你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
本文介绍如何以定量方式度量和提高基础语音转文本模型或你自己的自定义模型的准确度。 测试准确性需要音频 + 人工标记的听录内容数据。 应提供 30 分钟到 5 小时的代表性音频。
重要
测试时,系统将执行听录。 请务必记住这一点,因为定价因服务产品和订阅级别而异。 请务必参阅官方 Azure AI 服务定价获取最新详细信息。
创建测试
可以通过创建测试来测试自定义模型的准确性。 测试需要一系列音频文件及其相应的听录内容。 可以比较自定义模型、语音转文本基础模型或其他自定义模型的准确度。 获取测试结果后,对比语音识别结果评估单词错误率 (WER)。
上传训练和测试数据集后,可以创建测试。
若要测试微调的自定义语音模型,请执行以下步骤:
从左窗格中选择 “微调 ”,然后选择 “AI 服务微调”。
选择自定义语音识别微调任务(按模型名称),该任务是你按照“如何启动自定义语音识别微调”一文中所述启动的。
选择 “测试模型>+ 创建测试”。
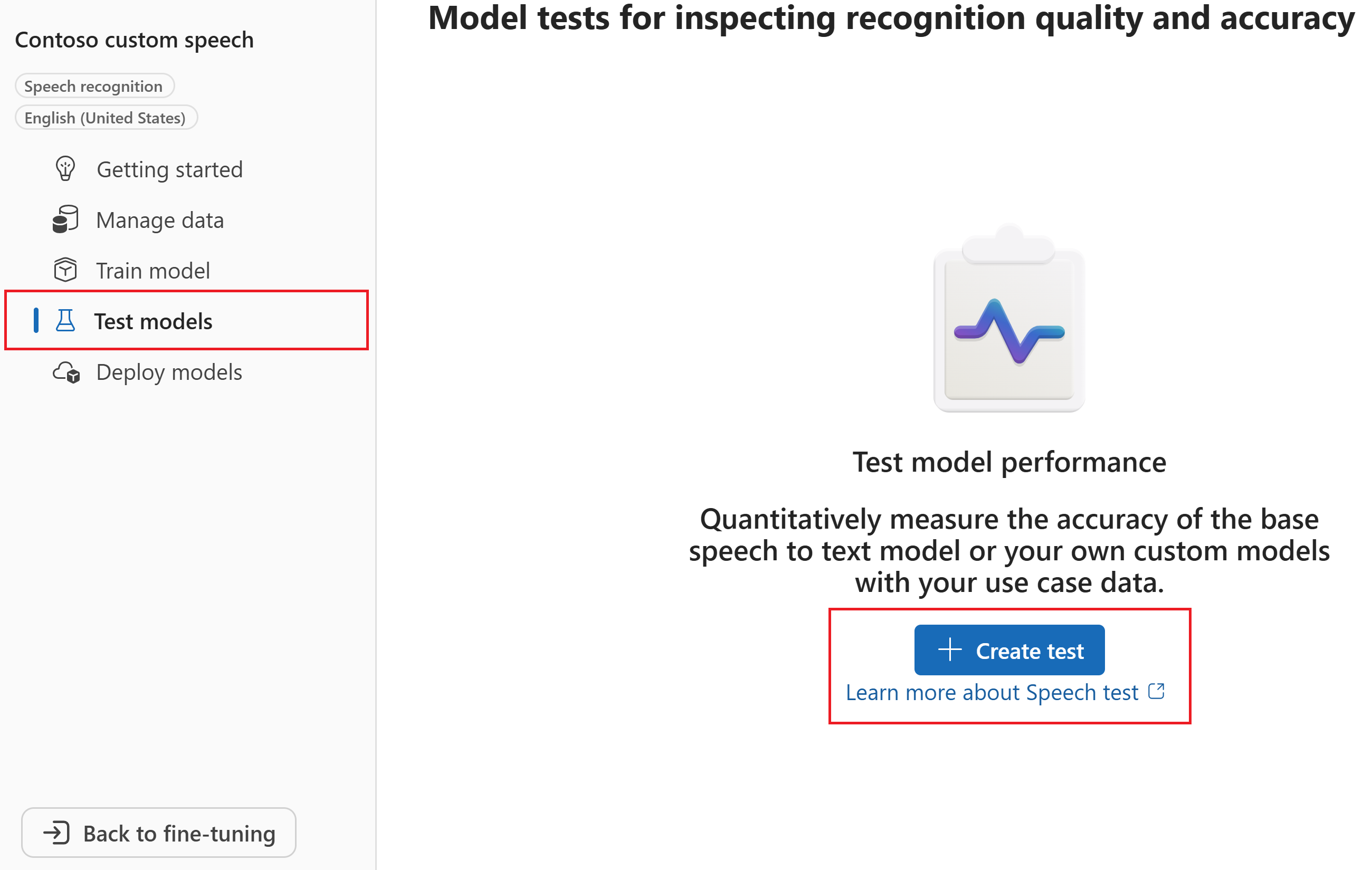
在“创建新测试”向导中选择测试类型。 对于准确性(定量)测试,请选择“评估准确性”(音频 + 脚本数据)。 然后选择下一步。
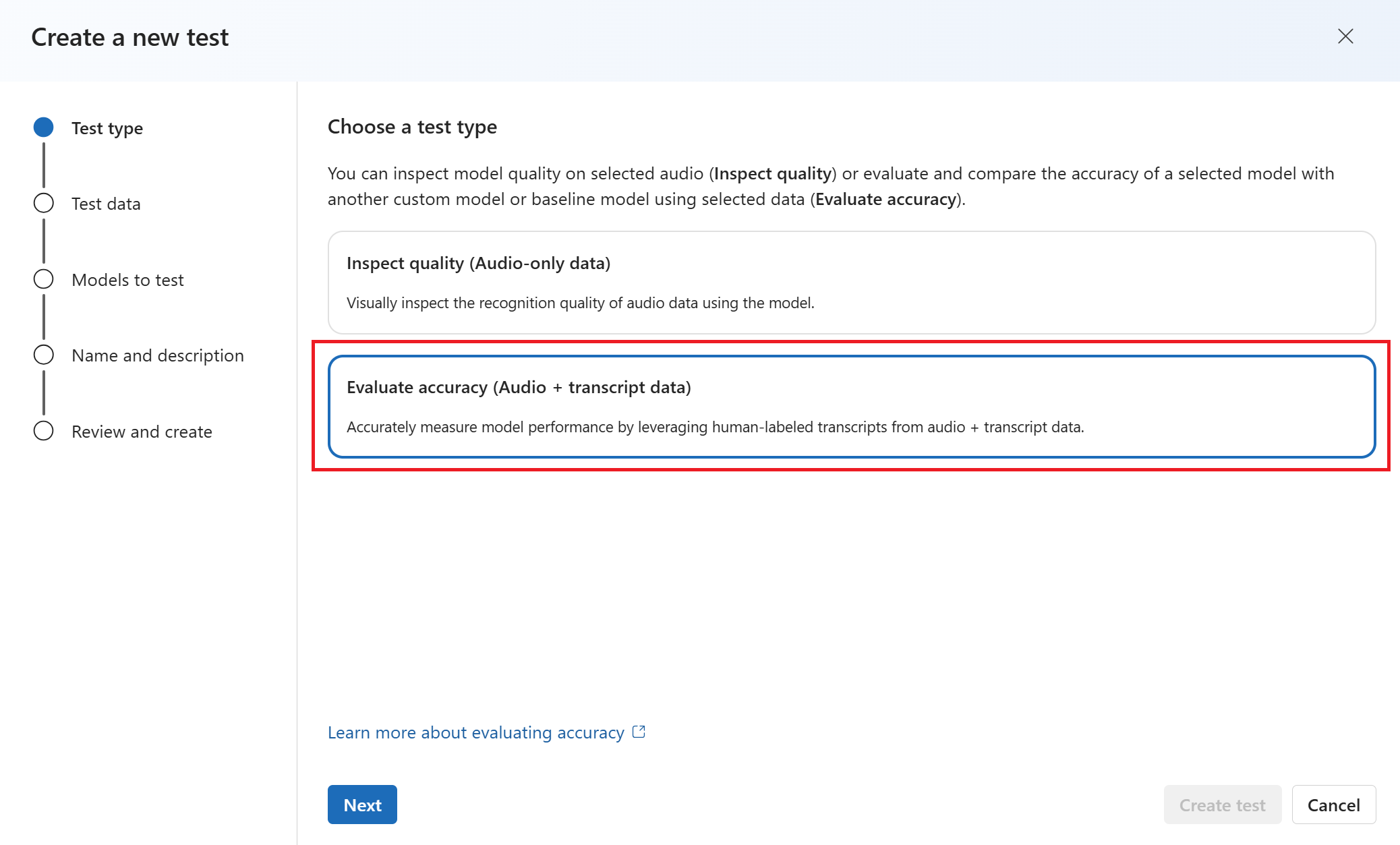
选择要用于测试的数据。 然后选择下一步。
选择最多两个模型来评估和比较准确度。 在此示例中,我们选择了已训练的模型和基础模型。 然后选择下一步。
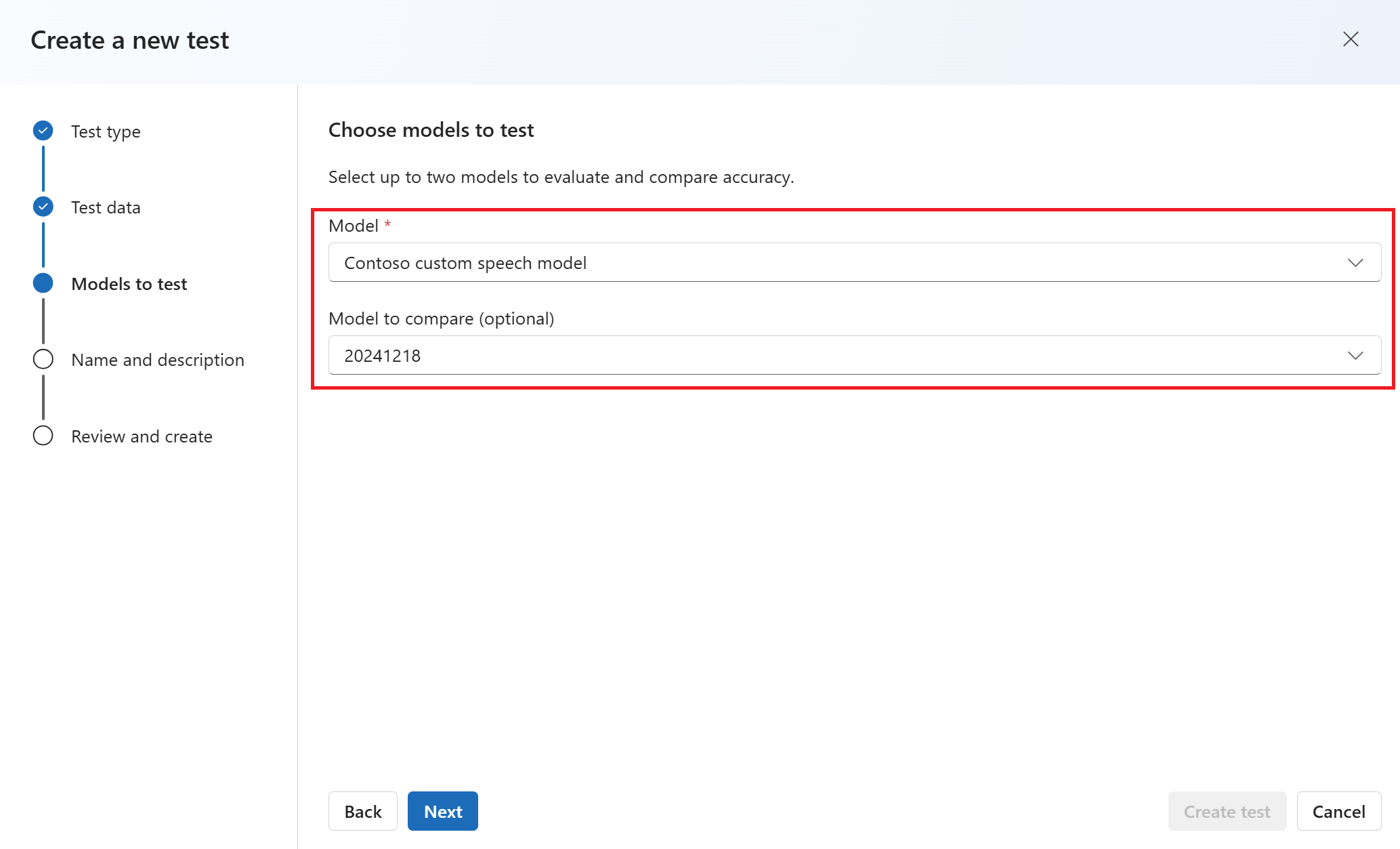
输入测试的名称和说明。 然后选择下一步。
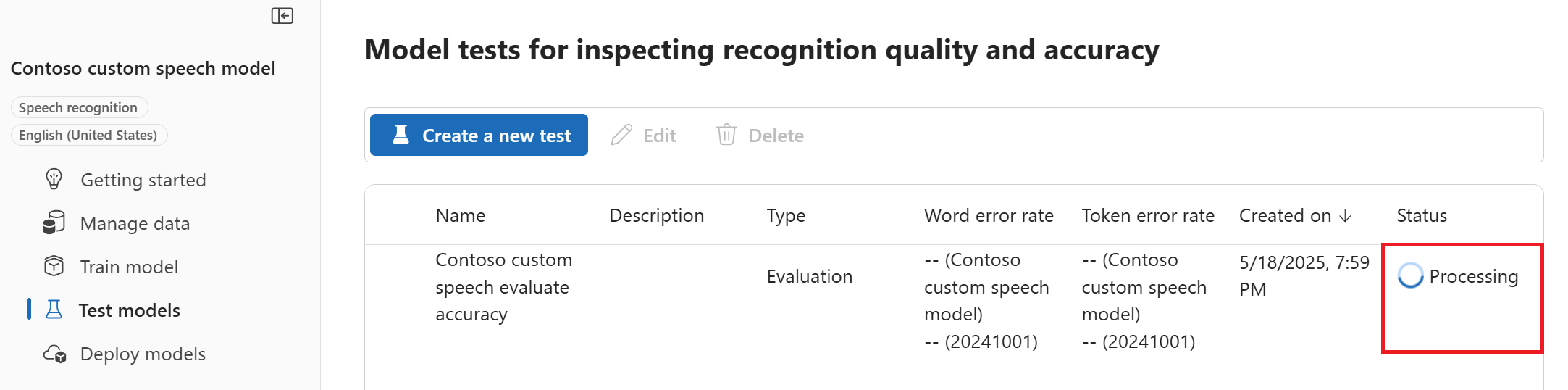
查看设置,然后选择“创建测试”。 随后你将返回到“测试模型”页面。 数据状态为“正在处理”。




按照以下步骤创建准确性测试:
登录 Speech Studio。
选择“自定义语音识别” 你的项目名称 >“测试模型”。>
选择“创建新测试”。
选择“评估准确度”“下一步”。
选择一个音频 + 人为标记的听录内容数据集,然后选择“下一步”。 如果没有任何可用的数据集,请取消设置,然后转到“语音数据集”菜单来上传数据集。
注意
选择的声学数据集必须不同于你对自己的模型使用的数据集。 此方法可以提供真正有意义的模型性能。
选择最多两个要评估的模型,然后选择“下一步”。
输入测试名称和描述,然后选择“下一步”。
查看测试详细信息,然后选择“保存并关闭”。
若要创建测试,请使用 spx csr evaluation create 命令。 根据以下说明构造请求参数:
- 将
project属性设置为现有项目的 ID。 建议使用此属性,以便还可以在 Azure AI Foundry 门户中查看测试。 可以运行spx csr project list命令来获取可用项目。 - 将所需
model1属性设置为要测试的模型的 ID。 - 将所需
model2属性设置为要测试的另一个模型的 ID。 如果不想比较两个模型,请同时对model1和model2使用相同的模型。 - 将所需
dataset属性设置为要用于测试的数据集的 ID。 - 设置
language属性,否则 Speech CLI 将默认设置为“en-US”。 此参数应该是数据集内容的区域设置。 以后无法更改此区域设置。 语音 CLIlanguage属性对应于 JSON 请求和响应中的locale属性。 - 设置所需的
name属性。 此参数是在 Azure AI Foundry 门户中显示的名称。 语音 CLIname属性对应于 JSON 请求和响应中的displayName属性。
下面是创建测试的语音 CLI 命令的示例:
spx csr evaluation create --api-version v3.2 --project 0198f569-cc11-4099-a0e8-9d55bc3d0c52 --dataset 23b6554d-21f9-4df1-89cb-f84510ac8d23 --model1 ff43e922-e3e6-4bf0-8473-55c08fd68048 --model2 13fb305e-09ad-4bce-b3a1-938c9124dda3 --name "My Evaluation" --description "My Evaluation Description"
你应该会收到以下格式的响应正文:
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/dda6e880-6ccd-49dc-b277-137565cbaa38",
"model1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"model2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"dataset": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/23b6554d-21f9-4df1-89cb-f84510ac8d23"
},
"transcription2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"transcription1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
"links": {
"files": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/dda6e880-6ccd-49dc-b277-137565cbaa38/files"
},
"properties": {
"wordErrorRate1": -1.0,
"sentenceErrorRate1": -1.0,
"sentenceCount1": -1,
"wordCount1": -1,
"correctWordCount1": -1,
"wordSubstitutionCount1": -1,
"wordDeletionCount1": -1,
"wordInsertionCount1": -1,
"wordErrorRate2": -1.0,
"sentenceErrorRate2": -1.0,
"sentenceCount2": -1,
"wordCount2": -1,
"correctWordCount2": -1,
"wordSubstitutionCount2": -1,
"wordDeletionCount2": -1,
"wordInsertionCount2": -1
},
"lastActionDateTime": "2024-07-14T21:31:14Z",
"status": "NotStarted",
"createdDateTime": "2024-07-14T21:31:14Z",
"locale": "en-US",
"displayName": "My Evaluation",
"description": "My Evaluation Description",
"customProperties": {
"testingKind": "Evaluation"
}
}
响应正文中的顶级 self 属性是评估的 URI。 使用此 URI 获取有关项目和测试结果的详细信息。 还可以使用此 URI 更新或删除评估。
对于评估的语音 CLI 帮助,请运行以下命令:
spx help csr evaluation
要创建测试,请使用语音转文本 REST API 的 Evaluations_Create 操作。 根据以下说明构造请求正文:
- 将
project属性设置为现有项目的 URI。 建议使用此属性,以便还可以在 Azure AI Foundry 门户中查看测试。 可以发出 Projects_List 请求来获取可用项目。 - 在
testingKind内将Evaluation属性设置为customProperties。 如果未指定Evaluation,则该测试将被视为质量检查测试。 无论是否将testingKind属性设置为Evaluation或Inspection,还是未设置,都可以通过 API 访问准确性分数,但无法在Azure AI Foundry门户中访问。 - 将所需的
model1属性设置为要测试的模型的 URI。 - 将所需的
model2属性设置为要测试的另一个模型的 URI。 如果不想比较两个模型,请同时对model1和model2使用相同的模型。 - 将所需的
dataset属性设置为要用于测试的数据集的 URI。 - 设置所需的
locale属性。 此属性应该是数据集内容的区域设置。 以后无法更改此区域设置。 - 设置所需的
displayName属性。 此属性是在 Azure AI Foundry 门户中显示的名称。
使用 URI 发出 HTTP POST 请求,如以下示例所示。 将 YourSpeechResoureKey 替换为语音资源密钥,将 YourServiceRegion 替换为语音资源区域,并按前面所述设置请求正文属性。
curl -v -X POST -H "Ocp-Apim-Subscription-Key: YourSpeechResoureKey" -H "Content-Type: application/json" -d '{
"model1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"model2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"dataset": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/23b6554d-21f9-4df1-89cb-f84510ac8d23"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
"displayName": "My Evaluation",
"description": "My Evaluation Description",
"customProperties": {
"testingKind": "Evaluation"
},
"locale": "en-US"
}' "https://YourServiceRegion.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations"
你应该会收到以下格式的响应正文:
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/dda6e880-6ccd-49dc-b277-137565cbaa38",
"model1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"model2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"dataset": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/23b6554d-21f9-4df1-89cb-f84510ac8d23"
},
"transcription2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"transcription1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
"links": {
"files": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/dda6e880-6ccd-49dc-b277-137565cbaa38/files"
},
"properties": {
"wordErrorRate1": -1.0,
"sentenceErrorRate1": -1.0,
"sentenceCount1": -1,
"wordCount1": -1,
"correctWordCount1": -1,
"wordSubstitutionCount1": -1,
"wordDeletionCount1": -1,
"wordInsertionCount1": -1,
"wordErrorRate2": -1.0,
"sentenceErrorRate2": -1.0,
"sentenceCount2": -1,
"wordCount2": -1,
"correctWordCount2": -1,
"wordSubstitutionCount2": -1,
"wordDeletionCount2": -1,
"wordInsertionCount2": -1
},
"lastActionDateTime": "2024-07-14T21:31:14Z",
"status": "NotStarted",
"createdDateTime": "2024-07-14T21:31:14Z",
"locale": "en-US",
"displayName": "My Evaluation",
"description": "My Evaluation Description",
"customProperties": {
"testingKind": "Evaluation"
}
}
响应正文中的顶级 self 属性是评估的 URI。 使用此 URI 获取有关评估的项目和测试结果的详细信息。 还可以使用此 URI 更新或删除评估。
获取测试结果
你应获取测试结果,并对比语音识别结果评估单词错误率 (WER)。
当测试状态为“成功”时,你可以查看结果。 选择测试以查看结果。
按照以下步骤获取测试结果:
- 登录 Speech Studio。
- 选择“自定义语音识别” 你的项目名称 >“测试模型”。>
- 按测试名称选择链接。
- 测试完成后,状态设置为“成功”指示,应会看到包含每个测试模型的 WER 数字的结果。
此页面会列出数据集中的所有语句和识别结果,以及提供的数据集中的听录。 可以切换各种错误类型,包括插入、删除和替换。 通过听音频并比较每个列中的识别结果,你可以确定哪个模型符合自己的需求,以及确定需要在哪些方面进行更多的训练和改进。
若要获取测试结果,请使用 spx csr evaluation status 命令。 根据以下说明构造请求参数:
- 将所需的
evaluation属性设置为想要获取测试结果的评估的 ID。
下面是获取测试结果的语音 CLI 命令示例:
spx csr evaluation status --api-version v3.2 --evaluation 8bfe6b05-f093-4ab4-be7d-180374b751ca
单词错误率和更多详细信息将在响应正文中返回。
你应该会收到以下格式的响应正文:
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/dda6e880-6ccd-49dc-b277-137565cbaa38",
"model1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"model2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"dataset": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/23b6554d-21f9-4df1-89cb-f84510ac8d23"
},
"transcription2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"transcription1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
"links": {
"files": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/dda6e880-6ccd-49dc-b277-137565cbaa38/files"
},
"properties": {
"wordErrorRate1": 0.028900000000000002,
"sentenceErrorRate1": 0.667,
"tokenErrorRate1": 0.12119999999999999,
"sentenceCount1": 3,
"wordCount1": 173,
"correctWordCount1": 170,
"wordSubstitutionCount1": 2,
"wordDeletionCount1": 1,
"wordInsertionCount1": 2,
"tokenCount1": 165,
"correctTokenCount1": 145,
"tokenSubstitutionCount1": 10,
"tokenDeletionCount1": 1,
"tokenInsertionCount1": 9,
"tokenErrors1": {
"punctuation": {
"numberOfEdits": 4,
"percentageOfAllEdits": 20.0
},
"capitalization": {
"numberOfEdits": 2,
"percentageOfAllEdits": 10.0
},
"inverseTextNormalization": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
},
"lexical": {
"numberOfEdits": 12,
"percentageOfAllEdits": 12.0
},
"others": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
}
},
"wordErrorRate2": 0.028900000000000002,
"sentenceErrorRate2": 0.667,
"tokenErrorRate2": 0.12119999999999999,
"sentenceCount2": 3,
"wordCount2": 173,
"correctWordCount2": 170,
"wordSubstitutionCount2": 2,
"wordDeletionCount2": 1,
"wordInsertionCount2": 2,
"tokenCount2": 165,
"correctTokenCount2": 145,
"tokenSubstitutionCount2": 10,
"tokenDeletionCount2": 1,
"tokenInsertionCount2": 9,
"tokenErrors2": {
"punctuation": {
"numberOfEdits": 4,
"percentageOfAllEdits": 20.0
},
"capitalization": {
"numberOfEdits": 2,
"percentageOfAllEdits": 10.0
},
"inverseTextNormalization": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
},
"lexical": {
"numberOfEdits": 12,
"percentageOfAllEdits": 12.0
},
"others": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
}
}
},
"lastActionDateTime": "2024-07-14T21:31:22Z",
"status": "Succeeded",
"createdDateTime": "2024-07-14T21:31:14Z",
"locale": "en-US",
"displayName": "My Evaluation",
"description": "My Evaluation Description",
"customProperties": {
"testingKind": "Evaluation"
}
}
对于评估的语音 CLI 帮助,请运行以下命令:
spx help csr evaluation
要获取测试结果,首先使用语音转文本 REST API 的 Evaluations_Get 操作。
使用 URI 发出 HTTP GET 请求,如以下示例所示。 将 YourEvaluationId 替换为评估 ID,将 YourSpeechResoureKey 替换为语音资源密钥,将 YourServiceRegion 替换为语音资源区域。
curl -v -X GET "https://YourServiceRegion.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/YourEvaluationId" -H "Ocp-Apim-Subscription-Key: YourSpeechResoureKey"
单词错误率和更多详细信息将在响应正文中返回。
你应该会收到以下格式的响应正文:
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/dda6e880-6ccd-49dc-b277-137565cbaa38",
"model1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"model2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"dataset": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/23b6554d-21f9-4df1-89cb-f84510ac8d23"
},
"transcription2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"transcription1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
"links": {
"files": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/dda6e880-6ccd-49dc-b277-137565cbaa38/files"
},
"properties": {
"wordErrorRate1": 0.028900000000000002,
"sentenceErrorRate1": 0.667,
"tokenErrorRate1": 0.12119999999999999,
"sentenceCount1": 3,
"wordCount1": 173,
"correctWordCount1": 170,
"wordSubstitutionCount1": 2,
"wordDeletionCount1": 1,
"wordInsertionCount1": 2,
"tokenCount1": 165,
"correctTokenCount1": 145,
"tokenSubstitutionCount1": 10,
"tokenDeletionCount1": 1,
"tokenInsertionCount1": 9,
"tokenErrors1": {
"punctuation": {
"numberOfEdits": 4,
"percentageOfAllEdits": 20.0
},
"capitalization": {
"numberOfEdits": 2,
"percentageOfAllEdits": 10.0
},
"inverseTextNormalization": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
},
"lexical": {
"numberOfEdits": 12,
"percentageOfAllEdits": 12.0
},
"others": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
}
},
"wordErrorRate2": 0.028900000000000002,
"sentenceErrorRate2": 0.667,
"tokenErrorRate2": 0.12119999999999999,
"sentenceCount2": 3,
"wordCount2": 173,
"correctWordCount2": 170,
"wordSubstitutionCount2": 2,
"wordDeletionCount2": 1,
"wordInsertionCount2": 2,
"tokenCount2": 165,
"correctTokenCount2": 145,
"tokenSubstitutionCount2": 10,
"tokenDeletionCount2": 1,
"tokenInsertionCount2": 9,
"tokenErrors2": {
"punctuation": {
"numberOfEdits": 4,
"percentageOfAllEdits": 20.0
},
"capitalization": {
"numberOfEdits": 2,
"percentageOfAllEdits": 10.0
},
"inverseTextNormalization": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
},
"lexical": {
"numberOfEdits": 12,
"percentageOfAllEdits": 12.0
},
"others": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
}
}
},
"lastActionDateTime": "2024-07-14T21:31:22Z",
"status": "Succeeded",
"createdDateTime": "2024-07-14T21:31:14Z",
"locale": "en-US",
"displayName": "My Evaluation",
"description": "My Evaluation Description",
"customProperties": {
"testingKind": "Evaluation"
}
}
评估字词错误率 (WER)
用于度量模型准确度的行业标准是误字率 (WER)。 WER 计算在识别过程中标识的错误单词的数量,并将总和除以人工标记的听录中提供的单词总数 (N)。
错误标识的单词分为三个类别:
- 插入 (I):在假设脚本中错误添加的单词
- 删除 (D):在假设脚本中未检测到的单词
- 替换 (S):在引用和假设之间替换的单词
在 Azure AI Foundry 门户和 Speech Studio 中,商会乘以 100,并显示为百分比。 语音 CLI 和 REST API 结果不乘以 100。
$$ WER = {{I+D+S} N}\over\times 100 $$
以下示例显示了与人工标记的听录内容相比的错误识别的单词:

语音识别结果错误如下:
- 插入 (I):添加了单词“a”
- 删除 (D):删除了单词“are”
- 替换 (S):用单词“Jones”代替“John”
上述示例中的单词错误率为 60%。
如果要在本地复制 WER 度量,可使用 NIST 评分工具包 (SCTK) 中的 sclite 工具。
解决错误并降低 WER
可以使用机器识别结果中的 WER 计算来评估与应用、工具或产品配合使用的模型的质量。 WER 为 5-10% 表明质量好,可以使用。 WER 为 20% 可以接受,但可能需要考虑进行更多的训练。 WER 为 30% 或以上表明质量差,需要自定义和训练。
错误的分布情况很重要。 如果遇到许多删除错误,通常是因为音频信号强度弱。 若要解决此问题,需要在收集音频数据时更靠近源。 插入错误意味着音频是在嘈杂环境中记录的,并且可能存在串音,导致识别问题。 如果以人为标记的听录内容或相关文本形式提供特定于领域的术语样本不足,则通常会遇到替换错误。
可以通过分析单个文件来确定存在的错误的类型,以及哪些错误是特定文件独有的。 在文件级别了解问题将有助于你确定改进目标。
评估令牌错误率 (TER)
除了字错误率外,还可以使用令牌错误率 (TER) 的扩展度量来评估最终端到端显示格式的质量。 除了词法格式(That will cost $900. 而不是 that will cost nine hundred dollars),TER 还会考虑标点、大大小写和 ITN 等显示格式方面的因素。 详细了解使用语音转文本进行的显示输出格式设置。
WER 计算在识别过程中标识的错误标记的数量,并将总和除以人工标记的听录中提供的标记总数 (N)。
$$ TER = {{I+D+S} N}\over\times 100 $$
TER 计算的公式也类似于 WER。 唯一的区别是它是基于标记级别而不是单词级别计算 TER。
- 插入 (I):在假设脚本中错误添加的标记
- 删除 (D):在假设脚本中未检测到的标记
- 替换 (S):引用和假设之间替换的标记
在实际情况下,可以分析 WER 和 TER 结果以获取所需的改进。
注意
若要测量 TER,需要确保音频 + 脚本测试数据包含显示格式(例如标点、大小写和 ITN)的脚本。
示例方案结果
语音识别场景因音频质量和语言(词汇和说话风格)而异。 下表考察了四种常见的场景:
| 方案 | 音频质量 | 词汇 | 说话风格 |
|---|---|---|---|
| 呼叫中心 | 低,8 kHz,可以是 1 个音频通道上的 2 个人,可以压缩 | 窄,特定于域和产品 | 会话,松散结构 |
| 语音助理(如 Cortana 或驾车通过式窗口) | 高音,16 kHz | 实体拥堵(歌曲名、产品、位置) | 明确表述的单词和短语 |
| 听写(即时消息、笔记、搜索) | 高音,16 kHz | 各式各样的 | 笔记记录 |
| 视频隐藏式字幕 | 各式各样,包括各种麦克风使用、添加的音乐 | 各式各样,包括会议、诵读演讲、音乐歌词 | 阅读、准备或松散结构 |
不同场景会产生不同的质量结果。 下表检查了如何用 WER 计算这四种方案中内容的错误率。 下表显示了每个场景中最常见的错误类型。 插入、替换和删除错误率有助于确定要添加哪种数据来改进模型。
| 方案 | 语音识别质量 | 插入错误 | 删除错误 | 替换错误 |
|---|---|---|---|---|
| 呼叫中心 | 中 (< 30% WER) |
低,但其他人在后台对话时除外 | 可能很高。 呼叫中心可能会有噪音,说话人声音重叠可能会对模型造成混淆 | 中等。 产品和人员的名称可能会导致这些错误 |
| 语音助手 | 高 (可以 < 10% WER) |
低 | 低 | 中,由于歌曲名称、产品名称或位置 |
| 听写 | 高 (可以 < 10% WER) |
低 | 低 | 高 |
| 视频隐藏式字幕 | 根据视频类型而定(可能 < 50% WER) | 低 | 可能由于音乐、噪音、麦克风质量而较高 | 专门术语可能导致这些错误 |