你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
Apache Spark 是用于大规模数据处理的统一分析引擎。 Azure 数据资源管理器是一个快速、完全托管的数据分析服务,可用于实时分析大量数据。
适用于 Spark 的 Kusto 连接器是可在任何 Spark 群集上运行的开放源代码项目。 它实现了用于跨 Azure 数据资源管理器和 Spark 群集移动数据的数据源和数据接收器。 使用 Azure 数据资源管理器和 Apache Spark,可以构建面向数据驱动型方案的可缩放快速应用程序。 例如,机器学习 (ML)、提取-转换-加载 (ETL) 和 Log Analytics。 使用连接器时,Azure 数据探索器将成为标准 Spark 源和接收器操作的有效数据存储,例如 write,read 以及 writeStream。
可以通过排队引入或流式引入写入 Azure 数据资源管理器。 Azure 数据资源管理器的读取功能支持列裁剪和谓词下推,这些技术可在 Azure 数据资源管理器中筛选数据,从而减少所需传输的数据量。
本文介绍如何安装和配置 Azure 数据资源管理器 Spark 连接器,以及如何在 Azure 数据资源管理器和 Apache Spark 群集之间移动数据。
注意
尽管本文中的一些示例参照了 Azure Databricks Spark 集群,但 Azure 数据探查器 Spark 连接器并不直接依赖 Databricks 或任何其他 Spark 发行版。
先决条件
- Azure 订阅。 创建免费 Azure 帐户。
- Azure 数据资源管理器群集和数据库。 创建群集和数据库。
- Spark 群集
- 安装连接器库:
- Spark 2.4+Scala 2.11 或 Spark 3+scala 2.12 的预生成库
- Maven 存储库
- 已安装 Maven 3.x
提示
Spark 2.3.x 版本也受支持,但可能需要更改 pom.xml中的某些依赖项。
如何生成 Spark 连接器
从版本 2.3.0 开始,我们引入了新的项目 ID,替换 spark-kusto-connector:针对 Spark 3.x 和 Scala 2.12 的 kusto-spark_3.0_2.12。
注意
请注意,2.5.1 以前的版本已无法用于导入到现有表,请更新到更高版本。 此步骤是可选的。 如果使用的是预生成库(例如 Maven),请参阅 Spark 群集设置。
生成先决条件
参考此源来生成 Spark 连接器。
对于使用 Maven 项目定义的 Scala 和 Java 应用程序,将您的应用程序链接到最新的构件。 在 Maven Central 上查找最新项目。
For more information, see [https://mvnrepository.com/artifact/com.microsoft.azure.kusto/kusto-spark_3.0_2.12](https://mvnrepository.com/artifact/com.microsoft.azure.kusto/kusto-spark_3.0_2.12).如果使用的不是预生成库,则需要安装依赖项中列出的库,包括以下 Kusto Java SDK 库。 若要查找要安装的正确版本,请查看相关版本的 pom:
生成 jar 并运行所有测试:
mvn clean package -DskipTests生成 jar,运行所有测试,并将 jar 安装到本地 Maven 存储库:
mvn clean install -DskipTests
有关详细信息,请参阅连接器用法。
Spark 群集设置
注意
建议使用最新的 Kusto Spark 连接器版本执行以下步骤。
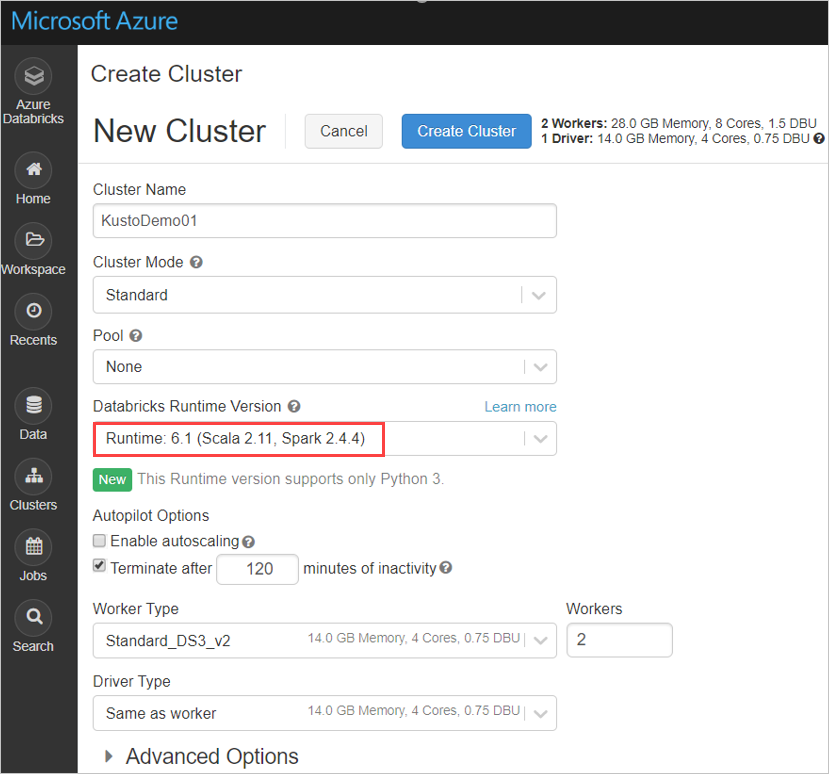
根据 Azure Databricks 群集 Spark 3.0.1 和 Scala 2.12,配置以下 Spark 群集设置:
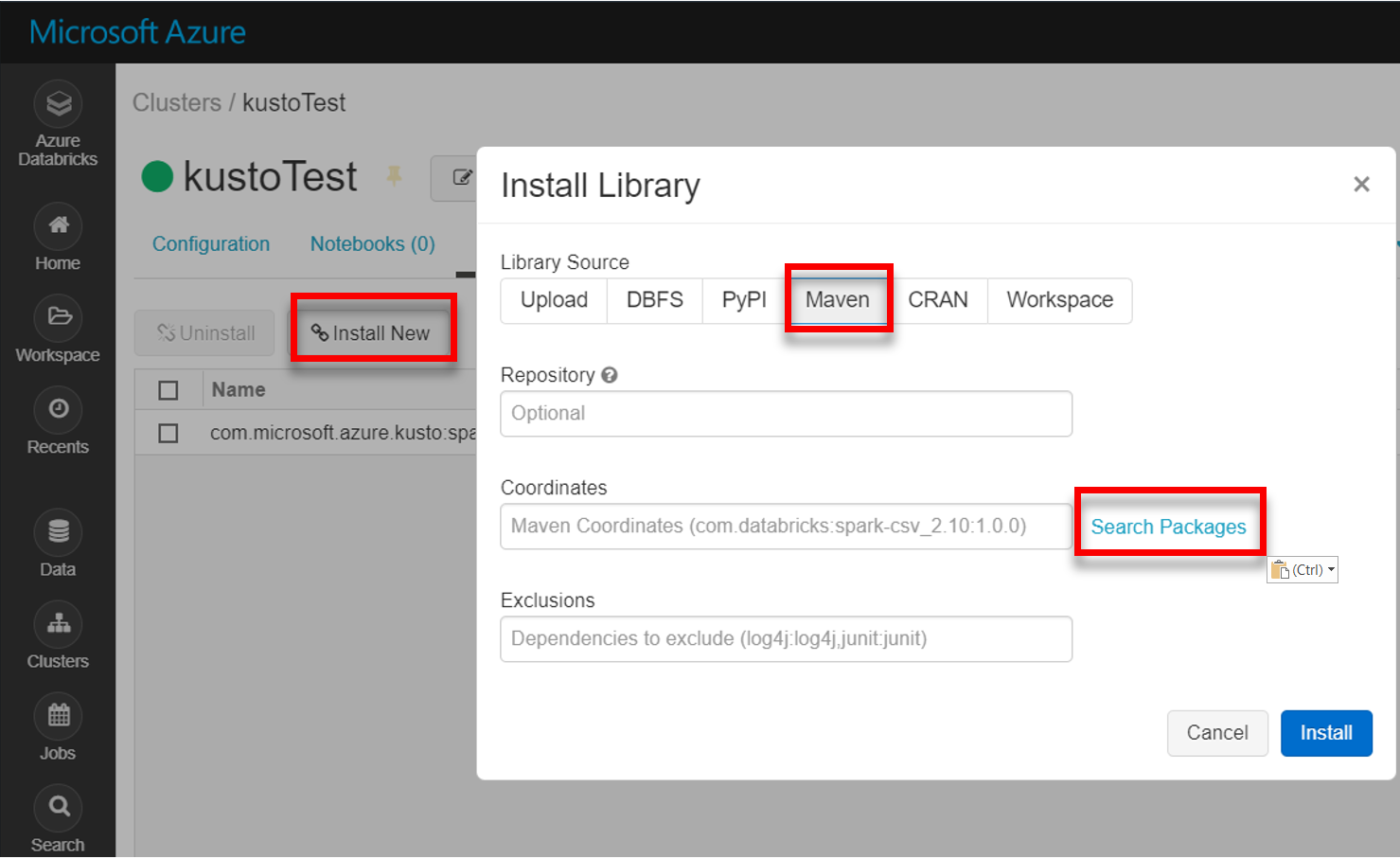
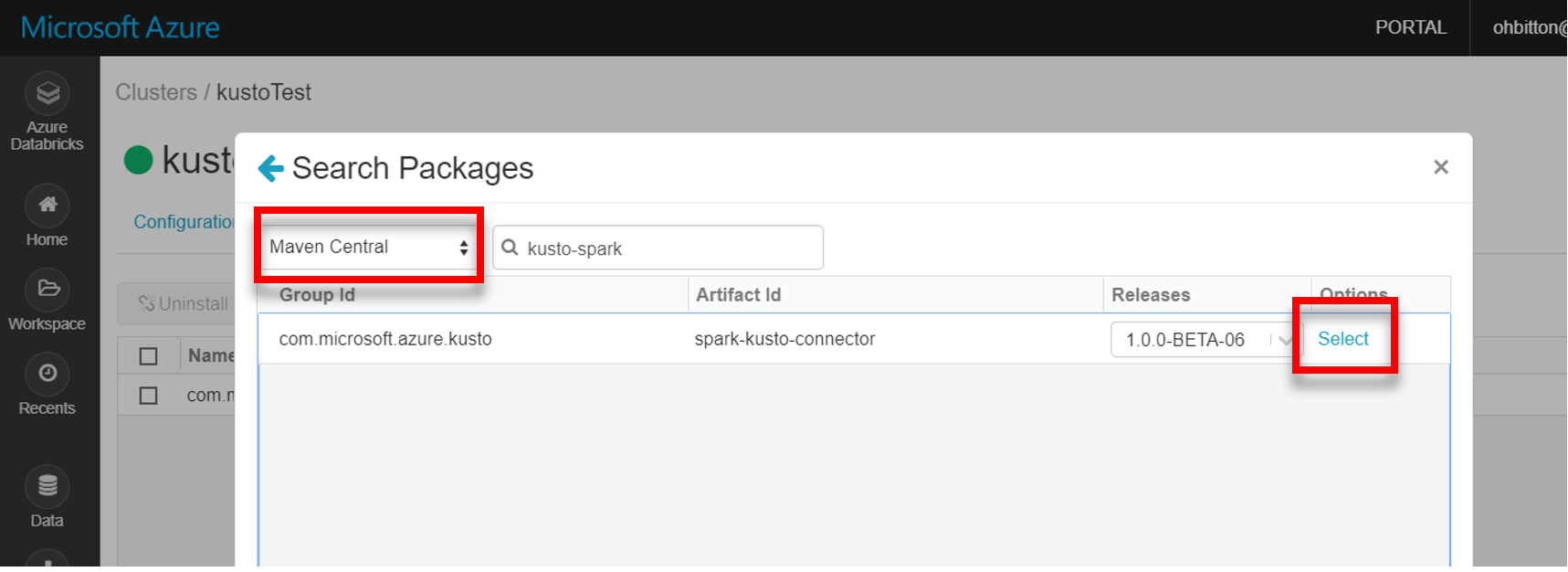
从 Maven 安装最新 spark-kusto-connector 库:
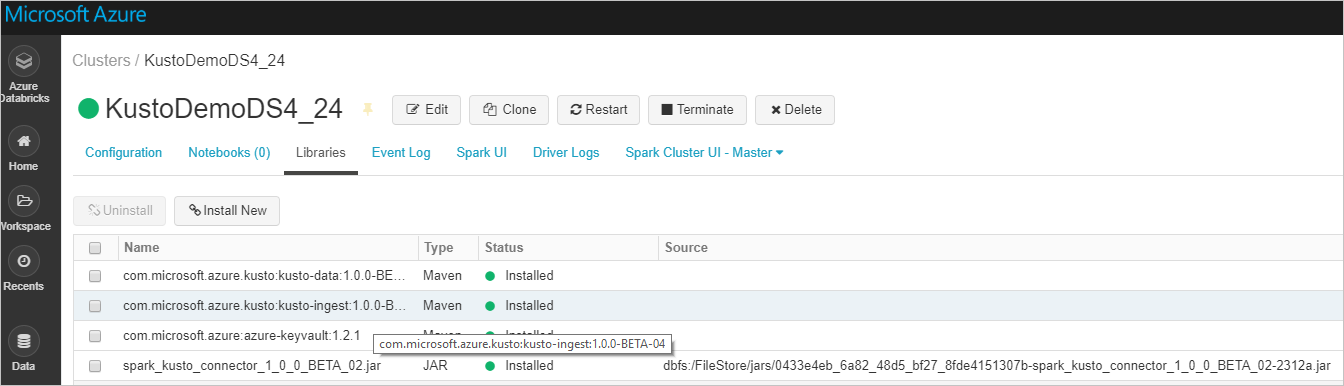
验证是否已安装所有必需的库:
使用 JAR 文件进行安装时,请验证是否已安装其他依赖项:
身份验证
使用 Kusto Spark 连接器,可以通过下列其中一个方法使用 Microsoft Entra ID 进行身份验证:
- Microsoft Entra 应用程序
- Microsoft Entra 访问令牌
- 设备身份验证(适用于非生产方案)
- Azure Key Vault 若要访问 Key Vault 资源,请安装 azure-keyvault 包并提供应用程序凭据。
Microsoft Entra 应用程序身份验证
Microsoft Entra 应用程序身份验证是最简单且最常用的身份验证方法,建议将其用于 Kusto Spark 连接器。
通过 Azure CLI 登录到你的 Azure 订阅。 然后在浏览器中进行身份验证。
az login选择要托管主体的订阅。 当你有多个订阅时,此步骤是必需的。
az account set --subscription YOUR_SUBSCRIPTION_GUID创建服务主体。 在此示例中,服务主体名为
my-service-principal。az ad sp create-for-rbac -n "my-service-principal" --role Contributor --scopes /subscriptions/{SubID}从返回的 JSON 数据中复制
appId、password、tenant供将来使用。{ "appId": "00001111-aaaa-2222-bbbb-3333cccc4444", "displayName": "my-service-principal", "name": "my-service-principal", "password": "00001111-aaaa-2222-bbbb-3333cccc4444", "tenant": "00001111-aaaa-2222-bbbb-3333cccc4444" }
现已创建了 Microsoft Entra 应用程序和服务主体。
Spark 连接器使用以下 Entra 应用属性进行身份验证:
| 属性 | 选项字符串 | 说明 |
|---|---|---|
| KUSTO_AAD_APP_ID | kustoAadAppId | Microsoft Entra 应用程序(客户端)标识符。 |
| KUSTO_AAD_AUTHORITY_ID | kustoAadAuthorityID | Microsoft Entra 身份验证权限。 Microsoft Entra 目录(租户)ID。 可选 - 默认为 microsoft.com。 有关详细信息,请参阅 Microsoft Entra 颁发机构。 |
| KUSTO_AAD_APP_SECRET | kustoAadAppSecret | 客户端的 Microsoft Entra 应用程序密钥。 |
| KUSTO_ACCESS_TOKEN | kustoAccessToken | 如果您已经创建了一个可以访问 Kusto 的 accessToken,那么也可以将其传递给连接器进行身份验证。 |
注意
较旧的 API 版本(低于 2.0.0)有以下命名:“kustoAADClientID”、“kustoClientAADClientPassword”、“kustoAADAuthorityID”
Kusto 权限
根据要执行的 Spark 操作,在 Kusto 端授予以下权限。
| Spark 操作 | 权限 |
|---|---|
| 读取 - 单一模式 | 读取者 |
| 读取 – 强制分布式模式 | 读取者 |
| 写入 - 包含 CreateTableIfNotExist 表创建选项的排队模式 | 管理员 |
| 写入 - 包含 FailIfNotExist 表创建选项的排队模式 | 引入者 |
| 写入 – TransactionalMode | 管理员 |
有关主体角色的详细信息,请参阅“基于角色的访问控制”。 有关如何管理安全角色,请参阅安全角色管理。
Spark 接收器:写入 Kusto
设置接收器参数:
val KustoSparkTestAppId = dbutils.secrets.get(scope = "KustoDemos", key = "KustoSparkTestAppId") val KustoSparkTestAppKey = dbutils.secrets.get(scope = "KustoDemos", key = "KustoSparkTestAppKey") val appId = KustoSparkTestAppId val appKey = KustoSparkTestAppKey val authorityId = "72f988bf-86f1-41af-91ab-2d7cd011db47" // Optional - defaults to microsoft.com val cluster = "Sparktest.eastus2" val database = "TestDb" val table = "StringAndIntTable"将 Spark 数据帧分批写入 Kusto 群集:
import com.microsoft.kusto.spark.datasink.KustoSinkOptions import org.apache.spark.sql.{SaveMode, SparkSession} df.write .format("com.microsoft.kusto.spark.datasource") .option(KustoSinkOptions.KUSTO_CLUSTER, cluster) .option(KustoSinkOptions.KUSTO_DATABASE, database) .option(KustoSinkOptions.KUSTO_TABLE, "Demo3_spark") .option(KustoSinkOptions.KUSTO_AAD_APP_ID, appId) .option(KustoSinkOptions.KUSTO_AAD_APP_SECRET, appKey) .option(KustoSinkOptions.KUSTO_AAD_AUTHORITY_ID, authorityId) .option(KustoSinkOptions.KUSTO_TABLE_CREATE_OPTIONS, "CreateIfNotExist") .mode(SaveMode.Append) .save()或者使用简化的语法:
import com.microsoft.kusto.spark.datasink.SparkIngestionProperties import com.microsoft.kusto.spark.sql.extension.SparkExtension._ // Optional, for any extra options: val conf: Map[String, String] = Map() val sparkIngestionProperties = Some(new SparkIngestionProperties()) // Optional, use None if not needed df.write.kusto(cluster, database, table, conf, sparkIngestionProperties)写入流数据:
import org.apache.spark.sql.streaming.Trigger import java.util.concurrent.TimeUnit import java.util.concurrent.TimeUnit import org.apache.spark.sql.streaming.Trigger // Set up a checkpoint and disable codeGen. spark.conf.set("spark.sql.streaming.checkpointLocation", "/FileStore/temp/checkpoint") // As an alternative to adding .option by .option, you can provide a map: val conf: Map[String, String] = Map( KustoSinkOptions.KUSTO_CLUSTER -> cluster, KustoSinkOptions.KUSTO_TABLE -> table, KustoSinkOptions.KUSTO_DATABASE -> database, KustoSourceOptions.KUSTO_ACCESS_TOKEN -> accessToken) // Write to a Kusto table from a streaming source val kustoQ = df .writeStream .format("com.microsoft.kusto.spark.datasink.KustoSinkProvider") .options(conf) .trigger(Trigger.ProcessingTime(TimeUnit.SECONDS.toMillis(10))) // Sync this with the ingestionBatching policy of the database .start()
Spark 源:从 Kusto 读取
读取少量数据时,可以定义数据查询:
import com.microsoft.kusto.spark.datasource.KustoSourceOptions import org.apache.spark.SparkConf import org.apache.spark.sql._ import com.microsoft.azure.kusto.data.ClientRequestProperties val query = s"$table | where (ColB % 1000 == 0) | distinct ColA" val conf: Map[String, String] = Map( KustoSourceOptions.KUSTO_AAD_APP_ID -> appId, KustoSourceOptions.KUSTO_AAD_APP_SECRET -> appKey ) val df = spark.read.format("com.microsoft.kusto.spark.datasource"). options(conf). option(KustoSourceOptions.KUSTO_QUERY, query). option(KustoSourceOptions.KUSTO_DATABASE, database). option(KustoSourceOptions.KUSTO_CLUSTER, cluster). load() // Simplified syntax flavor import com.microsoft.kusto.spark.sql.extension.SparkExtension._ val cpr: Option[ClientRequestProperties] = None // Optional val df2 = spark.read.kusto(cluster, database, query, conf, cpr) display(df2)可选:如果你提供暂时性 Blob 存储(而不是 Kusto),则由调用方负责创建 Blob。 这包括预配存储、轮换访问密钥以及删除临时工件。 KustoBlobStorageUtils 模块包含用于以下用途的帮助程序函数:基于帐户和容器坐标以及帐户凭据(或基于具有写入、读取和列出权限的完整 SAS URL)删除 Blob。 当不再需要相应的 RDD 时,每个事务会将暂时性 blob 项目存储在一个单独的目录中。 此目录是作为 Spark 驱动程序节点上报告的读取事务信息日志的一部分捕获的。
// Use either container/account-key/account name, or container SaS val container = dbutils.secrets.get(scope = "KustoDemos", key = "blobContainer") val storageAccountKey = dbutils.secrets.get(scope = "KustoDemos", key = "blobStorageAccountKey") val storageAccountName = dbutils.secrets.get(scope = "KustoDemos", key = "blobStorageAccountName") // val storageSas = dbutils.secrets.get(scope = "KustoDemos", key = "blobStorageSasUrl")在上面的示例中,并未使用连接器接口访问 Key Vault,而是采用了一种更简单的方法来使用 Databricks secrets。
从 Kusto 读取。
如果你提供暂时性 blob 存储,请如下所示从 Kusto 读取:
val conf3 = Map( KustoSourceOptions.KUSTO_AAD_APP_ID -> appId, KustoSourceOptions.KUSTO_AAD_APP_SECRET -> appKey KustoSourceOptions.KUSTO_BLOB_STORAGE_SAS_URL -> storageSas) val df2 = spark.read.kusto(cluster, database, "ReallyBigTable", conf3) val dfFiltered = df2 .where(df2.col("ColA").startsWith("row-2")) .filter("ColB > 12") .filter("ColB <= 21") .select("ColA") display(dfFiltered)如果 Kusto 提供暂时性 blob 存储,请从 Kusto 读取,如下所示:
val conf3 = Map( KustoSourceOptions.KUSTO_AAD_CLIENT_ID -> appId, KustoSourceOptions.KUSTO_AAD_CLIENT_PASSWORD -> appKey) val df2 = spark.read.kusto(cluster, database, "ReallyBigTable", conf3) val dfFiltered = df2 .where(df2.col("ColA").startsWith("row-2")) .filter("ColB > 12") .filter("ColB <= 21") .select("ColA") display(dfFiltered)