görüntülemek için bu uyarının üzerine gelin.

Yaptığınız her işlem tıklamalar halinde uygulanabilir, verilerin gerçek zamanlı olarak görüntülenmesi güncelleştirilebilir ve not defterinize yeniden kullanılabilir bir işlev olarak kaydedebileceğiniz kod oluşturulabilir.
Bu bölümün geri kalanı, Data Wrangler ile veri temizleme gerçekleştirme adımlarını gösterir.
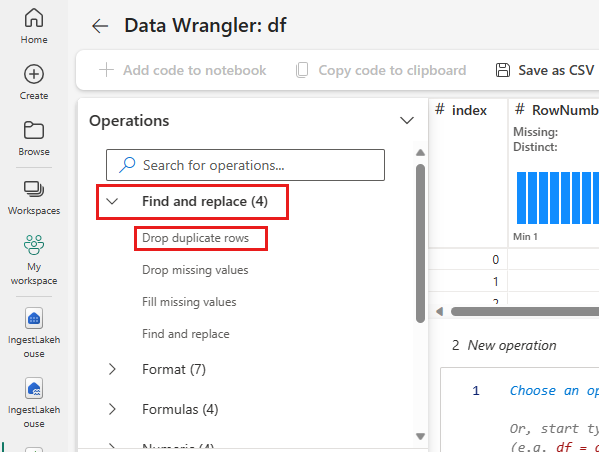
Yinelenen satırları bırakma
Sol panelde, veri kümesinde gerçekleştirebileceğiniz işlemlerin listesi (Bul ve değiştir, Biçim, Formüller, Sayısalgibi).
genişletin ve bul ve değiştir'i açın, yinelenen satırları bırakseçin.
Yinelenen bir satır tanımlamak üzere karşılaştırmak istediğiniz sütunların listesini seçmeniz için bir panel görüntülenir. RowNumber'yi ve CustomerId'ü seçin.
Orta panelde bu işlemin sonuçlarının önizlemesi yer alır. Önizlemenin altında işlemi gerçekleştirmek için kod bulunur. Bu örnekte veriler değişmemiş gibi görünür. Ancak kesilmiş bir görünüme baktığınız için işlemi yine de uygulamak iyi bir fikirdir.
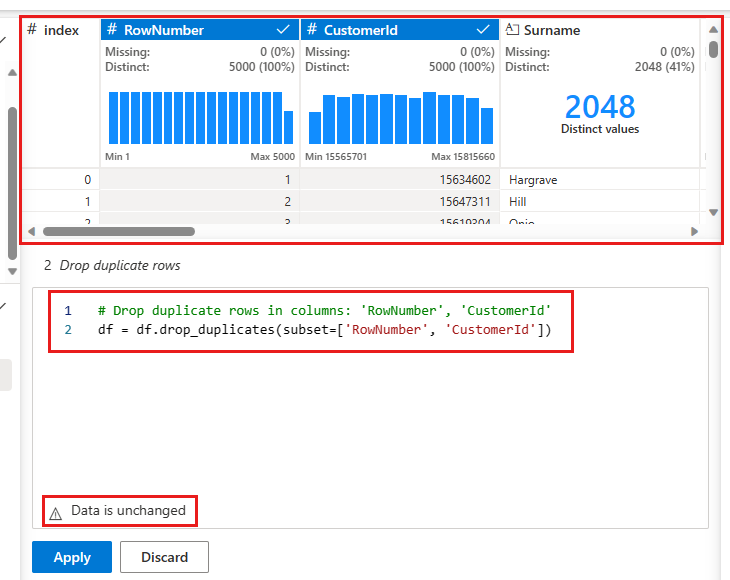
Sonraki adıma geçmek için seçin, uygula (yan tarafta veya altta) seçeneğini kullanın.

Eksik veri içeren satırları bırakma
Veri Wrangler’ı kullanarak tüm sütunlarda eksik veri bulunan satırları kaldırın.
bul ve değiştireksik değerleri Bırak'ı seçin.
Seçin'i tüm Hedef sütunlarından.
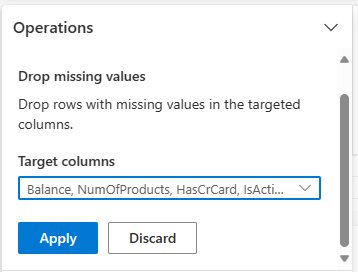
Sonraki adıma geçmek için seçin, ardından Uygula'yı tıklayın.

Sütunları kaldır
İhtiyacınız olmayan sütunları bırakmak için Data Wrangler'ı kullanın.
şema genişletin ve sütunlarıBırakın'ı seçin.
RowNumber, CustomerIdSoyadıöğesini seçin. Bu sütunlar, kod tarafından değiştirildiğini göstermek için önizlemede kırmızıyla gösterilir (bu durumda bırakılır.)
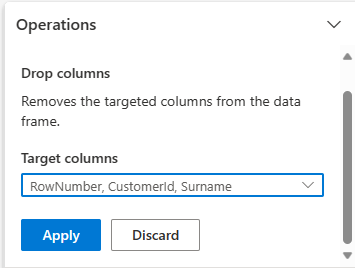
Sonraki adıma geçmek için seçin, ardından Uygula'yı tıklayın.

Deftere kod ekle
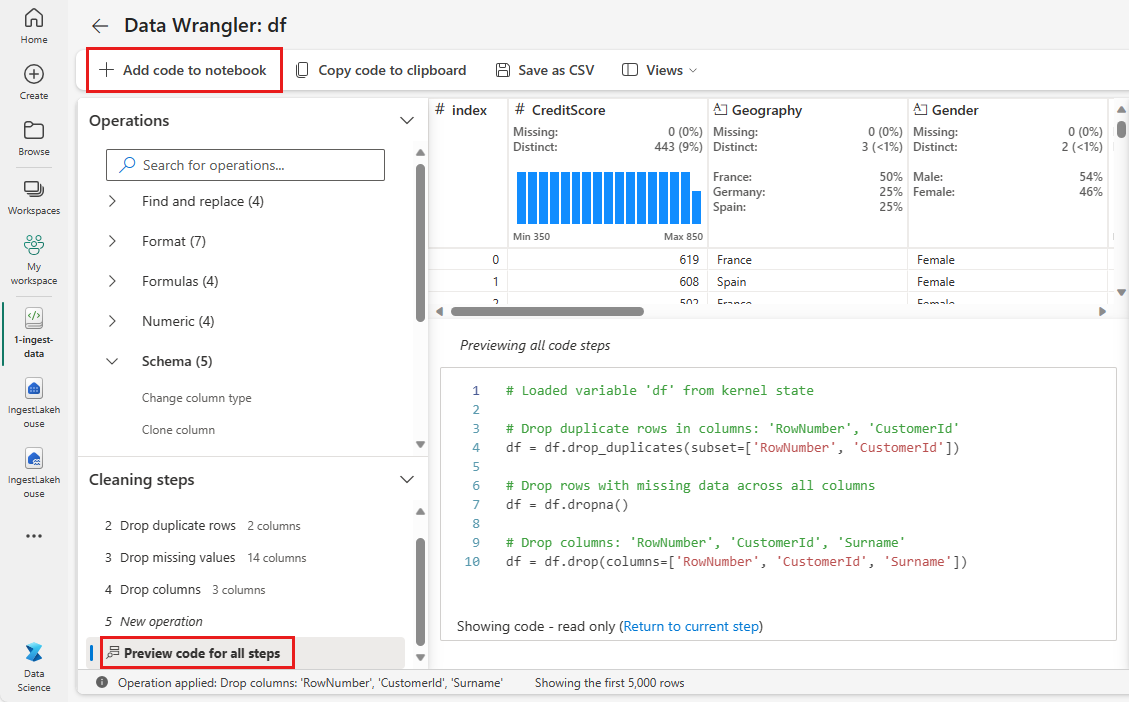
Her Uygulaseçtiğinizde, sol altta bulunan Temizleme adımları panelinde yeni bir adım oluşturulur. Panelin en altında, tüm ayrı adımların birleşimini görüntülemek tüm adımlar için Önizleme kodu'nu seçin.
Data Wrangler'ı kapatmak ve kodu otomatik olarak eklemek için sol üstteki Not defterine kod ekle seçin. Deftere Kod Ekle kodu bir fonksiyona sarar ve fonksiyonu çağırır.
İpucu
Yeni hücreyi el ile çalıştırmadığınız sürece Data Wrangler tarafından oluşturulan kod uygulanmaz.
Data Wrangler kullanmadıysanız, bunun yerine bu sonraki kod hücresini kullanabilirsiniz.
Bu kod, Data Wrangler tarafından üretilen koda benzer, ancak oluşturulan adımların her birine inplace=True bağımsız değişkenini ekler.
inplace=Truedeğerini ayarlayarak, Pandas çıkış olarak yeni bir DataFrame oluşturmak yerine özgün DataFrame'in üzerine yazar.
# Modified version of code generated by Data Wrangler
# Modification is to add in-place=True to each step
# Define a new function that include all above Data Wrangler operations
def clean_data(df):
# Drop rows with missing data across all columns
df.dropna(inplace=True)
# Drop duplicate rows in columns: 'RowNumber', 'CustomerId'
df.drop_duplicates(subset=['RowNumber', 'CustomerId'], inplace=True)
# Drop columns: 'RowNumber', 'CustomerId', 'Surname'
df.drop(columns=['RowNumber', 'CustomerId', 'Surname'], inplace=True)
return df
df_clean = clean_data(df.copy())
df_clean.head()
Verileri keşfetme
Temizlenen verilerin bazı özetlerini ve görselleştirmelerini görüntüleyin.
Kategorik, sayısal ve hedef öznitelikleri belirleme
Kategorik, sayısal ve hedef öznitelikleri belirlemek için bu kodu kullanın.
# Determine the dependent (target) attribute
dependent_variable_name = "Exited"
print(dependent_variable_name)
# Determine the categorical attributes
categorical_variables = [col for col in df_clean.columns if col in "O"
or df_clean[col].nunique() <=5
and col not in "Exited"]
print(categorical_variables)
# Determine the numerical attributes
numeric_variables = [col for col in df_clean.columns if df_clean[col].dtype != "object"
and df_clean[col].nunique() >5]
print(numeric_variables)
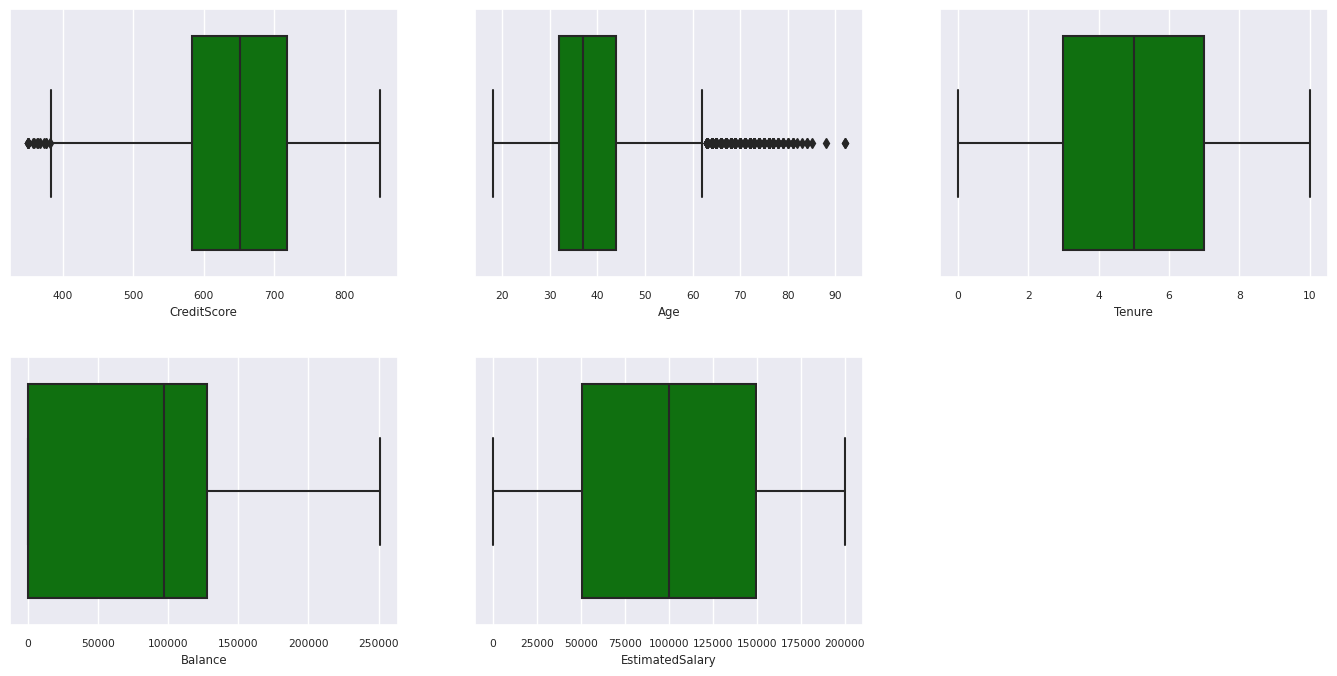
Beş sayıdan oluşan istatistik özeti
Kutu çizimlerini kullanarak sayısal öznitelikler için beş sayılık özeti (en düşük puan, ilk dörttebirlik, ortanca, üçüncü dörttebirlik, en yüksek puan) gösterin.
df_num_cols = df_clean[numeric_variables]
sns.set(font_scale = 0.7)
fig, axes = plt.subplots(nrows = 2, ncols = 3, gridspec_kw = dict(hspace=0.3), figsize = (17,8))
fig.tight_layout()
for ax,col in zip(axes.flatten(), df_num_cols.columns):
sns.boxplot(x = df_num_cols[col], color='green', ax = ax)
fig.delaxes(axes[1,2])
Çıkış yapan ve yapmayan müşterilerin dağıtımı
Kategorik öznitelikler arasında çıkış yapılan ve çıkarılmış olmayan müşterilerin dağılımını gösterin.
df_clean['Exited'] = df_clean['Exited'].astype(str)
attr_list = ['Geography', 'Gender', 'HasCrCard', 'IsActiveMember', 'NumOfProducts', 'Tenure']
df_clean['Exited'] = df_clean['Exited'].astype(str)
fig, axarr = plt.subplots(2, 3, figsize=(15, 4))
for ind, item in enumerate (attr_list):
print(ind, item)
sns.countplot(x = item, hue = 'Exited', data = df_clean, ax = axarr[ind%2][ind//2])
fig.subplots_adjust(hspace=0.7)
df_clean['Exited'] = df_clean['Exited'].astype(int)

Sayısal özniteliklerin dağılımı
Histogram kullanarak sayısal özniteliklerin sıklık dağılımını gösterin.
columns = df_num_cols.columns[: len(df_num_cols.columns)]
fig = plt.figure()
fig.set_size_inches(18, 8)
length = len(columns)
for i,j in itertools.zip_longest(columns, range(length)):
plt.subplot((length // 2), 3, j+1)
plt.subplots_adjust(wspace = 0.2, hspace = 0.5)
df_num_cols[i].hist(bins = 20, edgecolor = 'black')
plt.title(i)
plt.show()

Özellik mühendisliği gerçekleştirme
Geçerli öznitelikleri temel alan yeni öznitelikler oluşturmak için özellik mühendisliği gerçekleştirin:
df_clean['Tenure'] = df_clean['Tenure'].astype(int)
df_clean["NewTenure"] = df_clean["Tenure"]/df_clean["Age"]
df_clean["NewCreditsScore"] = pd.qcut(df_clean['CreditScore'], 6, labels = [1, 2, 3, 4, 5, 6])
df_clean["NewAgeScore"] = pd.qcut(df_clean['Age'], 8, labels = [1, 2, 3, 4, 5, 6, 7, 8])
df_clean["NewBalanceScore"] = pd.qcut(df_clean['Balance'].rank(method="first"), 5, labels = [1, 2, 3, 4, 5])
df_clean["NewEstSalaryScore"] = pd.qcut(df_clean['EstimatedSalary'], 10, labels = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
Veri Wrangler'ı kullanarak one-hot kodlama gerçekleştirin
Veri Wrangler, tekil sıcak kodlama gerçekleştirmek için de kullanılabilir. Bunu yapmak için Data Wrangler'ı yeniden açın. Bu kez df_clean verilerini seçin.
- Formüller genişletin ve One-hot encodeöğesini seçin.
- "Bir one-hot encoding gerçekleştirmek istediğiniz sütunların listesini seçmeniz için bir panel görüntülenir." Coğrafya ve Cinsiyetseçin.
Oluşturulan kodu kopyalayabilir, not defterine dönmek için Data Wrangler'ı kapatabilir ve ardından yeni bir hücreye yapıştırabilirsiniz. Alternatif olarak, Data Wrangler'ı kapatmak ve kodu otomatik olarak eklemek için sol üstteki Not defterine kod ekle seçeneğini seçin.
Data Wrangler kullanmadıysanız, bunun yerine bu sonraki kod hücresini kullanabilirsiniz:
# This is the same code that Data Wrangler will generate
import pandas as pd
def clean_data(df_clean):
# One-hot encode columns: 'Geography', 'Gender'
for column in ['Geography', 'Gender']:
insert_loc = df_clean.columns.get_loc(column)
df_clean = pd.concat([df_clean.iloc[:,:insert_loc], pd.get_dummies(df_clean.loc[:, [column]]), df_clean.iloc[:,insert_loc+1:]], axis=1)
return df_clean
df_clean_1 = clean_data(df_clean.copy())
df_clean_1.head()
# This is the same code that Data Wrangler will generate
import pandas as pd
def clean_data(df_clean):
# One-hot encode columns: 'Geography', 'Gender'
df_clean = pd.get_dummies(df_clean, columns=['Geography', 'Gender'])
return df_clean
df_clean_1 = clean_data(df_clean.copy())
df_clean_1.head()
Keşif veri analizinden gözlemlerin özeti
- Müşterilerin çoğu Fransa'dan İspanya ve Almanya'ya göre, İspanya ise Fransa ve Almanya'ya kıyasla en düşük değişim oranına sahip.
- Müşterilerin çoğunun kredi kartı var.
- Yaş ve kredi puanı sırasıyla 60'ın üzerinde ve 400'in altında olan müşteriler vardır, ancak aykırı değer olarak düşünülemezler.
- Çok az müşteri bankanın ikiden fazla ürününe sahip.
- Etkin olmayan müşterilerin değişim sıklığı daha yüksektir.
- Cinsiyet ve görev süresi yıllarının müşterinin banka hesabını kapatma kararı üzerinde bir etkisi yok gibi görünüyor.
Temizlenen veriler için delta tablosu oluşturma
Bu verileri bu serinin sonraki not defterinde kullanacaksınız.
table_name = "df_clean"
# Create Spark DataFrame from pandas
sparkDF=spark.createDataFrame(df_clean_1)
sparkDF.write.mode("overwrite").format("delta").save(f"Tables/{table_name}")
print(f"Spark dataframe saved to delta table: {table_name}")
Sonraki adım
Makine öğrenmesi modellerini şu verilerle eğitin ve kaydedin:
Bölüm 3: makine öğrenmesi modellerinieğitme ve kaydetme.