你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
适用于: Azure 数据工厂 Azure Synapse Analytics
Azure 数据工厂 Azure Synapse Analytics
提示
试用 Microsoft Fabric 中的数据工厂,这是一种适用于企业的一站式分析解决方案。 Microsoft Fabric 涵盖从数据移动到数据科学、实时分析、商业智能和报告的所有内容。 了解如何免费开始新的试用!
本文概述如何使用 Azure 数据工厂或 Synapse Analytics 管道中的复制活动将数据复制到 Azure AI 搜索索引。 它是基于概述复制活动总体的复制活动概述一文。
支持的功能
此 Azure AI 搜索连接器支持以下功能:
| 支持的功能 | IR | 托管专用终结点 |
|---|---|---|
| 复制活动(-/接收器) | ① ② | ✓ |
① Azure 集成运行时 ② 自承载集成运行时
可以将数据从任何支持的源数据存储复制到搜索索引中。 有关复制活动支持作为源/接收器的数据存储列表,请参阅支持的数据存储表。
入门
若要使用管道执行复制活动,可以使用以下工具或 SDK 之一:
使用 UI 创建到 Azure 搜索的链接服务
使用以下步骤在 Azure 门户 UI 中创建一个到 Azure 搜索的链接服务。
浏览到 Azure 数据工厂或 Synapse 工作区中的“管理”选项卡,并选择“链接服务”,然后单击“新建”:
搜索“搜索”并选择 Azure 搜索连接器。
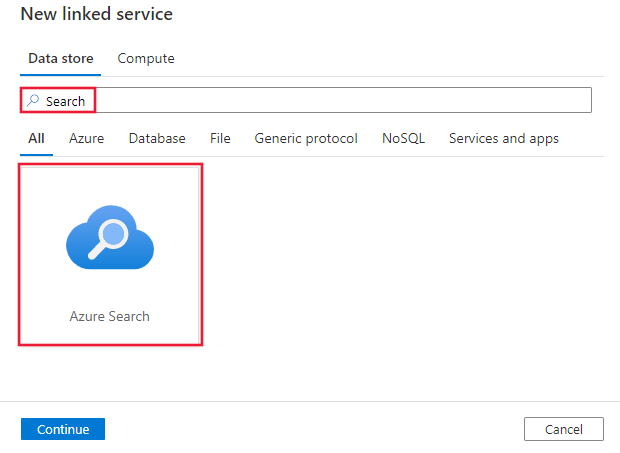
配置服务详细信息、测试连接并创建新的链接服务。
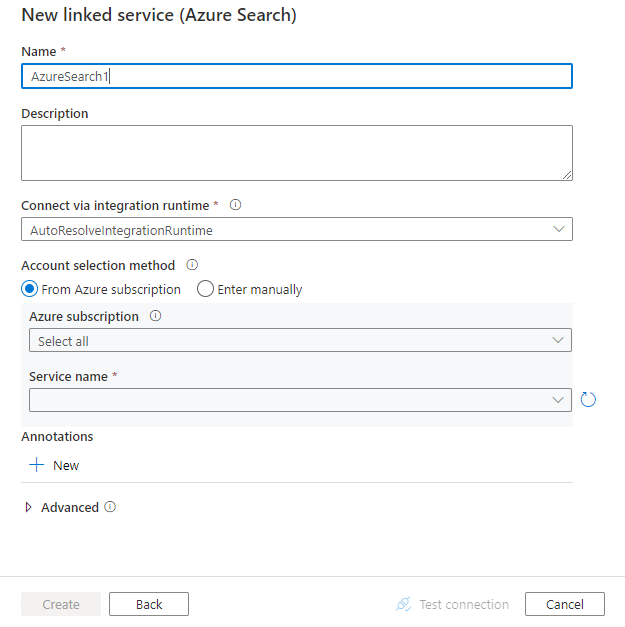
连接器配置详细信息
对于特定于 Azure AI 搜索连接器的数据工厂实体,以下部分提供了有关用于定义这些实体的属性的详细信息。
链接服务属性
Azure AI 搜索链接服务支持以下属性:
| properties | 描述 | 必需 |
|---|---|---|
| type | type 属性必须设置为:AzureSearch | 是 |
| url | 搜索服务的 URL。 | 是 |
| key | 搜索服务的管理密钥。 将此字段标记为 SecureString 以安全地存储它,或引用存储在 Azure Key Vault 中的机密。 | 是 |
| connectVia | 用于连接到数据存储的集成运行时。 如果数据存储位于专用网络,则可以使用 Azure Integration Runtime 或自承载集成运行时。 如果未指定,则使用默认 Azure Integration Runtime。 | 否 |
重要
将数据从云数据存储复制到搜索索引时,在 Azure AI 搜索链接服务中,需要使用 connectVia 中的显式区域引用 Azure Integration Runtime。 将区域设置为搜索服务所在的区域。 从 Azure Integration Runtime 了解更多信息。
示例:
{
"name": "AzureSearchLinkedService",
"properties": {
"type": "AzureSearch",
"typeProperties": {
"url": "https://<service>.search.windows.net",
"key": {
"type": "SecureString",
"value": "<AdminKey>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
数据集属性
有关可用于定义数据集的各部分和属性的完整列表,请参阅数据集一文。 本部分提供 Azure AI 搜索数据集支持的属性列表。
若要将数据复制到 Azure AI 搜索中,需支持以下属性:
| properties | 描述 | 必需 |
|---|---|---|
| type | 数据集的 type 属性必须设置为:AzureSearchIndex | 是 |
| indexName | 搜索索引的名称。 此服务不创建索引。 索引必须存在于 Azure AI 搜索中。 | 是 |
示例:
{
"name": "AzureSearchIndexDataset",
"properties": {
"type": "AzureSearchIndex",
"typeProperties" : {
"indexName": "products"
},
"schema": [],
"linkedServiceName": {
"referenceName": "<Azure AI Search linked service name>",
"type": "LinkedServiceReference"
}
}
}
复制活动属性
有关可用于定义活动的各部分和属性的完整列表,请参阅管道一文。 本部分提供 Azure AI 搜索源支持的属性列表。
Azure AI 搜索作为接收器
要将数据复制到 Azure AI 搜索,请将复制活动中的源类型设置为“AzureSearchIndexSink”。 复制活动接收器部分中支持以下属性:
| 属性 | 描述 | 必需 |
|---|---|---|
| type | 复制活动源的 type 属性必须设置为:AzureSearchIndexSink | 是 |
| writeBehavior | 指定索引中已存在文档时要合并还是替换该文档。 请参阅 WriteBehavior 属性。 允许的值为:Merge(默认)和Upload。 |
否 |
| writeBatchSize | 缓冲区大小达到 writeBatchSize 时会数据上传到搜索索引。 有关详细信息,请参阅 WriteBatchSize 属性。 允许的值为:整数 1 到 1,000;默认值为 1000。 |
否 |
| maxConcurrentConnections | 活动运行期间与数据存储建立的并发连接的上限。 仅在要限制并发连接时指定一个值。 | 否 |
WriteBehavior 属性
AzureSearchSink 在写入数据时执行 upsert 操作。 换言之,编写文档时,如果搜索索引中已存在文档键,则 Azure AI 会更新现有文档,而不引发冲突异常。
AzureSearchSink(通过使用 AzureSearch SDK)提供以下两种 upsert 行为:
- 合并:合并新文档和现有文档中的所有列。 对于新文档中具有 null 值的列,会在现有文档列中保留该值。
- 上传:新文档替换现有文档。 对于未在新文档中指定的列,无论现有文档中是否存在非 null 值,均将该值设置为 null。
默认行为是合并。
WriteBatchSize 属性
Azure AI 搜索服务支持成批编写文档。 每批次可包含 1 到 1,000 个操作。 每个操作处理一个文档以执行上传/合并操作。
示例:
"activities":[
{
"name": "CopyToAzureSearch",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Azure AI Search output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "AzureSearchIndexSink",
"writeBehavior": "Merge"
}
}
}
]
数据类型支持
下表指定是否支持某个 Azure AI 搜索数据类型。
| Azure AI 搜索数据类型 | 在 Azure AI 搜索接收器中受到支持 |
|---|---|
| 字符串 | Y |
| Int32 | Y |
| Int64 | Y |
| Double | Y |
| Boolean | Y |
| DataTimeOffset | Y |
| String Array | N |
| GeographyPoint | N |
当前不支持其他数据类型,例如 ComplexType。 有关 Azure AI 搜索支持的数据类型的完整列表,请参阅支持的数据类型(Azure AI 搜索)。
相关内容
有关复制活动支持作为源和接收器的数据存储的列表,请参阅支持的数据存储。