生成 AI 代理并使用 Databricks Apps 进行部署。 Databricks Apps 提供对代理代码、服务器配置和部署工作流的完全控制。 当你需要自定义服务器行为、基于 git 的版本控制或本地 IDE 开发时,此方法是理想的方法。
Tip
如果代理仅使用Azure Databricks托管的工具,并且不需要工具调用之间的自定义逻辑,则可以使用 Supervisor API (Beta)让Azure Databricks管理代理循环。
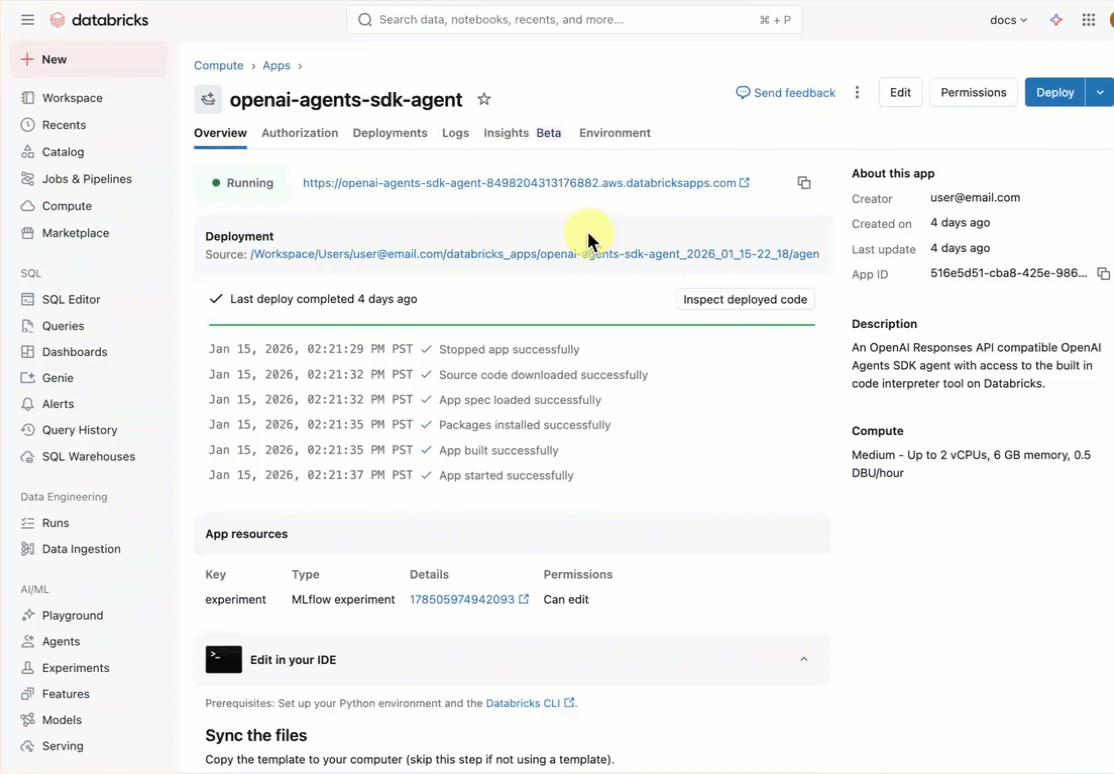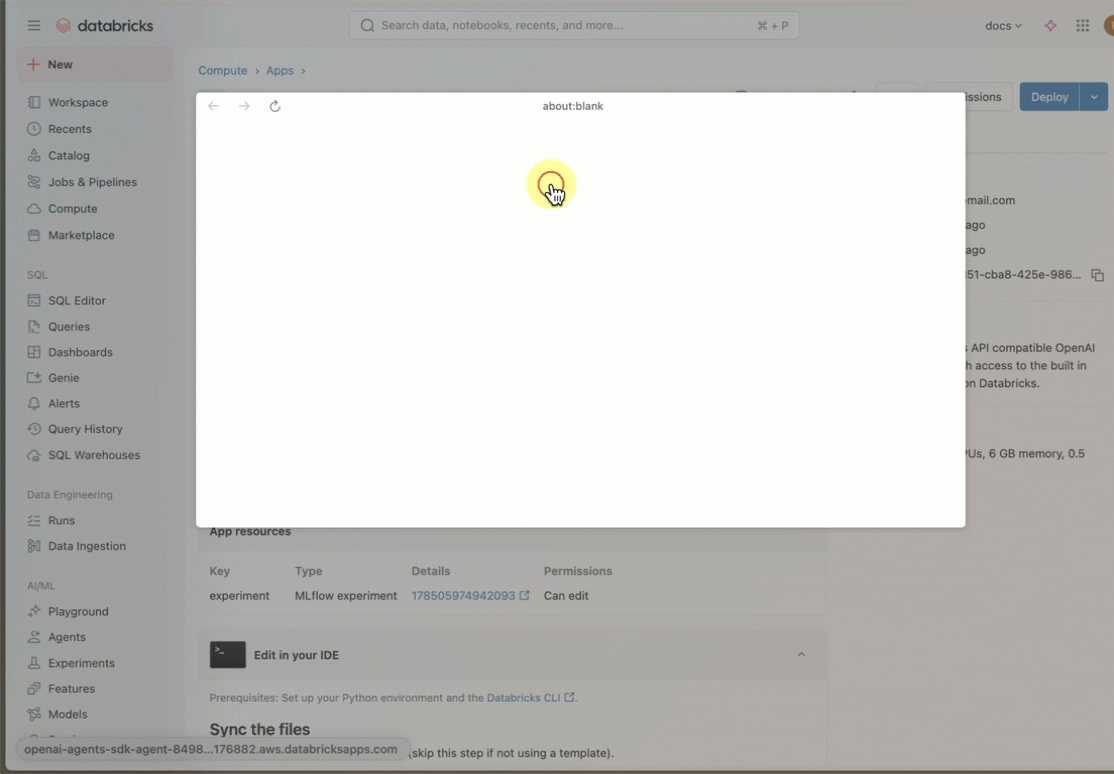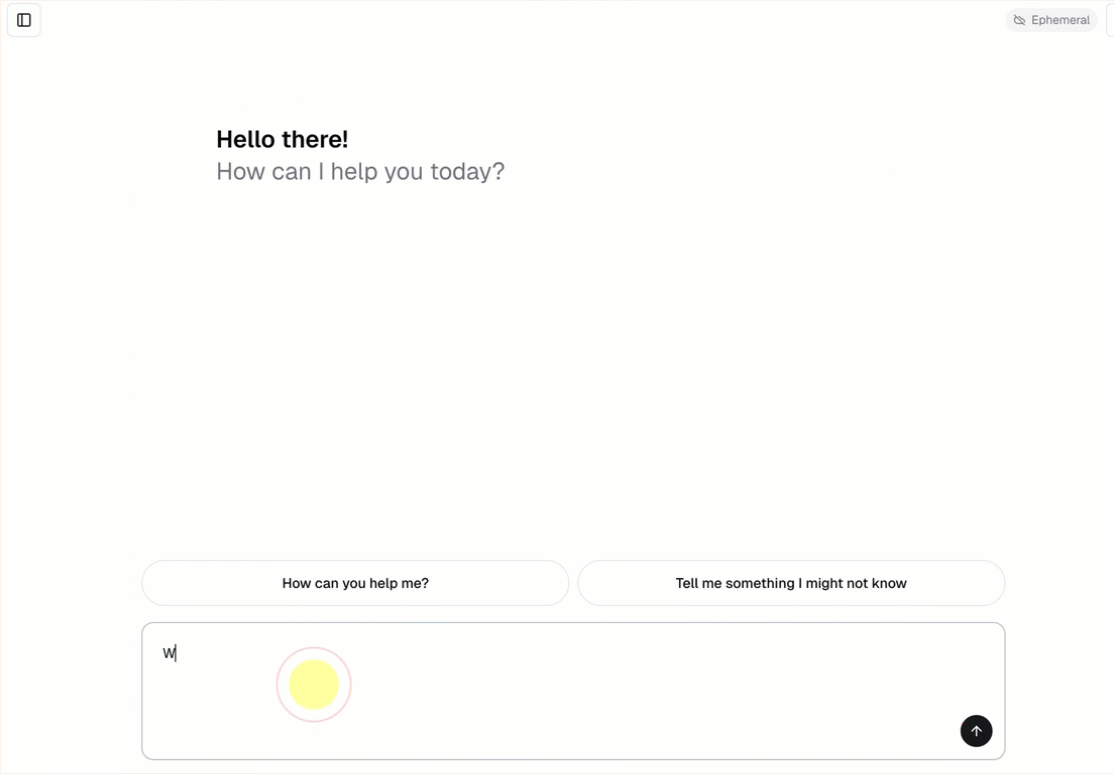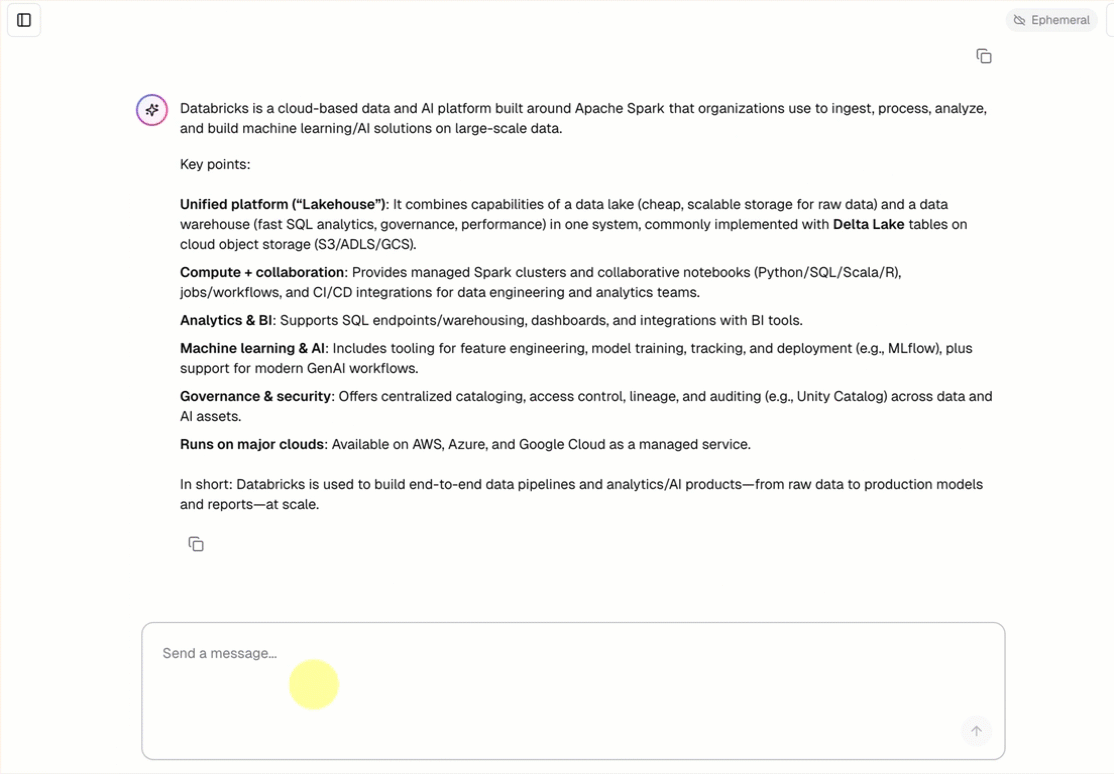
每个聊天 代理模板 都包含一个内置聊天 UI(如上所示),无需进行其他设置。 聊天 UI 支持流式处理响应、Markdown 呈现、Databricks 身份验证和可选的持久聊天历史记录。
要求
在工作区中启用 Databricks 应用。 请参阅 设置 Databricks Apps 工作区和开发环境。
步骤 1. 克隆代理应用模板
开始使用 Databricks 应用模板存储库中的预生成代理模板。
本教程使用 agent-openai-agents-sdk 模板,其中包括:
- 使用 OpenAI 代理 SDK 创建的代理
- 适用于代理应用的基础代码,包含会话 REST API 和交互式聊天 UI。
- 使用 MLflow 评估代理的代码
选择以下路径之一以设置模板:
工作区 UI
使用工作区 UI 安装应用模板。 这会安装应用并将其部署到工作区中的计算资源。 然后,可以将应用程序文件同步到本地环境,以便进一步开发。
在 Databricks 工作区中,单击“ + 新建>应用”。
单击“代理>自定义代理”(OpenAI SDK)。
使用名称
openai-agents-template创建新的 MLflow 试验,并完成设置的其余部分以安装模板。创建应用后,单击应用 URL 以打开聊天 UI。
创建应用后,将源代码下载到本地计算机以对其进行自定义:
在“同步文件”下复制第一个命令
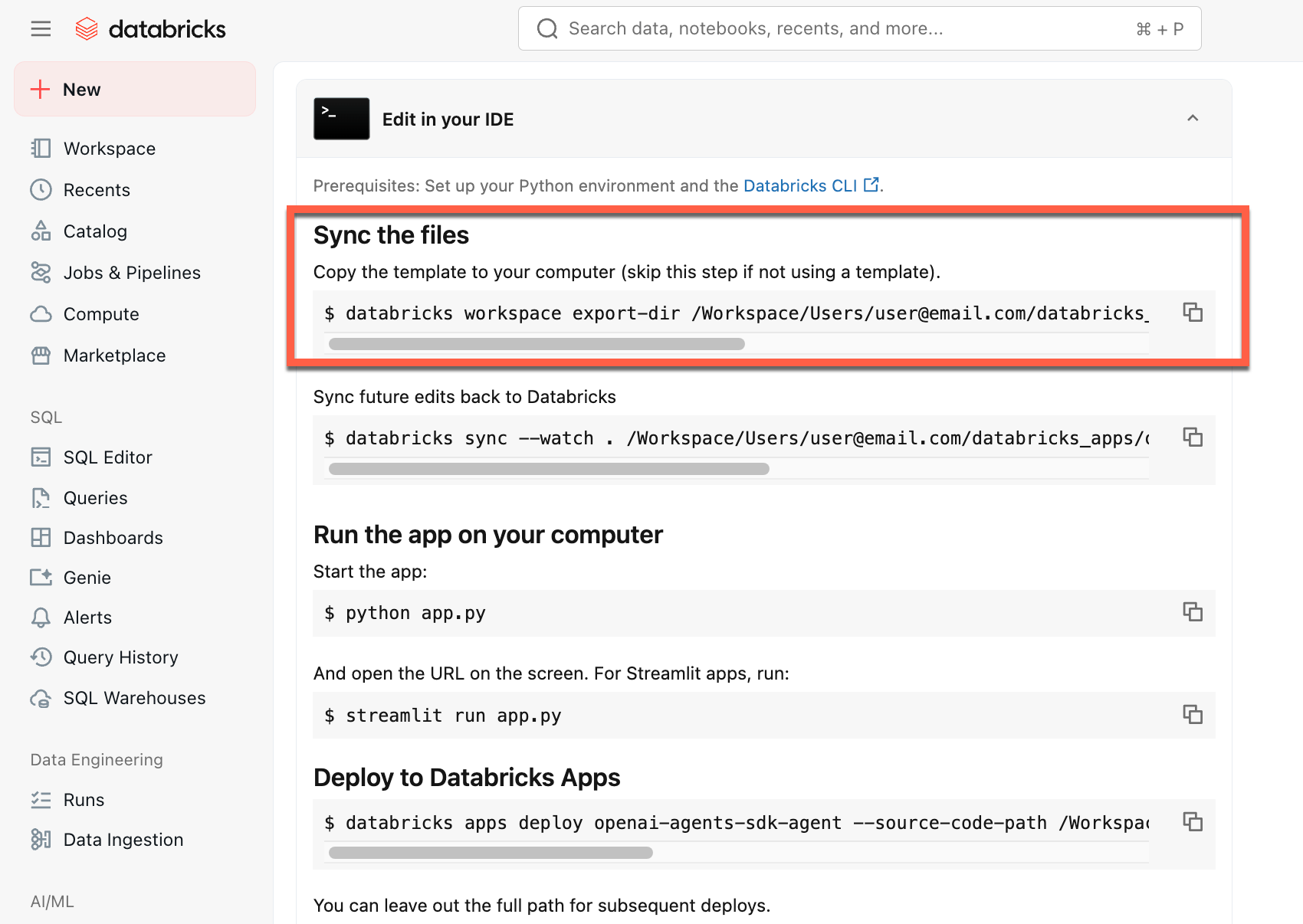
在本地终端中,运行复制的命令。
从GitHub克隆
若要从本地环境开始,请克隆代理模板存储库并打开 agent-openai-agents-sdk 目录:
git clone https://github.com/databricks/app-templates.git
cd app-templates/agent-openai-agents-sdk
步骤 2. 了解代理应用程序
代理模板演示了具有这些关键组件的生产就绪体系结构。 打开以下部分,了解有关每个组件的更多详细信息:

打开以下部分,了解有关每个组件的更多详细信息:
 内置聊天 UI
内置聊天 UI
代理模板自动提取并运行 聊天应用模板 作为其前端。 此聊天 UI 捆绑到相同的 Databricks 应用部署中,并随代理一起提供,因此不需要其他设置。
可以直接在项目中自定义聊天 UI。 有关聊天应用功能的更多详细信息,包括如何启用持久聊天历史记录和用户反馈收集,请参阅 与 Databricks 应用生成和共享聊天 UI。
 MLflow AgentServer
MLflow AgentServer
处理具有内置跟踪和可观测性的代理请求的异步 FastAPI 服务器。
AgentServer 提供/responses用于查询代理的终结点,并自动管理请求路由、日志记录和错误处理。

ResponsesAgent 接口
Databricks 建议使用 MLflow ResponsesAgent 来生成代理。
ResponsesAgent 允许使用任何第三方框架生成代理,然后将其与 Databricks AI 功能集成,实现可靠的日志记录、跟踪、评估、部署和监视功能。

若要了解如何创建ResponsesAgent,请参阅MLflow 文档中的示例 - 用于模型服务的 ResponsesAgent。
ResponsesAgent 提供以下优势:
高级代理功能
- 多代理支持
- 流式处理输出:以较小的区块流式传输输出。
- 全面的工具呼叫消息历史记录:返回多个消息,包括中间工具呼叫消息,以提高质量和聊天管理。
- 工具调用确认支持
- 长期运行工具的支持
简化的开发、部署和监视
-
使用任何框架创作代理:使用
ResponsesAgent接口封装任何现有代理,以便与 AI Playground、代理评估和代理监控实现开箱即用的兼容性。 - 特定类型编写接口:使用特定类型化的 Python 类编写代理代码,受益于 IDE 和笔记本的代码自动完成。
- 自动跟踪:MLflow 自动聚合跟踪中的流式响应,以便更轻松地评估和显示。
-
与 OpenAI
Responses架构兼容:请参阅 OpenAI:响应与 ChatCompletion。
-
使用任何框架创作代理:使用
 OpenAI 代理 SDK
OpenAI 代理 SDK
该模板使用 OpenAI 代理 SDK 作为聊天管理和工具业务流程的代理框架。 可以使用任何框架开发代理。 关键是使用 MLflow ResponsesAgent 接口对你的代理进行包装。
 MCP (模型上下文协议) 服务器
MCP (模型上下文协议) 服务器
该模板连接到 Databricks MCP 服务器,使代理能够访问工具和数据源。 请参阅 Databricks 上的模型上下文协议(MCP)。
使用 AI 编码助手创作代理
Databricks 建议使用 AI 编码助手(如 Claude、Cursor 和 Copilot)编写代理程序。 使用提供的代理技能,在/.claude/skills中,并使用AGENTS.md文件,来帮助 AI 助手了解项目结构、可用工具和最佳做法。 代理可以自动读取这些文件来开发和部署 Databricks 应用。
步骤 3. 将工具添加到代理
通过将其连接到 MCP 服务器,为代理提供查询数据库、搜索文档或调用外部 API 等代理功能。 代理模板包括默认 MCP 服务器连接。 若要添加更多工具,请在代理代码中配置其他 MCP 服务器,并在该代码中 databricks.yml授予所需的权限。
请参阅 AI 代理工具 ,了解受支持的工具类型和代码示例。
定义本地 Python 函数工具
对于不需要外部数据源或 API 的操作,请直接在代理代码中定义工具。 这些工具与代理在同一进程中运行,对于数据转换、计算或实用工具操作非常有用。
OpenAI 代理 SDK
@function_tool使用 OpenAI 代理 SDK 中的修饰器:
from agents import Agent, function_tool
@function_tool
def get_current_time() -> str:
"""Get the current date and time."""
from datetime import datetime
return datetime.now().isoformat()
agent = Agent(
name="My agent",
instructions="You are a helpful assistant.",
model="databricks-claude-sonnet-4-5",
tools=[get_current_time],
)
LangGraph
使用 LangChain 中的 @tool 修饰器:
from langchain_core.tools import tool
from langgraph.prebuilt import create_react_agent
from databricks_langchain import ChatDatabricks
@tool
def get_current_time() -> str:
"""Get the current date and time."""
from datetime import datetime
return datetime.now().isoformat()
agent = create_react_agent(
ChatDatabricks(endpoint="databricks-claude-sonnet-4-5"),
tools=[get_current_time],
)
本地函数工具不需要资源授予,这是因为它们运行在代理进程中。
步骤 4. 通过 Unity AI 网关治理你在 Databricks 应用上的代理对 LLM 的使用
通过 AI 网关(Beta) 路由代理的 LLM 调用,以便无论哪个提供商回答请求,每个请求都受同一控件的约束。 使用请求路径中的网关,无需修改代理代码或轮换提供程序凭据,即可集中权限、每个应用的属性成本、交换模型以及检查或重播流量。
Important
此功能在 Beta 版中。 工作区管理员可以从 预览 页控制对此功能的访问。 请参阅 Manage Azure Databricks 预览版。
在工作区上启用 AI 网关。 AI 网关在 Beta 版期间需要选择加入。 帐户管理员必须先从帐户控制台 预览 页打开它,然后才能创建或查询网关终结点。 请参阅 Manage Azure Databricks 预览版。
将代理指向 AI 网关终结点。 在代理代码中,将 AI 网关终结点名称作为
model参数传递,并在 Azure Databricks LLM 客户端上设置use_ai_gateway=True。 客户端通过网关路由流量并自动处理身份验证。OpenAI
from agents import Agent, set_default_openai_api, set_default_openai_client from databricks_openai import AsyncDatabricksOpenAI set_default_openai_client(AsyncDatabricksOpenAI(use_ai_gateway=True)) set_default_openai_api("chat_completions") agent = Agent( name="Agent", instructions="You are a helpful assistant.", model="<ai-gateway-endpoint>", )LangGraph
from databricks_langchain import ChatDatabricks llm = ChatDatabricks( model="<ai-gateway-endpoint>", use_ai_gateway=True, )有关其他 API 图面(OpenAI 响应 API、Anthropic 消息 API、Google Gemini)和 REST 示例,请参阅 Query Unity AI 网关终结点。
高级创作主题
流式响应
流式处理响应
流式处理允许代理以实时区块形式发送响应,而不是等待完整的响应。 要实现ResponsesAgent的流式处理,请依次发出一系列增量事件,最后再发出一个完成事件。
-
发出增量事件:发送多个具有相同的
output_text.delta的item_id事件,以实时流式传输文本区块。 -
通过完成事件结束:发送最终
response.output_item.done事件,其item_id与增量事件相同,包含完整的最终输出文本。
每个 delta 事件将一段文本流式传输到客户端。 最终完成事件包含完整的响应文本,并指示 Databricks 执行以下作:
- 使用 MLflow 跟踪代理的输出
- AI 网关推理表中的聚合流式响应
- 在 AI Playground UI 中显示完整的输出
流式处理错误传播
Mosaic AI 在使用 databricks_output.error 中的最后一个令牌进行流式处理时传递所遇到的任何错误。 由调用客户端来正确处理和显示此错误。
{
"delta": …,
"databricks_output": {
"trace": {...},
"error": {
"error_code": BAD_REQUEST,
"message": "TimeoutException: Tool XYZ failed to execute."
}
}
}
自定义输入和输出
自定义输入和输出
某些方案可能需要其他代理输入,例如 client_type ,或 session_id检索源链接等输出,这些源链接不应包含在聊天历史记录中供将来交互使用。
对于这些方案,MLflow ResponsesAgent 原生支持字段 custom_inputs 和 custom_outputs。 上面的框架示例中可以通过 request.custom_inputs 访问自定义输入。
代理评估评审应用不支持为具有其他输入字段的代理呈现跟踪信息。
在 AI实验空间和审核应用中提供custom_inputs
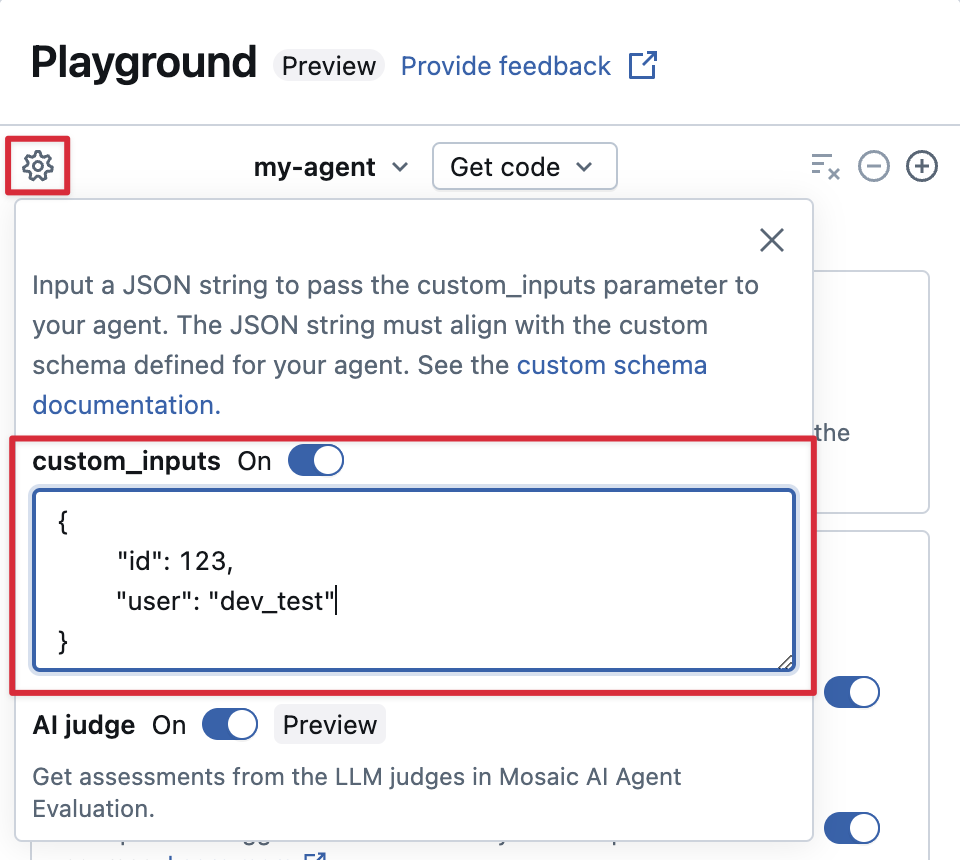
如果代理使用 custom_inputs 字段接受其他输入,则可以在 AI Playground 和 评审应用中手动提供这些输入。
在 AI 操场或代理评审应用中,选择齿轮图标
 。
。启用自定义输入。
提供与代理定义的输入架构匹配的 JSON 对象。
步骤 5. 在本地运行代理应用
设置本地环境:
安装
uv(Python 包管理器)、nvm(节点版本管理器)和 Databricks CLI:-
uv安装 -
nvm安装 - 运行以下命令以使用 Node 20 LTS:
nvm use 20 -
databricks CLI安装
-
将目录更改为
agent-openai-agents-sdk文件夹。运行提供的快速入门脚本以安装依赖项、设置环境并启动应用。
uv run quickstart uv run start-app
在浏览器中,转到 http://localhost:8000 打开内置聊天 UI 并开始与代理聊天。
步骤 6. 配置身份验证
代理需要身份验证才能访问Azure Databricks资源。 Databricks 应用提供两种身份验证方法:应用授权(服务主体)和用户授权(代表用户)。 可以通过工作区 UI 或在 databricks.yml 中使用声明性自动化捆绑包进行配置。 代理模板附带了一个 databricks.yml,因此从模板开始时,该路径是默认的。
有关包括所有受支持的资源类型、权限值,以及端到端 databricks.yml 演练的完整参考,请参阅 AI 代理的身份验证。
应用授权(默认值)
应用授权使用Azure Databricks自动为应用创建的服务主体。 所有用户共享相同的权限。
在resources.apps.<app>.resourcesdatabricks.yml中声明代理使用的每个资源。 部署捆绑包以向服务主体授予声明的权限:
resources:
apps:
agent_openai_agents_sdk:
name: 'agent-openai-agents-sdk'
source_code_path: ./
config:
command: ['uv', 'run', 'start-app']
env:
- name: MLFLOW_TRACKING_URI
value: 'databricks'
- name: MLFLOW_REGISTRY_URI
value: 'databricks-uc'
- name: MLFLOW_EXPERIMENT_ID
value_from: 'experiment'
resources:
- name: 'experiment'
experiment:
experiment_id: '<experiment-id>'
permission: 'CAN_EDIT'
- name: 'llm'
serving_endpoint:
name: 'databricks-claude-sonnet-4-5'
permission: 'CAN_QUERY'
databricks bundle deploy
databricks bundle run agent_openai_agents_sdk
有关资源类型的完整列表,请参阅 应用授权。
用户授权
用户授权允许代理处理每个用户的个人权限。 如果需要每个用户的访问控制或审核线索,请使用此功能。
将此代码添加到你的代理中:
from agent_server.utils import get_user_workspace_client
# In your agent code (inside @invoke or @stream)
user_workspace = get_user_workspace_client()
# Access resources with the user's permissions
response = user_workspace.serving_endpoints.query(name="my-endpoint", inputs=inputs)
Important
在get_user_workspace_client()或@invoke函数中初始化@stream,而不是在应用启动时进行初始化。 仅当处理请求时,用户凭据才存在。
在 user_api_scopes 应用中,通过在 databricks.yml 下添加范围来配置代理可以代表用户调用的 Azure Databricks API:
resources:
apps:
agent_openai_agents_sdk:
name: 'agent-openai-agents-sdk'
source_code_path: ./
user_api_scopes:
- sql
- dashboards.genie
- serving.serving-endpoints
databricks bundle deploy
databricks bundle run agent_openai_agents_sdk
有关可用范围的列表和完整的设置说明,请参阅 用户授权。
步骤 7. 评估代理
该模板包括代理评估代码。 有关详细信息,请参阅 agent_server/evaluate_agent.py。 通过在终端中运行以下命令来评估代理响应的相关性和安全性:
uv run agent-evaluate
步骤 8。 将代理部署到 Databricks 应用
配置身份验证后,将代理部署到Azure Databricks。 代理模板使用 Databricks 资产捆绑包(DAB) 进行部署。
databricks.yml模板中的文件定义应用配置和资源权限。 确保已安装并配置 Databricks CLI 。
注意
如果在步骤 1 中通过工作区 UI 创建了应用,请在部署之前运行 databricks bundle deployment bind agent_openai_agents_sdk <app-name> --auto-approve 以将现有应用绑定到捆绑包。 否则, databricks bundle deploy 将失败并显示“已存在同名的应用”。
在部署之前验证捆绑配置以捕获错误:
databricks bundle validate部署捆绑包。 将会上传您的代码并配置在以下文件中
databricks.yml定义的资源(MLflow 试验、服务端点等):databricks bundle deploy启动或重启应用:
databricks bundle run agent_openai_agents_sdk注意
bundle deploy仅上传文件和配置资源。bundle run需要使用新代码启动或重启应用。
对于将来的更新,请先运行 databricks bundle deploy,然后 databricks bundle run agent_openai_agents_sdk 进行重新部署。
步骤 9. 查询已部署的代理
以下示例使用具有 OAuth 令牌的快速 curl 请求。 Databricks Apps 不支持个人访问令牌(PAT)。
有关查询方法的完整列表(包括 Databricks OpenAI 客户端和 REST API),请参阅
使用 Databricks CLI 生成 OAuth 令牌:
databricks auth login --host <https://host.databricks.com>
databricks auth token
使用令牌查询代理:
curl -X POST <app-url.databricksapps.com>/responses \
-H "Authorization: Bearer <oauth token>" \
-H "Content-Type: application/json" \
-d '{ "input": [{ "role": "user", "content": "hi" }], "stream": true }'
局限性
- 仅支持中型和大型计算大小。 请参阅 配置 Databricks 应用的计算资源。
- MLflow 审阅应用聊天 UI 目前不支持在 Databricks 应用上部署的代理。 若要评估现有跟踪,请使用 标记会话,无论部署方法如何,这些会话都起作用。 Databricks 正在直接在 聊天机器人模板中构建评审和反馈支持。