你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
适用于: Azure 数据工厂 Azure Synapse Analytics
Azure 数据工厂 Azure Synapse Analytics
提示
试用 Microsoft Fabric 中的数据工厂,这是一种适用于企业的一站式分析解决方案。 Microsoft Fabric 涵盖从数据移动到数据科学、实时分析、商业智能和报告的所有内容。 了解如何免费开始新的试用!
数据流在 Azure 数据工厂和 Azure Synapse 管道中均可用。 本文适用于映射数据流。 如果不熟悉转换,请参阅介绍性文章使用映射数据流转换数据。
聚合转换可以定义数据流中列的聚合。 使用表达式生成器可以定义不同类型的聚合,如 SUM、MIN、MAX 和 COUNT,并按现有列或计算列进行分组。
Group by
选择现有列或创建新的计算列,以用作聚合的 group by 子句。 若要使用现有列,请从下拉列表中选择它。 若要创建新的计算列,请将鼠标悬停在子句上,并单击“计算列”。 这将打开数据流表达式生成器。 创建计算列后,请在“命名为”字段下输入输出列名称。 如果要添加其他 group by 子句,请将鼠标悬停在现有子句上,然后单击加号图标。
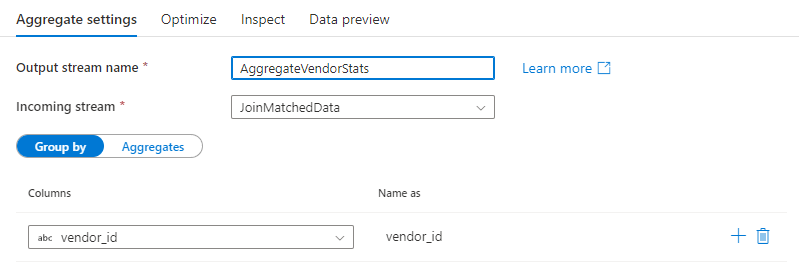
在聚合转换中,group by 子句是可选的。
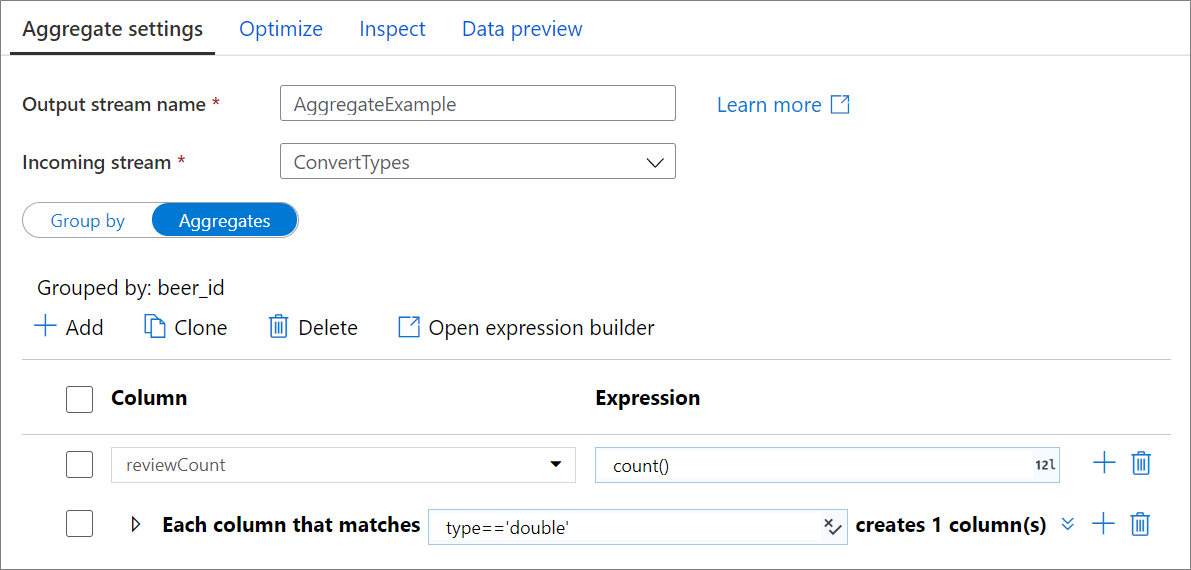
聚合列
转到“聚合”选项卡以生成聚合表达式。 可以使用聚合覆盖现有列,也可以使用新名称创建新字段。 在列名选择器旁的右侧框中输入聚合表达式。 若要编辑表达式,请单击文本框并打开表达式生成器。 若要添加更多聚合列,请单击列列表上方的“添加”或现有聚合列旁边的加号图标。 选择“添加列”或“添加列模式”。 每个聚合表达式必须至少包含一个聚合函数。
注意
在“调试”模式下,表达式生成器无法使用聚合函数生成数据预览。 若要查看聚合转换的数据预览,请关闭表达式生成器,然后通过“数据预览”选项卡查看数据。
列模式
使用列模式将相同的聚合应用于一组列。 如果希望保留输入架构中的许多列(默认情况下会将其删除),则此功能很有用。 使用诸如 first() 之类的试探法来通过聚合保留输入列。
重新连接行和列
聚合转换类似于 SQL 聚合 select 查询。 未包含在 group by 子句或聚合函数中的列不会流向聚合转换的输出。 如果希望在聚合输出中包括其他列,请执行以下方法之一:
- 使用聚合函数(如
last()或first())来包含该其他列。 - 使用自联接模式将列重新联接到输出流。
删除重复的行
聚合转换的常见用途是删除或标识源数据中的重复条目。 此过程称为重复数据删除。 基于一组分组依据键,使用你选择的试探法确定要保留的重复行。 常见试探法有 first()、last()、max() 和 min()。 使用列模式将规则应用到除分组依据列之外的每一列。
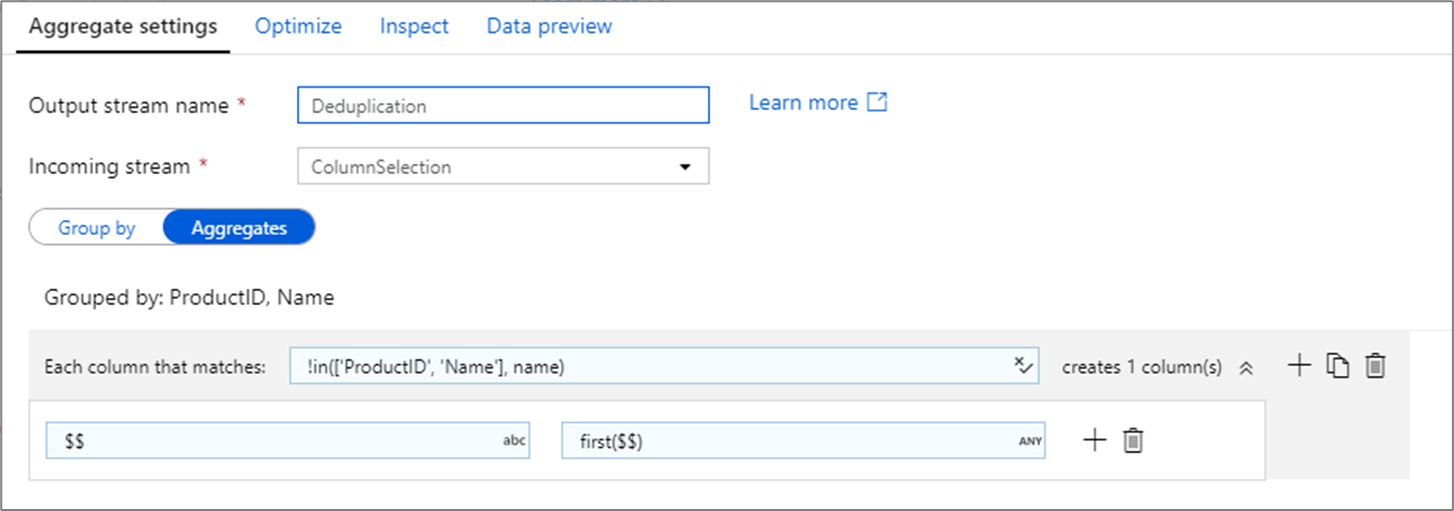
在上面的示例中,列 ProductID 和 Name 用于分组。 如果这两列中有两行的值相同,则将其视为重复项。 在此聚合转换中,将保留匹配的第一行的值,并删除所有其他行的值。 使用列模式语法,将名称不是 ProductID 和 Name 的所有列都映射到它们的现有列名,并为其指定第一个匹配行的值。 输出架构与输入架构相同。
对于数据验证方案,count() 函数可用于计算有多少重复项。
数据流脚本
语法
<incomingStream>
aggregate(
groupBy(
<groupByColumnName> = <groupByExpression1>,
<groupByExpression2>
),
<aggregateColumn1> = <aggregateExpression1>,
<aggregateColumn2> = <aggregateExpression2>,
each(
match(matchExpression),
<metadataColumn1> = <metadataExpression1>,
<metadataColumn2> = <metadataExpression2>
)
) ~> <aggregateTransformationName>
示例
下面的示例采用传入流 MoviesYear 并按列 year 对行分组。 该转换将创建一个汇总列 avgrating,其计算结果为列 Rating 的平均值。 此聚合转换名为 AvgComedyRatingsByYear。
在 UI 中,此转换如下图所示:
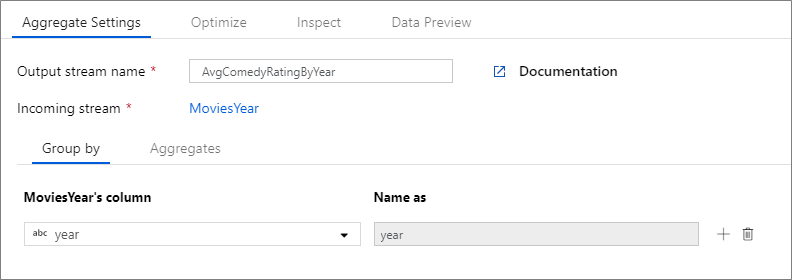
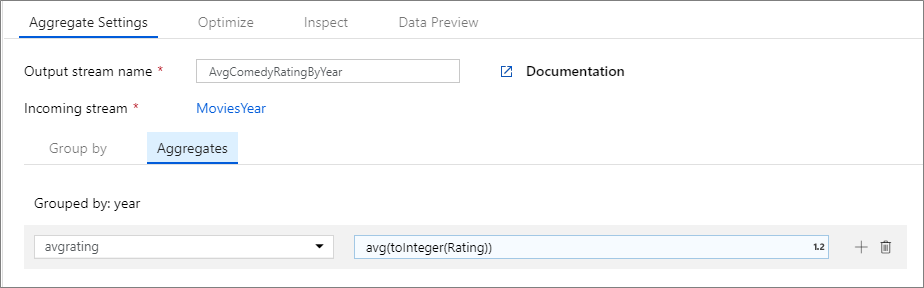
此转换的数据流脚本位于下面的代码片段中。
MoviesYear aggregate(
groupBy(year),
avgrating = avg(toInteger(Rating))
) ~> AvgComedyRatingByYear
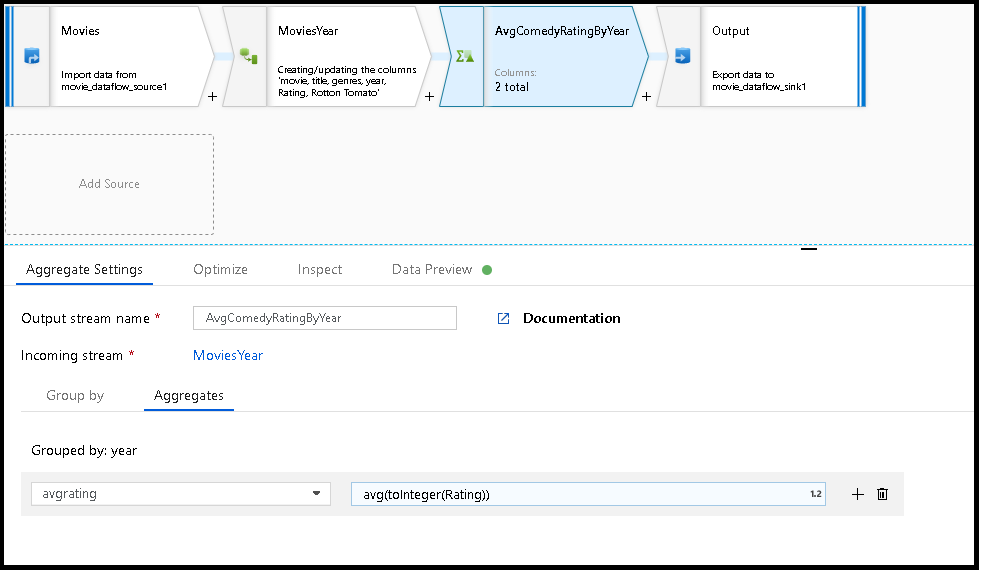
MoviesYear:用于定义年份和标题列的派生列 AvgComedyRatingByYear:按年份分组的喜剧的平均评分的聚合转换 avgrating:将为保存聚合值而创建的新列的名称
MoviesYear aggregate(groupBy(year),
avgrating = avg(toInteger(Rating))) ~> AvgComedyRatingByYear
相关内容
- 使用窗口转换定义基于窗口的聚合