Azure Databricks 是一个统一的开放分析平台,用于大规模构建、部署、共享和维护企业级数据、分析和 AI 解决方案。 Databricks Data Intelligence Platform 与云帐户中的云存储和安全性集成,并为你管理和部署云基础结构。
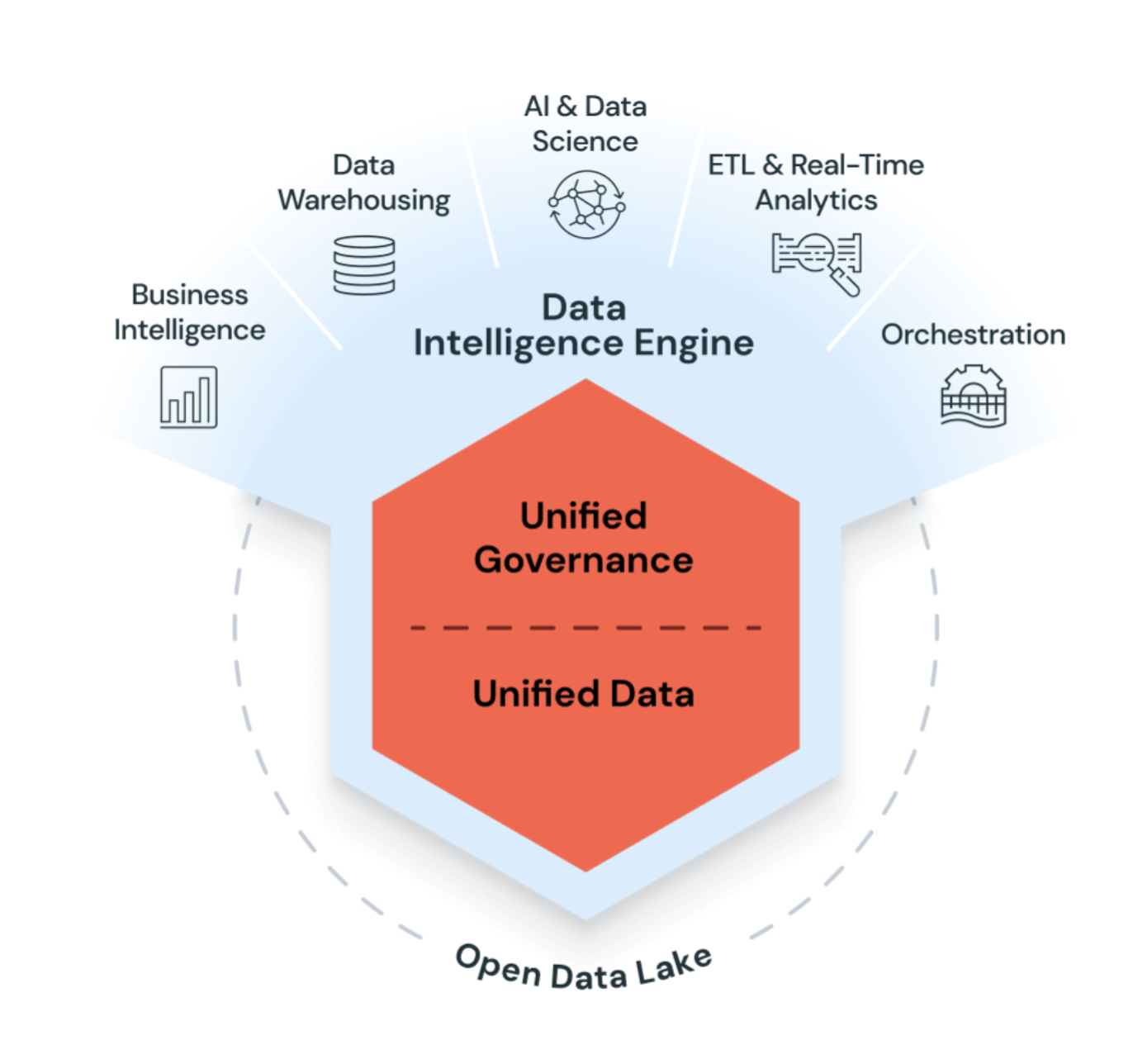
Azure Databricks 将生成式 AI 与数据湖配合使用,以了解数据的独特语义。 然后,它会自动优化性能并管理基础结构,以满足业务需求。
自然语言处理会学习业务的语言,因此可以通过用自己的语言提问来搜索和发现数据。 自然语言帮助可帮助你编写代码、排查错误,并在文档中查找答案。
托管式开源集成
Databricks 致力于开源社区,并管理与 Databricks Runtime 版本的开源集成更新。 以下技术是以前由 Databricks 员工创建的开源项目:
常见用例
以下用例重点介绍了客户使用 Azure Databricks 完成处理、存储和分析驱动关键业务功能和决策的数据至关重要的任务。
构建企业数据湖屋
Data Lakehouse 结合了企业数据仓库和数据湖,以加速、简化和统一企业数据解决方案。 数据工程师、数据科学家、分析师和生产系统都可以使用 Data Lakehouse 作为其单一事实来源,从而提供对一致数据的访问并减少生成、维护和同步许多分布式数据系统的复杂性。 请参阅什么是数据湖仓?。
ETL 和数据工程
无论是生成仪表板还是为人工智能应用程序提供支持,数据工程都通过确保数据可用、清理和存储在数据模型中,从而为以数据为中心的公司提供主干,以便高效发现和使用。 Azure Databricks 将 Apache Spark 的强大功能与 Delta 和自定义工具相结合,以提供无与伦比的 ETL 体验。 单击几下鼠标,使用 SQL、Python 和 Scala 编写 ETL 逻辑并协调计划的作业部署。
Lakeflow Spark 声明性管道 通过智能管理数据集之间的依赖关系以及自动部署和扩展生产基础设施来进一步简化 ETL,以确保及时准确地将数据传送符合您的规范。
Azure Databricks 提供自定义的数据引入工具,包括自动加载程序,它是一个高效且可缩放的工具,用于以增量方式和幂等方式将数据从云对象存储和数据湖加载到数据湖屋中。
机器学习、AI 和数据科学
Azure Databricks 机器学习通过一套针对数据科学家和 ML 工程师需求定制的工具(包括 MLflow 和用于机器学习的 Databricks Runtime)扩展了平台的核心功能。
大型语言模型和生成式 AI
Databricks 机器学习 Runtime 包括诸如 Hugging Face Transformers 之类的库,可以将预训练的现有模型或其他开源库集成到您的工作流中。 借助 Databricks MLflow 集成,可以轻松地将 MLflow 跟踪服务与转换器管道、模型和处理组件配合使用。 在 Databricks 工作流中集成 OpenAI 模型或解决方案,例如来自John Snow Labs的解决方案。
使用 Azure Databricks,将 LLM 针对您的数据和特定任务进行自定义。 借助开放源代码工具(如 Hugging Face 和 DeepSpeed)的支持,你可以有效地利用基础 LLM,开始使用自己的数据进行训练,以提高域和工作负载的准确性。
此外,Azure Databricks 还提供 AI 函数,SQL 数据分析师可以直接在其数据管道和工作流中使用这些函数访问大型语言模型(LLM),包括从 OpenAI 获取的模型。 请参阅 使用 AI 函数扩充数据。
数据仓库、分析和 BI
Azure Databricks 将用户友好的 UI、经济高效的计算资源以及无限可缩放、负担得起的存储相结合,提供了一个运行分析查询的强大平台。 管理员将可缩放的计算群集配置为 SQL 仓库,使最终用户能够执行查询,而无需担心在云中工作的任何复杂性。 SQL 用户可以使用 SQL 查询编辑器在湖屋中针对数据运行查询,或在笔记本中运行查询。 笔记本除了 SQL 之外,还支持 Python、R 和 Scala,并允许用户在仪表板中嵌入相同的可视化效果,以及用 Markdown 编写的链接、图像和评论。
数据治理和安全数据共享
Unity Catalog 为数据湖屋提供统一的数据治理模型。 云管理员为 Unity Catalog 配置和集成粗略的访问控制权限,然后 Azure Databricks 管理员可以管理团队和个人的权限。 通过用户友好的 UI 或 SQL 语法,与访问控制列表 (ACL) 相结合对特权进行管理,使数据库管理员无需在云原生标识访问管理 (IAM) 和网络上进行缩放就可以更轻松地保护对数据的访问。
Unity Catalog 使在云中运行安全分析变得简单,并提供了一个责任划分,这个划分有助于减少平台管理员和最终用户所必需的再培训或技能提升。 请参阅什么是 Unity Catalog?。
Lakehouse(湖仓)使组织内的数据共享变得像授予对表或视图的查询访问权限一样简单。 为了可以在安全环境之外共享,Unity Catalog 提供了增量共享的托管版本。
DevOps、CI/CD 和任务编排
ETL 管道、ML 模型和分析仪表板的开发生命周期都呈现出各自的独特挑战。 Azure Databricks 允许所有用户利用单个数据源,这样可以减少重复工作和不同步报告。 通过另外为版本控制、自动化、计划、部署代码和生产资源提供一套通用工具,你可以简化监视、编排和操作的开销。
工作可以调度 Azure Databricks 笔记本、SQL 查询和任意其他代码。 声明式自动化包 允许通过编程方式来定义、部署和运行 Databricks 资源,比如作业和流水线。 Git 文件夹可用于将 Azure Databricks 项目与许多流行的 git 提供程序同步。
有关 CI/CD 最佳做法和建议,请参阅 Databricks 上的最佳做法和建议的 CI/CD 工作流。 有关面向开发人员的工具的完整概述,请参阅 Databricks 上的开发。
实时分析和流式分析
Azure Databricks 利用 Apache Spark 结构化流式处理来处理流数据和增量数据更改。 结构化流式处理与 Delta Lake 紧密集成,这些技术为 Lakeflow Spark 声明性管道和自动加载程序提供了基础。 请参阅结构化流式处理概念。
联机事务处理
Lakebase 是一个与 Databricks Data Intelligence Platform 完全集成的联机事务处理(OLTP)数据库。 使用此完全托管的 Postgres 数据库,可以创建和管理存储在 Azure Databricks 托管存储中的 OLTP 数据库。 请参阅 Lakebase Postgres。