你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
训练是模型从标记的数据进行学习的过程。 完成训练后,可通过查看模型的性能来确定是否需要改进模型。
若要训练模型,请启动训练作业。 只有已成功完成的作业才能创建可用模型。 训练作业在七天后过期。 在此时间段之后,将无法检索作业详细信息。 如果成功完成训练作业并创建了模型,则作业过期不会影响该模型。 你在同一时间只能有一个训练作业处于运行状态,并且无法在同一项目中启动其他作业。
处理少量文档时,训练时间可从几分钟到几小时不等,具体取决于数据集大小和架构的复杂性。
先决条件
在训练模型之前,需要:
有关详细信息,请参阅项目开发生命周期。
数据拆分
开始训练过程之前,项目中标记的文档会划分为训练集和测试集。 其中的每一个都有不同的功能。 训练集用于训练模型,这是模型从中学习分配给每个文档的类的集合。 测试集是一个盲集,它不是在训练期间引入到模型的,而是在评估期间引入的。 成功训练模型后,它将用于根据测试集中的文档进行预测。 根据这些预测,将会计算模型的评估指标。 建议确保所有类在训练集和测试集中均已充分表示。
自定义文本分类支持两种数据拆分方法:
- 自动从训练数据拆分测试集:系统将根据所选百分比将标记的数据拆分为训练集和测试集。 系统将尝试表示训练集中的所有类。 建议的拆分百分比为 80% 用于训练,20% 用于测试。
注意
如果选择“自动从训练数据拆分测试集”选项,则只有分配给训练集的数据会按照提供的百分比拆分。
- 使用手动拆分训练和测试数据:此方法使用户能够定义标记的文档应分别属于哪个集合。 仅当在数据标记期间已将文档添加到测试集时,才会启用此步骤。
定型模型
若要在 Language Studio 中开始训练模型,请执行以下操作:
在左侧菜单中,选择“训练作业”。
从顶部菜单中选择“启动训练作业”。
然后选择“训练新模型”并在文本框中键入模型名称。 还可以通过选择“覆盖现有模型”选项并从下拉菜单中选择要覆盖的模型来覆盖现有模型。 覆盖已训练的模型是不可逆的,但这在部署新模型之前不会影响已部署的模型。
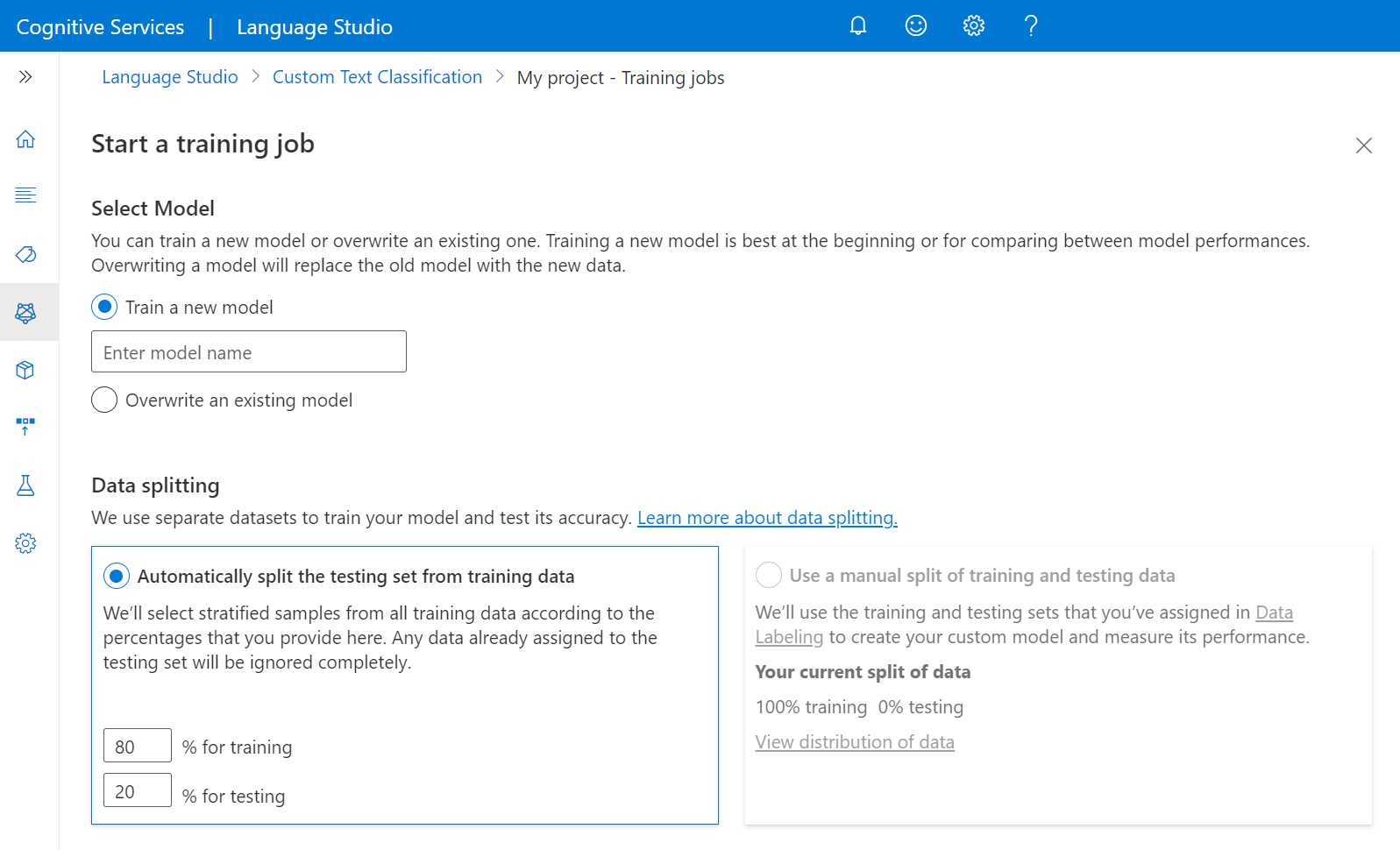
选择数据拆分方法。 可以选择“从训练数据中自动拆分测试集”,系统将根据指定的百分比在训练集和测试集之间拆分标记数据。 也可以选择“使用手动拆分训练和测试数据”,仅当在数据标记期间已将文档添加到测试集时才会启用此选项。 有关数据拆分的详细信息,请参阅如何训练模型。
选择“训练”按钮。
如果从列表中选择训练作业 ID,则会显示一个侧窗格,可在其中检查此作业的“训练进度”、“作业状态”和其他详细信息。
注意
- 只有成功完成的训练作业才会生成模型。
- 训练模型所需的时间可能在几分钟到几个小时之间,具体取决于你标记的数据的大小。
- 一次只能运行一个训练作业。 在运行的作业完成之前,无法在同一项目中启动其他训练作业。

取消训练作业
要在 Language Studio 中取消训练作业,请转到“训练作业”页。 选择要取消的训练作业,然后选择顶部菜单中的“取消”。
后续步骤
完成训练后,将能够查看模型的性能,并可以根据需要选择改进模型。 对模型感到满意后,就可以部署模型,使其可用于对文本进行分类。