你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
本文介绍如何跟踪和调试 HDInsight 群集上运行的 Apache Spark 作业。 使用 Apache Hadoop YARN UI、Spark UI 和 Spark History Server 进行调试。 使用 Spark 群集提供的笔记本( 机器学习:使用 MLLib 对食品检查数据进行预测分析)启动 Spark 作业。 执行以下步骤来跟踪使用任何其他方法(例如 spark-submit)提交的应用程序。
如果没有 Azure 订阅,请在开始之前创建一个免费帐户。
先决条件
HDInsight 上的 Apache Spark 群集。 有关说明,请参阅 在 Azure HDInsight 中创建 Apache Spark 群集。
你应该已经开始运行笔记本, 机器学习:使用 MLLib 对食品检查数据的预测分析。 有关如何运行此笔记本的说明,请点击链接。
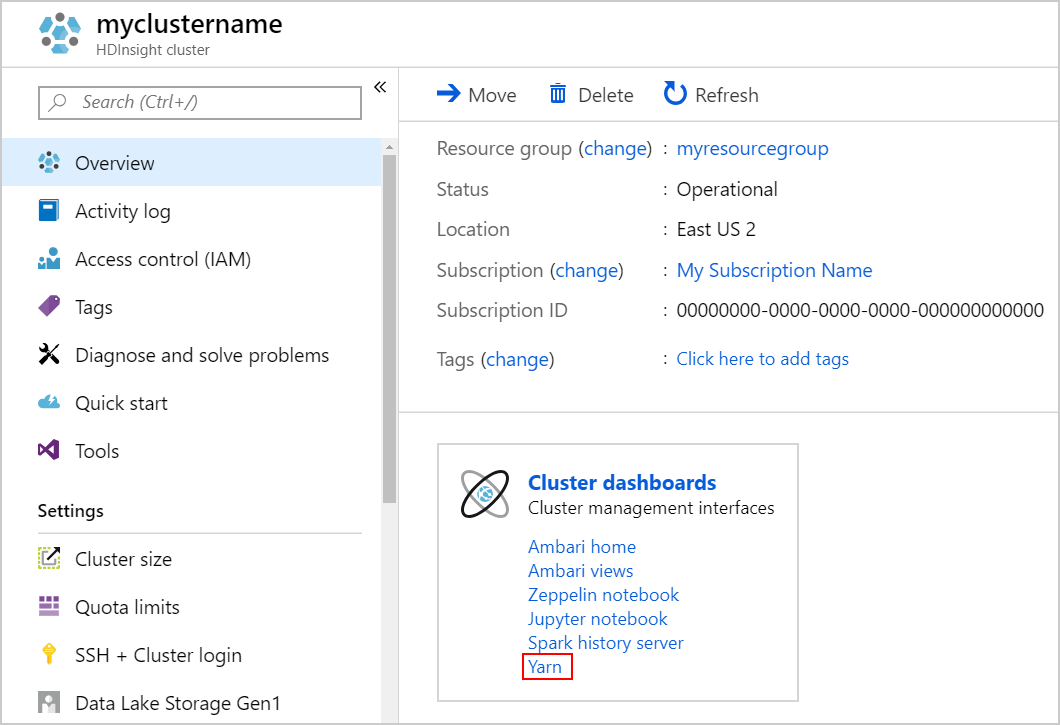
在 YARN UI 中跟踪应用程序
启动 YARN UI。 在群集仪表板下选择 Yarn。
小窍门
或者,也可以从 Ambari UI 启动 YARN UI。 若要启动 Ambari UI,请选择群集仪表板下的 Ambari 主页。 在 Ambari UI 中,导航到 YARN>快速链接> 活动资源管理器 >资源管理器 UI。
由于已使用 Jupyter Notebook 启动 Spark 作业,因此应用程序具有 名称 remotesparkmagics (从笔记本启动的所有应用程序的名称)。 根据应用程序名称选择应用程序 ID 以获取有关作业的详细信息。 此操作将启动应用程序视图。
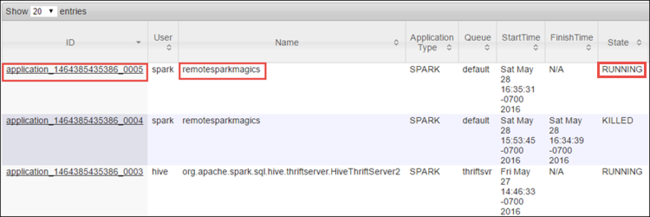
对于从 Jupyter Notebook 启动的此类应用程序,在退出笔记本之前,状态始终 为 RUNNING 。
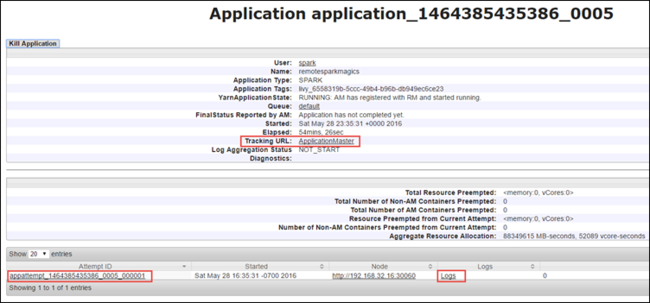
在应用程序视图中,可以进一步向下钻取,找出与应用程序和日志(stdout/stderr)关联的容器。 还可以通过单击与 跟踪 URL 对应的链接来启动 Spark UI,如下所示。
在 Spark UI 中跟踪应用程序
在 Spark 用户界面中,用户可以深入查看由您此前启动的应用程序生成的 Spark 作业。
若要启动 Spark UI,请在应用程序视图中针对 跟踪 URL 选择链接,如上面的屏幕截图所示。 可以看到 Jupyter Notebook 中运行的应用程序启动的所有 Spark 作业。
选择 “执行程序 ”选项卡以查看每个执行程序的处理和存储信息。 还可以通过选择 “线程转储 ”链接来检索调用堆栈。
选择“ 阶段 ”选项卡以查看与应用程序关联的阶段。
每个阶段可以有多个任务,你可以查看执行统计信息,如下所示。
在阶段详细信息页中,可以启动 DAG 可视化效果。 展开页面顶部的 DAG 可视化链接 ,如下所示。
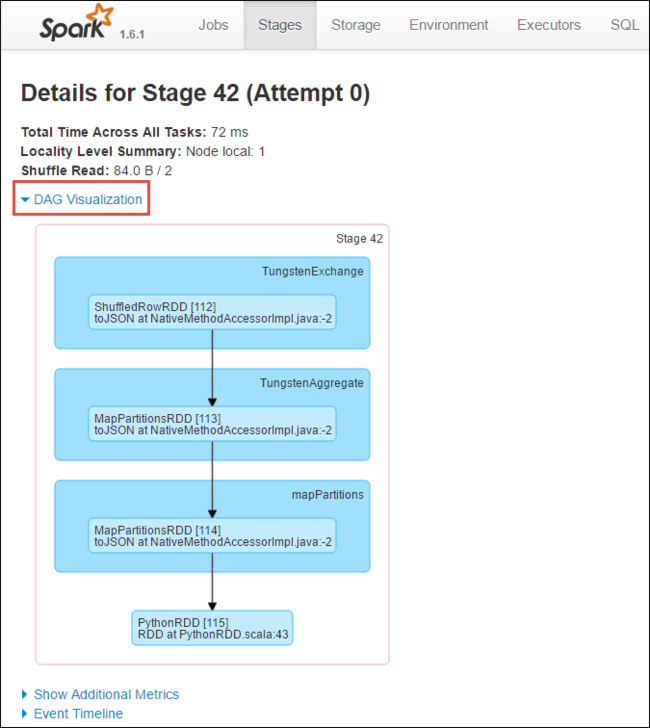
DAG 或 Direct Aclyic Graph 表示应用程序中的不同阶段。 图表中的每个蓝色框表示从应用程序调用的 Spark 操作。
在阶段详细信息页中,还可以启动应用程序时间线视图。 在如下所示页面顶部,展开 事件时间线 链接。
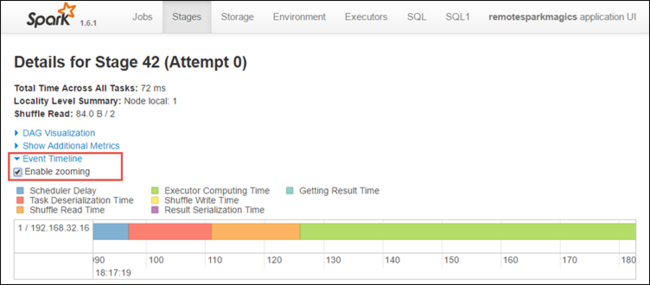
此图像以时间线的形式显示 Spark 事件。 时间线视图在三个级别、跨作业、作业和阶段内可用。 上图显示了给定阶段的时间线视图。
小窍门
如果选中“ 启用缩放 ”复选框,则可以在时间线视图中向左和向右滚动。
Spark UI 中的其他选项卡也提供有关 Spark 实例的有用信息。
- 存储选项卡 - 如果应用程序创建了 RDD,可以在“存储”选项卡中找到信息。
- “环境”选项卡 - 此选项卡提供有关 Spark 实例的有用信息,例如:
- Scala 版本
- 与群集关联的事件日志目录
- 应用程序的执行程序核心数
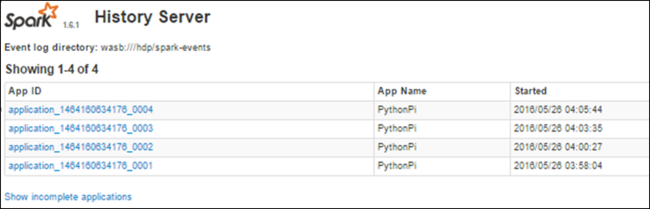
使用 Spark History Server 查找有关已完成作业的信息
作业完成后,有关该作业的信息将保留在 Spark History Server 中。
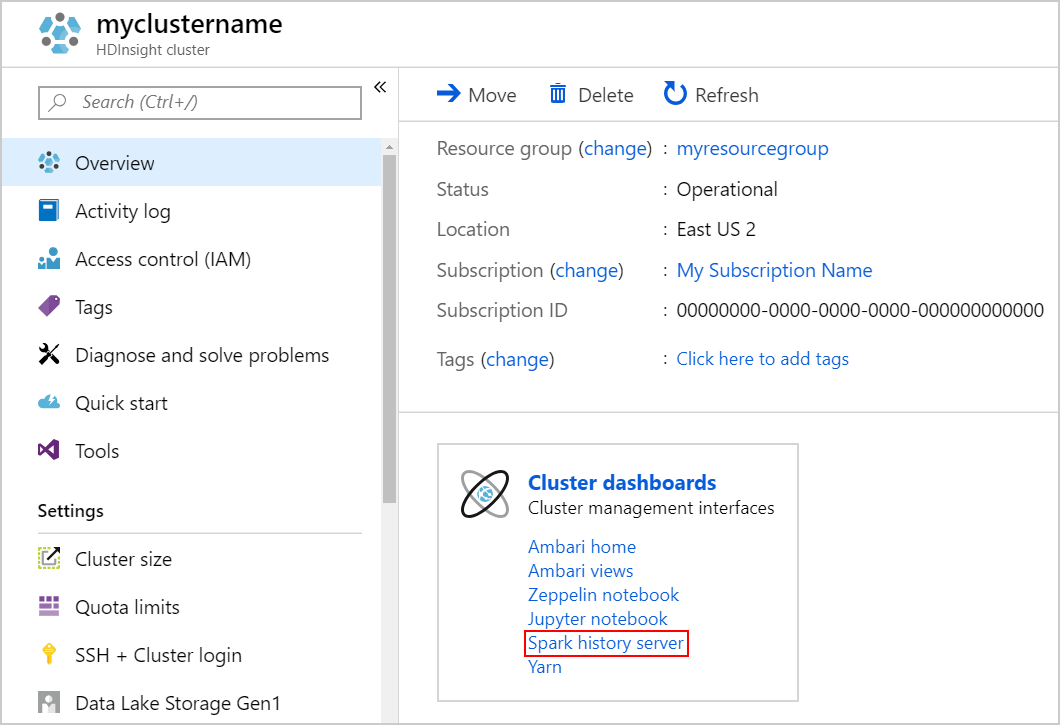
若要启动 Spark History Server,请在“概述”页中选择群集仪表板下的 Spark 历史记录服务器。
小窍门
或者,也可以从 Ambari UI 启动 Spark History Server UI。 若要启动 Ambari UI,请在“概述界面”中,选择群集仪表板下的Ambari 主页。 在 Ambari UI 中,导航到“Spark2”>“快速链接”>“Spark2 History Server UI”。
随后会看到已列出所有已完成的应用程序。 选择一个应用程序 ID 来深入查看应用程序以获取更多信息。