本文介绍了如何测量 RAG 应用程序的性能,以确定检索质量、回复质量和系统性能。
检索、回复和性能
使用评估集,你可以从许多不同的维度测量 RAG 应用程序的性能,包括:
- 检索质量:检索指标可评估 RAG 应用程序检索相关支持数据的成功程度。 精度和召回率是两个关键检索指标。
- 响应质量: 响应质量指标评估 RAG 应用程序响应用户请求的方式。 回复指标可测量得到的结果是否基于基本事实是准确的、在给定检索到的上下文的情况下回复基于事实的程度(例如,LLM 是否虚构),或者回复的安全程度如何(也就是说,是否无害)。
- 系统性能(成本和延迟):这些指标捕获 RAG 应用程序的总体成本和性能。 总体延迟和令牌消耗是链性能指标的示例。
同时收集回复指标和检索指标非常重要。 即使检索到了正确的上下文,RAG 应用程序的回复也可能很差;它也可能会基于错误的检索提供良好的回复。 只有同时测量这两个组件,我们才能准确诊断和解决应用程序中的问题。
测量性能的方法
可通过两种主要方法跨以下指标来测量性能:
- 确定性度量: 可以根据应用程序的输出确定性计算成本和延迟指标。 如果你的评估集包括了包含问题答案的文档列表,则还可以确定地计算一部分检索指标。
- 基于 LLM 的度量: 在此方法中,单独的 LLM 作为评审,评估 RAG 应用程序的检索和响应质量。 某些 LLM 判定程序(例如答案正确性)将人类标记的基本事实与应用输出进行比较。 其他 LLM 判定程序(例如有据性)不需要人类标记的基本事实来评估它们的应用输出。
重要
为了使 LLM 判定程序生效,必须对其进行调整以理解用例。 要做到这一点,需要细心观察以了解判定程序在哪些方面做得很好,哪些方面做得不好,然后调整判定程序以针对失败案例对其进行改进。
Mosaic AI 代理评估为本页上讨论的每个指标提供了现成可用的实现(使用托管 LLM 判定程序模型)。 代理评估的文档讨论了如何实施这些细节和标准,并提供功能以利用您的数据来调整标准以提高其准确性。
指标概述
下面汇总了 Databricks 建议用于测量 RAG 应用程序的质量、成本和延迟的指标。 这些指标是在 Mosaic AI 代理评估中实现的。
| 维度 | 指标名称 | 问题 | 衡量依据 | 需要基本事实? |
|---|---|---|---|---|
| 检索 | chunk_relevance/精度 | 检索到的块中与请求相关的块所占百分比是多少? | LLM 判定 | 否 |
| 检索 | 文档召回 | 在检索到的块中,提供的基本事实文档所占百分比是多少? | 具有确定性 | 是 |
| 检索 | 情境充分性 | 检索的区块是否足够生成预期的响应? | LLM 判定 | 是 |
| 响应 | 正确性 | 总体来说,代理是否生成了正确的回复? | LLM 判定 | 是 |
| 响应 | 与查询的相关性 | 回复是否与请求相关? | LLM 判定 | 否 |
| 响应 | 有据性 | 回复是虚构的还有基于实际情况? | LLM 判定 | 否 |
| 响应 | 安全 | 回复中是否有有害内容? | LLM 判定 | 否 |
| 成本 | total_token_count、total_input_token_count、total_output_token_count | LLM 代系的令牌总数是多少? | 具有确定性 | 否 |
| 延迟 | 延迟(秒) | 执行应用的延迟是多少? | 具有确定性 | 否 |
检索指标如何工作
检索指标帮助你了解检索器是否提供了相关结果。 检索指标基于精准率和召回率。
| 标准名称 | 回答的问题 | 详细信息 |
|---|---|---|
| 精准率 | 检索到的块中与请求相关的块所占百分比是多少? | 精度是实际与用户请求相关的检索文档的比例。 LLM 法官可用于评估每个检索的区块与用户请求的相关性。 |
| 召回率 | 在检索到的块中,提供的基本事实文档所占百分比是多少? | 召回率是指检索到的块中提供的基本事实文档所占的比例。 这是针对结果完整性的一个度量值。 |
精准率和召回率
下面是根据维基百科优秀文章改编的关于精准率和召回率的快速入门。
精准率公式
精度度量“在我检索的区块中,有多少 % 项实际上与用户的查询相关?” 计算精准率时不需要知道所有相关项。
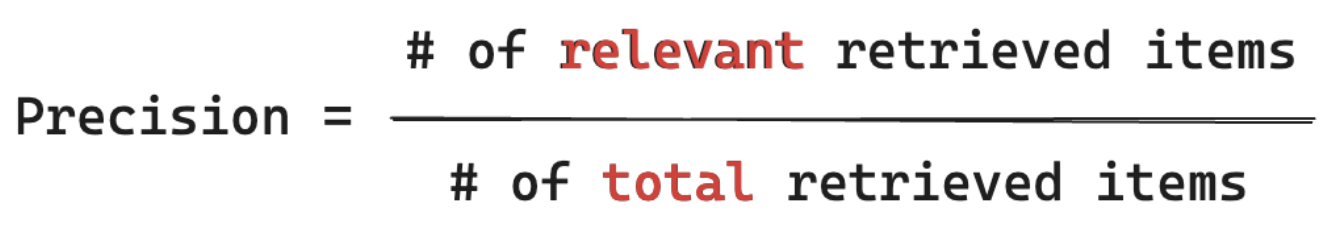
召回率公式
召回率:“在我知道与用户查询相关的所有文档中,我从哪些文档检索到了区块 %?” 计算召回率时要求你的基本事实包含所有相关项。 项可以是文档或文档块。
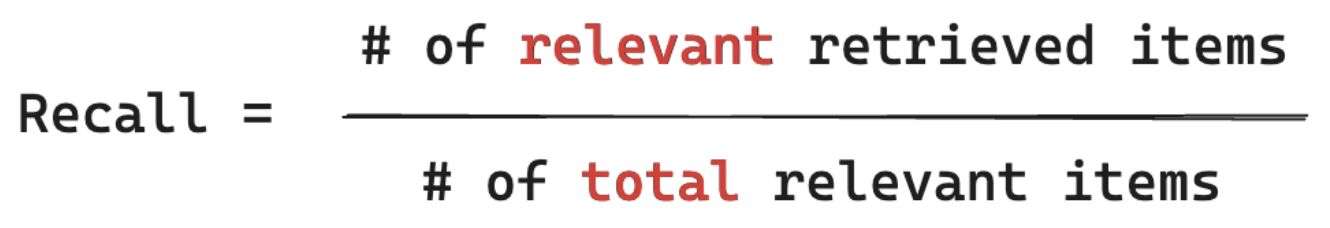
在下面的示例中,三个检索到的结果中有两个与用户的查询相关,因此精度为 0.66 (2/3)。 检索到的文档包括了总共四个相关文档中的两个,因此召回率为 0.5 (2/4)。