你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
适用于: Azure 数据工厂 Azure Synapse Analytics
Azure 数据工厂 Azure Synapse Analytics
提示
试用 Microsoft Fabric 中的数据工厂,这是一种适用于企业的一站式分析解决方案。 Microsoft Fabric 涵盖从数据移动到数据科学、实时分析、商业智能和报告的所有内容。 了解如何免费开始新的试用!
本文概述了如何在 Azure 数据工厂中使用复制活动从 Amazon RDS for Oracle 数据库复制数据。 本文是在复制活动概述的基础上编写的。
重要
Amazon RDS for Oracle 连接器版本 2.0 增强了对本机 Amazon RDS for Oracle 的支持。 如果在解决方案中使用 Amazon RDS for Oracle 连接器版本 1.0,请在 2025 年 10 月 31 日之前升级 Amazon RDS for Oracle 连接器。 有关版本 2.0 和版本 1.0 之间差异的详细信息,请参阅此部分。
支持的功能
此 Amazon RDS for Oracle 连接器支持以下功能:
| 支持的功能 | 红外线 |
|---|---|
| 复制活动(源/-) | (1) (2) |
| Lookup 活动 | (1) (2) |
① Azure 集成运行时 ② 自承载集成运行时
有关复制活动支持作为源或接收器的数据存储列表,请参阅支持的数据存储表。
具体而言,此 Amazon RDS for Oracle 连接器支持:
- 适用于 2.0 版的 Amazon RDS for Oracle 数据库的以下版本:
- Amazon RDS for Oracle 19c 或更高版本
- 以下是适用于 Oracle 数据库的 Amazon RDS 1.0 版本:
- Amazon RDS for Oracle 19c R1 (19.1) 和更高版本
- Amazon RDS for Oracle 18c R1 (18.1) 和更高版本
- Amazon RDS for Oracle 12c R1 (12.1) 和更高版本
- Amazon RDS for Oracle 11g R1 (11.1) 和更高版本
- 从 Amazon RDS for Oracle 源进行并行复制。 有关详细信息,请参阅从 Amazon RDS for Oracle 进行并行复制部分。
注意
不支持 Amazon RDS for Oracle 代理服务器。
先决条件
如果数据存储位于本地网络、Azure 虚拟网络或 Amazon Virtual Private Cloud 内部,则需要配置自承载集成运行时才能连接到该数据存储。
如果数据存储是托管的云数据服务,则可以使用 Azure Integration Runtime。 如果访问范围限制为防火墙规则中允许的 IP,你可以选择将 Azure Integration Runtime IP 添加到允许列表。
此外,还可以使用 Azure 数据工厂中的托管虚拟网络集成运行时功能访问本地网络,而无需安装和配置自承载集成运行时。
要详细了解网络安全机制和数据工厂支持的选项,请参阅数据访问策略。
集成运行时提供内置的 Amazon RDS for Oracle 驱动程序。 因此,在从 Amazon RDS for Oracle 复制数据时不需要手动安装驱动程序。
入门
若要使用管道执行复制活动,可以使用以下工具或 SDK 之一:
使用 UI 创建到 Amazon RDS for Oracle 的链接服务
使用以下步骤在 Azure 门户 UI 中创建一个到 Amazon RDS for Oracle 的链接服务。
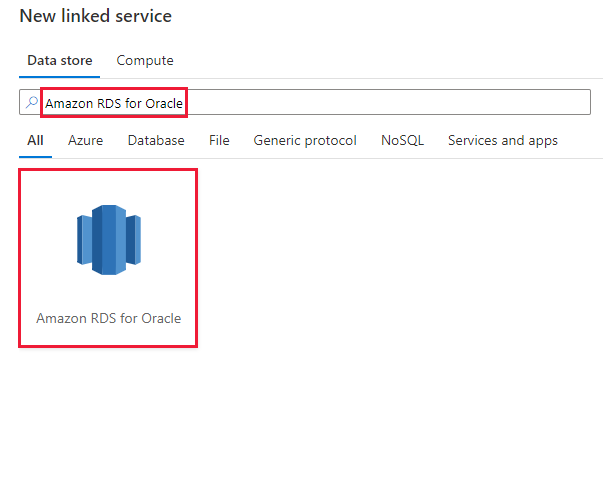
浏览到 Azure 数据工厂或 Synapse 工作区中的“管理”选项卡并选择“链接服务”,然后单击“新建”:
搜索 Amazon RDS for Oracle 并选择 Amazon RDS for Oracle 连接器。
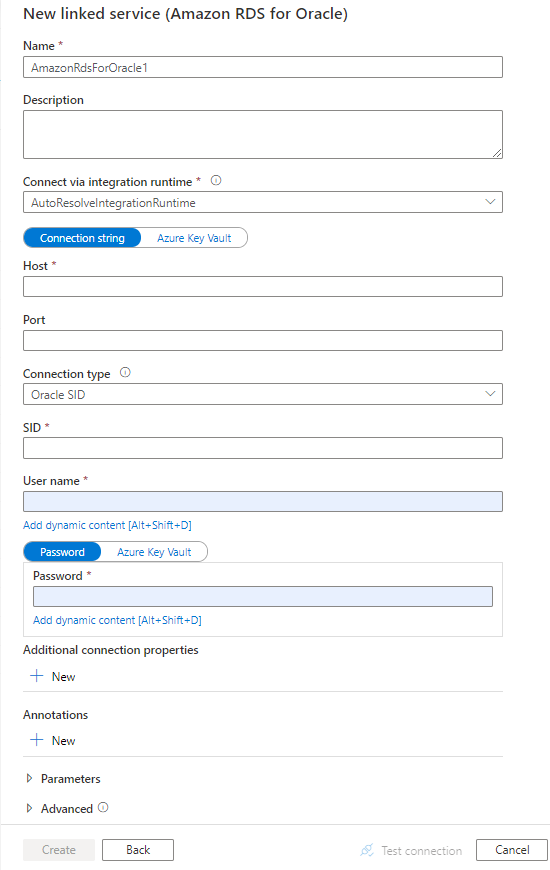
配置服务详细信息、测试连接并创建新的链接服务。
连接器配置详细信息
对于特定于 Amazon RDS for Oracle 连接器的实体,以下部分提供了有关用于定义这些实体的属性的详细信息。
链接服务属性
Amazon RDS for Oracle 连接器版本 2.0 支持 TLS 1.3。 请参阅本 部分,将 Amazon RDS for Oracle 连接器从 1.0 版本升级到更高版本。 关于属性详情,请参阅对应部分。
版本 2.0
应用版本 2.0 时,Amazon RDS for Oracle 链接服务支持以下属性:
| 属性 | 描述 | 必需 |
|---|---|---|
| 类型 | type 属性必须设置为 AmazonRdsForOracle。 | 是 |
| 版本 | 指定的版本。 该值为 2.0。 |
是 |
| 服务器 | 您想要连接的 Amazon RDS for Oracle 数据库的位置。 可以引用 服务器属性配置 来指定它。 | 是 |
| 验证类型 | 用于连接到 Amazon RDS for Oracle 数据库的身份验证类型。 现在仅支持 基本 身份验证。 | 是 |
| 用户名 | Amazon RDS for Oracle 数据库用户名。 | 是 |
| 密码 | Amazon RDS for Oracle 数据库密码。 将此字段标记为 SecureString 以安全存储它。 或者,可以引用 Azure Key Vault 中存储的机密。 | 是 |
| connectVia | 用于连接到数据存储的集成运行时。 在先决条件部分了解更多信息。 如果未指定,则使用默认 Azure Integration Runtime。 | 否 |
可以按案例在链接服务中设置的更多连接属性:
| 属性 | 描述 | 必需 | 默认值 |
|---|---|---|---|
| 加密客户端 | 指定加密客户端的行为。 支持的值是accepted、rejected或requestedrequired。 类型:字符串 |
否 | required |
| encryptionTypesClient | 指定客户端可以使用的加密算法。 支持的值是AES128,,AES192,AES256,3DES1123DES168。 类型:字符串 |
否 | (AES256) |
| cryptoChecksumClient | 指定当此客户端连接到服务器时所需的数据完整性行为。 支持的值是accepted、rejected或requestedrequired。 类型:字符串 |
否 | required |
| cryptoChecksumTypes客户端 | 指定客户端可以使用的加密校验算法。 支持的值为 SHA1,, SHA256SHA384。 SHA512 类型:字符串 |
否 | (SHA512) |
| initialLobFetchSize (初始LOB提取大小) | 指定源最初为 LOB 列提取的量。 类型:int | 否 | 0 |
| fetchSize | 指定驱动程序分配的字节数,用于在一次数据库往返操作中提取数据。 类型:int | 否 | 10 MB |
| 声明缓存大小 | 指定要为每个数据库连接缓存的游标或语句的数量。 类型:int | 否 | 0 |
| initializationString | 指定一个命令,该命令在连接数据库后立即执行,以管理会话设置。 类型:字符串 | 否 | Null |
| enableBulkLoad | 指定在将数据加载到数据库中时是使用大容量复制还是批量插入。 类型:布尔值 | 否 | 是 |
| supportV1DataTypes | 指定是否使用版本 1.0 数据类型映射。 除非要保持与版本 1.0 数据类型映射的向后兼容性,否则不要将其设置为 true。 类型:布尔值 | 否,此属性仅用于向后兼容性使用 | 假 |
| 获取Tswtz作为时间戳 | 指定驱动程序是否将 TIMESTAMP WITH TIME ZONE 数据类型的列值作为 DateTime 或字符串返回。 如果 supportV1DataTypes 不为 true,则忽略此设置。 类型:布尔值 | 否,此属性仅用于向后兼容性使用 | 是 |
示例:
{
"name": "AmazonRdsForOracleLinkedService",
"properties": {
"type": "AmazonRdsForOracle",
"version": "2.0",
"typeProperties": {
"server": "<server name>",
"username": "<user name>",
"password": "<password>",
"authenticationType": "<authentication type>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
示例:在 Azure 密钥保管库中存储密码
{
"name": "AmazonRdsForOracleLinkedService",
"properties": {
"type": "AmazonRdsForOracle",
"version": "2.0",
"typeProperties": {
"server": "<server name>",
"username": "<user name>",
"authenticationType": "<authentication type>",
"password": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
server属性配置
对于 server 属性,可以使用以下三种格式之一指定它:
| 格式 | 示例: |
|---|---|
| 连接描述符 | (DESCRIPTION=(ADDRESS=(PROTOCOL=tcp)(HOST=sales-server)(PORT=1521)(CONNECT_DATA=(SERVICE_NAME=sales.us.acme.com)) |
| Easy Connect (Plus) 命名 | salesserver1:1521/sales.us.example.com |
| Oracle Net Services 名称 (TNS 别名) (仅适用于本地集成运行时) | 销售额 |
以下列表显示了server中受支持的参数。 如果使用的参数不在以下列表中,则连接将失败。
使用 Azure 集成运行时时:
主机
港口
协议
服务名称
SID
INSTANCE_NAME
服务器
CONNECT_TIMEOUT
重试次数 (RETRY_COUNT)
RETRY_DELAY
SSL版本
SSL_SERVER_DN_MATCH
SSL_服务器_证书_DN当使用自承载集成运行时:
主机
港口
协议
使
过期时间
故障转移
负载均衡
RECV_BUF_SIZE
山东大学 (SDU)
SEND_BUF_SIZE
来源路径
服务类型
COLOCATION_TAG
CONNECTION_ID_PREFIX
FAILOVER_MODE
GLOBAL_NAME
高中
INSTANCE_NAME
泳池边界
POOL_CONNECTION_CLASS
泳池名称
泳池纯度
RDB_DATABASE
SHARDING_KEY
SHARDING_KEY_ID
SUPER_SHARDING_KEY
服务器
服务名称
SID
隧道服务名称
SSL_客户端认证
SSL_CERTIFICATE_ALIAS
SSL_CERTIFICATE_THUMBPRINT
SSL版本
SSL_SERVER_DN_MATCH
SSL_服务器_证书_DN
钱包位置
CONNECT_TIMEOUT
重试次数 (RETRY_COUNT)
RETRY_DELAY
TRANSPORT_CONNECT_TIMEOUT
RECV_TIMEOUT
压缩
压缩级别
版本 1.0
应用版本 1.0 时,Amazon RDS for Oracle 链接服务支持以下属性:
| 属性 | 描述 | 必需 |
|---|---|---|
| 类型 | type 属性必须设置为 AmazonRdsForOracle。 | 是 |
| connectionString 连接字符串 | 指定连接到 Amazon RDS for Oracle 数据库实例所需的信息。 还可以将密码放在 Azure Key Vault 中,并从连接字符串中拉取 password 配置。 有关更多详细信息,请参阅以下示例和在 Azure Key Vault 中存储凭据。 支持的连接类型:可以使用“Amazon RDS for Oracle SID”或 “Amazon RDS for Oracle 服务名称”来标识数据库: - 如果使用 SID: Host=<host>;Port=<port>;Sid=<sid>;User Id=<username>;Password=<password>;- 如果使用服务名称: Host=<host>;Port=<port>;ServiceName=<servicename>;User Id=<username>;Password=<password>;对于高级 Amazon RDS for Oracle 本机连接选项,可以选择在 Amazon RDS for Oracle 服务器上的 TNSNAMES.ORA 文件中添加条目,在 Amazon RDS for Oracle 链接服务中,可以选择使用“Amazon RDS for Oracle 服务名称”连接类型并配置相应的服务名称。 |
是 |
| connectVia | 用于连接到数据存储的集成运行时。 在先决条件部分了解更多信息。 如果未指定,则使用默认 Azure Integration Runtime。 | 否 |
如果故障转移方案中有多个 Amazon RDS for Oracle 实例,可以创建 Amazon RDS for Oracle 链接服务并填写主要主机、端口、用户名、密码等,并添加新的“其他连接属性”,其属性名称为 ,值为 AlternateServers,请勿遗漏括号,并注意使用冒号 ((HostName=<secondary host>:PortNumber=<secondary port>:ServiceName=<secondary service name>)) 作为分隔符。 例如,以下备用服务器值定义用于连接故障转移的两台备用数据库服务器:(HostName=AccountingAmazonRdsForOracleServer:PortNumber=1521:SID=Accounting,HostName=255.201.11.24:PortNumber=1522:ServiceName=ABackup.NA.MyCompany)。
可以根据自己的情况在连接字符串中设置更多连接属性:
| 属性 | 描述 | 允许的值 |
|---|---|---|
| ArraySize | 连接器在单个网络往返中可以提取的字节数。 例如 ArraySize=10485760。较大的值可减少在网络中提取数据的次数,从而提高吞吐量。 较小的值会增加响应时间,因为等待服务器传输数据的延迟较小。 |
1 到 4294967296 (4 GB) 之间的一个整数。 默认值为 60000。 值 1 不定义字节数,而指示仅为一行数据分配空间。 |
若要在 Amazon RDS for Oracle 连接上启用加密,你有两种选择:
若要使用“三重 DES 加密 (3DES) 和高级加密标准 (AES)”,在 Amazon RDS for Oracle 服务器端,转到“Oracle 高级安全性 (OAS)”并配置加密设置。 有关详细信息,请参阅 Oracle 文档。 Amazon RDS for Oracle 应用程序开发框架 (ADF) 连接器会自动协商加密方法,以便在建立与 Amazon RDS for Oracle 的连接时使用在 OAS 中配置的加密方法。
若要使用 TLS ,请执行以下操作:
获取 TLS/SSL 证书信息。 获取 TLS/SSL 证书的可辨别编码规则 (DER) 编码证书信息,并将输出 (----- Begin Certificate … End Certificate -----) 保存为文本文件。
openssl x509 -inform DER -in [Full Path to the DER Certificate including the name of the DER Certificate] -text示例: 从 DERcert.cer 提取证书信息;然后,将输出保存到 cert.txt。
openssl x509 -inform DER -in DERcert.cer -text Output: -----BEGIN CERTIFICATE----- XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX XXXXXXXXX -----END CERTIFICATE-----生成
keystore或truststore。 以下命令使用或不使用 PKCS-12 格式的密码来创建truststore文件。openssl pkcs12 -in [Path to the file created in the previous step] -out [Path and name of TrustStore] -passout pass:[Keystore PWD] -nokeys -export示例: 使用密码创建名为 MyTrustStoreFile 的 PKCS12
truststore文件。openssl pkcs12 -in cert.txt -out MyTrustStoreFile -passout pass:ThePWD -nokeys -export将
truststore文件放在自承载 IR 计算机上。 例如,将该文件放在 C:\MyTrustStoreFile。在服务中,使用
EncryptionMethod=1和相应的TrustStore/TrustStorePassword值配置 Amazon RDS for Oracle 连接字符串。 例如Host=<host>;Port=<port>;Sid=<sid>;User Id=<username>;Password=<password>;EncryptionMethod=1;TrustStore=C:\\MyTrustStoreFile;TrustStorePassword=<trust_store_password>。
示例:
{
"name": "AmazonRdsForOracleLinkedService",
"properties": {
"type": "AmazonRdsForOracle",
"typeProperties": {
"connectionString": "Host=<host>;Port=<port>;Sid=<sid>;User Id=<username>;Password=<password>;"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
示例:在 Azure 密钥保管库中存储密码
{
"name": "AmazonRdsForOracleLinkedService",
"properties": {
"type": "AmazonRdsForOracle",
"typeProperties": {
"connectionString": "Host=<host>;Port=<port>;Sid=<sid>;User Id=<username>;",
"password": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
数据集属性
本部分提供 Amazon RDS for Oracle 数据集支持的属性列表。 有关可用于定义数据集的各个部分和属性的完整列表,请参阅数据集。
若要从 Amazon RDS for Oracle 复制数据,请将数据集的 type 属性设置为 AmazonRdsForOracleTable。 支持以下属性。
| 属性 | 描述 | 必需 |
|---|---|---|
| 类型 | 数据集的 type 属性必须设置为 AmazonRdsForOracleTable。 |
是 |
| 图式 | 架构的名称。 | 否 |
| 表 | 表/视图的名称。 | 否 |
| 表名称 | 具有架构的表/视图的名称。 此属性支持后向兼容性。 对于新的工作负荷,请使用 schema 和 table。 |
否 |
示例:
{
"name": "AmazonRdsForOracleDataset",
"properties":
{
"type": "AmazonRdsForOracleTable",
"schema": [],
"typeProperties": {
"schema": "<schema_name>",
"table": "<table_name>"
},
"linkedServiceName": {
"referenceName": "<Amazon RDS for Oracle linked service name>",
"type": "LinkedServiceReference"
}
}
}
复制活动属性
本部分提供 Amazon RDS for Oracle 源支持的属性列表。 有关可用于定义活动的各个部分和属性的完整列表,请参阅管道。
Amazon RDS for Oracle 作为源
提示
若要使用数据分区从 Amazon RDS for Oracle 高效加载数据,请参阅从 Amazon RDS for Oracle 进行并行复制了解详细信息。
要从 Amazon RDS for Oracle 复制数据,请将复制活动中的源类型设置为 AmazonRdsForOracleSource。 复制活动的 source 节支持以下属性。
| 属性 | 描述 | 必需 |
|---|---|---|
| 类型 | 复制活动 source 的 type 属性必须设置为 AmazonRdsForOracleSource。 |
是 |
| oracleReaderQuery | 使用自定义 SQL 查询读取数据。 例如 "SELECT * FROM MyTable"。启用分区加载时,需要在查询中挂接任何相应的内置分区参数。 例如,请参阅从 Amazon RDS for Oracle 进行并行复制部分。 |
否 |
| 将小数转换为整数 | 使用零标度或未指定标度的 Amazon RDS for Oracle NUMBER 类型将转换为相应的整数。 允许的值为 true 和 true(默认值)。 如果使用 Amazon RDS for Oracle 版本 2.0,则仅当 supportV1DataTypes 为 true 时,才允许设置此属性。 |
否 |
| 分区选项 | 指定用于从 Amazon RDS for Oracle 加载数据的数据分区选项。 允许值包括:None(默认值)、PhysicalPartitionsOfTable 和 DynamicRange 。 启用分区选项(即该选项不为 None)时,从 Amazon RDS for Oracle 数据库并行加载数据的并行度由复制活动上的 parallelCopies 设置控制。 |
否 |
| 分区设置 | 指定数据分区的设置组。 当分区选项不是 None 时适用。 |
否 |
| partitionNames (分区名称) | 需要复制的物理分区的列表。 当分区选项是 PhysicalPartitionsOfTable 时适用。 如果使用查询来检索源数据,请在 WHERE 子句中挂接 ?AdfTabularPartitionName。 例如,请参阅从 Amazon RDS for Oracle 进行并行复制部分。 |
否 |
| partitionColumnName (分区列名称) | 指定并行复制范围分区使用的源列(整数类型)的名称。 如果未指定,系统会自动检测表的主键并将其用作分区列。 当分区选项是 DynamicRange 时适用。 如果使用查询来检索源数据,请在 WHERE 子句中挂接 ?AdfRangePartitionColumnName。 例如,请参阅从 Amazon RDS for Oracle 进行并行复制部分。 |
否 |
| partitionUpperBound 分区上限 | 要从中复制数据的分区列的最大值。 当分区选项是 DynamicRange 时适用。 如果使用查询来检索源数据,请在 WHERE 子句中挂接 ?AdfRangePartitionUpbound。 例如,请参阅从 Amazon RDS for Oracle 进行并行复制部分。 |
否 |
| partitionLowerBound | 要从中复制数据的分区列的最小值。 当分区选项是 DynamicRange 时适用。 如果使用查询来检索源数据,请在 WHERE 子句中挂接 ?AdfRangePartitionLowbound。 例如,请参阅从 Amazon RDS for Oracle 进行并行复制部分。 |
否 |
示例:使用基本查询但不使用分区复制数据
"activities":[
{
"name": "CopyFromAmazonRdsForOracle",
"type": "Copy",
"inputs": [
{
"referenceName": "<Amazon RDS for Oracle input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "AmazonRdsForOracleSource",
"convertDecimalToInteger": false,
"oracleReaderQuery": "SELECT * FROM MyTable"
},
"sink": {
"type": "<sink type>"
}
}
}
]
从 Amazon RDS for Oracle 进行并行复制
Amazon RDS for Oracle 连接器提供内置的数据分区,用于从 Amazon RDS for Oracle 并行复制数据。 可以在复制活动的“源”表中找到数据分区选项。
启用分区复制后,服务将对 Amazon RDS for Oracle 源运行并行查询,按分区加载数据。 可通过复制活动中的 parallelCopies 设置控制并行度。 例如,如果将 parallelCopies 设置为 4,该服务会根据指定的分区选项和设置并行生成并运行 4 个查询,每个查询从 Amazon RDS for Oracle 数据库检索一部分数据。
建议同时启用并行复制和数据分区,尤其是从 Amazon RDS for Oracle 数据库加载大量数据时。 下面是适用于不同方案的建议配置。 将数据复制到基于文件的数据存储中时,建议将数据作为多个文件写入文件夹(仅指定文件夹名称),在这种情况下,性能优于写入单个文件。
| 方案 | 建议的设置 |
|---|---|
| 从包含物理分区的大型表进行完整加载。 |
分区选项:表的物理分区。 在执行期间,该服务将自动检测物理分区并按分区复制数据。 |
| 从不包含物理分区但包含用于数据分区的整数列的大型表进行完整加载。 |
分区选项:动态范围分区。 分区列:指定用于对数据进行分区的列。 如果未指定,将使用主键列。 |
| 使用自定义查询从包含物理分区的表加载大量数据。 |
分区选项:表的物理分区。 查询: SELECT * FROM <TABLENAME> PARTITION("?AdfTabularPartitionName") WHERE <your_additional_where_clause>。分区名称:指定要从中复制数据的分区名称。 如果没有指定,服务将自动检测在 Amazon RDS for Oracle 数据集中指定的表的物理分区。 在执行期间,服务会将 ?AdfTabularPartitionName 替换为实际分区名称,并发送到 Amazon RDS for Oracle。 |
| 使用自定义查询从不包含物理分区但包含用于数据分区的整数列的表加载大量数据。 |
分区选项:动态范围分区。 查询: SELECT * FROM <TABLENAME> WHERE ?AdfRangePartitionColumnName <= ?AdfRangePartitionUpbound AND ?AdfRangePartitionColumnName >= ?AdfRangePartitionLowbound AND <your_additional_where_clause>。分区列:指定用于对数据进行分区的列。 可以针对整数数据类型的列进行分区。 分区上限和分区下限:指定是否要对分区列进行筛选,以便仅检索介于下限和上限之间的数据。 在执行期间,服务会将 ?AdfRangePartitionColumnName、?AdfRangePartitionUpbound 和 ?AdfRangePartitionLowbound 替换为每个分区的实际列名称和值范围,并发送到 Amazon RDS for Oracle。 例如,如果为分区列“ID”设置了下限 1、上限 80,并将并行复制设置为 4,则服务会按 4 个分区检索数据。 其 ID 分别介于 [1, 20]、[21, 40]、[41, 60] 和 [61, 80] 之间。 |
提示
从非分区表复制数据时,可以使用“动态范围”分区选项针对整数列进行分区。 如果源数据没有这种类型的列,则可以利用源查询中的 ORA_HASH 函数来生成列,并将其用作分区列。
示例:使用物理分区进行查询
"source": {
"type": "AmazonRdsForOracleSource",
"query": "SELECT * FROM <TABLENAME> PARTITION(\"?AdfTabularPartitionName\") WHERE <your_additional_where_clause>",
"partitionOption": "PhysicalPartitionsOfTable",
"partitionSettings": {
"partitionNames": [
"<partitionA_name>",
"<partitionB_name>"
]
}
}
示例:使用动态范围分区进行查询
"source": {
"type": "AmazonRdsForOracleSource",
"query": "SELECT * FROM <TABLENAME> WHERE ?AdfRangePartitionColumnName <= ?AdfRangePartitionUpbound AND ?AdfRangePartitionColumnName >= ?AdfRangePartitionLowbound AND <your_additional_where_clause>",
"partitionOption": "DynamicRange",
"partitionSettings": {
"partitionColumnName": "<partition_column_name>",
"partitionUpperBound": "<upper_value_of_partition_column>",
"partitionLowerBound": "<lower_value_of_partition_column>"
}
}
Amazon RDS for Oracle 的数据类型映射
从/向 Amazon RDS for Oracle 复制数据时,服务中会使用以下临时数据类型映射。 若要了解复制活动如何将源架构和数据类型映射到接收器,请参阅架构和数据类型映射。
| Amazon RDS for Oracle 数据类型 | 临时服务数据类型(适用于版本 2.0) | 临时服务数据类型(适用于版本 1.0) |
|---|---|---|
| BFILE | Byte[] | Byte[] |
| BINARY_FLOAT | 单身 | 单身 |
| 双精度二进制 | 加倍 | 加倍 |
| BLOB | Byte[] | Byte[] |
| 煳 | 字符串 | 字符串 |
| CLOB | 字符串 | 字符串 |
| 日期 | DateTime | DateTime |
| FLOAT (P < 16) | 加倍 | 加倍 |
| FLOAT (P >= 16) | 十进制 | 加倍 |
| 年到月间隔 | Int64 | 字符串 |
| 时间跨度从天到秒 | TimeSpan | 字符串 |
| 长 | 字符串 | 字符串 |
| LONG RAW | Byte[] | Byte[] |
| NCHAR | 字符串 | 字符串 |
| NCLOB | 字符串 | 字符串 |
| NUMBER (p,s) | Int16、Int32、Int64、Double、Single、Decimal | 十进制,字符串(如果 p > 28) |
| NUMBER(没有精度和小数位数) | 十进制 | 加倍 |
| NVARCHAR2 | 字符串 | 字符串 |
| 生 | Byte[] | Byte[] |
| 时间戳 | DateTime | DateTime |
| 具有本地时区的时间戳 | DateTime | DateTime |
| 时间戳与时区 | 日期时间偏移 (DateTimeOffset) | DateTime |
| VARCHAR2 | 字符串 | 字符串 |
| XML类型 | 字符串 | 字符串 |
注意
NUMBER (p,s) 根据精度 (p) 和小数位数 (s) 映射到适当的临时服务数据类型。
Lookup 活动属性
若要了解有关属性的详细信息,请查看 Lookup 活动。
升级 Amazon RDS for Oracle 连接器
下面是帮助你升级 Amazon RDS for Oracle 连接器的步骤:
在 “编辑链接服务 ”页中,选择版本 2.0,并通过引用 链接服务属性版本 2.0 配置链接服务。
对于身份验证相关属性(包括用户名和密码),请在版本 2.0 中的相应字段中指定原始值。 其他连接属性(例如主机、端口,以及在版本 1.0 中的 Amazon RDS for Oracle 服务名/Amazon RDS for Oracle SID)现在在版本 2.0 中属于
server属性的参数。例如,如果将版本 1.0 的连接服务配置如下:
{ "name": "AmazonRdsForOracleLinkedService", "properties": { "type": "AmazonRdsForOracle", "typeProperties": { "connectionString": "host=amazonrdsfororaclesample.com;port=1521;servicename=db1" }, "connectVia": { "referenceName": "<name of Integration Runtime>", "type": "IntegrationRuntimeReference" } } }使用 Easy Connect (Plus) 命名 的相同版本 2.0 链接服务配置为:

{ "name": "AmazonRdsForOracleLinkedService", "properties": { "type": "AmazonRdsForOracle", "version": "2.0", "typeProperties": { "server": "amazonrdsfororaclesample.com:1521/db1", "username": "<user name>", "password": "<password>", "authenticationType": "<authentication type>" }, "connectVia": { "referenceName": "<name of Integration Runtime>", "type": "IntegrationRuntimeReference" } } }使用 连接器描述符 的相同版本 2.0 链接服务配置为:

{ "name": "AmazonRdsForOracleLinkedService", "properties": { "type": "AmazonRdsForOracle", "version": "2.0", "typeProperties": { "server": "(DESCRIPTION=(ADDRESS=(PROTOCOL=tcp)(HOST= amazonrdsfororaclesample.com)(PORT=1521))(CONNECT_DATA=(SERVICE_NAME=db1)))", "username": "<user name>", "password": "<password>", "authenticationType": "<authentication type>" }, "connectVia": { "referenceName": "<name of Integration Runtime>", "type": "IntegrationRuntimeReference" } } }提示
Azure Key Vault 支持
server属性。 可以编辑链接服务 JSON 以添加 Azure Key Vault 引用,如下所示:

请注意:
如果在版本 1.0 中使用 Oracle 服务名称 ,则可以使用 Easy Connect (Plus) 命名 或 连接器描述符 作为版本 2.0 中的服务器格式。
如果在版本 1.0 中使用 Oracle SID ,则需要使用 连接器描述符 作为版本 2.0 中的服务器格式。
对于版本 1.0 中的一些附加连接属性,我们在版本 2.0 中的
server属性中提供替代属性或参数。 可以参考下表来升级版本 1.0 属性。版本 1.0 版本 2.0 加密方法 协议(参数在 server中)tnsnamesfile TNS_ADMIN(自承载集成运行时支持的环境变量) 服务器名称 服务器 enablebulkload
值:1、0enableBulkLoad
值:true、falsefetchtswtzastimestamp
值:1、0fetchTswtzAsTimestamp
值:true、false备用服务器 DESCRIPTION_LIST( server中的参数)数组大小 fetchSize cachedcursorlimit 声明缓存大小 connectionretrycount RETRY_COUNT( server中的参数)初始化字符串 initializationString loginTimeout CONNECT_TIMEOUT( server中的参数)cryptoprotocolversion SSL_VERSION (参数位于 server中)truststore WALLET_LOCATION( server中的参数)例如,如果在
alternateservers版本 1.0 中使用,则可以在版本 2.0 的服务器属性中设置DESCRIPTION_LIST参数:使用
alternateservers的 1.0 版链接服务:{ "name": "AmazonRdsForOracleV1", "properties": { "type": "AmazonRdsForOracle", "typeProperties": { "connectionString": "host=amazonrdsfororaclesample.com;port=1521;servicename=db1;alternateservers=(HostName= amazonrdsfororaclesample2.com:PortNumber=1521:SID=db2,HostName=255.201.11.24:PortNumber=1522:ServiceName=db3)" } } }在“连接器描述符”中使用
DESCRIPTION_LIST参数的相同 2.0 版本链接服务:{ "name": "AmazonRdsForOracleV2", "properties": { "type": "AmazonRdsForOracle", "version": "2.0", "typeProperties": { "server": "(DESCRIPTION_LIST=(DESCRIPTION=(ADDRESS=(PROTOCOL=tcp)(HOST=amazonrdsfororaclesample.com)(PORT=1521))(CONNECT_DATA=(SERVICE_NAME=db1)))(DESCRIPTION=(ADDRESS=(PROTOCOL=tcp)(HOST=amazonrdsfororaclesample2.com)(PORT=1521))(CONNECT_DATA=(SID=db2)))(DESCRIPTION=(ADDRESS=(PROTOCOL=tcp)(HOST=255.201.11.24)(PORT=1522))(CONNECT_DATA=(SERVICE_NAME=db3))))", "username": "<user name>", "password": "<password>", "authenticationType": "<authentication type>" } } }
Amazon RDS for Oracle 链接服务版本 2.0 的数据类型映射不同于版本 1.0 的数据类型映射。 若要了解最新的数据类型映射,请参阅 Amazon RDS for Oracle 的数据类型映射。
版本 2.0 中的其他连接属性
supportV1DataTypes可以减少数据类型更改导致的升级困难。 设置此属性可确保true版本 2.0 中的数据类型与版本 1.0 保持一致。
Amazon RDS for Oracle 版本 2.0 和版本 1.0 之间的差异
Amazon RDS for Oracle 连接器版本 2.0 提供新功能,并且与版本 1.0 的大多数功能兼容。 下表显示了版本 2.0 和版本 1.0 之间的功能差异。
| 版本 2.0 | 版本 1.0 |
|---|---|
| 以下映射用于从 Amazon RDS for Oracle 数据类型到服务内部使用的临时服务数据类型。 NUMBER(p,s)-> Int16、Int32、Int64、Double、Single、Decimal FLOAT(p)-> 基于其精度的 Double 或 Decimal NUMBER -> 十进制 TIMESTAMP WITH TIME ZONE -> DateTimeOffset INTERVAL YEAR TO MONTH -> Int64 间隔 天 到 秒 -> 时间跨度 |
以下映射用于从 Amazon RDS for Oracle 数据类型到服务内部使用的临时服务数据类型。 NUMBER (p,s) -> 基于其精度为 Decimal String FLOAT(p)-> Double NUMBER -> Double TIMESTAMP WITH TIME ZONE -> DateTime INTERVAL YEAR TO MONTH -> String 时间间隔从天到秒 -> 字符串 |
当 supportV1DataTypes 设置为 true 时,支持在复制源中使用 convertDecimalToInteger。 |
支持复制源中的 convertDecimalToInteger。 |
| 支持 TLS 1.3。 | 不支持 TLS 1.3。 |
相关内容
有关复制活动支持作为源和接收器的数据存储的列表,请参阅受支持的数据存储。