Automated backups for Hyperscale databases
Applies to: ![]() Azure SQL Database
Azure SQL Database
This article explains the automated backup feature with Hyperscale databases in Azure SQL Database.
Hyperscale databases use a unique architecture with highly scalable storage and compute performance tiers. Hyperscale backups are snapshot-based and are nearly instantaneous. Log backups are stored in long-term Azure storage for the backup retention period.
A Hyperscale architecture doesn't require full, differential, or log backups. As such, backup frequency, storage costs, scheduling, storage redundancy, and restore capabilities differ from other databases in Azure SQL Database.
Backup and restore performance
Storage and compute separation enables Hyperscale to push down backup and restore operations to the storage layer to eliminate resource consumption on compute replicas. Database backups don't affect the performance of either primary or secondary compute replicas.
Backup and restore operations for Hyperscale databases are fast regardless of data size, because they use storage snapshots. Backup is virtually instantaneous.
You can restore a database to any point in time within its backup retention period by:
- Reverting to applicable file snapshots.
- Applying transaction logs to make the restored database transactionally consistent.
As such, restore isn't a size-of-data operation that remains the same. Restore of a Hyperscale database within the same Azure region finishes in minutes instead of hours or days, even for multi-terabyte databases.
Changing the storage redundancy when issuing a restore can result in longer restore times as the restore is the size of data, and hence the time is proportional to the database size.
Creating new databases by restoring an existing backup or copying the database, also takes advantage of compute and storage separation in Hyperscale. You can create copies for development or testing purposes, even of multi-terabyte databases, in minutes within the same region when you use the same storage type.
Backup retention
The default short-term retention of backups for Hyperscale databases is 7 days.
Short-term retention of backups in the range of 1 to 35 days and long-term backup retention (LTR) capability for Hyperscale databases is generally available, as of September 2023. For more information, see Long-term retention - Azure SQL Database and Azure SQL Managed Instance.
Backup scheduling
There are no traditional full, differential, and transaction log backups for Hyperscale databases. Instead, regular storage snapshots of data files are taken.
The generated transaction logs are retained as is for the configured retention period. At restore time, relevant transaction log records are applied to the restored storage snapshot. The result is a transactionally consistent database without any data loss as of the specified point in time within the retention period.
Monitor backup storage consumption
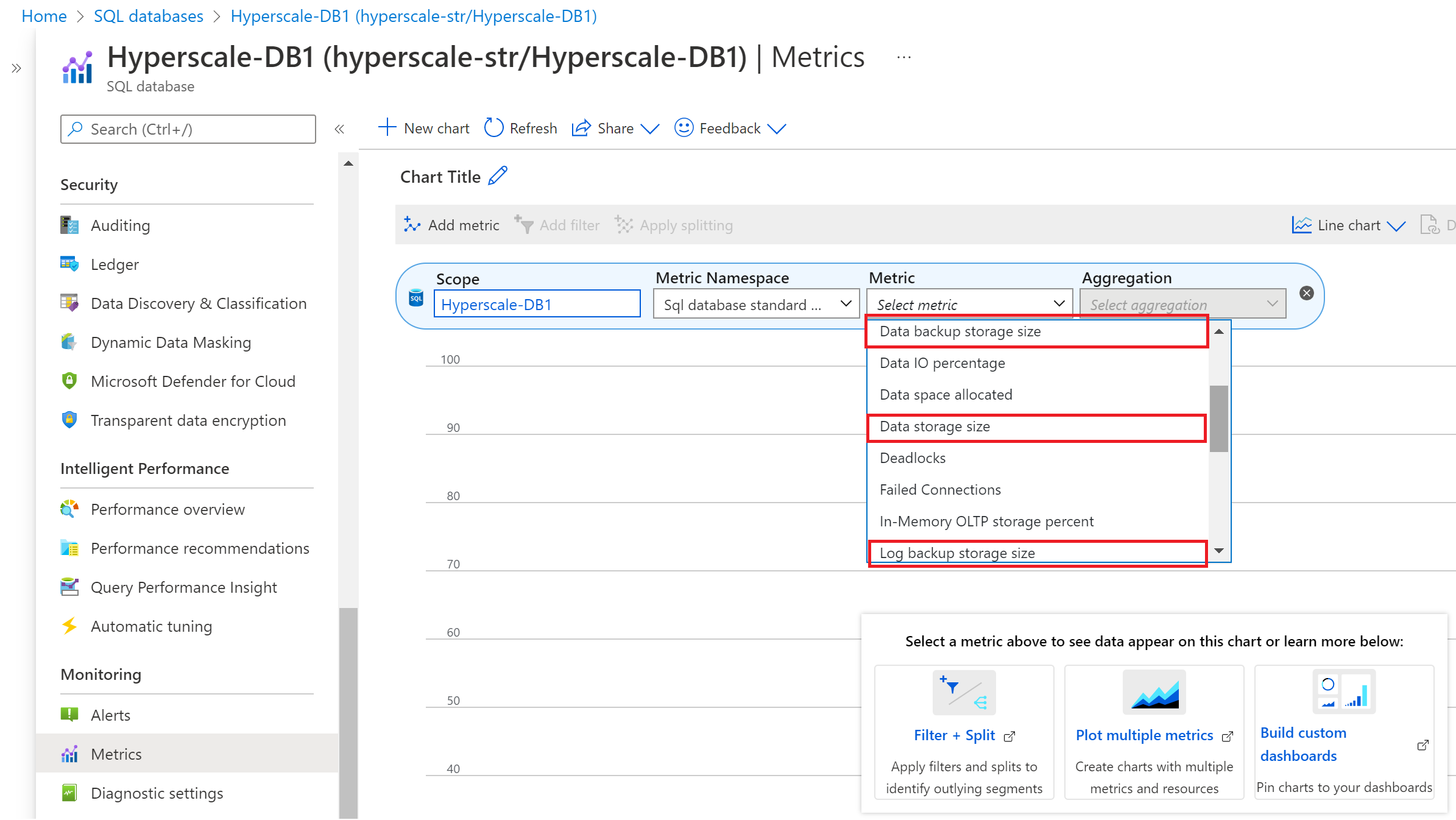
In Hyperscale, Azure Monitor metrics report the following consumption information:
- Data backup storage size (snapshot backup size)
- Data storage size (allocated database size)
- Log backup storage size (transaction log backup size)
To view backup and data storage metrics in the Azure portal, follow these steps:
- Go to the Hyperscale database for which you want to monitor backup and data storage metrics.
- In the Monitoring section, select the Metrics page.
- From the Metric dropdown list, select the Data backup storage, Data storage size, and Log backup storage metrics with an appropriate aggregation rule.
Reduce backup storage consumption
Backup storage consumption for a Hyperscale database depends on the retention period, choice of region, backup storage redundancy, and workload type. Consider some of the following tuning techniques to reduce your backup storage consumption for a Hyperscale database:
- Reduce the backup retention period to the minimum for your needs.
- Avoid doing large write operations, such as index maintenance, more frequently than you need to. For index maintenance recommendations, see Optimize index maintenance to improve query performance and reduce resource consumption.
- For large data-load operations, consider using data compression when appropriate.
- Use the
tempdbdatabase instead of permanent tables in your application logic to store temporary results and/or transient data. - Use locally redundant or zone-redundant backup storage when geo-restore capability is unnecessary (for example, dev/test environments).
Backup storage costs
Hyperscale backup storage cost depends on the choice of region and backup storage redundancy. It also depends on the workload type.
Write-heavy workloads are more likely to change data pages frequently, which results in larger storage snapshots. Such workloads also generate more transaction logs, contributing to the overall backup costs. Backup storage is charged based on gigabytes consumed per month. For pricing details, see the Azure SQL Database pricing page.
For Hyperscale, billable backup storage is calculated as follows:
Total billable backup storage size = (data backup storage size + log backup storage size)
Data storage size isn't included in the billable backup because it's already billed as allocated database storage.
Deleted Hyperscale databases incur backup costs to support recovery to a point in time before deletion. For a deleted Hyperscale database, billable backup storage is calculated as follows:
Total billable backup storage size for deleted Hyperscale database = (data storage size + data backup size + log backup storage size) * (remaining backup retention period after deletion / configured backup retention period)
Data storage size is included in the formula because allocated database storage isn't billed separately for a deleted database. For a deleted database, data is stored after deletion to enable recovery during the configured backup retention period.
Billable backup storage for a deleted database reduces gradually over time after it's deleted. It becomes zero when backups are no longer retained, and then recovery is no longer possible. If it's a permanent deletion and you no longer need backups, you can optimize costs by reducing retention before deleting the database.
Monitor backup costs
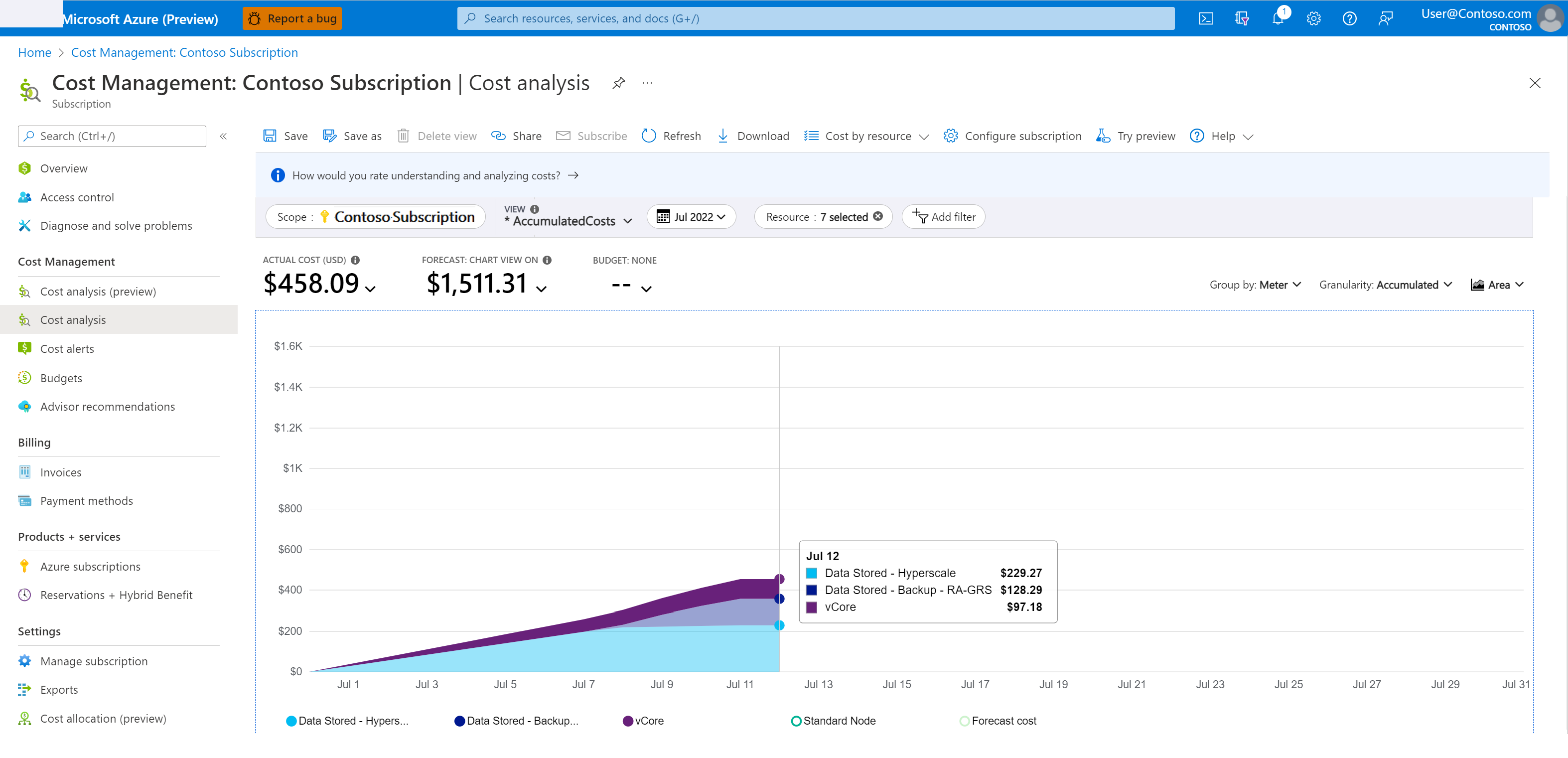
To understand backup storage costs:
In the Azure portal, go to Cost Management + Billing.
Select Cost Management > Cost analysis.
For Scope, select the desired subscription.
Filter for the time period and service you're interested in by following these steps:
- Add a filter for Service name.
- Choose sql-database from the dropdown list.
- Add another filter for Meter.
- To monitor backup costs for point-in-time recovery, select Data Stored - Backup - RA from the dropdown list.
The following screenshot shows an example cost analysis.
Data and backup storage redundancy
Hyperscale supports configurable storage redundancy. When you're creating a Hyperscale database, you can choose your preferred storage type: read-access geo-zone-redundant storage (RA-GZRS), read-access geo-redundant storage (RA-GRS), zone-redundant storage (ZRS), or locally redundant storage (LRS).
- Geo-zone-redundant storage: Copies your backups synchronously across three Azure availability zones in the primary region. similar to zone-redundant storage(ZRS). In addition, it copies your data asynchronously to a single physical location in the paired secondary region. It's currently available in only certain regions.
For more information about how the backups are replicated for other storage types, see backup storage redundancy.
Since Hyperscale uses storage snapshots for backups, data and backups share the same storage account. As a result, the selected backup storage redundancy is applicable for both data and backups.
Note
Consider backup storage redundancy carefully when you create a Hyperscale database, because you can set it only during database creation. You can't modify this setting after the resource is provisioned.
Use active geo-replication to update backup storage redundancy settings for an existing Hyperscale database with minimum downtime. Alternatively, you can use database copy.
Warning
- Geo-restore is disabled as soon as a database is updated to use locally redundant or zone-redundant storage.
- Zone-redundant storage is currently available in only certain regions.
- Geo-zone-redundant storage is currently available in only certain regions.
Restore a Hyperscale database to a different region
You might need to restore your Hyperscale database to a region that's different from the current region. Common reasons include a disaster recovery operation or drill, or a relocation. The primary method is to do a geo-restore of the database. You use the same steps that you would use to restore any other database in Azure SQL Database to a different region:
- Create a server in the target region if you don't already have an appropriate server there. This server should be owned by the same subscription as the original (source) server.
- Follow the instructions in the geo-restore section of the page on restoring a database in Azure SQL Database from automatic backups.
Note
Because the source and target are in separate regions, the database can't share snapshot storage with the source database as it does in non-geo restores. Non-geo restores finish quickly regardless of database size.
A geo-restore of a Hyperscale database is a size-of-data operation, even if the target is in the paired region of the geo-replicated storage. Therefore, a geo-restore will take a significantly longer time compared to a point-in-time restore in the same region.
If the target is in the paired region, data transfer will be within a region. That transfer will be significantly faster than a cross-region data transfer. But it will still be a size-of-data operation.
If you prefer, you can copy the database to a different region. Use this method if geo-restore isn't available because it's not supported with the selected storage redundancy type. For details, see Database copy for Hyperscale.
Related content
Database backups are an essential part of any business continuity and disaster recovery strategy because they help protect your data from accidental corruption or deletion.