本文提供的技术指南介绍如何使用 Azure 认知搜索实现合规性风险分析解决方案。 这些指南基于实际的项目经验。 考虑到解决方案的全面范围以及使其适应特定用例的需要,本文重点介绍基本和特定的体系结构部分和实现部分。 它适当参考了分步教程。
Apache®、Apache Lucene® 和火焰徽标是 Apache Software Foundation 在美国和/或其他国家/地区的商标或注册商标。 使用这些标记并不暗示获得 Apache Software Foundation 的认可。
简介
每天,金融机构的顾问和交易员都会讨论、分析和决定价值数百万美元的交易。 无论是法律后果还是公众形象方面,员工进行欺诈交易、串通、内幕交易和其他不当行为对这些机构而言都是重大风险。
合规性团队致力于缓解这些风险。 他们的一部分工作是监视多个渠道的通信,包括即时消息、电子邮件和工作电话。 通常,根据业务交易数据对监视进行交叉检查。 目标是发现不合规的迹象,这些迹象通常是隐藏的,难以察觉。 这项任务是劳动和注意力密集型的,需要筛选大量数据。 尽管自动化系统可以提供帮助,但被忽视的风险可能非常多,这导致需要审查原始通信。
Azure 认知搜索可以帮助自动执行风险评估和提高风险评估的质量。 它具有内置 AI、可扩展 AI 和智能搜索功能。 本文中的合规性风险分析解决方案介绍如何通过整合和分析各种信道的内容来识别风险,例如金融交易员进行不当行为。 在这种非结构化内容中可识别的潜在风险包括市场操纵、内幕交易、共同基金欺诈等信号。
解决方案体系结构使用 Azure 认知服务和 Azure 认知搜索。 该场景针对金融部门的通信风险,但设计模式可迁移到其他行业和部门,例如政府和医疗保健。 组织可以通过开发和集成适用于其业务场景的风险评估模型来调整体系结构。 例如,通过使用Wolters Kluwer 演示应用,律师能够在证券交易委员会 (SEC) 的文件和通信中快速找到相关信息。 它可识别与融资相关的风险,包括网络安全和知识产权风险。
Azure 认知搜索具有内置 AI 和自定义技能,可提高业务流程性能和合规性团队的工作效率。 它对以下情况特别有用:
- 需从大量异类非结构化文档中提取见解,例如财务报表、语音听录和电子邮件。
- 非结构化内容的风险管理程序尚未完全到位。
- 现有方法是时间和劳动密集型的,会导致大量错误警报或被忽视的风险。
- 需要集成各种信道和数据源,包括结构化数据,以实现更全面的风险分析。
- 可以使用数据和域知识训练机器学习模型,以识别非结构化文本中的风险信号。 另外,可以集成现有模型。
- 需要体系结构能够不断地引入和处理新的可用非结构化数据,例如对话和消息,以优化解决方案。
- 合规性分析师需要使用一种有效的工具来识别和详细分析风险。 该工具必须可与人交互,以便分析师控制流程并标记可能的错误预测以优化模型。
Azure 认知搜索是一种具有内置 AI 功能的云搜索服务,可扩充所有类型的信息来帮助你大规模识别并探索相关内容。 可以使用视觉和语言认知技能,或使用自定义机器学习模型从所有类型的内容中挖掘见解。 Azure 认知搜索还提供语义搜索功能,该功能使用高级机器学习技术来划分用户意向并根据上下文对相关度最高的搜索结果进行排名。
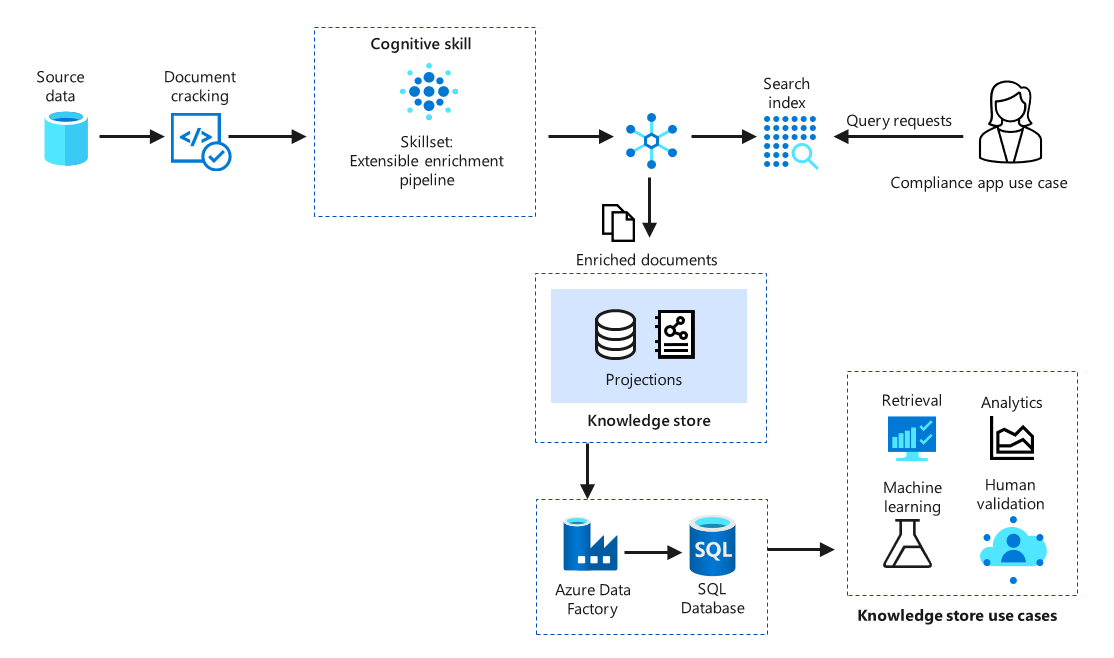
下图显示 Azure 认知搜索运行原理的概括视图,从数据引入和编制索引到向用户提供结果。

下载此体系结构的 PowerPoint 文件。
本文详细介绍了风险分析用例和其他金融服务场景(如上述 Wolters Kluwer 示例)的解决方案。 它提供了技术执行步骤,以及用于参考的操作文档和参考体系结构。 它包括从组织角度和技术角度而言的最佳做法。 设计模式假设根据业务环境和需求使用自己的数据开发自己的风险分析模型。
解决方案概述
下图提供了风险分析解决方案的概括视图。

下载此体系结构的 PowerPoint 文件。
为识别真正的风险通信,使用认知服务的各种机器学习模型提取和扩充异类通道的内容。 接下来,应用特定于自定义域的模型来识别市场操纵迹象以及交易各方之间的通信和互动中的其他风险。 所有数据都聚合到一个整合的 Azure 认知搜索解决方案中。 该解决方案包括用户友好型应用以及风险识别和分析功能。 应用程序数据存储在搜索索引中,如果需要长期存储,则存储在知识存储中。
下图提供了解决方案体系结构的概念性概述:

下载此体系结构的 PowerPoint 文件。
尽管每个信道(例如电子邮件、聊天和电话)都可以单独使用以检测潜在风险,但通过结合渠道并使用市场消息等补充信息来扩充内容,可以获得更好的见解。
风险分析解决方案使用多个接口来集成企业通信系统,以引入数据:
- Blob 存储用作文档格式数据的一般来源,例如电子邮件内容,包括附件、电话或聊天记录和消息文档。
- 可以使用 Microsoft Graph 数据连接集成 Microsoft Exchange Online 和 Microsoft Teams 等 Office 365 通信服务,以批量引入电子邮件、聊天和其他内容。 也可以使用 Microsoft 365 中适用于 SharePoint 的 Azure 认知搜索界面。
- 使用认知服务的语音转文本服务转录电话等语音通信。 然后,使用 Azure 认知搜索通过 Blob 存储引入生成的听录和元数据。
这些示例涵盖了常用的企业信道。 但也可以集成其他渠道,并且可以使用类似的引入模式。
整合后,使用 AI 技能扩充原始数据,以检测结构并从以前无法搜索的内容类型中创建基于文本的内容。 例如:
- PowerPoint 文件或 PDF 中的财务报表通常包含嵌入图像而不是计算机可读的文本,以防更改。 为处理此类内容,光学字符识别 (OCR) 使用 OCR 认知技能分析所有图像。
- 使用文本翻译认知技能将各种语言的内容翻译成英语或其他语言。
- 使用实体识别认知技能自动提取重要信息(例如人员名称和组织名称)并用于实现强大的搜索查询。 例如,通过搜索,可以找到 James Doe 与 Mary Silva 之间的在指定时间段内讨论特定公司的所有通信。
- 自定义模型用于识别通信中的风险证据,例如内幕交易。 这些特定于域的模型可以基于关键字、语句或整个段落。 它们使用高级的自然语言处理 (NLP) 技术。 使用当前用例的特定于域的数据训练自定义模型。
应用 Azure 认知搜索 AI 扩充功能和自定义技能后,将内容整合到搜索索引中,以支持扩充搜索和知识挖掘场景。 合规性分析师和其他用户使用前端应用来识别潜在的风险通信并执行深入搜索,以实现进一步分析。 风险管理是一个动态的过程。 在生产中不断优化模型,并添加新风险类型的模型。 因此,解决方案需要模块化。 扩展模型集时,自动标记 UI 中的新风险类型。
前端应用使用智能和语义搜索查询来检查内容。 也可以将内容移动到知识存储中,以保持合规性或与其他系统集成。
以下部分将更详细地介绍解决方案的基础部分。
实现风险分析解决方案是一项多学科活动,需要各个领域的关键利益干系人的参与。 根据经验,建议包括以下角色,以确保成功开发解决方案并在组织范围内采用。

提示
- 有关 Azure 认知搜索的详细信息,请参阅文档。
数据引入
本部分说明如何将异类内容整合到单个数据源中,然后设置从该源派生的搜索资产的初始集合。
Azure 认知搜索解决方案的开发和实现通常是一个增量过程。 除基线配置外,数据源、转换和扩充的添加也是在连续迭代中完成的。
Azure 认知搜索解决方案的第一步是在 Azure 门户中创建服务实例。 除搜索服务本身,还需要多个搜索资产,包括搜索索引、索引器、数据源和技能集。 使用 Azure 门户中的 Azure 认知搜索的导入数据向导即可轻松创建基线配置。 此处的该向导指导用户完成基本步骤来创建和加载使用外部数据源数据的简单搜索索引。

导入数据向导创建搜索索引的四个步骤如下:
- 连接数据:例如,只需单击几下即可轻松连接到现有 Blob 存储。 连接字符串用于身份验证。 其他本机支持的数据源包括各种 Azure 服务,例如 Azure SQL 数据库、Azure Cosmos DB,以及 SharePoint Online 等服务。 在此解决方案中,Blob 存储用于整合异类内容类型。
- 添加认知技能:在此可选步骤中,将内置 AI 技能添加到索引编制过程中。 使用它们可以扩充从数据源读取的内容。 例如,通过此步骤,可以提取人员和组织的名称和位置。
- 自定义目标索引:在此步骤中,开发人员为索引配置字段实体。 提供了默认索引,但可以添加、删除或重命名字段。 示例字段包括:文档标题、描述、URL、作者、位置、公司和股票代码,以及每个字段中可进行的操作的类型。
- 创建索引器:最后一步配置索引器,该组件定期运行以更新搜索索引的内容。 一个关键参数是索引器的运行频率。
确认配置后,将创建数据源、技能集、索引器和索引。 为其中的每一个组件创建 JSON 定义。 JSON 定义提供了增强的自定义功能,可用于通过 REST API 以编程方式创建服务。 好处是可在所有后续开发迭代中一致地按计划创建资产。 因此,我们使用 JSON 定义来演示所有资产的配置。 自动创建搜索资产部分详细说明了如何使用这些定义以编程方式创建所有资产。
在配置中,选择 Blob 存储作为默认数据源。 尽管通信可以来自多个渠道或来源,但此解决方案模式的通用方法依赖于 Blob 存储中包含文本和/或图像的所有通信。 以下步骤将详细介绍 Blob 存储的数据源 JSON 定义的配置。
本部分引用了一些模式来举例说明如何将 Office 365 通信引入 Blob 存储,以及如何使用语音转文本服务转录音频通话。
Blob 存储
以下 JSON 定义显示将 Blob 存储配置为 Azure 认知搜索的数据源所需的结构和信息:
{
"name": "email-ds",
"description": "Datasource for emails.",
"type": "azureblob",
"subtype": null,
"credentials": {
"connectionString": "DefaultEndpointsProtocol=https;AccountName=..."
},
"container": {
"name": "communications",
"query": "written_comms/emails"
}
}
以下字段为必填字段
- 名称:分配给数据源的名称。
- 类型:将数据源定义为 Blob 存储。
- 凭据:Blob 存储的连接字符串。
- 容器:存储 blob 的容器的名称。 可以指定容器内的目录,确保可在同一容器内创建多个数据源。
默认情况下,Blob 存储数据源支持多种文档格式。 例如,音频转录通常以 JSON 文件形式存储,电子邮件通常是 MSG 或 EML 文件,消息或其他通信材料通常是 PDF 格式、DOC/DOCX/DOCM 等 Word 格式或 PPT/PPTX/PPTM 等 PowerPoint 格式,或者 HTML 网页。
若要在同一 Blob 存储中设置多个数据源进行通信,可以使用以下方法之一:
- 为每个数据源提供专属容器。
- 为所有数据源使用同一容器,但在该容器中为每个数据源提供专属目录。
Microsoft Graph 数据连接
对于 Office 365 客户,Microsoft Graph 数据连接可用于将选定数据从 Microsoft Graph 提取到 Azure 存储,即 Azure 认知搜索解决方案的上游。 Microsoft Graph 中存储的数据包括电子邮件、会议、聊天、SharePoint 文档、人员和任务等数据。
注意
使用此机制需要经过数据同意流程。

下载此体系结构的 PowerPoint 文件。
该图显示来自 Microsoft Graph 的数据流。 该流程使用 Azure 数据工厂功能从 Microsoft Graph 中提取数据。 具有精细的安全控制,包括同意和治理模型。 数据工厂管道配置为要提取的数据类型,例如电子邮件和团队聊天,以及用户组和日期范围等范围。 按定义的计划以可配置的时间间隔执行搜索,并将其配置为将提取的数据拖入 Azure 存储。 然后,数据由索引器引入 Azure 认知搜索。
提示
以下文章包含分步说明,介绍如何设置通过数据工厂将数据从 Microsoft Graph 数据连接提取到 Azure 存储,以便后续引入到 Azure 认知搜索:
语音转文本参考体系结构
电话沟通是所有金融服务机构必不可少的工作方法。 如果可以访问相应的音频文件,则可以将电话沟通包含在风险分析解决方案中。 本部分涵盖了这种情况。
Azure 认知搜索中的文档破解是一组处理步骤,由索引器执行以从数据源中提取文本和图像。 对于音频文件,需要一种方法来提取这些音频通信的转录,以用于实现基于文本的处理。
下图显示音频引入和语音转文本管道。 管道处理成批的音频文件并将转录文件存储到 Blob 存储,即 Azure 认知搜索解决方案的上游。

下载此体系结构的 PowerPoint 文件。
在此参考体系结构中,音频文件通过客户端应用程序上传到 Blob 存储。 在此过程中,应用程序使用 Microsoft Entra ID 进行身份验证并调用 REST API 以获取 Blob 存储的令牌。 Azure API Management 提供对 REST API 的安全访问,Azure Key Vault 可安全地存储生成令牌所需的机密以及帐户凭据。
上传文件后,会发出 Azure 事件网格触发器以调用 Azure 函数。 然后,该函数使用认知服务语音转文本 API 处理音频文件。 然后,将转录的 JSON 文档存储在单独的 blob 容器中,Azure 认知搜索可将其作为数据源引入。
搜索解决方案
如前所述,创建了多个数据源,例如电子邮件、转录和消息,然后存储在 Blob 存储中。 然后,以专属方式转换和扩充了每个数据源。 所有生成的输出都映射到同一索引,并整合所有类型的源文档的数据。
下图演示了此方法。 为每个可用数据源配置自定义索引器,并将所有结果都放入一个搜索索引。

以下部分探讨索引引擎和可搜索的索引。 其中介绍了如何配置索引器,以及如何为 JSON 定义编制索引以实现可搜索的解决方案。
索引器
索引器协调文档内容的提取和扩充。 索引器定义包括以下详细信息:要引入的数据源、如何映射字段,以及如何转换和扩充数据。
由于映射、转换和扩充因数据类型而异,因此每个数据源都应有一个索引器。 例如,为电子邮件编制索引可能需要 OCR 技能来处理图像和附件,但转录只需要基于语言的技能。
这些是为过程编制索引的步骤:
- 文档破解:Azure 认知搜索打开并从文档中提取相关内容。 提取的可索引内容是数据源和文件格式的函数。 例如,对于 Blob 存储中的 PDF 或 Microsoft 365 文件等文件,索引器会打开文件并提取文本、图像和元数据。
- 字段映射:从源中提取的字段名称映射到搜索索引中的目标字段。
- 技能组执行:内置或自定义 AI 处理在此步骤中完成,如后面部分所述。
- 输出字段映射:转换字段或扩充字段的名称映射到索引中的目标字段。
以下代码片段显示电子邮件索引器 JSON 定义的某一段。 此定义使用步骤中详述的信息,并向索引引擎提供一组详细的说明。
{
"name": "email-indexer",
"description": "",
"dataSourceName": "email-ds",
"skillsetName": "email-skillset",
"targetIndexName": "combined-index",
"disabled": null,
"schedule": {
"interval": "P1D",
"startTime": "2021-10-17T22:00:00Z"
},
"parameters": {
"batchSize": null,
"mixabilities": 50,
"maxFailedItemsPerBatch": 0,
"base64EncodeKeys": null,
"configuration": {
"imageAction": "generateNormalizedImages",
"dataToExtract": "contentAndMetadata",
"parsingMode": "default"
}
},
"fieldMappings": [
{
"sourceFieldName": "metadata_storage_path",
"targetFieldName": "metadata_storage_path",
"mappingFunction": {
"name": "base64Encode",
"parameters": null
}
}
],
"outputFieldMappings": [
{
"sourceFieldName": "/document/merged_content/people",
"targetFieldName": "people"
},
{
"sourceFieldName": "/document/merged_content/organizations",
"targetFieldName": "organizations"
},
在此示例中,索引器由唯一名称 email-indexer 标识。 此索引器引用名为 email-ds 的数据源,AI 扩充由名为 email-skillset 的技能集定义。 为过程编制索引的输出存储在名为 combine-index 的索引中。 其他详细信息包括每日计划、最多 50 个失败项,以及用于生成规范化图像与用于提取内容和元数据的配置。
在字段映射部分,metadata_storage_path 字段使用 base64encoder 进行编码,用作唯一的文档密钥。 在输出字段映射配置中(仅部分显示),扩充过程的输出映射到索引架构。
如果为新数据源(如转录)创建新索引器,则大部分 JSON 定义配置为与数据源和技能组选择一致。 但目标索引必须是 combined-index(前提是所有字段映射都是兼容的)。 此方法使索引能够整合多个数据源的结果。
索引和其他结构
为过程编制索引后,提取和扩充的文档将保存在可搜索的索引中,也可以选择保存在知识存储中。
可搜索的索引:可搜索的索引对应于为过程编制索引时必须创建的输出,有时也称为搜索目录。 若要创建索引,需要索引定义。 它包含所有字段的配置(例如类型、可搜索、可筛选、可排序、可分面和可检索)。 这些索引字段名称需要与索引器字段和输出字段映射一致。
可以将多个索引器分配给同一索引,以便索引整合不同数据集的通信,例如电子邮件或转录。 然后,可以使用全文搜索或语义搜索来查询索引。
与索引器类似,可以使用索引 JSON 定义来配置索引。 以下代码片段对应于 combined-index JSON 定义的某一段:
{ "name": "combined-index", "fields": [ { "name": "metadata_storage_path", "type": "Edm.String", "facetable": false, "filterable": false, "key": true, "retrievable": true, "searchable": false, "sortable": false, "analyzer": null, "indexAnalyzer": null, "searchAnalyzer": null, "synonymMaps": [], "fields": [] }, { "name": "people", "type": "Collection(Edm.String)", "facetable": true, "filterable": true, "retrievable": true, "searchable": true, "analyzer": "standard.lucene", "indexAnalyzer": null, "searchAnalyzer": null, "synonymMaps": [], "fields": [] },在此示例中,索引由唯一名称 combined-index 标识。 索引定义独立于任何索引器、数据源或技能集。 字段定义索引的架构,在配置时,用户可以配置每个字段的名称和类型,以及一组属性,例如可分面和可筛选。
此代码片段包含两个字段。 Metadata_storage_path 是用作文档密钥的可检索字符串。 另一方面,“人员”字段是字符串集合,可以是可分面的、可筛选的、可检索的和可搜索的,并且全文查询是使用 standard.lucene 分析器进行处理的。
知识存储:知识存储可以是可选输出,用于知识挖掘等非搜索场景中的独立分析和下游处理。 知识存储的实现是在技能集中定义的,其中扩充的文档或特定的字段可以配置为以表或文件的形式显示。
下图显示知识存储的实现:

下载此体系结构的 PowerPoint 文件。
借助 Azure 认知搜索知识存储,可以使用以下选项(称为投影)来保存数据:
- 文件投影可以将内容(如嵌入图像)提取为文件。 例如,以图像文件格式导出的财务报表中的示意图或图表。
- 表投影支持表格格式的报告结构(例如,用于分析用例)。 可以使用它们来存储聚合信息,例如每个文档的风险评分。
- 对象投影将内容以 JSON 对象的形式提取到 Blob 存储中。 如果出于合规性原因需要详细地保留数据,可将其用于风险分析解决方案。 使用这种方法可以将风险评分存档。
由于搜索数据的结构针对查询进行了优化,因此通常未针对其他用途进行优化,例如导出到知识存储。 应用投影之前,可以根据保留要求使用 Shaper 技能重构数据。
在知识存储中,永久性内容存储在 Azure 存储中,也可以存储在表存储或 Blob 存储中。
可以通过多个选项使用知识存储中的数据。 Azure 机器学习可以访问用于生成机器学习模型的内容。 Power BI 可以分析数据和创建视觉对象。
金融机构使用现有的策略和系统,实现长期合规性保留。 因此,Azure 存储可能不是此用例的理想目标解决方案。 数据保存到知识存储后,数据工厂可将其导出到其他系统,例如数据库。
查询引擎
创建索引后,可以使用 Azure 认知搜索通过全文和语义搜索对其进行查询。
- 全文搜索基于 Apache Lucene 查询引擎,并接受在索引的所有可搜索字段中的搜索参数中传递的字词或短语。 找到匹配的字词时,查询引擎会按照相关性顺序对文档进行排序,并返回排名靠前的结果。 可通过对配置文件进行评分来自定义文档排名,并且可以使用索引可排序字段对结果进行排序。
- 语义搜索提供了一组强大的功能,可通过使用语义相关性和语言理解来提高搜索结果的质量。 启用后,语义搜索通过以下方式扩展搜索功能:
- 语义重排名使用查询的上下文或语义含义基于现有结果计算新的相关性分数。
- 语义亮点从文档中提取最能概括内容的句子和短语。
用户界面部分包含语义搜索功能的示例。 语义搜索目前仅提供公共预览版。 有关其功能的详细信息,请参阅文档。
自动创建搜索资产
开发搜索解决方案是一个迭代过程。 部署 Azure 认知搜索基础结构以及数据源、索引、索引器和技能集等搜索资产的初始版本后,可以不断优化解决方案(例如,通过添加和配置 AI 技能)。
为确保一致性和快速迭代,建议自动执行 Azure 认知搜索资产的创建流程。
对于解决方案,我们使用 Azure 认知搜索的 REST API 以自动化方式部署十个资产,如下图所示:

由于我们的解决方案需要对电子邮件、转录和消息文档进行不同的处理和 AI 扩充,因此我们创建了不同的数据源、索引器和技能集。 但我们决定为所有渠道使用单一索引,以更轻松地使用风险分析解决方案。
十项中的每一项都有一个详细说明其配置的关联 JSON 定义文件。 有关设置的说明,请参阅本指南中的示例代码框。
通过 build-search-config.py 脚本按所示顺序发出的 API 请求,将 JSON 规范发送到 Azure 认知搜索。 以下示例说明如何创建 email-skillset.json 中指定的电子邮件技能集:
url = f"https://{search_service}.search.windows.net/skillsets?api-version=2020-06-30-Preview"
headers = {'Content-type': 'application/json', 'api-key': cog_search_admin_key}
r = requests.post(url, data=open('email-skillset.json', 'rb'), headers=headers)
print(r)
- search_service 是 Azure 认知搜索资源的名称。
- cog_search_admin_key 是管理密钥。 只使用查询键无法实现管理操作。
执行所有配置请求并加载索引后,REST 查询确定搜索解决方案是否正确响应。 请注意,在生成所有资产并且索引器完成其初始运行之前存在时间延迟。 第一次查询前,可能需要等待几分钟。
若要详细了解如何使用 Azure 认知搜索 REST API 以编程方式创建配置来为 Blob 存储内容编制索引,请参阅:教程:使用 REST 和 AI 从 Azure Blob 生成可搜索内容。
AI 扩充
在上述部分中,我们奠定了风险分析解决方案的基础。 现在,重点介绍如何将信息从原始内容处理为有形的业务见解。
为使内容可搜索,通信内容通过使用内置技能和自定义模型进行风险检测的 AI 扩充管道传递:

首先,根据用于风险分析解决方案的示例技能 1 到 4,了解如何使用内置技能。 然后,了解如何添加自定义技能以集成风险模型(步骤 5)。 最后,了解如何审查和调试技能管道。
以下部分提供概念性介绍。 如需动手体验,请参阅 Microsoft Learn 分步指南。
内置 AI 扩充技能
应用的 AI 扩充的管道称为 Azure 认知搜索技能组。 风险分析解决方案中使用了以下内置技能:
光学字符识别:财务报表可以包含大量嵌入图像而不是文本的内容,以防更改内容。 以下演示文稿显示 Microsoft 季度报表中的一个示例:

幻灯片组中的所有幻灯片仅包含图形内容。 若要使用这些信息,对电子邮件(对附件特别重要)和市场消息文档使用 OCR 认知技能。 这可确保即使原始内容不是计算机可读的,搜索查询(例如上例中的“资本支出”)也能从幻灯片中找到文本。 在用户使用文本中未包含的与“资本支出”存在偏差的术语的情况下,语义搜索可进一步提高搜索相关性。
语言检测:在全球性组织中,支持机器翻译是一项常见要求。 例如,假设合规性分析师团队更喜欢用英语进行一致的阅读和交流,则解决方案需要能够准确地翻译内容。 语言检测认知技能用于识别原始文档的语言。 此信息用于识别是否需要翻译成所需的目标语言,并且还会显示在用户界面中以向用户指示原始语言。
提取人员和组织:实体识别认知技能可以识别非结构化文本中的人员、位置、组织和其他实体。 此信息可用于优化对大量异类内容的搜索或导航(例如筛选和分面)。 对于风险分析解决方案,选择提取人员(例如贸易商名称)和组织(例如公司名称)。
电子邮件技能集的 JSON 定义中的以下示例提供了所选配置的详细信息:
"skills": [ { "@odata.type": "#Microsoft.Skills.Text.V3.EntityRecognitionSkill", "name": "Detect Entities", "description": "Detect people and organizations in emails", "context": "/document/merged_content", "categories": [ "Person", "Organization" ], "defaultLanguageCode": "en", "minimumPrecision": 0.85, "modelVersion": null, "inputs": [ { "name": "text", "source": "/document/merged_content" }, { "name": "languageCode", "source": "/document/original_language" } ], "outputs": [ { "name": "persons", "targetName": "people" }, { "name": "organizations", "targetName": "organizations" } ] },首先,指定从内容中提取个人和组织。 存在其他类别(例如位置),且可在需要时提取它们。 但我们有意将提取限制为这两个实体,避免一开始信息过多导致用户不知所措。
由于没有任何 AI 解决方案能够提供 100% 的准确性,因此始终存在误报(例如错误的组织名称)和漏报(例如遗漏组织)的风险。 Azure 认知搜索提供了用于平衡提取实体时的信噪比的控件。 在示例中,检测的最小精度设为 0.85,以增强识别相关性并减少噪声。
在下一步中,在扩充的文档中指定技能集的输入和输出。 输入路径指向 merge_content,其中包括电子邮件和附件。 附件内容包括使用 OCR 提取的文本。
最后,为指定实体定义输出名称“人员”和“组织”。 稍后,这些内容将作为索引器定义的一部分映射到搜索索引。
其他技能的定义遵循类似的模式,并补充了特定于技能的设置。
翻译:在下一步中将包含外语的文档翻译成英文。 文本翻译认知技能用于转换。 请注意,只要将文本发送到文本翻译 API,就会收取翻译费用,即使源语言和目标语言相同。 为避免产生这些情况下的服务费用,在这些情况下使用额外的条件认知技能来绕过翻译。

提示
可以使用 Azure 认知搜索中的导入数据助手快速引入和扩充内容。 今后,你将受益于以自动化方式创建技能集和其他 Azure 认知搜索资产。 下文提供了详细信息:
用于风险检测的自定义 AI 扩充
从 Azure 认知搜索实现所需的内置技能后,接下来了解如何添加自定义模型以进行风险分析。
对通信内容中预期或实际的不当行为进行识别始终取决于上下文,并且需要广泛的域知识。 风险分析解决方案的一个关键目标是提供一种方法来将自定义风险模型灵活集成并应用到扩充管道中,以发现特定业务场景的真实风险。
根据用例,以下对话示例可能表明存在潜在的故意不当行为:

以下选项可以解析非结构化通信内容以识别风险:
- 基于关键字的方法:此方法使用相关关键字(例如离线、特殊见解)列表来识别潜在风险。 该方法易于实现,但如果内容中的表述与关键字不匹配,则可能会忽略风险。
- 基于实体识别的方法:机器学习模型针对简短的语句(例如句子)进行训练,以使用语言模型识别风险。 专家知识用于创建具有相应风险分类(例如市场操纵、内幕交易)的代表性示例的训练集。 该方法的一个关键优势是,即使语句具有类似的语义含义但表述与训练集中的示例不同,仍有很大可能识别出风险。 Azure 对话语言理解服务可用于此类用途。
- 基于高级 NLP 的方法:神经网络的最新进展使得能够分析较长的非结构化文本片段,包括分类和其他 NLP 任务。 该方法可以识别更难以察觉且涉及多个句子或段落的信号。 该方法的缺点是,相较于其他方法,通常需要更多训练数据。 Azure 提供了多种训练 NLP 模型的选项,包括自定义文本分类和自动机器学习。
作为 REST Web 服务提供的任何模型都可以作为自定义技能集成到 Azure 认知搜索风险分析解决方案中。 在示例中,我们将一组对话语言理解模型与一个用作 Azure 认知搜索和这些模型之间的接口的 Azure 函数集成在一起。 下图演示了该方法:

下载此体系结构的 PowerPoint 文件。
处理内置技能后,扫描电子邮件和转录以查看是否存在风险。 自定义技能将文档类型及其内容提供给 Azure Functions 应用,以进行预处理。 该应用基于已发布的示例并执行以下任务:
- 确定要使用的模型:组织可以使用不同的模型来识别多种类型的风险(例如市场操纵、内幕交易、共同基金欺诈)。 Functions 应用根据配置的首选项激活可用模型。
- 预处理内容:此任务包括删除附件内容以及将文本拆分为句子以匹配用于训练风险模型的数据的结构。
- 将标记的内容发送到配置的风险模型:风险模型为每个句子赋予风险评分。
- 将结果汇总并评分:先完成此操作,然后将其返回技能组。 文档风险评分是其所有句子中风险最高的。 识别出的最高风险句子也会被返回并在 UI 中显示。 此外,文档风险根据分数分为低、中或高风险。
- 将信息写入 Azure 认知搜索索引:该信息用于合规性分析师 UI 和知识存储中。 它包括所有通信内容、内置扩充内容和自定义风险模型结果。
以下 JSON 示例将 Azure 认知搜索与 Functions 应用(调用风险模型)之间的接口定义说明为自定义技能:
{
"@odata.type": "#Microsoft.Skills.Custom.WebApiSkill",
"name": "apply-risk-models",
"description": "Obtain risk model results",
"context": "/document/content",
"uri": "https://risk-models.azurewebsites.net/api/luis-risks?...",
"httpMethod": "POST",
"timeout": "PT3M",
"batchSize": 100,
"degreeOfParallelism": null,
"inputs": [
{
"name": "text",
"source": "/document/mergedenglishtext"
},
{
"name": "doc_type",
"source": "/document/type"
}
],
"outputs": [
{
"name": "risk_average",
"targetName": "risk_average"
},
{
"name": "risk_models",
"targetName": "risk_models"
}
],
},
URI 指定从 Azure 认知搜索获取以下输入的 Functions 应用的 Web 地址:
- text 包含英文内容。
- doc_type 用于区分转录、电子邮件和市场消息,它们需要不同的预处理步骤。
Functions 应用从适用于语言的 Azure 认知服务的对话语言理解功能收到风险评分后,会将整合的结果返回到 Azure 认知搜索。
金融服务组织需要一种模块化方法来灵活地结合现有的和新的风险模型。 因此,不执行特定模型的硬编码。 相反,risk_models 是一种复杂的数据类型,它返回每种风险类型(例如内幕交易)的详细信息,包括风险评分和具有最高风险评分的已识别句子。 合规性和可追溯性是金融服务组织的主要关注点。 不过,风险模型会不断优化(例如,使用新的训练数据),因此对文档的预测可能会随着时间而改变。 为确保可追溯性,每次预测时还会返回风险模型的具体版本。
可以重用该体系结构以集成更高级的 NLP 模型(例如,能够识别可能涉及多个语句的更难以察觉的风险信号)。 主要调整是将 Functions 应用中的预处理步骤与训练 NLP 模型时进行的预处理相匹配。
调试 AI 扩充管道
对于大型技能组而言,了解信息流和 AI 扩充可能非常困难。 Azure 认知搜索提供了用于调试和可视化扩充管道的有用功能,包括技能的输入和输出。

该流程图提取自 Azure 门户中 Azure 认知搜索资源的调试会话选项卡。 它总结了扩充的流程,内容由技能集中的内置技能和自定义风险模型连续处理。
技能图中的处理流程由 Azure 认知搜索根据技能的输入和输出配置自动生成。 该图还显示处理时的并行度。
条件技能用于识别文档类型(电子邮件、转录或消息),因为这些类型在后续步骤中的处理方式不同。 条件技能用于避免产生原始语言与目标语言相同时的翻译费用。
内置技能包括 OCR、语言检测、实体检测、翻译和文本合并(用于将嵌入图像替换为原始文档中的嵌入 OCR 输出)。
管道中的最后一项技能是通过 Functions 应用集成对话语言理解风险模型。
最后,为原始和扩充的字段编制索引并映射到 Azure 认知搜索索引。
以下来自搜索响应的摘录举例说明可通过使用扩充的内容和语义搜索获得的见解。 查询词是“资本支出如何产生”(即“报告期内资本支出如何产生?”的缩写)。
{
"@search.captions" : [
{
"highlights" : "Cash flow from operations was $22.7 billion, up 2296 year-over-year, driven by strong cloud billings and collections Free cash flow of $16.3 billion, up 1796 year-over-year, reflecting higher<em> capital expenditures</em> to support our cloud business 6 includes non-GAAP constant currency CCC\") growth and cash flow."
}],
"sender_or_caller" : "Jim Smith",
"recipient" : "Mary Turner",
"metadata_storage_name" : "Reevaluate MSFT.msg",
"people" : ["Jim Smith", "Mary Turner", "Bill Ford", … ],
"organizations" : ["Microsoft", "Yahoo Finance", "Federal Reserve", … ],
"original_language" : "nl",
"translated_text" : "Here is the latest update about …",
"risk_average" : "high",
"risk_models" : [
{
"risk" : "Insider Trade",
"risk_score" : 0.7187,
"risk_sentence" : "Happy to provide some special insights to you. Let’s take this conversation offline.",
"risk_model_version" : "Inside Trade v1.3"
},
]
}
用户界面
实现搜索解决方案后,可以通过 Azure 门户直接查询索引。 尽管此选项有利于学习、试验和调试,但它并不是一个好的最终用户体验。
专注于用户体验的自定义用户界面有助于展示搜索解决方案的真正价值,并使组织能够识别和审查各种渠道和来源的风险沟通。
知识挖掘解决方案加速器提供了 Azure 认知搜索 UI 模板(.NET Core MVC Web 应用),用于快速生成原型来查询和查看搜索结果。
只需几个步骤即可将模板 UI 配置为连接和查询搜索索引,并显示一个简单的网页,用于搜索和可视化结果。 可进一步自定义该模板,以优化检索和分析风险通信的体验。
以下屏幕截图显示适用于我们的风险场景的示例用户界面,该用户界面是通过自定义 Azure 认知搜索 UI 模板创建的。 此 UI 通过提供跨渠道通信和风险信息的直观视图,介绍了一种显示搜索解决方案的方法。

在起始页,可进行与搜索解决方案的交互。 在起始页中,用户能够搜索、优化、可视化和探索结果:
- 初始结果检索自搜索索引,并以表格形式显示,便于访问通信且便于进行结果比较。
- 用户可以获得重要的通信详细信息,来自多个渠道(电子邮件、转录、消息)的文档会整合到一个视图中。
- 针对每一次通信,显示来自自定义风险模型的分数,并突出显示高风险。
- 整合风险分类汇总来自自定义风险模型的分数,并根据平均风险级别对结果进行排序。
- 用户可以使用阈值滑块更改风险阈值。 超出阈值的自定义风险评分会突出显示。
- 可以使用日期范围选择器扩大分析周期或搜索历史结果。
- 可以使用一组筛选器(例如语言或文档类型)来优化搜索结果。 这些选项在 UI 中动态生成,随索引中配置的可分面字段变化而变化。
- 可以使用搜索栏在索引中搜索特定字词或短语。
- 语义搜索可用。 用户可以在标准搜索和语义搜索之间切换。
- 可以通过用户界面直接上传新的通信并为其编制索引。 还为每个文档提供了一个详细信息页面:

详细信息页面提供对通信内容以及扩充和元数据的访问:
- 显示文档破解过程中提取的内容。 可以直接在详细信息页面中查看某些文件(例如 PDF)。
- 总结了自定义风险模型的结果。
- 本页显示本文档中排名靠前的人员和组织。
- 可在详细信息页面的其他选项卡中添加并显示编制索引过程中捕获的其他元数据。
如果引入了非英语内容,则用户可以以原始语言或以英语查看该内容。 详细信息页面的“翻译”选项卡并排显示原始内容和翻译内容。 这表明,在编制索引过程中,两种语言都是永久性的,均可供用户界面使用。
最后,用户可以进行语义搜索。 下例显示使用语义搜索搜索表达式“资本支出如何产生”(即“报告季度内资本支出如何产生?”的缩写)时的最优结果。

全文模式下的等效搜索会导致搜索查询搜索“capex”的完全匹配项,但文档中不存在该匹配项。 然而,语义功能使得查询引擎能够识别出“capex”与“capital expenditures”相关,从而将该通信识别为最相关。 此外,语义搜索生成语义亮点 (12),并在文档中汇总最相关的句子。
最佳实践
本部分总结开发合规性风险分析解决方案的组织和技术最佳做法。
让必要的利益干系人参与:实现风险分析解决方案是一项多学科活动,需要各个领域的关键利益干系人的参与。 需包含之前介绍的项目相关角色以及受解决方案影响的其他角色。
确保适当的采用和变更管理:自动执行风险分析做法很可能会严重改变员工的工作方式。 尽管解决方案增添了价值,但对任何工作流程的更改都可能会带来许多困难,导致采用时间较长,并且可能会遇到阻力。 根据最佳做法,应尽早让受影响的员工参与进来。 考虑使用 Prosci ADKAR 采用模型,该模型重点介绍了技术采用过程的五个关键步骤:意识、愿望、知识、能力和强化。
使用多种渠道发现风险:可以单独研究每一个沟通渠道(例如电子邮件、聊天、电话)以检测潜在风险。 但通过将正式通信(例如电子邮件)和非正式通信(例如聊天)的异类渠道相结合,可以获得更好的见解。 此外,集成补充信息(例如市场消息、公司报表、SEC 文件)可以为合规性分析师提供额外的背景信息(例如公司特定计划的背景信息)。
从简单入手并进行迭代:Azure 认知搜索提供了一套全面的基于各种认知服务的内置 AI 扩充。 立即添加这些功能可能很吸引人。 但如果控制不当,可提取的实体或关键短语数可能会使最终用户不知所措。 减少使用的技能或实体数有助于用户和开发人员了解哪些技能或实体价值最大。
负责任的创新:开发 AI 解决方案需要所有相关人员具有高度责任心。 Microsoft 非常重视负责任地使用人工智能,并制定了核心设计原则框架:
- 公平性
- 可靠性和安全性
- 隐私和安全
- 包容
- 透明和问责
评估员工通信需要特别小心,会导致道德问题。 在一些国家/地区,对员工的自动监视会受严格的法律限制。 由于这些原因,负责任的创新是项目计划的基础。 Microsoft 为此提供了多种框架和工具。 有关详细信息,请参阅本部分末尾的“提示”框。
自动执行开发迭代:使用导入数据向导即可轻松入门,但对于更复杂的解决方案和高效的用例,建议在代码中创建数据源、索引器、索引和技能集等资产。 自动执行显著加快了开发周期并确保一致地部署到生产环境中。 资产以 JSON 格式指定。 可以从门户复制 JSON 定义,根据需要对其进行修改,然后将其输入对 Azure 认知搜索 REST API 的调用的请求正文。
选择适当的 NLP 方法进行风险分析:识别非结构化文本中的风险的方法包括基本关键字搜索和实体提取,以及强大的新式 NLP 体系结构。 最佳选择取决于具体用例的现有训练数据的数量和质量。 如果训练数据有限,可以使用适用于语言的 Azure 认知服务的对话语言理解功能来训练基于语句的模型。 可以查看现有对话以识别和标记指示相关风险类型的句子。 有时,使用几十个样本即可训练出一个结果良好的模型。
如果风险信号更难以察觉且涉及多个句子,则训练最先进的 NLP 模型很可能是更好的选择。 但是,该方法通常需要更多的训练数据。 建议在解决方案投入生产时尽可能使用实际数据,以针对潜在的错误预测进行调整,并不断重新训练模型以不断提高其性能。
根据特定要求调整 UI:丰富的用户界面可以提供 Azure 认知搜索和 AI 扩充的所有附加价值。 尽管使用 Azure AI 搜索 UI 模板可以简单快捷地实现初始 Web 应用,但可能必须对其进行调整才能集成其他功能。 此外,还需要根据处理的通信类型、使用的 AI 扩充类型以及其他任何业务需求对其进行调整。 前端开发人员、业务利益干系人和最终用户之间的持续协作和迭代将优化查找和审查相关通信的用户体验,从而提升解决方案的价值。
优化翻译服务的成本:默认情况下,所有文档都会通过 AI 扩充管道。 这意味着即使无需翻译,英语文档也会传递给翻译服务。 但由于内容经翻译 API 处理,因此仍需付费。 在解决方案中,我们将语言检测与条件技能结合使用,以避免在这些情况下进行翻译。 如果检测到的原始文档语言不是英语,则将内容复制到针对非英语内容的特定字段,然后传递给翻译服务。 如果文档为英文,则此字段为空且不产生翻译费用。 最后,所有内容(初始英文内容或翻译内容)会合并到一个公共字段,以供进一步处理。 还可以启用缓存以重用现有的扩充。
确保生产环境的可用性和可伸缩性:从概念证明转向生产规划后,需考虑可用性和可伸缩性,以确保搜索解决方案的可靠性和性能。 搜索服务的实例称为副本,用于对查询操作进行负载均衡。 添加副本以实现高可用性并提高查询性能。 使用分区来管理解决方案的可伸缩性。 分区代表物理存储且具有特定的大小和 I/O 特征。 有关如何管理容量和其他服务管理注意事项的指南,请参阅文档。
结束语
本指南为如何设置使用 AI 查找欺诈迹象的解决方案提供了全面的指导。 该方法适用于其他受监管的行业,如医疗保健或政府。
可以扩展体系结构,添加其他数据源和 AI 功能,例如:
- 引入结构化数据,例如市场数据(如股票报价)和交易信息。
- 通过使用 Azure 表单识别器 和 Azure 读取 API 等功能,附加旨在从基于纸的源中提取内容的分类模型。
- 通过使用 Azure Language Studio 功能对相关主题进行分类和筛选,或使用 Azure 情绪分析来捕获意见趋势,获取社交网络信息。
- 使用 Microsoft Graph 收集和整合来自 Microsoft 365 的信息,例如人际互动、任职公司或所访问信息。 将此数据保存在 Azure 存储中时,即可轻松搜索此数据。
Azure 认知搜索技术是解决方案的基础,也是最佳选择,因为它支持知识挖掘、目录搜索和应用内搜索。 该技术很简单,可用于部署和连接到多个数据源,也用于提供内置的可扩展 AI 来处理内容。 它具有深度学习支持的语义搜索等功能,推断用户意图的功能,以及显示最相关结果并排序的功能。
作者
本文由 Microsoft 维护, 它最初是由以下贡献者撰写的。
主要作者:
- Andreas Kopp | 高级云解决方案架构师
- João Pedro Martins | 高级云解决方案架构师主管
- Carlos Alexandre Santos | 高级云解决方案架构师
若要查看非公开领英个人资料,请登录领英。