重要
Lakebase Autoscaling 是 Lakebase 的最新版本更新,具有自动缩放计算、缩放到零、分支和即时还原功能。 有关支持的区域,请参阅 区域可用性。 如果你是 Lakebase 预配的用户,请参阅 Lakebase 预配。
Lakebase 数据 API 是一个与 PostgREST 兼容的 RESTful 接口,可用于使用标准 HTTP 方法直接与 Lakebase Postgres 数据库交互。 它提供派生自数据库架构的 API 终结点,允许对数据执行安全 CRUD(创建、读取、更新、删除)作,而无需自定义后端开发。
概述
数据 API 会根据数据库架构自动生成 RESTful 终结点。 数据库中的每一个表都可以通过 HTTP 请求进行访问,使你能够:
- 使用具有灵活筛选、排序和分页的 HTTP 请求GET
- 使用 HTTP POST 请求插入记录
- 使用 HTTP PATCH 或 PUT 请求更新记录
- 使用 HTTP DELETE 请求删除记录
- 使用 HTTP POST 请求以 RPC 身份执行函数
此方法无需编写和维护自定义 API 代码,使你能够专注于应用程序逻辑和数据库架构。
PostgREST 兼容性
Lakebase 数据 API 与 PostgREST 规范兼容。 您可以:
- 使用现有的 PostgREST 客户端库和工具
- 遵循 PostgREST 约定进行筛选、排序和分页
- 借鉴 PostgREST 社区的文档和示例
注释
Lakebase 数据 API 是由 Azure Databricks 实现的,旨在与 PostgREST 规范兼容。 由于数据 API 是独立的实现,因此不包括一些不适用于 Lakebase 环境的 PostgREST 功能。 有关功能兼容性的详细信息,请参阅 功能兼容性参考。
有关 API 功能、查询参数和功能的综合详细信息,请参阅 PostgREST API 参考。
用例
Lakebase 数据 API 非常适合:
- Web 应用程序:生成通过 HTTP 请求直接与数据库交互的前端
- 微服务:创建轻量级服务,通过 REST API 访问数据库资源
- 无服务器体系结构:与无服务器函数和边缘计算平台集成
- 移动应用程序:通过 RESTful 接口为移动应用提供直接数据库访问权限
- 第三方集成:使外部系统能够安全地读取和写入数据
配置数据 API
本部分将指导你设置数据 API,从创建所需的角色到发出第一个 API 请求。
先决条件
数据 API 需要 Lakebase Postgres 自动缩放数据库项目。 如果没有,请参阅 数据库项目入门。
小窍门
如果需要示例表来测试数据 API,请在启用数据 API 之前创建它们。 有关完整的示例架构,请参阅 示例架构 。
启用数据 API
数据 API 允许所有数据库通过名为 authenticator 的 Postgres 角色进行访问,该角色不需要任何权限,只需登录。 通过 Lakebase 应用启用数据 API 时,会自动创建此角色和必要的基础结构。
要启用数据 API,请执行以下操作:
- 导航到项目中的 数据 API 页面。
- 单击“ 启用数据 API”。
这会自动执行所有设置步骤,包括创建 authenticator 角色、配置 pgrst 架构以及通过 API 公开 public 架构。
注释
如果您需要暴露额外的架构(超过public),可以在高级数据 API 设置中修改暴露的架构。
启用数据 API 后
启用数据 API 后,Lakebase 应用会显示包含两个选项卡 的数据 API 页: API 和 设置。
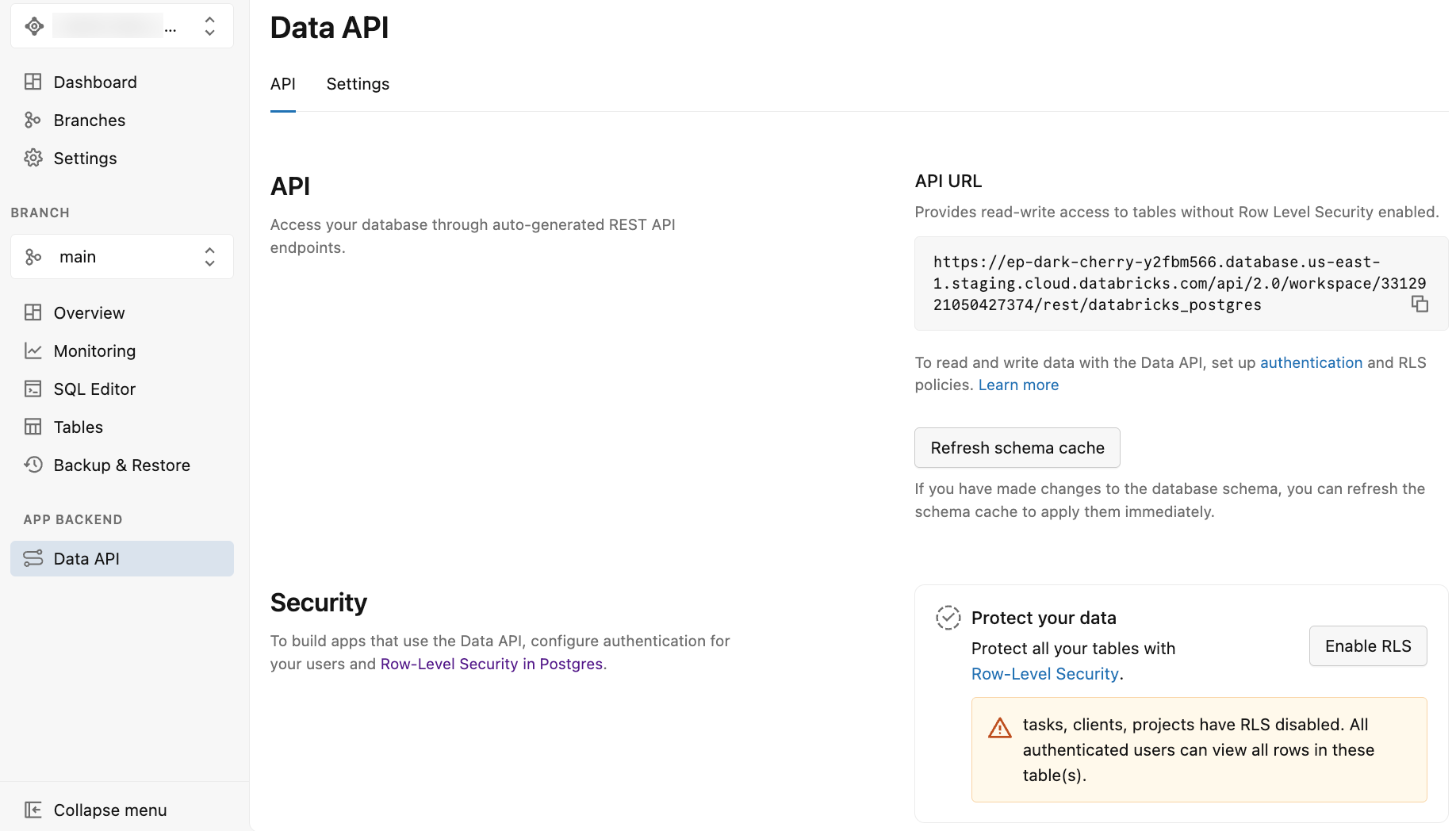
API 选项卡提供:
-
API URL:用于应用程序代码和 API 请求的 REST 终结点 URL。 显示的 URL 不包括架构,因此在发出 API 请求时,必须将架构名称(例如)
/public追加到 URL。 - 刷新架构缓存:更改数据库架构后刷新 API 架构缓存的按钮。 请参阅 刷新架构缓存。
- 保护数据:为表启用 Postgres 行级别安全性(RLS)的选项。 请参阅 “启用行级别安全性”。
“ 设置” 选项卡提供配置 API 行为的选项,例如公开的架构、最大行数、CORS 设置等。 请参阅 高级数据 API 设置。
示例架构(可选)
本文档中的示例使用以下架构。 可以创建自己的表,也可以使用此示例架构进行测试。 使用 Lakebase SQL 编辑器 或任何 SQL 客户端运行这些 SQL 语句:
-- Create clients table
CREATE TABLE clients (
id SERIAL PRIMARY KEY,
name TEXT NOT NULL,
email TEXT UNIQUE NOT NULL,
company TEXT,
phone TEXT,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- Create projects table with foreign key to clients
CREATE TABLE projects (
id SERIAL PRIMARY KEY,
name TEXT NOT NULL,
description TEXT,
client_id INTEGER NOT NULL REFERENCES clients(id) ON DELETE CASCADE,
status TEXT DEFAULT 'active',
start_date DATE,
end_date DATE,
budget DECIMAL(10,2),
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- Create tasks table with foreign key to projects
CREATE TABLE tasks (
id SERIAL PRIMARY KEY,
title TEXT NOT NULL,
description TEXT,
project_id INTEGER NOT NULL REFERENCES projects(id) ON DELETE CASCADE,
status TEXT DEFAULT 'pending',
priority TEXT DEFAULT 'medium',
assigned_to TEXT,
due_date DATE,
estimated_hours DECIMAL(5,2),
actual_hours DECIMAL(5,2),
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- Insert sample data
INSERT INTO clients (name, email, company, phone) VALUES
('Acme Corp', 'contact@acme.com', 'Acme Corporation', '+1-555-0101'),
('TechStart Inc', 'hello@techstart.com', 'TechStart Inc', '+1-555-0102'),
('Global Solutions', 'info@globalsolutions.com', 'Global Solutions Ltd', '+1-555-0103');
INSERT INTO projects (name, description, client_id, status, start_date, end_date, budget) VALUES
('Website Redesign', 'Complete overhaul of company website with modern design', 1, 'active', '2024-01-15', '2024-06-30', 25000.00),
('Mobile App Development', 'iOS and Android app for customer management', 1, 'planning', '2024-07-01', '2024-12-31', 50000.00),
('Database Migration', 'Migrate legacy system to cloud database', 2, 'active', '2024-02-01', '2024-05-31', 15000.00),
('API Integration', 'Integrate third-party services with existing platform', 3, 'completed', '2023-11-01', '2024-01-31', 20000.00);
INSERT INTO tasks (title, description, project_id, status, priority, assigned_to, due_date, estimated_hours, actual_hours) VALUES
('Design Homepage', 'Create wireframes and mockups for homepage', 1, 'in_progress', 'high', 'Sarah Johnson', '2024-03-15', 16.00, 8.00),
('Setup Development Environment', 'Configure local development setup', 1, 'completed', 'medium', 'Mike Chen', '2024-02-01', 4.00, 3.50),
('Database Schema Design', 'Design new database structure', 3, 'completed', 'high', 'Alex Rodriguez', '2024-02-15', 20.00, 18.00),
('API Authentication', 'Implement OAuth2 authentication flow', 4, 'completed', 'high', 'Lisa Wang', '2024-01-15', 12.00, 10.50),
('User Testing', 'Conduct usability testing with target users', 1, 'pending', 'medium', 'Sarah Johnson', '2024-04-01', 8.00, NULL),
('Performance Optimization', 'Optimize database queries and caching', 3, 'in_progress', 'medium', 'Alex Rodriguez', '2024-04-30', 24.00, 12.00);
配置用户权限
必须使用 Azure Databricks OAuth 持有者令牌(通过 Authorization 标头发送)对所有数据 API 请求进行身份验证。 数据 API 限制对经过身份验证的Azure Databricks标识的访问,Postgres 控制基础权限。
该 authenticator 角色在处理 API 请求时模拟请求用户的标识。 为此,访问数据 API 的每个 Azure Databricks 标识必须在数据库中具有相应的 Postgres 角色。 如果需要先将用户添加到Azure Databricks帐户,请参阅 将用户添加到帐户。
添加 Postgres 角色
为每个需要数据 API 访问权限的 Azure Databricks 标识创建 Postgres 数据库角色:
UI
- 在 “角色和数据库>添加角色>OAuth ”选项卡中,选择要授予数据库访问权限的用户、服务主体或组。
- 创建角色后,继续 向用户授予权限。
SQL
创建
databricks_auth扩展。 每个 Postgres 数据库必须有自己的扩展。CREATE EXTENSION IF NOT EXISTS databricks_auth;使用
databricks_create_role为Azure Databricks标识添加 Postgres 角色:对于用户:
SELECT databricks_create_role('user@databricks.com', 'USER');对于服务主体,请使用应用程序 ID (UUID)作为标识名称。 在 Settings > Identity 下的 Azure Databricks 工作区中找到它,并访问 > 服务主体:
SELECT databricks_create_role('8c01cfb1-62c9-4a09-88a8-e195f4b01b08', 'SERVICE_PRINCIPAL');
Python SDK
设置为identity_typeUSER或 SERVICE_PRINCIPALGROUP。 请分别将 postgres_role 设置为标识所对应的电子邮件地址、应用程序 ID(UUID)或组显示名称。 此值将成为语句中使用的 GRANT Postgres 角色名称。
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.postgres import Role, RoleIdentityType, RoleRoleSpec
w = WorkspaceClient()
operation = w.postgres.create_role(
parent="projects/my-project/branches/production",
role=Role(
spec=RoleRoleSpec(
identity_type=RoleIdentityType.USER,
postgres_role="user@example.com"
)
)
)
role = operation.wait()
curl
设置为identity_typeUSER或 SERVICE_PRINCIPALGROUP。 请分别将 postgres_role 设置为标识所对应的电子邮件地址、应用程序 ID(UUID)或组显示名称。
curl -X POST "$WORKSPACE/api/2.0/postgres/projects/my-project/branches/production/roles" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" \
-H "Content-Type: application/json" \
-d '{
"spec": {
"identity_type": "USER",
"postgres_role": "user@example.com"
}
}' | jq
重要
请勿使用数据库所有者帐户(即创建 Lakebase 项目的 Azure Databricks 身份)访问数据 API。 该 authenticator 角色需要能够承担其职责,并且无法为权限已被提升的帐户授予该权限。
如果尝试授予数据库所有者角色 authenticator,将收到此错误:
ERROR: permission denied to grant role "db_owner_user@databricks.com"
DETAIL: Only roles with the ADMIN option on role "db_owner_user@databricks.com" may grant this role.
向用户授予权限
为Azure Databricks标识创建了相应的 Postgres 角色后,需要向这些 Postgres 角色授予权限。 这些权限控制每个用户可以通过 API 请求与哪些数据库对象(架构、表、序列、函数)进行交互。
使用标准 SQL GRANT 语句授予权限。 此示例使用 public 架构;如果要公开其他架构,请替换为 public 架构名称:
-- Allow authenticator to assume the identity of the user
GRANT "user@databricks.com" TO authenticator;
-- Allow user@databricks.com to access everything in public schema
GRANT USAGE ON SCHEMA public TO "user@databricks.com";
GRANT SELECT, UPDATE, INSERT, DELETE ON ALL TABLES IN SCHEMA public TO "user@databricks.com";
GRANT USAGE ON ALL SEQUENCES IN SCHEMA public TO "user@databricks.com";
GRANT EXECUTE ON ALL FUNCTIONS IN SCHEMA public TO "user@databricks.com";
此示例授予对 public 标识架构 user@databricks.com 的完全访问权限。 将此替换为实际Azure Databricks标识,并根据要求调整权限。 对于服务主体,在语句中使用 GRANT 应用程序 ID(UUID)作为 Postgres 角色名称,而不是电子邮件地址。
重要
实现行级别安全性:上述权限授予表级访问权限,但大多数 API 用例都需要行级限制。 例如,在多租户应用程序中,用户应只看到自己的数据或组织的数据。 使用 PostgreSQL 行级别安全性 (RLS) 策略在数据库级别强制实施精细访问控制。 请参阅 “实现行级别安全性”。
身份验证
若要访问数据 API,必须在 HTTP 请求的 Authorization 标头中提供Azure Databricks OAuth 令牌。 经过身份验证的 Azure Databricks 身份必须具有在前面步骤中创建的相应 Postgres 角色,该角色定义了其在数据库中的权限。
获取 OAuth 令牌
以在前面的步骤中为其创建了 Postgres 角色的 Azure Databricks 标识的用户身份连接到作业空间,并获取 OAuth 令牌。 有关说明,请参阅 “身份验证 ”。
发出请求
借助 OAuth 令牌和 API URL(可从 Lakebase App 中的 API 选项卡获取),可以使用 curl 或任何 HTTP 客户端发出 API 请求。 请记住,将架构名称(例如) /public追加到 API URL。 以下示例假定你导出了DBX_OAUTH_TOKEN和REST_ENDPOINT环境变量。
下面是使用预期输出的示例调用(使用示例客户端/项目/任务架构):
curl -H "Authorization: Bearer $DBX_OAUTH_TOKEN" \
"$REST_ENDPOINT/public/clients?select=id,name,projects(id,name)&id=gte.2"
示例响应:
[
{ "id": 2, "name": "TechStart Inc", "projects": [{ "id": 3, "name": "Database Migration" }] },
{ "id": 3, "name": "Global Solutions", "projects": [{ "id": 4, "name": "API Integration" }] }
]
关于API操作的更多示例和详细信息,请参阅API参考部分。 有关查询参数和 API 功能的综合详细信息,请参阅 PostgREST API 参考。 有关特定于 Lakebase 的兼容性信息,请参阅 PostgREST 兼容性。
在广泛使用 API 之前,请配置 行级安全性 以保护数据。
管理数据 API
启用数据 API 后,可以通过 Lakebase 应用管理架构更改和安全设置。
刷新架构缓存
对数据库架构进行更改(添加表、列或其他架构对象)时,需要刷新架构缓存。 这会使更改通过数据 API 立即可用。
刷新架构缓存:
- 在项目的应用后端部分导航到数据 API。
- 单击“ 刷新架构缓存”。
数据 API 现在反映最新的架构更改。
启用行级别安全性
Lakebase 应用提供了为数据库中的表启用行级安全性(RLS)的快速方法。 当架构中存在表时, API 选项卡会显示一个“ 保护数据 ”部分,其中显示了:
- 启用了 RLS 的表
- 禁用了 RLS 的表(带有警告)
- “启用 RLS”按钮,为所有表启用 RLS
重要
通过 Lakebase 应用启用 RLS 可启用表的行级安全性。 启用 RLS 后,默认情况下,用户无法访问所有行(表所有者、具有 BYPASSRLS 属性的角色和超级用户除外),尽管 Lakebase 不支持超级用户。 必须创建 RLS 策略,才能根据安全要求授予对特定行的访问权限。 有关创建策略的信息,请参阅 行级别安全性 。
若要为你的表启用 RLS,请执行以下操作:
- 在项目的应用后端部分导航到数据 API。
- 在“ 保护数据 ”部分中,查看未启用 RLS 的表。
- 单击“ 启用 RLS ”为所有表启用行级安全性。
还可以使用 SQL 为单个表启用 RLS。 有关详细信息,请参阅 行级别安全性 。
高级数据 API 设置
Lakebase App 中 API 选项卡上的“高级设置”部分控制数据 API 终结点的安全、性能和行为。
公开的架构
默认:public
定义哪些 PostgreSQL 架构公开为 REST API 终结点。 默认情况下,仅架构 public 可访问。 如果使用其他架构(例如, api), v1请从下拉列表中选择它们以添加它们。
注释
权限适用: 在此处添加架构会公开终结点,但 API 使用的数据库角色仍必须具有 USAGE 对架构和 SELECT 表的权限。
最大行数
默认: 空
对单个 API 响应中要返回的行数强制实施硬限制。 这可以防止大型查询意外性能下降。 客户端应使用分页限制来检索此阈值中的数据。 这也可以防止大型数据传输产生意外的流出成本。
CORS 允许的来源
默认: 空 (允许所有源)
控制哪些 Web 域可以使用浏览器从 API 提取数据。
-
空: 允许
*(任何域)。 适用于开发。 -
生产: 列出您的特定域(例如
https://myapp.com),以防止未经授权的网站查询您的 API。
OpenAPI 规范
默认: 禁用
控制自动生成的 OpenAPI 3 架构在以下位置 /openapi.json是否可用。 此架构描述表、列和 REST 终结点。 启用后,可以使用它来:
- 生成 API 文档 (Swagger UI, Redoc)
- 生成类型化客户端库(TypeScript、Python、Go)
- 将 API 导入 Postman
- 与 API 网关和其他基于 OpenAPI 的工具集成
服务器计时标头
默认: 禁用
启用后,数据 API 在每个响应中包含头信息 Server-Timing。 这些标头显示了处理请求的不同部分的时间(例如,数据库执行时间和内部处理时间)。 可以使用此信息来调试速度缓慢的查询、测量性能以及排查应用程序中的延迟问题。
注释
更改任何高级设置后,单击“ 保存 ”以应用它们。
行级安全性
行级别安全性 (RLS) 策略通过限制用户可以在表中访问的行来提供精细的访问控制。
RLS 如何处理数据 API:当用户发出 API 请求时,该 authenticator 角色假定该用户的标识。 PostgreSQL 会自动强制执行为该用户角色定义的任何 RLS 策略,筛选他们可以访问的数据。 这发生在数据库级别,因此,即使应用程序代码尝试查询所有行,数据库也只返回允许用户查看的行。 这提供了深度防御安全性,无需在应用程序代码中筛选逻辑。
为什么 RLS 对于 API 至关重要:与控制连接上下文的直接数据库连接不同,HTTP API 通过单个终结点向多个用户公开数据库。 仅表级权限意味着,如果用户可以访问 clients 表,则他们可以访问 所有 客户端记录,除非实现筛选。 RLS 策略可确保每个用户仅看到其授权数据。
RLS 对于…… 至关重要:
- 多租户应用程序:在不同客户或组织之间隔离数据
- 用户拥有的数据:确保用户仅访问自己的记录
- 基于团队的访问:限制团队成员或特定组的可见性
- 符合性要求:在数据库级别强制实施数据访问限制
启用 RLS
可以通过 Lakebase 应用或使用 SQL 语句启用 RLS。 有关使用 Lakebase 应用的说明,请参阅 “启用行级别安全性”。
警告
如果表未启用 RLS,Lakebase App 中的 API 选项卡将显示一条警告,表明经过身份验证的用户可以查看这些表中的所有行。 数据 API 直接与 Postgres 架构交互,并且由于 API 可通过 Internet 访问,因此必须使用 PostgreSQL 行级别安全性在数据库级别强制实施安全性。
若要使用 SQL 启用 RLS,请运行以下命令:
ALTER TABLE clients ENABLE ROW LEVEL SECURITY;
创建 RLS 策略
在表上启用 RLS 后,必须创建定义访问规则的策略。 如果没有策略,用户无法访问任何行(默认情况下隐藏所有行)。
策略的工作原理:在表上启用 RLS 时,用户只能看到与至少一个策略匹配的行。 将筛选掉所有其他行。表所有者、具有 BYPASSRLS 属性的角色和超级用户可以绕过行安全系统(尽管 Lakebase 上不支持超级用户)。
注释
在 Lakebase 中, current_user 返回经过身份验证的用户的电子邮件地址(例如, user@databricks.com)。 在 RLS 策略中使用此策略来标识发出请求的用户。
基本策略语法:
CREATE POLICY policy_name ON table_name
[TO role_name]
USING (condition);
- policy_name:策略的描述性名称
- table_name:要向其应用策略的表
- TO role_name:可选。 指定此策略的角色。 省略此子句以将策略应用到所有角色。
- USING (条件):确定哪些行可见的条件
RLS 教程
以下教程使用本文档(客户端、项目、任务表)中的示例架构来演示如何实现行级别安全性。
方案:有多个用户应只看到其分配的客户端和相关项目。 限制访问,以便:
-
alice@databricks.com只能查看 ID 为 1 和 2 的客户端 -
bob@databricks.com只能查看 ID 为 2 和 3 的客户端
步骤 1:在客户端表上启用 RLS
ALTER TABLE clients ENABLE ROW LEVEL SECURITY;
步骤 2:为 Alice 创建策略
CREATE POLICY alice_clients ON clients
TO "alice@databricks.com"
USING (id IN (1, 2));
步骤 3:为 Bob 创建策略
CREATE POLICY bob_clients ON clients
TO "bob@databricks.com"
USING (id IN (2, 3));
步骤 4:测试策略
Alice 发出 API 请求时:
# Alice's token in the Authorization header
curl -H "Authorization: Bearer $ALICE_TOKEN" \
"$REST_ENDPOINT/public/clients?select=id,name"
响应(Alice 仅看到客户端 1 和 2):
[
{ "id": 1, "name": "Acme Corp" },
{ "id": 2, "name": "TechStart Inc" }
]
当 Bob 发出 API 请求时:
# Bob's token in the Authorization header
curl -H "Authorization: Bearer $BOB_TOKEN" \
"$REST_ENDPOINT/public/clients?select=id,name"
响应(Bob 仅看到客户端 2 和 3):
[
{ "id": 2, "name": "TechStart Inc" },
{ "id": 3, "name": "Global Solutions" }
]
常见 RLS 模式
这些模式涵盖数据 API 的典型安全要求:
用户所有权 - 将行限制为经过身份验证的用户:
CREATE POLICY user_owned_data ON tasks
USING (assigned_to = current_user);
租户隔离 - 将数据行限制在用户所属的组织内:
CREATE POLICY tenant_data ON clients
USING (tenant_id = (
SELECT tenant_id
FROM user_tenants
WHERE user_email = current_user
));
团队成员身份 - 将数据行限制在用户所属团队内:
CREATE POLICY team_projects ON projects
USING (client_id IN (
SELECT client_id
FROM team_clients
WHERE team_id IN (
SELECT team_id
FROM user_teams
WHERE user_email = current_user
)
));
基于角色的访问 - 根据角色成员身份限制行:
CREATE POLICY manager_access ON tasks
USING (
status = 'pending' OR
pg_has_role(current_user, 'managers', 'member')
);
特定角色的只读 - 针对不同操作的不同策略:
-- Allow all users to read their assigned tasks
CREATE POLICY read_assigned_tasks ON tasks
FOR SELECT
USING (assigned_to = current_user);
-- Only managers can update tasks
CREATE POLICY update_tasks ON tasks
FOR UPDATE
TO "managers"
USING (true);
其他资源
有关实现 RLS(包括策略类型、安全最佳做法和高级模式)的综合信息,请参阅 PostgreSQL 行安全策略文档。
有关权限的详细信息,请参阅 “管理权限”。
API 参考
本部分假定你已完成设置步骤、配置的权限并实现了行级别安全性。 以下部分提供了有关使用数据 API 的参考信息,包括常见作、高级功能、安全注意事项和兼容性详细信息。
基本操作
查询记录
使用 HTTP GET从表中检索记录:
curl -H "Authorization: Bearer $DBX_OAUTH_TOKEN" \
"$REST_ENDPOINT/public/clients"
示例响应:
[
{ "id": 1, "name": "Acme Corp", "email": "contact@acme.com", "company": "Acme Corporation", "phone": "+1-555-0101" },
{
"id": 2,
"name": "TechStart Inc",
"email": "hello@techstart.com",
"company": "TechStart Inc",
"phone": "+1-555-0102"
}
]
筛选结果
使用查询参数筛选结果。 此示例检索大于或等于 2 的 id 客户端:
curl -H "Authorization: Bearer $DBX_OAUTH_TOKEN" \
"$REST_ENDPOINT/public/clients?id=gte.2"
示例响应:
[
{ "id": 2, "name": "TechStart Inc", "email": "hello@techstart.com" },
{ "id": 3, "name": "Global Solutions", "email": "info@globalsolutions.com" }
]
选择特定列并进行表联接
使用 select 参数检索特定列并联接相关表:
curl -H "Authorization: Bearer $DBX_OAUTH_TOKEN" \
"$REST_ENDPOINT/public/clients?select=id,name,projects(id,name)&id=gte.2"
示例响应:
[
{ "id": 2, "name": "TechStart Inc", "projects": [{ "id": 3, "name": "Database Migration" }] },
{ "id": 3, "name": "Global Solutions", "projects": [{ "id": 4, "name": "API Integration" }] }
]
插入记录
使用 HTTP POST 创建新记录:
curl -X POST \
-H "Authorization: Bearer $DBX_OAUTH_TOKEN" \
-H "Content-Type: application/json" \
-d '{
"name": "New Client",
"email": "newclient@example.com",
"company": "New Company Inc",
"phone": "+1-555-0104"
}' \
"$REST_ENDPOINT/public/clients"
更新记录
使用 HTTP PATCH 更新现有记录:
curl -X PATCH \
-H "Authorization: Bearer $DBX_OAUTH_TOKEN" \
-H "Content-Type: application/json" \
-d '{"phone": "+1-555-0199"}' \
"$REST_ENDPOINT/public/clients?id=eq.1"
删除记录
使用 HTTP DELETE 删除记录:
curl -X DELETE \
-H "Authorization: Bearer $DBX_OAUTH_TOKEN" \
"$REST_ENDPOINT/public/clients?id=eq.5"
高级功能
分页
控制使用 limit 和 offset 参数返回的记录数:
curl -H "Authorization: Bearer $DBX_OAUTH_TOKEN" \
"$REST_ENDPOINT/public/tasks?limit=10&offset=0"
排序
使用参数 order 对结果进行排序:
curl -H "Authorization: Bearer $DBX_OAUTH_TOKEN" \
"$REST_ENDPOINT/public/tasks?order=due_date.desc"
复杂筛选
合并多个筛选器条件:
curl -H "Authorization: Bearer $DBX_OAUTH_TOKEN" \
"$REST_ENDPOINT/public/tasks?status=eq.in_progress&priority=eq.high"
常见筛选器运算符:
-
eq-等于 -
gte- 大于或等于 -
lte- 小于或等于 -
neq- 不等于 -
like- 模式匹配 -
in- 匹配列表中的任何值
有关支持的查询参数和 API 功能的详细信息,请参阅 PostgREST API 参考。 有关特定于 Lakebase 的兼容性信息,请参阅 PostgREST 兼容性。
功能兼容性参考
Lakebase 数据 API 与 PostgREST 规范完全兼容,包括资源嵌入(外键和计算关系、内部/左联接提示)、响应格式(JSON、CSV、GeoJSON、自定义媒体类型)、筛选、分页、计数模式(、、)、请求首选项(exactplanned、estimatedhandlingtimezone、tx、查询计划公开和 RPC 功能)。
以下 PostgREST 功能在 Lakebase 环境中不适用或不可用:
身份验证
| 功能 / 特点 | 状态 | 详细信息 |
|---|---|---|
| JWT 配置 | 不適用 | Lakebase 数据 API 使用 Azure Databricks OAuth 令牌而不是 JWT 身份验证。 JWT 特定的配置选项(自定义机密、RS256 密钥、受众验证)不可用。 |
高级配置
| 功能 / 特点 | 状态 | 详细信息 |
|---|---|---|
| 应用程序设置(GUC) | 不支持 | 不支持通过 PostgreSQL GUC 将自定义配置值传递给数据库函数。 |
| 请求前函数 | 不支持 |
db-pre-request 不支持允许在每次请求之前指定运行数据库函数的配置。 |
Observability
| 功能 / 特点 | 状态 | 详细信息 |
|---|---|---|
| 追踪标头传播 | 不適用 | Lakebase 实施了自己的可观测性功能,而不是采用 PostgREST 的 X-Request-Id 和自定义追踪标头传播。 |
有关 PostgREST 功能的详细信息,请参阅 PostgREST 文档。
安全注意事项
数据 API 在多个级别强制实施数据库的安全模型:
- 身份验证:所有请求都需要有效的 OAuth 令牌身份验证
- 基于角色的访问:数据库级权限控制哪些表和作业用户可以访问
- 行级别安全性:RLS 策略强制实施精细访问控制,限制用户可以查看或修改的特定行
- 用户上下文:API 假定经过身份验证的用户标识,确保数据库权限和策略正确应用
建议的安全做法
对于生产部署:
- 实现行级别安全性:使用 RLS 策略在行级别限制数据访问。 这对于多租户应用程序和用户拥有的数据尤其重要。 请参阅行级别安全性。
-
授予最小权限:仅授予用户在特定表上所需的权限,
SELECTINSERTUPDATEDELETE而不是授予广泛访问权限。 - 为每个应用程序使用单独的角色:为不同的应用程序或服务创建专用角色,而不是共享单个角色。
- 定期审核访问权限:定期查看授予的权限和 RLS 策略,以确保它们符合安全要求。
有关管理角色和权限的信息,请参阅: