本文介绍如何使用 马赛克 AI 矢量搜索创建矢量搜索终结点和索引。
可以使用 UI、 Python SDK 或 REST API 创建和管理矢量搜索组件,例如矢量搜索终结点和矢量搜索索引。
有关演示如何创建和查询矢量搜索终结点的示例笔记本,请参阅 矢量搜索示例笔记本。 有关参考信息,请参阅 Python SDK 参考。
要求
- 已启用 Unity Catalog 的工作区。
- 已启用无服务器计算。 详细说明,请参阅连接到无服务器计算。
- 对于 标准终结点,源表必须启用更改数据馈送。 请参阅在 Azure Databricks 上使用 Delta Lake 更改数据馈送。
- 若要创建矢量搜索索引,必须在要在其中创建索引的目录架构上拥有 CREATE TABLE 权限。
- 若要查询其他用户拥有的索引,必须具有其他权限。 请参阅 如何查询矢量搜索索引。
使用访问控制列表配置创建和管理矢量搜索终结点的权限。 请参阅矢量搜索终结点 ACL。
Installation
若要使用矢量搜索 SDK,必须在笔记本中安装它。 使用以下代码安装包:
%pip install databricks-vectorsearch
dbutils.library.restartPython()
然后使用以下命令导入 VectorSearchClient:
from databricks.vector_search.client import VectorSearchClient
有关身份验证的信息,请参阅 数据保护和身份验证。
创建矢量搜索终结点
可以使用 Databricks UI、Python SDK 或 API 创建矢量搜索终结点。
使用 UI 创建矢量搜索终结点
按照以下步骤使用 UI 创建矢量搜索终结点。
在左侧栏中,单击“ 计算”。
单击 “矢量搜索 ”选项卡,然后单击“ 创建”。

此时会打开 “创建终结点”窗体 。 输入此终结点的名称。
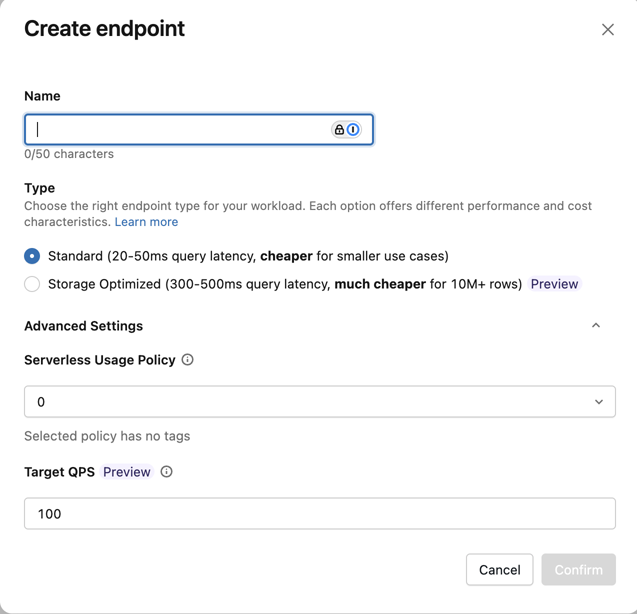
在 “类型” 字段中,选择“ 标准 ”或“ 存储优化”。 请参阅 终结点选项。
(可选)在 “高级设置”下,选择预算策略。 请参阅 马赛克 AI 矢量搜索:预算策略。
单击“确认”。
使用 Python SDK 创建矢量搜索终结点
以下示例使用 create_endpoint() SDK 函数创建矢量搜索终结点。
# The following line automatically generates a PAT Token for authentication
client = VectorSearchClient()
# The following line uses the service principal token for authentication
# client = VectorSearchClient(service_principal_client_id=<CLIENT_ID>,service_principal_client_secret=<CLIENT_SECRET>)
client.create_endpoint(
name="vector_search_endpoint_name",
endpoint_type="STANDARD" # or "STORAGE_OPTIMIZED"
)
使用 REST API 创建矢量搜索终结点
请参阅 REST API 参考文档: POST /api/2.0/vector-search/endpoints。
(可选)创建并配置终结点来为嵌入模型提供服务
如果选择让 Databricks 计算嵌入内容,则可以使用预配置的基础模型 API 终结点或创建提供终结点的模型来为所选的嵌入模型提供服务。 有关说明,请参阅 按令牌付费的基础模型 API,或 创建基础模型服务终结点。 有关示例笔记本,请参阅 矢量搜索示例笔记本。
配置嵌入终结点时,Databricks 建议删除 缩放到零的默认选择。 服务终结点可能需要几分钟时间来预热,因此在终结点纵向缩减的情况下对索引执行初始查询可能会超时。
注释
如果未为数据集适当配置嵌入终结点,矢量搜索索引初始化可能会超时。 应仅对小型数据集和测试使用 CPU 终结点。 对于较大的数据集,请使用 GPU 终结点实现最佳性能。
创建矢量搜索索引
可以使用 UI、Python SDK 或 REST API 创建矢量搜索索引。 UI 是最简单的方法。
有两种类型的索引:
- 增量同步索引 会自动与源 Delta 表同步,并在 Delta 表中的基础数据发生变化时,自动且增量地更新索引。
- 直接矢量访问索引 支持直接读取和写入矢量和元数据。 用户负责使用 REST API 或 Python SDK 更新此表。 无法使用 UI 创建这种类型的索引。 必须使用 REST API 或 SDK。
注释
保留列名 _id。 如果源表有一个名为 _id列,请在创建矢量搜索索引之前对其进行重命名。
使用 UI 创建索引
在左侧栏中,单击 目录 打开目录资源管理器用户界面。
导航到要使用的 Delta 表。
单击右上角的“ 创建 ”按钮,然后从下拉菜单中选择 矢量搜索索引 。
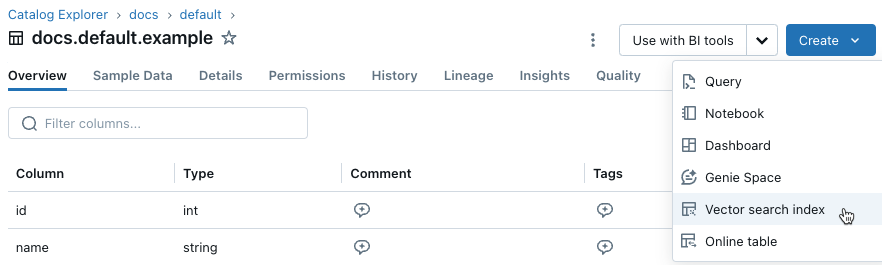
使用对话框中的选择器配置索引。
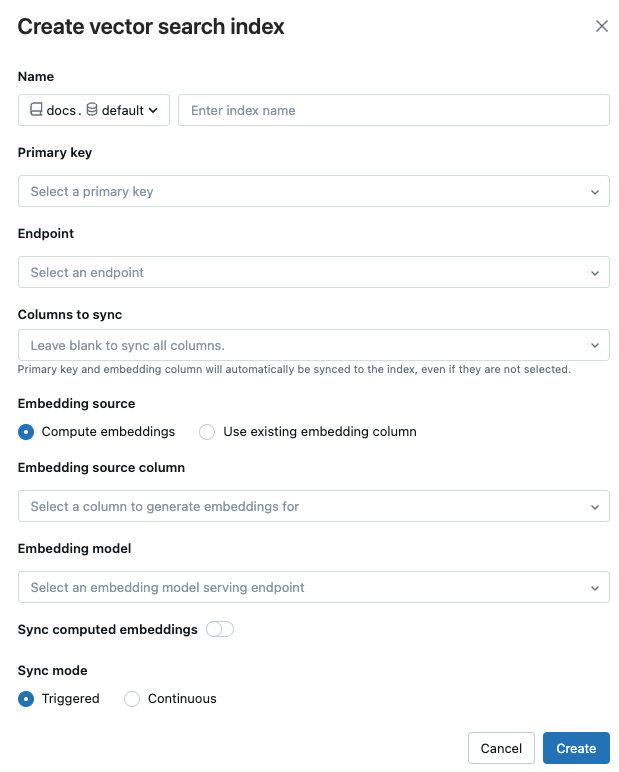
名称:用于 Unity Catalog 中在线表使用的名称。 名称需要三级命名空间。
<catalog>.<schema>.<name>仅允许字母数字字符和下划线。主键:要用作主键的列。
要同步的列:(仅标准终结点支持)。选择要与矢量索引同步的列。 如果将此字段留空,则源表中的所有列都与索引同步。 主键列和嵌入源列或嵌入向量列始终同步。 对于存储优化终结点,源表中的所有列始终同步。
嵌入源:指示您是希望 Databricks 为 Delta 表的文本列计算嵌入(计算嵌入),还是您的 Delta 表中已经包含预计算的嵌入(使用现有嵌入列)。
如果选择了 计算嵌入项,请选择要为其嵌入计算的列以及要用于计算的嵌入模型。 仅支持文本列。
对于使用标准终结点的生产应用程序,Databricks 建议将基础模型
databricks-gte-large-en与预配的吞吐量服务终结点配合使用。对于将存储优化终结点与 Databricks 托管的模型配合使用的生产应用程序,请直接使用模型名称(例如)
databricks-gte-large-en作为嵌入模型终结点。 存储优化端点在摄取时用于ai_query的批量推理处理,为嵌入作业提供高吞吐量。 如果想要使用预配的吞吐量终结点进行查询,请在创建索引时在model_endpoint_name_for_query字段中指定它。
如果选择了“使用现有嵌入列”,请选择包含预先计算的嵌入和嵌入维度的列。 预先计算的嵌入列格式应为
array[float]。 对于存储优化端点,嵌入维度必须能被 16 整除。
同步计算嵌入内容:切换此设置,将生成的嵌入内容保存到 Unity 目录表。 有关详细信息,请参阅 保存生成的嵌入表。
矢量搜索终结点:选择要存储索引的矢量搜索终结点。
同步模式:连续模式让索引以秒级延迟保持同步。 但是,由于预配了计算群集以运行连续同步流式处理管道,因此它的成本更高。
- 对于标准终结点,连续式和触发式都执行增量更新,因此仅处理自上次同步后发生变化的数据。
- 对于存储优化终结点,每次同步都会部分重新生成索引。 对于后续同步中的管理的索引,在源行未更改的情况下,将重复使用任何生成的嵌入向量,无需重新计算。 请参阅 存储优化终结点限制。
使用“触发”同步模式时,使用 Python SDK 或 REST API 启动同步。请参阅更新 Delta 同步索引。
对于存储优化终结点,仅支持触发的同步模式。
高级设置:(可选)如果选择了 计算嵌入,则可以指定单独的嵌入模型来查询矢量搜索索引。 如果需要高吞吐量终结点进行引入,但查询索引的延迟较低终结点,这非常有用。 嵌入模型字段中指定的模型始终用于引入,也用于查询,除非在此处指定其他模型。 若要指定其他模型,请单击“ 选择单独的嵌入模型”以查询索引 ,然后从下拉菜单中选择模型。

完成索引配置后,单击“ 创建”。
使用 Python SDK 创建索引
以下示例将创建 Delta 同步索引,其中包含由 Databricks 计算的嵌入。 有关详细信息,请参阅 Python SDK 参考。
此示例还显示了可选参数,该参数 model_endpoint_name_for_query指定用于查询索引的单独嵌入模型服务终结点。
client = VectorSearchClient()
index = client.create_delta_sync_index(
endpoint_name="vector_search_demo_endpoint",
source_table_name="vector_search_demo.vector_search.en_wiki",
index_name="vector_search_demo.vector_search.en_wiki_index",
pipeline_type="TRIGGERED",
primary_key="id",
embedding_source_column="text",
embedding_model_endpoint_name="e5-small-v2", # This model is used for ingestion, and is also used for querying unless model_endpoint_name_for_query is specified.
model_endpoint_name_for_query="e5-mini-v2" # Optional. If specified, used only for querying the index.
)
以下示例将创建 Delta 同步索引,其中包含自托管的嵌入。
client = VectorSearchClient()
index = client.create_delta_sync_index(
endpoint_name="vector_search_demo_endpoint",
source_table_name="vector_search_demo.vector_search.en_wiki",
index_name="vector_search_demo.vector_search.en_wiki_index",
pipeline_type="TRIGGERED",
primary_key="id",
embedding_dimension=1024,
embedding_vector_column="text_vector"
)
默认情况下,源表中的所有列都与索引同步。
在标准终结点上,你可以选择要使用 columns_to_sync 同步的列的子集。 主键和嵌入列始终包含在索引中。
若要仅同步主键和嵌入列,必须按如下所示在 中指定它们:columns_to_sync
index = client.create_delta_sync_index(
...
columns_to_sync=["id", "text_vector"] # to sync only the primary key and the embedding column
)
若要同步其他列,请指定它们,如下所示。 无需包括主键和嵌入列,因为它们始终同步。
index = client.create_delta_sync_index(
...
columns_to_sync=["revisionId", "text"] # to sync the `revisionId` and `text` columns in addition to the primary key and embedding column.
)
以下示例创建直接矢量访问索引。
client = VectorSearchClient()
index = client.create_direct_access_index(
endpoint_name="storage_endpoint",
index_name=f"{catalog_name}.{schema_name}.{index_name}",
primary_key="id",
embedding_dimension=1024,
embedding_vector_column="text_vector",
schema={
"id": "int",
"field2": "string",
"field3": "float",
"text_vector": "array<float>"}
)
使用 REST API 创建索引
请参阅 REST API 参考文档: POST /api/2.0/vector-search/indexes。
保存生成的嵌入表
如果 Databricks 生成嵌入,可以将生成的嵌入内容保存到 Unity 目录中的表中。 此表是在与矢量索引相同的架构中创建的,并且是从向量索引页链接的。
表的名称是矢量搜索索引的名称,后面追加了 _writeback_table。 该名称不可编辑。
你可以像 Unity 目录中的任何其他表一样访问和查询表。 但是,不应删除或修改表,因为它不打算手动更新。 如果删除索引,则会自动删除该表。
更新矢量搜索索引
更新 Delta 同步索引
源 Delta 表更改时,使用 连续 同步模式创建的索引会自动更新。 如果使用 触发同步 模式,则可以使用 UI、Python SDK 或 REST API 启动同步。
Databricks 用户界面
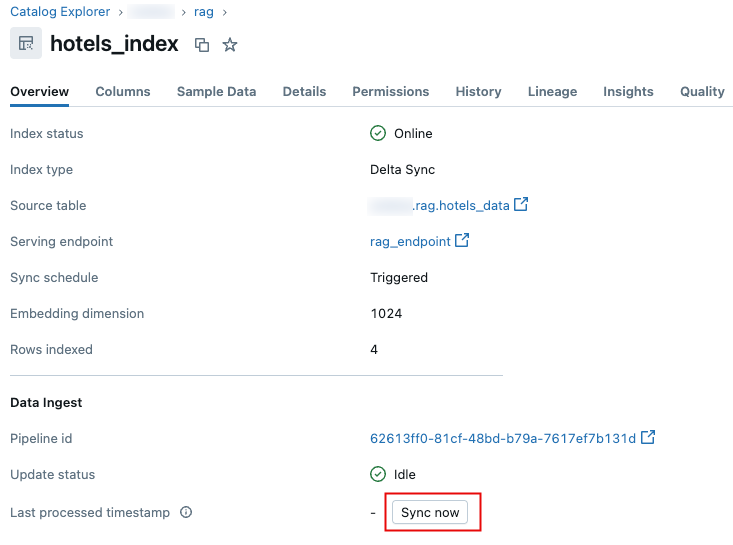
在目录资源管理器中,导航到矢量搜索索引。
在“ 概述 ”选项卡上的 “数据引入 ”部分中,单击“ 立即同步”。
Python SDK
有关详细信息,请参阅 Python SDK 参考。
client = VectorSearchClient()
index = client.get_index(index_name="vector_search_demo.vector_search.en_wiki_index")
index.sync()
REST API
请参阅 REST API 参考文档: POST /api/2.0/vector-search/indexes/{index_name}/sync。
更新直接矢量访问索引
可以使用 Python SDK 或 REST API 从直接矢量访问索引插入、更新或删除数据。
Python SDK
有关详细信息,请参阅 Python SDK 参考。
index.upsert([
{
"id": 1,
"field2": "value2",
"field3": 3.0,
"text_vector": [1.0] * 1024
},
{
"id": 2,
"field2": "value2",
"field3": 3.0,
"text_vector": [1.1] * 1024
}
])
REST API
请参阅 REST API 参考文档: POST /api/2.0/vector-search/indexes。
对于生产应用程序,Databricks 建议使用服务主体而不是个人访问令牌。 每次查询的性能最多可提升 100 毫秒。
下面的代码示例演示如何使用服务主体更新索引。
export SP_CLIENT_ID=...
export SP_CLIENT_SECRET=...
export INDEX_NAME=...
export WORKSPACE_URL=https://...
export WORKSPACE_ID=...
# Set authorization details to generate OAuth token
export AUTHORIZATION_DETAILS='{"type":"unity_catalog_permission","securable_type":"table","securable_object_name":"'"$INDEX_NAME"'","operation": "WriteVectorIndex"}'
# Generate OAuth token
export TOKEN=$(curl -X POST --url $WORKSPACE_URL/oidc/v1/token -u "$SP_CLIENT_ID:$SP_CLIENT_SECRET" --data 'grant_type=client_credentials' --data 'scope=all-apis' --data-urlencode 'authorization_details=['"$AUTHORIZATION_DETAILS"']' | jq .access_token | tr -d '"')
# Get index URL
export INDEX_URL=$(curl -X GET -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME | jq -r '.status.index_url' | tr -d '"')
# Upsert data into vector search index.
curl -X POST -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url https://$INDEX_URL/upsert-data --data '{"inputs_json": "[...]"}'
# Delete data from vector search index
curl -X DELETE -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url https://$INDEX_URL/delete-data --data '{"primary_keys": [...]}'
下面的代码示例演示如何使用个人访问令牌(PAT)更新索引。
export TOKEN=...
export INDEX_NAME=...
export WORKSPACE_URL=https://...
# Upsert data into vector search index.
curl -X POST -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME/upsert-data --data '{"inputs_json": "..."}'
# Delete data from vector search index
curl -X DELETE -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME/delete-data --data '{"primary_keys": [...]}'
如何在不停机的情况下进行架构更改
如果源表中现有列的架构发生更改,则必须重新生成索引。 如果启用了 写回表 ,则还必须在向源表添加新列时重新生成索引。 如果未启用写回表,则新列不需要重新生成索引。
按照以下步骤重新生成并部署索引,且不会停机:
- 对源表执行架构更改。
- 创建新索引。
- 新索引准备就绪后,将流量切换到新索引。
- 删除原始索引。