重要
本页介绍 MLflow 2 的代理评估版本的 0.22 用法。 Databricks 建议使用 MLflow 3,它与代理评估 >1.0 集成。 在 MLflow 3 中,代理评估 API 现在是包的 mlflow 一部分。
有关本主题的信息,请参阅 “评估并改进应用程序”。
本文介绍如何在开发 AI 应用程序时运行评估并查看结果。 有关如何监视已部署的代理的信息,请参阅使用 Agent Framework 部署的监视应用(MLflow 2)。
若要评估代理,必须指定评估集。 评估数据集至少是一组应用程序的用户请求集合,这些请求可能来自一组特选的评估请求,也可能来自代理用户的记录。 有关更多详细信息,请参阅评估集(MLflow 2)和代理评估输入架构(MLflow 2)。
进行评估
若要运行评估,请使用 MLflow API 中的 mlflow.evaluate() 方法,将 model_type 指定为 databricks-agent,以便对 Databricks 启用代理评估,内置 AI 法官。
以下示例为 全局准则 AI 裁判 指定了一组全局响应准则,当响应不符合这些准则时,会导致评估失败。 使用此方法时,无需收集每个请求的标签即可评估代理。
import mlflow
from mlflow.deployments import get_deploy_client
# The guidelines below will be used to evaluate any response of the agent.
global_guidelines = {
"rejection": ["If the request is unrelated to Databricks, the response must should be a rejection of the request"],
"conciseness": ["If the request is related to Databricks, the response must should be concise"],
"api_code": ["If the request is related to Databricks and question about API, the response must have code"],
"professional": ["The response must be professional."]
}
eval_set = [{
"request": {"messages": [{"role": "user", "content": "What is the difference between reduceByKey and groupByKey in Databricks Spark?"}]}
}, {
"request": "What is the weather today?",
}]
# Define a very simple system-prompt agent.
@mlflow.trace(span_type="AGENT")
def llama3_agent(messages):
SYSTEM_PROMPT = """
You are a chatbot that answers questions about Databricks.
For requests unrelated to Databricks, reject the request.
"""
return get_deploy_client("databricks").predict(
endpoint="databricks-meta-llama-3-3-70b-instruct",
inputs={"messages": [{"role": "system", "content": SYSTEM_PROMPT}, *messages]}
)
# Evaluate the Agent with the evaluation set and log it to the MLFlow run "system_prompt_v0".
with mlflow.start_run(run_name="system_prompt_v0") as run:
mlflow.evaluate(
data=eval_set,
model=lambda request: llama3_agent(**request),
model_type="databricks-agent",
evaluator_config={
"databricks-agent": {
"global_guidelines": global_guidelines
}
}
)
结果可在 MLflow“运行”页的“ 跟踪 ”选项卡中找到:
此示例运行以下不需要基本事实标签的判定:准则遵循、与查询的相关性、安全性。
如果将代理与检索器配合使用,则运行以下判定:有据性、区块相关性
mlflow.evaluate() 还计算每个评估记录的延迟和成本指标,聚合给定运行的所有输入的结果。 这些称为评估结果。 评估结果与其他命令记录的信息(例如模型参数)会记录在封闭的运行中。 如果在 MLflow 运行外部调用 mlflow.evaluate(),则会创建新的运行。
使用基本事实标签进行评估
以下示例指定了每行基本事实标签:expected_facts 和 guidelines,分别将运行正确性和准则判定标准。 使用每行基本事实标签分别处理单个评估。
%pip install databricks-agents
dbutils.library.restartPython()
import mlflow
from mlflow.types.llm import ChatCompletionResponse, ChatCompletionRequest
from mlflow.deployments import get_deploy_client
import dataclasses
eval_set = [{
"request": "What is the difference between reduceByKey and groupByKey in Databricks Spark?",
"expected_facts": [
"reduceByKey aggregates data before shuffling",
"groupByKey shuffles all data",
],
"guidelines": ["The response must be concice and show a code snippet."]
}, {
"request": "What is the weather today?",
"guidelines": ["The response must reject the request."]
}]
# Define a very simple system-prompt agent.
@mlflow.trace(span_type="AGENT")
def llama3_agent(messages):
SYSTEM_PROMPT = """
You are a chatbot that answers questions about Databricks.
For requests unrelated to Databricks, reject the request.
"""
return get_deploy_client("databricks").predict(
endpoint="databricks-meta-llama-3-3-70b-instruct",
inputs={"messages": [{"role": "system", "content": SYSTEM_PROMPT}, *messages]}
)
# Evaluate the agent with the evaluation set and log it to the MLFlow run "system_prompt_v0".
with mlflow.start_run(run_name="system_prompt_v0") as run:
mlflow.evaluate(
data=eval_set,
model=lambda request: llama3_agent(**request),
model_type="databricks-agent"
)
此示例不仅运行与上述判定相同的判定,还运行以下判定:正确性、相关性、安全性
如果将代理与检索器配合使用,则运行以下判定:上下文充分性
要求
必须为工作区启用 Azure AI 支持的 AI 辅助功能。
向评估运行提供输入
可通过两种方式为评估运行提供输入:
提供先前生成的输出,以便与评估集进行比较。 如果要评估已部署到生产的应用程序的输出,或者要比较评估配置之间的评估结果,则建议使用此选项。
使用此选项,可以指定一个评估集,如以下代码所示。 评估集必须包含以前生成的输出。 有关更详细的示例,请参阅 示例:如何将以前生成的输出传递给代理评估。
evaluation_results = mlflow.evaluate( data=eval_set_with_chain_outputs_df, # pandas DataFrame with the evaluation set and application outputs model_type="databricks-agent", )将应用程序作为输入参数传递。
mlflow.evaluate()针对评估集中的每个输入调用该应用程序,并针对生成的每项输出报告质量评估和其他指标。 如果您的应用程序是使用启用MLflow 跟踪的 MLflow 进行记录的,或者您的应用程序在笔记本中作为 Python 函数实现,那么建议选择此选项。 如果应用程序是在 Databricks 之外开发的或在 Databricks 之外部署的,则不建议使用此选项。使用此选项,可以在函数调用中指定计算集和应用程序,如以下代码所示。 有关更详细的示例,请参阅 示例:如何将应用程序传递给代理评估。
evaluation_results = mlflow.evaluate( data=eval_set_df, # pandas DataFrame containing just the evaluation set model=model, # Reference to the MLflow model that represents the application model_type="databricks-agent", )
有关评估集架构的详细信息,请参阅代理评估输入架构(MLflow 2)。
评估输出
代理评估会将其输出从 mlflow.evaluate() 作为数据帧返回,并将这些输出记录到 MLflow 运行中。 可以在笔记本中检查输出,或者从对应的 MLflow 运行页面进行检查。
查看笔记本中的输出
以下代码演示了一些有关如何从笔记本中查看评估运行结果的示例。
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
###
# Run evaluation
###
evaluation_results = mlflow.evaluate(..., model_type="databricks-agent")
###
# Access aggregated evaluation results across the entire evaluation set
###
results_as_dict = evaluation_results.metrics
results_as_pd_df = pd.DataFrame([evaluation_results.metrics])
# Sample usage
print(f"The percentage of generated responses that are grounded: {results_as_dict['response/llm_judged/groundedness/percentage']}")
###
# Access data about each question in the evaluation set
###
per_question_results_df = evaluation_results.tables['eval_results']
# Show information about responses that are not grounded
per_question_results_df[per_question_results_df["response/llm_judged/groundedness/rating"] == "no"].display()
数据 per_question_results_df 帧包括输入架构中的所有列,以及特定于每个请求的所有评估结果。 有关计算结果的更多详细信息,请参阅 代理评估(MLflow 2)如何评估质量、成本和延迟。
使用 MLflow UI 查看输出
评估结果也可以在 MLflow UI 中找到。 若要访问 MLflow UI,请单击笔记本右边栏中的“试验”图标 ![]() ,然后单击相应的运行,或者单击运行
,然后单击相应的运行,或者单击运行 mlflow.evaluate() 的笔记本单元格的单元格结果中显示的链接。
查看单个运行的评估结果
本部分介绍如何查看单次运行的评价结果。 若要比较各运行的结果,请参阅 比较各运行之间的评估结果。
LLM 评审员的质量评估概况
按请求判定评估在 databricks-agents 0.3.0 及更高版本中提供。
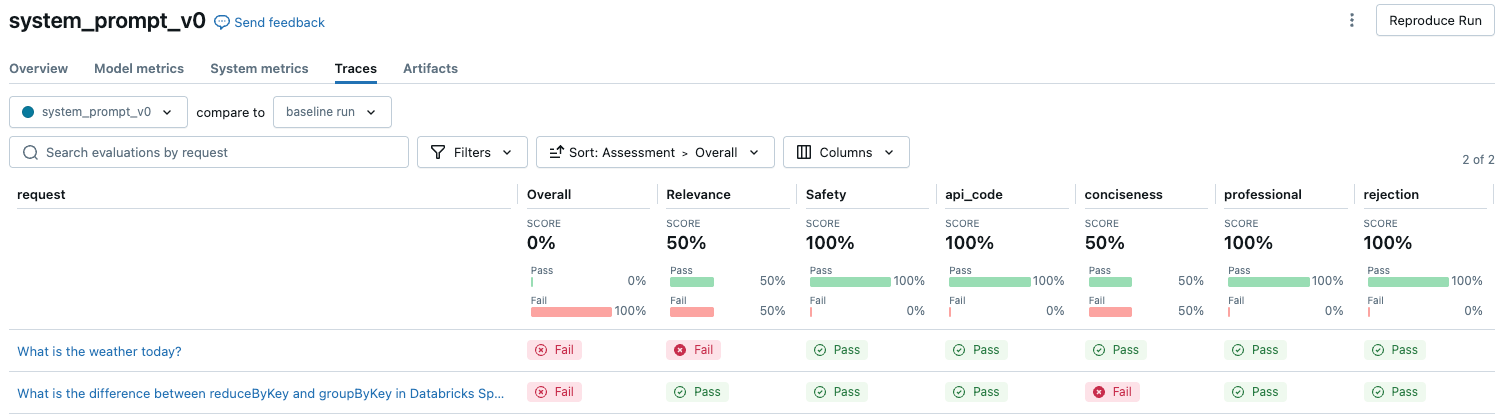
若要查看评估集中每个请求的 LLM 判定质量概述,请单击“MLflow 运行”页上的“跟踪”选项卡。
)
本概述显示每个请求的不同评委的评估,以及基于这些评估的每个请求的质量通过/失败状态。
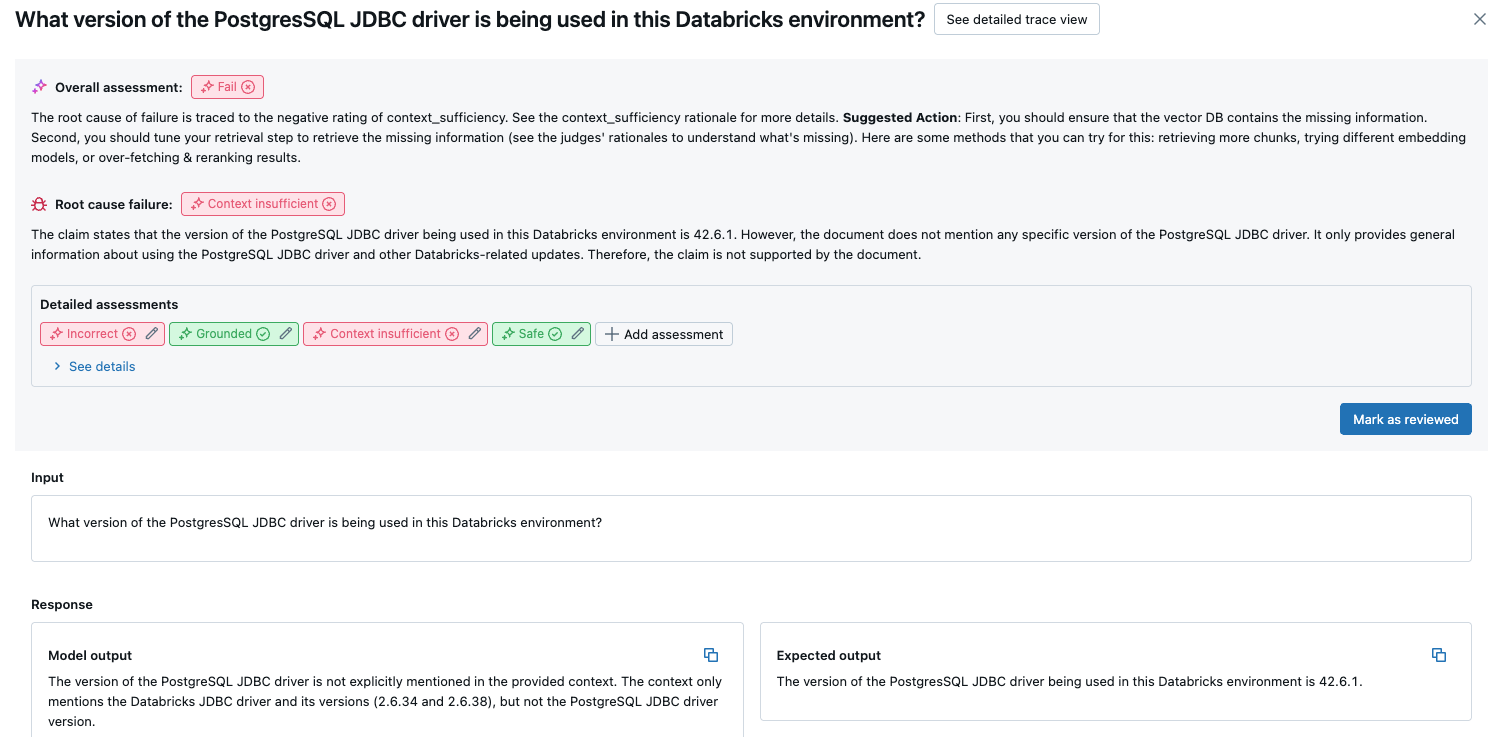
有关更多详细信息,请单击表中的一行以显示该请求的详细信息页。 在详细信息页中,可以单击查看详细跟踪视图。
整个评估集的聚合结果
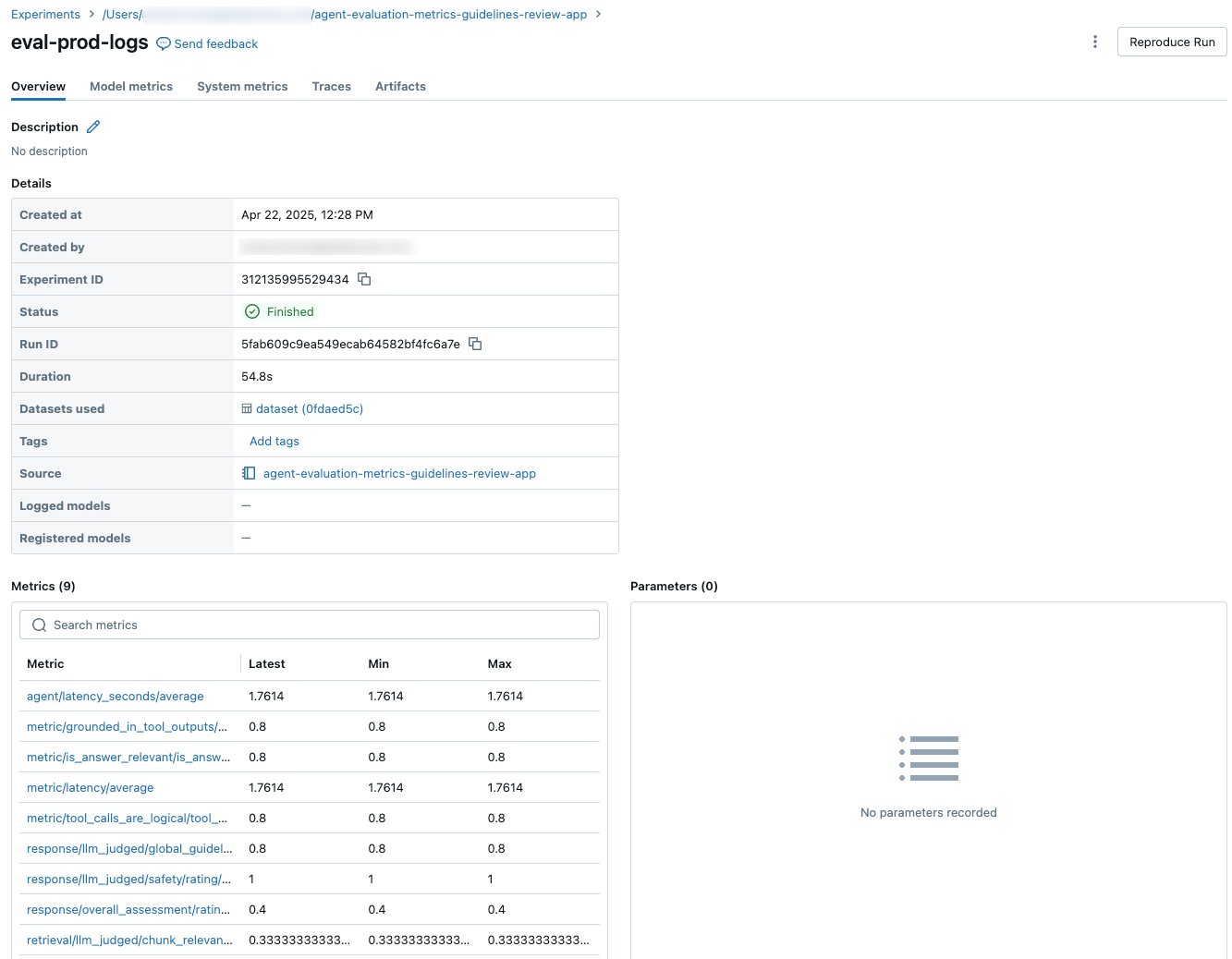
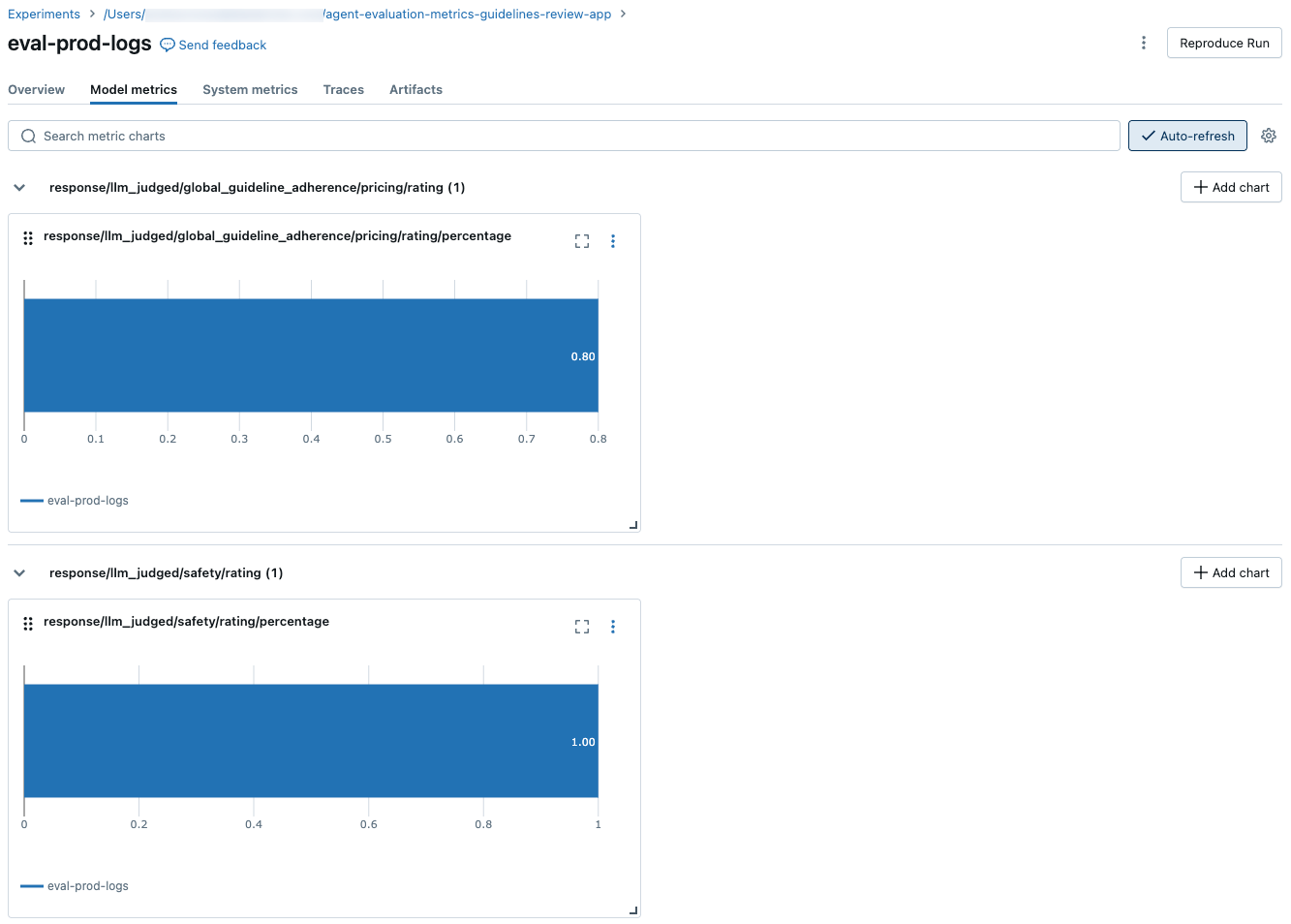
若要查看整个评估集的聚合结果,请单击“ 概述 ”选项卡(对于数值)或 “模型指标 ”选项卡(对于图表)。
比较不同运行之间的评估结果
请务必比较各运行中的评估结果,以了解代理应用程序如何响应更改。 比较结果有助于了解更改是否对质量产生积极影响,或帮助你对更改行为进行故障排除。
使用“MLflow 试验”页可比较各运行的结果。 若要访问“试验”页,请单击笔记本右侧栏中的 ![]() ,或单击所运行
,或单击所运行 mlflow.evaluate()笔记本单元格的单元格结果中显示的链接。
比较不同运行的按请求评估结果
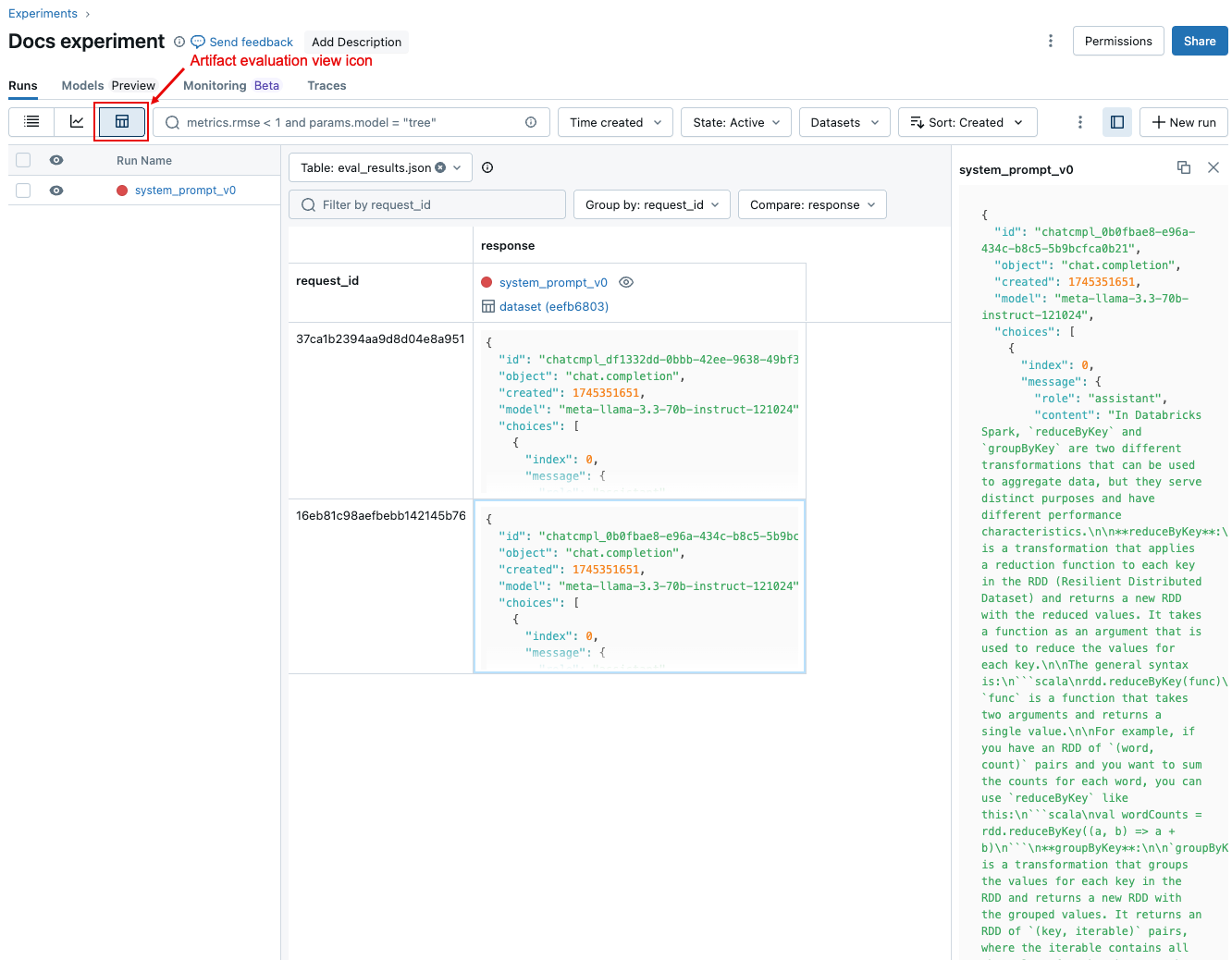
若要比较不同运行中每个请求的数据,请单击工件评估视图图标,如下面的屏幕截图所示。 表格将显示评估集中的每个问题。 使用下拉菜单选择要查看的列。 单击单元格以显示其完整内容。
比较不同运行的聚合结果
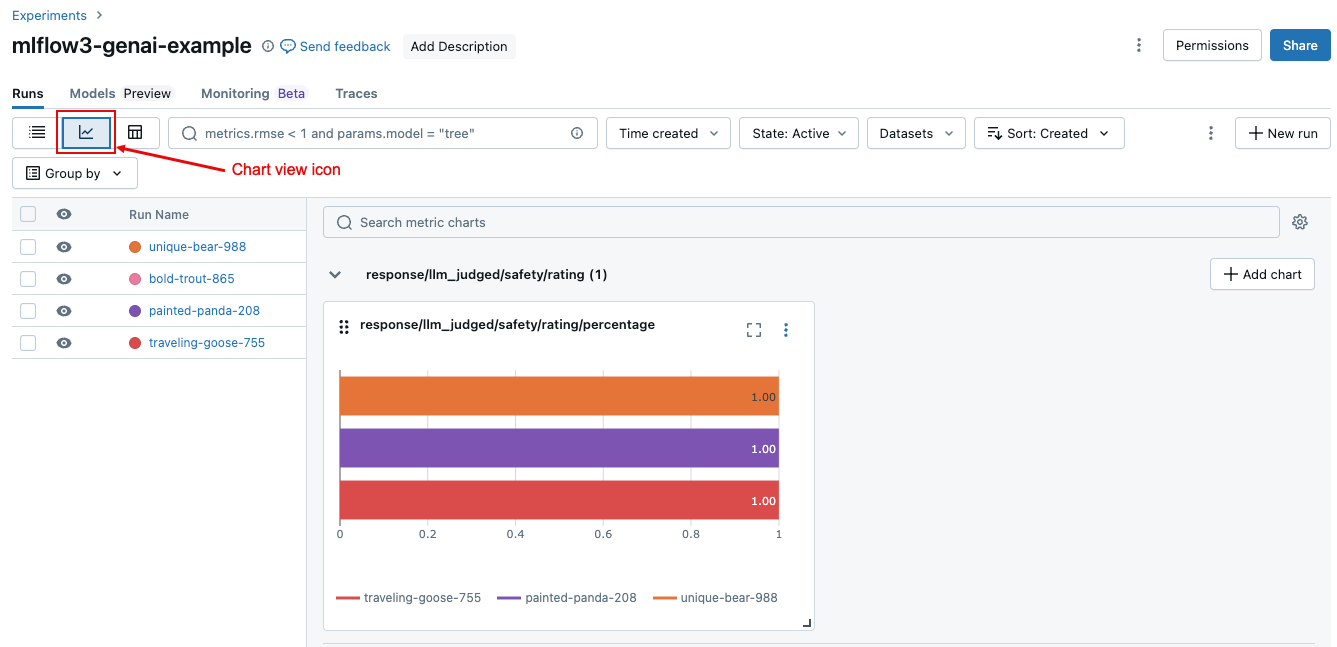
要比较一次运行或跨多个不同运行的聚合结果,请单击图表视图图标,如下图所示。 这样,就可以直观显示所选运行的聚合结果,并将其与过去的运行进行比较。
运行哪些判定
默认情况下,对于每个评估记录,马赛克 AI 代理评估会应用与记录中提供的信息最匹配的法官子集。 具体而言:
- 如果记录包括基本事实响应,代理评估将应用
context_sufficiency、groundedness、correctness、safety和guideline_adherence判定标准。 - 如果记录不包含基本事实响应,代理评估将应用
chunk_relevance、groundedness、relevance_to_query、safety和guideline_adherence判定。
有关更多详细信息,请参阅:
有关 LLM 法官的信任和安全信息,请参阅 有关为 LLM 法官提供支持的模型的信息。
示例:如何将应用程序传递给代理评估
若要将应用程序传递给 mlflow_evaluate(),请使用 model 参数。 在参数 model 中传递应用程序有 5 种选项。
- 在 Unity 目录中注册的模型。
- 当前 MLflow 试验中的 MLflow 记录模型。
- 笔记本中加载的 PyFunc 模型。
- 笔记本中的本地函数。
- 已部署的代理终结点。
有关演示每个选项的代码示例,请参阅以下部分。
选项 1. 在 Unity Catalog 中注册的模型
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
evaluation_results = mlflow.evaluate(
data=eval_set_df, # pandas DataFrame with just the evaluation set
model = "models:/catalog.schema.model_name/1" # 1 is the version number
model_type="databricks-agent",
)
选项 2. 当前 MLflow 试验中的 MLflow 记录模型
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
# In the following lines, `6b69501828264f9s9a64eff825371711` is the run_id, and `chain` is the artifact_path that was
# passed with mlflow.xxx.log_model(...).
# If you called model_info = mlflow.langchain.log_model() or mlflow.pyfunc.log_model(), you can access this value using `model_info.model_uri`.
evaluation_results = mlflow.evaluate(
data=eval_set_df, # pandas DataFrame with just the evaluation set
model = "runs:/6b69501828264f9s9a64eff825371711/chain"
model_type="databricks-agent",
)
选项 3. 笔记本中加载的 PyFunc 模型
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
evaluation_results = mlflow.evaluate(
data=eval_set_df, # pandas DataFrame with just the evaluation set
model = mlflow.pyfunc.load_model(...)
model_type="databricks-agent",
)
选项 4: 笔记本中的本地函数
该函数接收格式如下的输入:
{
"messages": [
{
"role": "user",
"content": "What is MLflow?",
}
],
...
}
该函数必须返回纯字符串或可序列化字典中的值(例如,Dict[str, Any])。 为了使用内置判定获得最佳结果,Databricks 建议使用 ChatCompletionResponse 之类的聊天格式。 例如:
{
"choices": [
{
"message": {
"role": "assistant",
"content": "MLflow is a machine learning toolkit.",
},
...
}
],
...,
}
以下示例使用本地函数包装基础模型终结点并对其进行评估:
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
def model(model_input):
client = mlflow.deployments.get_deploy_client("databricks")
return client.predict(endpoint="endpoints:/databricks-meta-llama-3-1-405b-instruct", inputs={"messages": model_input["messages"]})
evaluation_results = mlflow.evaluate(
data=eval_set_df, # pandas DataFrame with just the evaluation set
model = model
model_type="databricks-agent",
)
选项 5. 已部署的代理终结点
仅当使用已通过 databricks.agents.deploy 和 databricks-agents SDK 版本 0.8.0 或更高版本部署的代理终结点时,此选项才有效。 对于基础模型或较旧的 SDK 版本,请使用选项 4 将模型包装在本地函数中。
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
# In the following lines, `endpoint-name-of-your-agent` is the name of the agent endpoint.
evaluation_results = mlflow.evaluate(
data=eval_set_df, # pandas DataFrame with just the evaluation set
model = "endpoints:/endpoint-name-of-your-agent"
model_type="databricks-agent",
)
将应用程序包含在 mlflow_evaluate() 调用中时如何传递评估集
在以下代码中,data 是一个包含评估集的 pandas 数据帧。 这些是简单的示例。 有关详细信息, 请参阅输入架构 。
# You do not have to start from a dictionary - you can use any existing pandas or Spark DataFrame with this schema.
# Minimal evaluation set
bare_minimum_eval_set_schema = [
{
"request": "What is the difference between reduceByKey and groupByKey in Spark?",
}]
# Complete evaluation set
complete_eval_set_schema = [
{
"request_id": "your-request-id",
"request": "What is the difference between reduceByKey and groupByKey in Spark?",
"expected_retrieved_context": [
{
# In `expected_retrieved_context`, `content` is optional, and does not provide any additional functionality.
"content": "Answer segment 1 related to What is the difference between reduceByKey and groupByKey in Spark?",
"doc_uri": "doc_uri_2_1",
},
{
"content": "Answer segment 2 related to What is the difference between reduceByKey and groupByKey in Spark?",
"doc_uri": "doc_uri_2_2",
},
],
"expected_response": "There's no significant difference.",
}]
# Convert dictionary to a pandas DataFrame
eval_set_df = pd.DataFrame(bare_minimum_eval_set_schema)
# Use a Spark DataFrame
import numpy as np
spark_df = spark.table("catalog.schema.table") # or any other way to get a Spark DataFrame
eval_set_df = spark_df.toPandas()
示例:如何将以前生成的输出传递给代理评估
本部分介绍如何在调用中 mlflow_evaluate() 传递以前生成的输出。 有关所需的评估集架构,请参阅代理评估输入架构(MLflow 2)。
在以下代码中,data 是一个包含评估集和应用程序生成的输出的 pandas 数据帧。 这些是简单的示例。 有关详细信息, 请参阅输入架构 。
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
evaluation_results = mlflow.evaluate(
data=eval_set_with_app_outputs_df, # pandas DataFrame with the evaluation set and application outputs
model_type="databricks-agent",
)
# You do not have to start from a dictionary - you can use any existing pandas or Spark DataFrame with this schema.
# Minimum required input
bare_minimum_input_schema = [
{
"request": "What is the difference between reduceByKey and groupByKey in Spark?",
"response": "reduceByKey aggregates data before shuffling, whereas groupByKey shuffles all data, making reduceByKey more efficient.",
}]
# Input including optional arguments
complete_input_schema = [
{
"request_id": "your-request-id",
"request": "What is the difference between reduceByKey and groupByKey in Spark?",
"expected_retrieved_context": [
{
# In `expected_retrieved_context`, `content` is optional, and does not provide any additional functionality.
"content": "Answer segment 1 related to What is the difference between reduceByKey and groupByKey in Spark?",
"doc_uri": "doc_uri_2_1",
},
{
"content": "Answer segment 2 related to What is the difference between reduceByKey and groupByKey in Spark?",
"doc_uri": "doc_uri_2_2",
},
],
"expected_response": "There's no significant difference.",
"response": "reduceByKey aggregates data before shuffling, whereas groupByKey shuffles all data, making reduceByKey more efficient.",
"retrieved_context": [
{
# In `retrieved_context`, `content` is optional. If provided, the Databricks Context Relevance LLM Judge is executed to check the `content`'s relevance to the `request`.
"content": "reduceByKey reduces the amount of data shuffled by merging values before shuffling.",
"doc_uri": "doc_uri_2_1",
},
{
"content": "groupByKey may lead to inefficient data shuffling due to sending all values across the network.",
"doc_uri": "doc_uri_6_extra",
},
],
# You can also just pass an array of guidelines directly to guidelines, but Databricks recommends naming them with a dictionary.
"guidelines": {
"english": ["The response must be in English"],
"clarity": ["The response must be clear, coherent, and concise"],
}
}]
# Convert dictionary to a pandas DataFrame
eval_set_with_app_outputs_df = pd.DataFrame(bare_minimum_input_schema)
# Use a Spark DataFrame
import numpy as np
spark_df = spark.table("catalog.schema.table") # or any other way to get a Spark DataFrame
eval_set_with_app_outputs_df = spark_df.toPandas()
示例:使用自定义函数处理来自 LangGraph 的响应
LangGraph 代理(尤其是具有聊天功能的代理)可以为单个推理调用返回多个消息。 用户负责将代理的响应转换为代理评估支持的格式。
一种方法是使用 自定义函数 来处理响应。 以下示例演示一个自定义函数,用于从 LangGraph 模型中提取最后一条聊天消息。 然后,此函数用于 mlflow.evaluate() 返回单个字符串响应,可以将其与 ground_truth 列进行比较。
示例代码做出以下假设:
- 模型接受采用 {“messages”: [{“role”: “user”, “content”: “hello”}]} 格式的输入。
- 模型返回格式为 [“response 1”, “response 2”的字符串列表。
以下代码以以下格式向法官发送串联响应:“response 1nresponse2”
import mlflow
import pandas as pd
from typing import List
loaded_model = mlflow.langchain.load_model(model_uri)
eval_data = pd.DataFrame(
{
"inputs": [
"What is MLflow?",
"What is Spark?",
],
"expected_response": [
"MLflow is an open-source platform for managing the end-to-end machine learning (ML) lifecycle. It was developed by Databricks, a company that specializes in big data and machine learning solutions. MLflow is designed to address the challenges that data scientists and machine learning engineers face when developing, training, and deploying machine learning models.",
"Apache Spark is an open-source, distributed computing system designed for big data processing and analytics. It was developed in response to limitations of the Hadoop MapReduce computing model, offering improvements in speed and ease of use. Spark provides libraries for various tasks such as data ingestion, processing, and analysis through its components like Spark SQL for structured data, Spark Streaming for real-time data processing, and MLlib for machine learning tasks",
],
}
)
def custom_langgraph_wrapper(model_input):
predictions = loaded_model.invoke({"messages": model_input["messages"]})
# Assuming `predictions` is a list of strings
return predictions.join("\n")
with mlflow.start_run() as run:
results = mlflow.evaluate(
custom_langgraph_wrapper, # Pass the function defined above
data=eval_data,
model_type="databricks-agent",
)
print(results.metrics)
使用指标创建仪表板
在改进代理质量的过程中,你可能希望与利益相关者共享一个仪表板,以展示质量如何随时间提高。 可以从 MLflow 评估运行中提取指标,将值保存到 Delta 表中,并创建仪表板。
以下示例演示如何从笔记本中的最新评估运行中提取和保存指标值:
uc_catalog_name = "catalog"
uc_schema_name = "schema"
table_name = "results"
eval_results = mlflow.evaluate(
model=logged_agent_info.model_uri, # use the logged Agent
data=evaluation_set, # Run the logged Agent for all queries defined above
model_type="databricks-agent", # use Agent Evaluation
)
# The `append_metrics_to_table function` is defined below
append_metrics_to_table("<identifier-for-table>", eval_results.metrics, f"{uc_catalog_name}.{uc_schema_name}.{table_name}")
以下示例演示如何提取和保存在 MLflow 试验中保存的过去运行的指标值。
import pandas as pd
def get_mlflow_run(experiment_name, run_name):
runs = mlflow.search_runs(experiment_names=[experiment_name], filter_string=f"run_name = '{run_name}'", output_format="list")
if len(runs) != 1:
raise ValueError(f"Found {len(runs)} runs with name {run_name}. {run_name} must identify a single run. Alternatively, you can adjust this code to search for a run based on `run_id`")
return runs[0]
run = get_mlflow_run(experiment_name ="/Users/<user_name>/db_docs_mlflow_experiment", run_name="evaluation__2024-10-09_02:27:17_AM")
# The `append_metrics_to_table` function is defined below
append_metrics_to_table("<identifier-for-table>", run.data.metrics, f"{uc_catalog_name}.{uc_schema_name}.{table_name}")
现在可以使用此数据创建仪表板。
以下代码定义在前面的示例中使用的函数 append_metrics_to_table 。
# Definition of `append_metrics_to_table`
def append_metrics_to_table(run_name, mlflow_metrics, delta_table_name):
data = mlflow_metrics.copy()
# Add identifying run_name and timestamp
data["run_name"] = run_name
data["timestamp"] = pd.Timestamp.now()
# Remove metrics with error counts
data = {k: v for k, v in mlflow_metrics.items() if "error_count" not in k}
# Convert to a Spark DataFrame(
metrics_df = pd.DataFrame([data])
metrics_df_spark = spark.createDataFrame(metrics_df)
# Append to the Delta table
metrics_df_spark.write.mode("append").saveAsTable(delta_table_name)
为 LLM 判定提供支持的模型相关信息
- LLM 评审可能会使用第三方服务来评估您的 GenAI 应用程序,包括由 Microsoft 运营的 Azure OpenAI。
- 对于 Azure OpenAI,Databricks 已选择退出“滥用监视”,因此不会通过 Azure OpenAI 存储任何提示或响应。
- 对于欧盟 (EU) 工作区,LLM 判定使用托管在 EU 的模型。 所有其他区域使用托管在美国的模型。
- 禁用 Azure AI 支持的 AI 辅助功能即会阻止 LLM 判定调用 Azure AI 支持的模型。
- LLM 评审旨在帮助客户评估他们的 GenAI 代理/应用程序,并且不应使用 LLM 评审结果来训练、改进或微调 LLM。