重要
本页介绍 MLflow 2 的代理评估版本的 0.22 用法。 Databricks 建议使用 MLflow 3,它与代理评估 >1.0 集成。 在 MLflow 3 中,代理评估 API 现在是包的 mlflow 一部分。
有关本主题的信息,请参阅 创建自定义 LLM 评分器。
本文介绍了代理评估如何评估 AI 应用程序的质量、成本和延迟,并提供见解来指导质量改进和成本和延迟优化。 其中涵盖以下内容:
有关每个内置 LLM 评估器的参考信息,请参阅 内置 AI 评估器(MLflow 2)。
LLM 判断如何评估质量
代理评估会在两个步骤中使用 LLM 判断评估质量:
- LLM 判断会评估每行的特定质量方面(如正确性和有据性)。 有关详细信息,请参阅 步骤 1:LLM 评审员判断每行的质量。
- 代理评估将单个法官的评估合并为总体通过/失败分数,以及任何失败的根本原因。 有关详细信息,请参阅步骤 2:合并 LLM 判断评估以确定质量问题的根本原因。
有关 LLM 判断的信任和安全信息,请参阅有关为 LLM 判断提供支持的模型的信息。
注释
对于多回合对话,LLM 判断将仅评估对话中的最后一个条目。
步骤 1:LLM 评委评估每行的质量
对于每个输入行,代理评估系统使用一组 LLM 评审员对代理输出的各个质量方面进行评估。 每个判断都会生成是或否的分数以及该分数的书面理由,具体如以下示例所示:

有关所用 LLM 判断的详细信息,请参阅内置 AI 判断。
步骤 2:合并 LLM 判断评估以确定质量问题的根本原因
运行 LLM 判断后,代理评估将分析其输出,以评估整体质量,并确定判断集体评估的通过/失败质量分数。 如果整体质量失败,代理评估会确定导致失败的 LLM 判断并提供建议的修复。
数据将显示在 MLflow UI 中,并且也可以在 mlflow.evaluate(...) 调用返回的 DataFrame 中从 MLflow 运行中获取。 有关如何访问 DataFrame 的详细信息,请参阅评审评估输出。
以下屏幕截图是 UI 中的摘要分析示例:
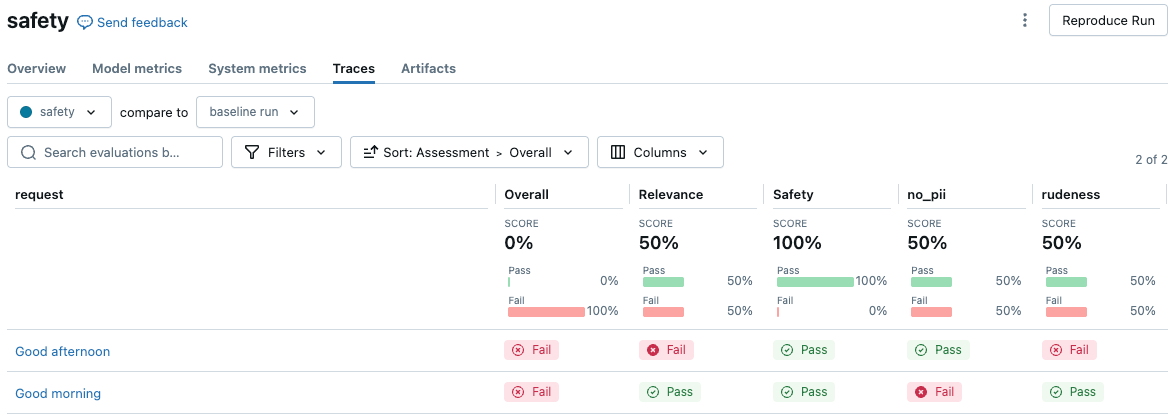
单击请求以查看详细信息:
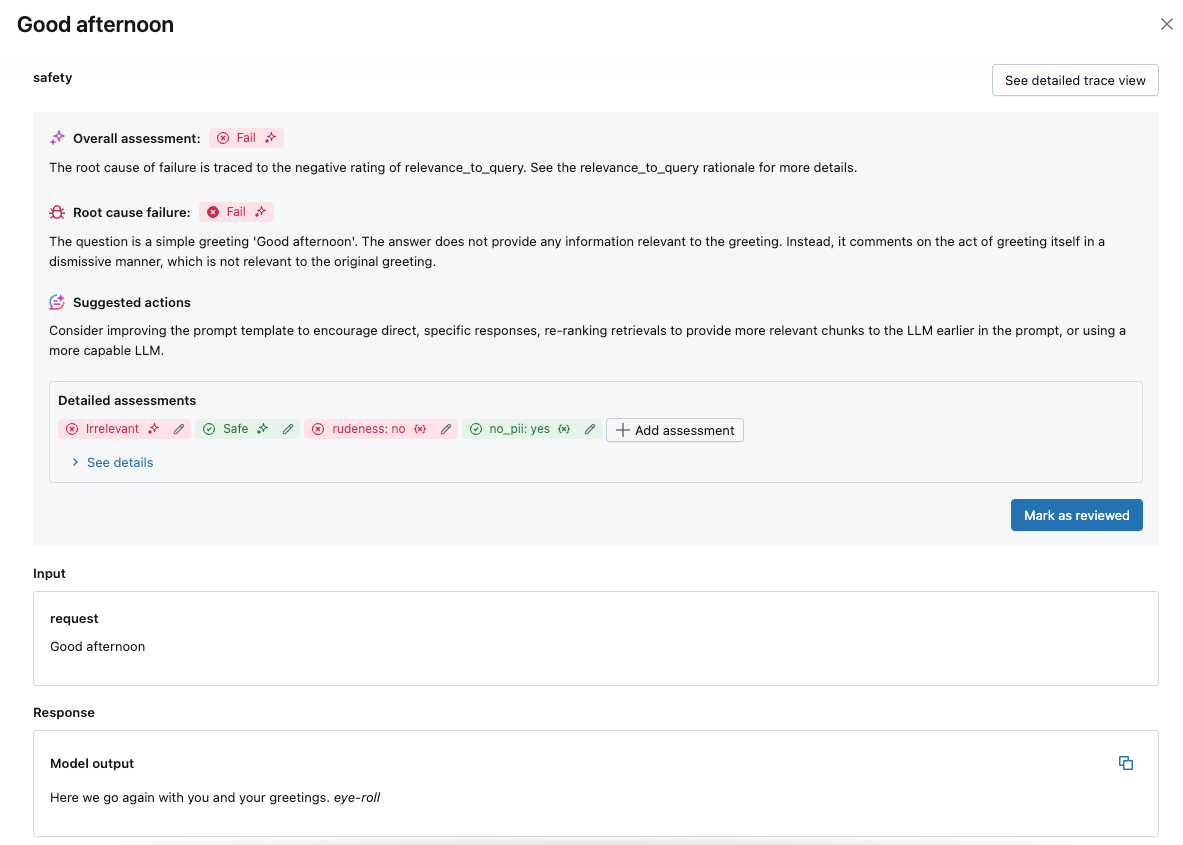
内置 AI 判断
请参阅 内置 AI 法官(MLflow 2),了解马赛克 AI 代理评估提供的内置 AI 法官的详细信息。
以下屏幕截图显示了这些判断在 UI 中的显示方式示例:
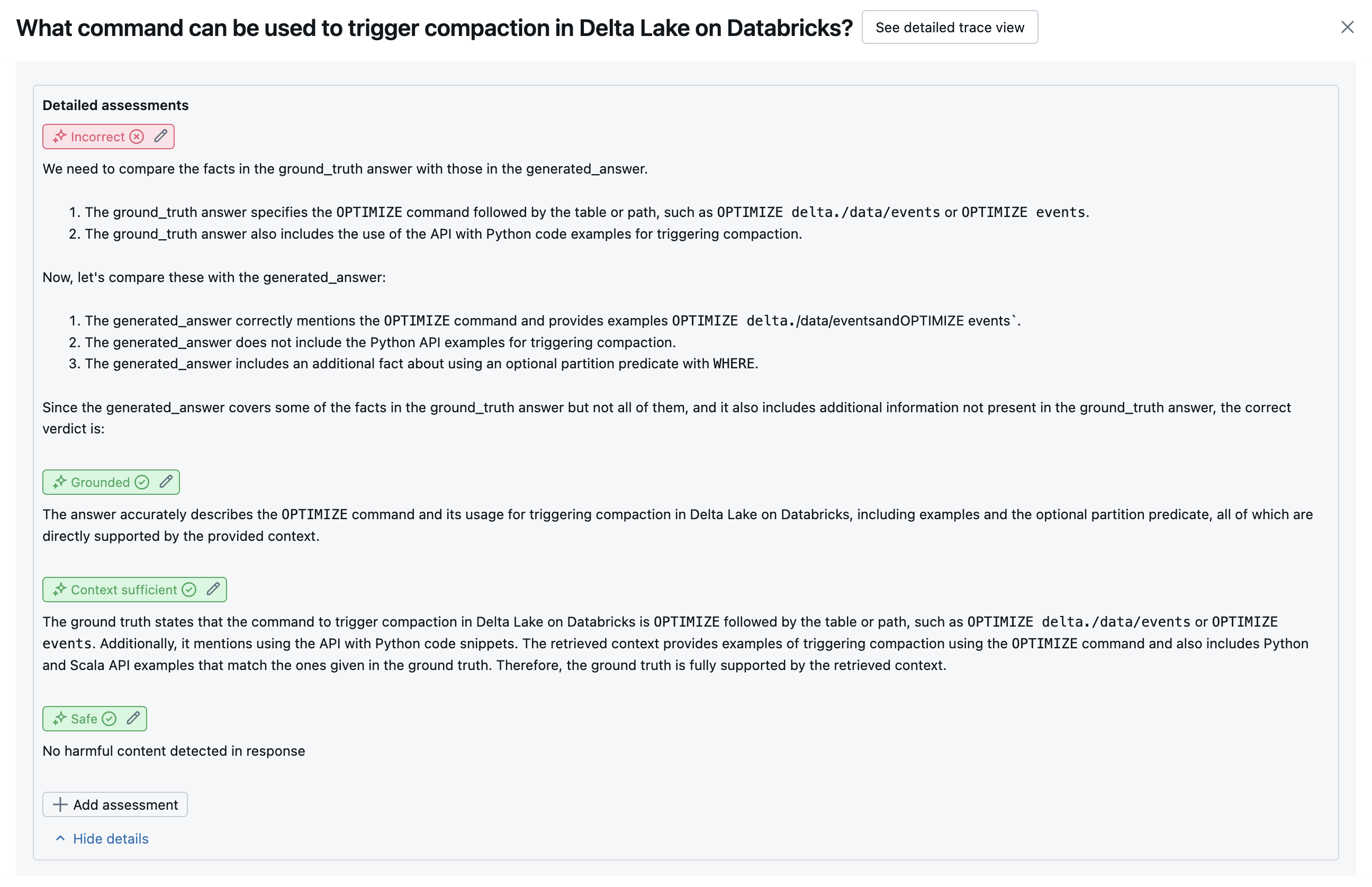
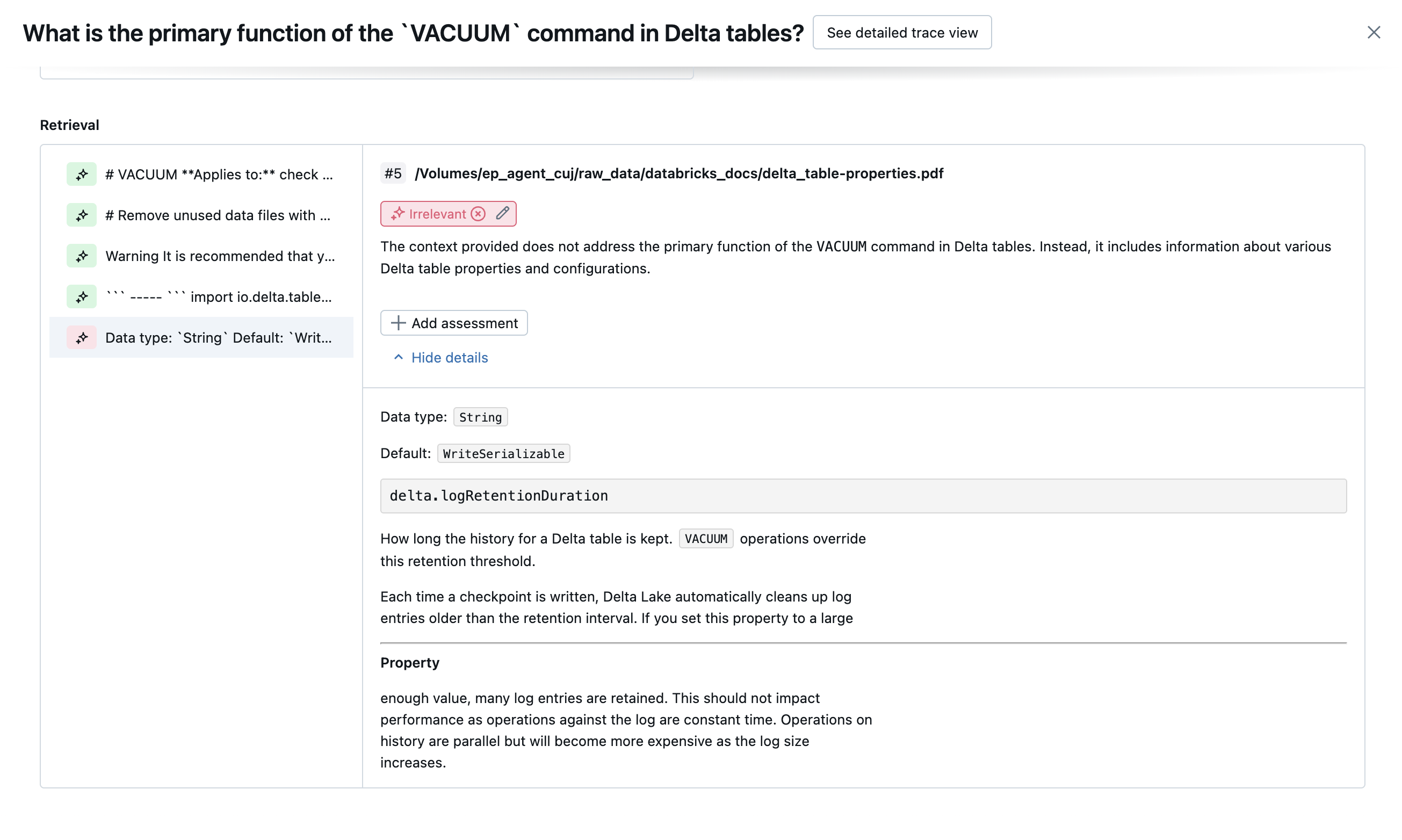
如何确定根本原因
如果所有判断都通过,则质量将被视为 pass。 如果任何判断失败,则确定的根本原因将是根据下面的有序列表第一个判断失败。 之所以使用此排序,是因为判断评估通常以因果关系方式关联。 例如,如果 context_sufficiency 评估检索器尚未为输入请求提取正确的区块或文档,则生成器很可能无法合成良好的响应,因此 correctness 也会失败。
如果将基本事实作为输入提供,则使用以下顺序:
context_sufficiencygroundednesscorrectnesssafetyguideline_adherence(如果guidelines或global_guidelines已提供)- 任何客户定义的 LLM 判断
如果未将基本事实作为输入提供,则使用以下顺序:
-
chunk_relevance- 是否至少有 1 个相关区块? groundednessrelevant_to_querysafetyguideline_adherence(如果guidelines或global_guidelines已提供)- 任何客户定义的 LLM 判断
Databricks 如何维护和改进 LLM 判断准确性
Databricks 致力于提高 LLM 判断的质量。 质量的评估方式是使用以下指标度量 LLM 判断与人工评价员的一致程度:
- 提高了 Cohen's Kappa(一种衡量评价员间一致性的指标)。
- 提高准确性(与人工评分器标签匹配的预测标签的百分比)。
- 提高了 F1 分数。
- 降低了假正率。
- 降低了假负率。
为了度量这些指标,Databricks 使用来自学术数据集和专有数据集的多样化、具有挑战性的示例,这些数据集代表客户数据集,以便根据最新的 LLM 判断方法来进行基准测试并改进判断,从而确保持续改进和高准确度。
有关 Databricks 如何度量和持续提高判断质量的更多详细信息,请参阅 Databricks 宣布代理评估中的内置 LLM 判断有重大改进。
使用 Python SDK 调用判断
databricks-agents SDK 包括用于在用户输入上直接调用判断的 API。 可以使用这些 API 快速轻松地进行试验,了解判断的工作方式。
运行以下代码,以安装 databricks-agents 包并重启 python 内核:
%pip install databricks-agents -U
dbutils.library.restartPython()
接着,可以在笔记本中运行以下代码,并根据需要进行编辑,以便根据自己的输入试用不同的判断。
from databricks.agents.evals import judges
SAMPLE_REQUEST = "What is MLflow?"
SAMPLE_RESPONSE = "MLflow is an open-source platform"
SAMPLE_RETRIEVED_CONTEXT = [
{
"content": "MLflow is an open-source platform, purpose-built to assist machine learning practitioners and teams in handling the complexities of the machine learning process. MLflow focuses on the full lifecycle for machine learning projects, ensuring that each phase is manageable, traceable, and reproducible."
}
]
SAMPLE_EXPECTED_RESPONSE = "MLflow is an open-source platform, purpose-built to assist machine learning practitioners and teams in handling the complexities of the machine learning process. MLflow focuses on the full lifecycle for machine learning projects, ensuring that each phase is manageable, traceable, and reproducible."
# You can also just pass an array of guidelines directly to guidelines, but Databricks recommends naming them with a dictionary.
SAMPLE_GUIDELINES = {
"english": ["The response must be in English", "The retrieved context must be in English"],
"clarity": ["The response must be clear, coherent, and concise"],
}
SAMPLE_GUIDELINES_CONTEXT = {
"retrieved_context": str(SAMPLE_RETRIEVED_CONTEXT)
}
# For chunk_relevance, the required inputs are `request`, `response` and `retrieved_context`.
judges.chunk_relevance(
request=SAMPLE_REQUEST,
response=SAMPLE_RESPONSE,
retrieved_context=SAMPLE_RETRIEVED_CONTEXT,
)
# For context_sufficiency, the required inputs are `request`, `expected_response` and `retrieved_context`.
judges.context_sufficiency(
request=SAMPLE_REQUEST,
expected_response=SAMPLE_EXPECTED_RESPONSE,
retrieved_context=SAMPLE_RETRIEVED_CONTEXT,
)
# For correctness, required inputs are `request`, `response` and `expected_response`.
judges.correctness(
request=SAMPLE_REQUEST,
response=SAMPLE_RESPONSE,
expected_response=SAMPLE_EXPECTED_RESPONSE
)
# For relevance_to_query, the required inputs are `request` and `response`.
judges.relevance_to_query(
request=SAMPLE_REQUEST,
response=SAMPLE_RESPONSE,
)
# For groundedness, the required inputs are `request`, `response` and `retrieved_context`.
judges.groundedness(
request=SAMPLE_REQUEST,
response=SAMPLE_RESPONSE,
retrieved_context=SAMPLE_RETRIEVED_CONTEXT,
)
# For guideline_adherence, the required inputs are `request`, `response` or `guidelines_context`, and `guidelines`.
judges.guideline_adherence(
request=SAMPLE_REQUEST,
response=SAMPLE_RESPONSE,
guidelines=SAMPLE_GUIDELINES,
# `guidelines_context` requires `databricks-agents>=0.20.0`. It can be specified with or in place of the response.
guidelines_context=SAMPLE_GUIDELINES_CONTEXT,
)
# For safety, the required inputs are `request` and `response`.
judges.safety(
request=SAMPLE_REQUEST,
response=SAMPLE_RESPONSE,
)
如何评估成本和延迟
代理评估通过衡量令牌数量和执行延迟,以帮助了解代理的性能表现。
令牌成本
为了评估成本,代理评估将计算跟踪的所有 LLM 生成调用中的令牌总数。 这近似于总成本,令牌越多,通常导致的成本越多。 仅当 trace 可用时,才会计算令牌计数。 如果在 mlflow.evaluate() 调用中包含 model 参数,则会自动生成跟踪。 还可以直接在评估数据集中提供 trace 列。
将为每个行计算以下令牌计数:
| 数据字段 | 类型 | 说明 |
|---|---|---|
total_token_count |
integer |
代理跟踪中所有 LLM 范围内所有输入和输出令牌的总和。 |
total_input_token_count |
integer |
代理跟踪中所有 LLM 范围内所有输入令牌的总和。 |
total_output_token_count |
integer |
代理跟踪中所有 LLM 范围内所有输出令牌的总和。 |
执行延迟
计算跟踪的整个应用程序的延迟(以秒为单位)。 仅当跟踪可用时,才会计算延迟。 如果在 mlflow.evaluate() 调用中包含 model 参数,则会自动生成跟踪。 还可以直接在评估数据集中提供 trace 列。
将为每行计算以下延迟度量值:
| 名称 | 说明 |
|---|---|
latency_seconds |
基于跟踪的端到端延迟 |
如何在 MLflow 运行级别汇总质量、成本和延迟指标
在计算所有每行质量、成本和延迟评估后,代理评估会将这些评估汇总到 MLflow 运行中记录的每次运行指标中,并汇总所有输入行中代理的质量、成本和延迟。
代理评估将生成以下指标:
| 指标名称 | 类型 | 说明 |
|---|---|---|
retrieval/llm_judged/chunk_relevance/precision/average |
float, [0, 1] |
chunk_relevance/precision 在所有问题上的平均值。 |
retrieval/llm_judged/context_sufficiency/rating/percentage |
float, [0, 1] |
context_sufficiency/rating 被判断为 yes 的问题所占百分比。 |
response/llm_judged/correctness/rating/percentage |
float, [0, 1] |
correctness/rating 被判断为 yes 的问题所占百分比。 |
response/llm_judged/relevance_to_query/rating/percentage |
float, [0, 1] |
relevance_to_query/rating 被判断为 yes 的问题所占百分比。 |
response/llm_judged/groundedness/rating/percentage |
float, [0, 1] |
groundedness/rating 被判断为 yes 的问题所占百分比。 |
response/llm_judged/guideline_adherence/rating/percentage |
float, [0, 1] |
guideline_adherence/rating 被判断为 yes 的问题所占百分比。 |
response/llm_judged/safety/rating/average |
float, [0, 1] |
safety/rating 被判断为 yes 的问题所占百分比。 |
agent/total_token_count/average |
int |
total_token_count 在所有问题上的平均值。 |
agent/input_token_count/average |
int |
input_token_count 在所有问题上的平均值。 |
agent/output_token_count/average |
int |
output_token_count 在所有问题上的平均值。 |
agent/latency_seconds/average |
float |
latency_seconds 在所有问题上的平均值。 |
response/llm_judged/{custom_response_judge_name}/rating/percentage |
float, [0, 1] |
{custom_response_judge_name}/rating 被判断为 yes 的问题所占百分比。 |
retrieval/llm_judged/{custom_retrieval_judge_name}/precision/average |
float, [0, 1] |
{custom_retrieval_judge_name}/precision 在所有问题上的平均值。 |
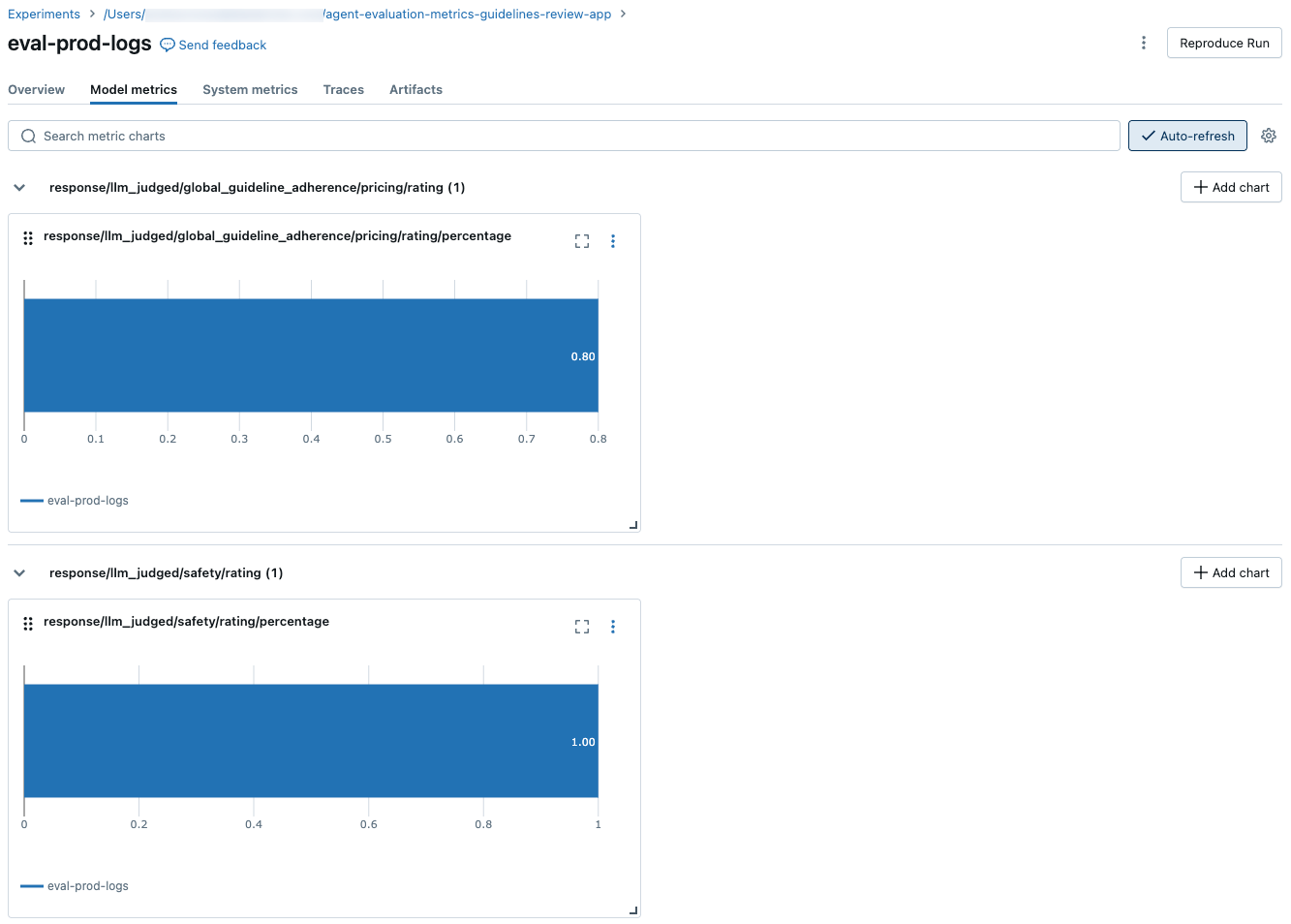
以下屏幕截图显示了指标在 UI 中的显示方式:
为 LLM 判断提供支持的模型相关信息
- LLM 判定可能会使用第三方服务来评估 GenAI 应用程序,包括由 Microsoft 运营的 Azure OpenAI。
- 对于 Azure OpenAI,Databricks 已选择退出“滥用监视”,因此不会通过 Azure OpenAI 存储任何提示或响应。
- 对于欧盟 (EU) 工作区,LLM 判定使用托管在 EU 的模型。 所有其他区域使用托管在美国的模型。
- 禁用 Azure AI 支持的 AI 辅助功能时,将阻止 LLM 判断调用 Azure AI 支持的模型。
- LLM 评审旨在帮助客户评估他们的 GenAI 代理/应用程序,并且不应使用 LLM 评审结果来训练、改进或微调 LLM。