你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
本文介绍如何在横向扩展配置中部署高度可用的 SAP HANA 系统。 具体来说,该配置在 Azure Red Hat Enterprise Linux 虚拟机 (VM) 上使用 HANA 系统复制 (HSR) 和 Pacemaker。 所示体系结构中的共享文件系统是通过 NFS 装载的,由 Azure NetApp 文件或 Azure 文件存储上的 NFS 共享提供。
在示例配置和安装命令中,HANA 实例为 03,HANA 系统 ID 为 HN1。
先决条件
在继续阅读本文中的主题之前,一些读者会从查阅各种 SAP 说明和资源中受益:
- SAP 说明 1928533 包括:
- SAP 软件部署支持的 Azure VM 大小的列表。
- Azure VM 大小的重要容量信息。
- 支持的 SAP 软件、操作系统和数据库组合。
- Microsoft Azure 上 Windows 和 Linux 所需的 SAP 内核版本。
- SAP 说明 2015553:列出了在 Azure 中 SAP 支持的 SAP 软件部署的先决条件。
- SAP 说明 [2002167]:具有推荐的 RHEL 操作系统设置。
- SAP 说明 2009879:包含适用于 RHEL 的 SAP HANA 指南。
- SAP 说明 3108302 包含适用于 Red Hat Enterprise Linux 9.x 的 SAP HANA 指南。
- SAP 说明 2178632:包含有关在 Azure 中为 SAP 报告的所有监视指标的详细信息。
- SAP 说明 2191498:包含 Azure 中的 Linux 所需的 SAP 主机代理版本。
- SAP 说明 2243692:包含 Azure 中 Linux 上的 SAP 许可的相关信息。
- SAP 说明 1999351:包含适用于 SAP 的 Azure 增强型监视扩展的其他故障排除信息。
- SAP 说明 1900823:包含有关 SAP HANA 存储要求的信息。
- SAP Community Wiki:包含适用于 Linux 的所有必需 SAP 说明。
- 适用于 Linux 上的 SAP 的 Azure 虚拟机规划和实施。
- 适用于 Linux 上的 SAP 的 Azure 虚拟机部署。
- 适用于 Linux 上的 SAP 的 Azure 虚拟机 DBMS 部署。
- SAP HANA 网络要求。
- 通用 RHEL 文档:
- Azure 特定的 RHEL 文档:
- Install SAP HANA on Red Hat Enterprise Linux for Use in Microsoft Azure(在 Red Hat Enterprise Linux 上安装要在 Microsoft Azure 中使用的 SAP HANA)。
- 适用于 SAP HANA 横向扩展和系统复制的 Red Hat Enterprise Linux 解决方案。
- Azure NetApp 文件文档。
- 适用于 SAP HANA 的 Azure NetApp 文件上的 NFS v4.1 卷。
- Azure 文件文档
概述
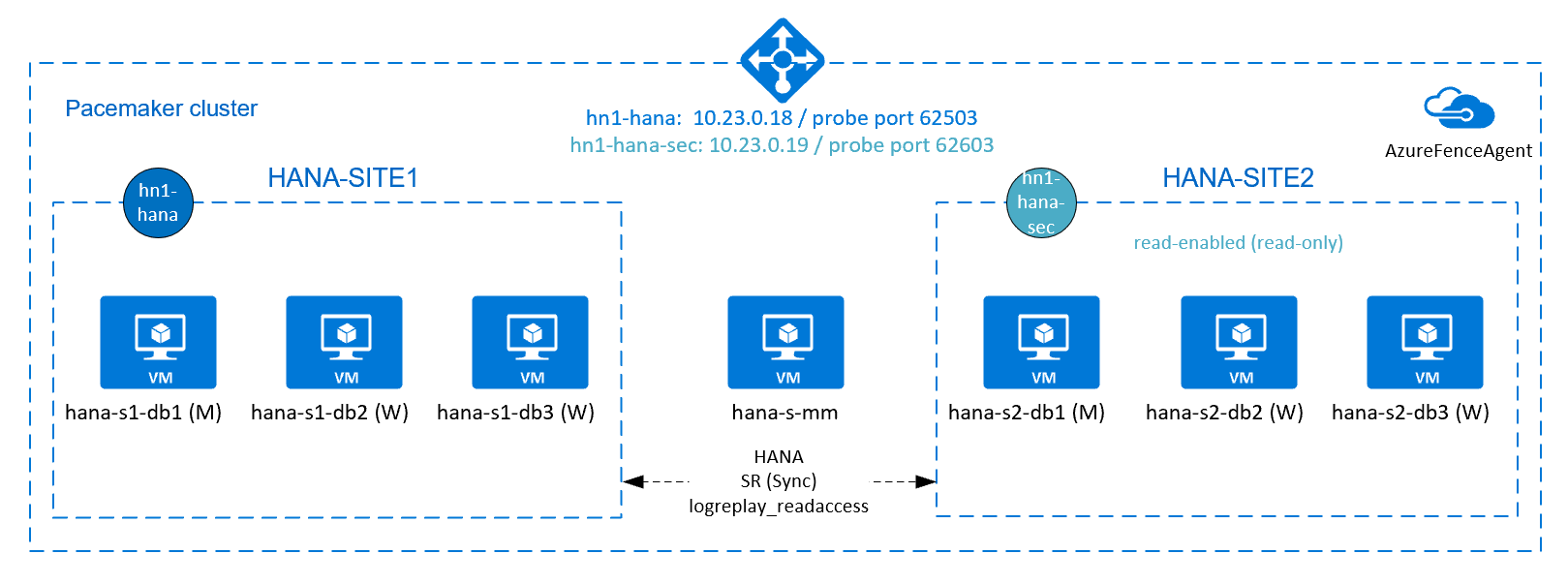
若要为 HANA 横向扩展安装实现 HANA 高可用性,可配置 HANA 系统复制,并通过 Pacemaker 群集保护解决方案,以允许自动故障转移。 当活动节点发生故障时,群集会将 HANA 资源故障转移到另一个站点。
在下图中,每个站点上有三个 HANA 节点,以及一个多数仲裁节点,以防止出现“裂脑”情况。 可以改编说明,以将更多 VM 作为 HANA DB 节点。
所示体系结构中的 HANA 共享文件系统 /hana/shared 可以由 Azure NetApp 文件或 Azure 文件存储上的 NFS 共享提供。 HANA 共享文件系统通过 NFS 装载在同一 HANA 系统复制站点中的每个 HANA 节点上。 文件系统 /hana/data 和 /hana/log 是本地文件系统,不在 HANA DB 节点之间共享。 SAP HANA 将以非共享模式安装。
有关建议的 SAP HANA 存储配置,请参阅 SAP HANA Azure VM 存储配置。
重要
如果在 Azure NetApp 文件上部署所有 HANA 文件系统,则对于性能是关键的生产系统,建议评估并考虑使用针对 SAP HANA 的 Azure NetApp 文件应用程序卷组。

上图中,按照 SAP HANA 网络建议,一个 Azure 虚拟网络中表示了三个子网:
- 对于客户端通信:
client10.23.0.0/24 - 对于内部 HANA 节点间通信:
inter10.23.1.128/26 - 对于 HANA 系统复制:
hsr10.23.1.192/26
由于 /hana/data 和 /hana/log 部署在本地磁盘上,因此不必部署单独的子网和单独的虚拟网卡来与存储进行通信。
如果使用 Azure NetApp 文件,则 /hana/shared 的 NFS 卷将部署在单独的子网中,委托给 Azure NetApp 文件:anf 10.23.1.0/26。
设置基础结构
在接下来的说明中,假设已创建资源组,即其中包含三个 Azure 网络子网的 Azure 虚拟网络:client、inter 和 hsr。
通过 Azure 门户部署 Linux 虚拟机
部署 Azure VM。 对于此配置,请部署七个虚拟机:
- 三个虚拟机充当 HANA 复制站点 1 的 HANA DB 节点:hana-s1-db1、hana-s1-db2 和 hana-s1-db3 。
- 三个虚拟机充当 HANA 复制站点 2 的 HANA DB 节点:hana-s2-db1、hana-s2-db2 和 hana-s2-db3 。
- 一个小型虚拟机充当多数仲裁节点:hana-s-mm。
作为 SAP DB HANA 节点部署的 VM 应由 SAP for HANA 认证,如 SAP HANA 硬件目录中发布的一样。 部署 HANA DB 节点时,请确保选择加速网络。
对于多数仲裁节点,可以部署一个小型 VM,因为此 VM 不会运行任何 SAP HANA 资源。 在群集配置中使用多数仲裁 VM 可在拆分式方案中实现奇数个群集节点。 在此示例中,多数仲裁 VM 只需要
client子网中的一个虚拟网络接口。部署
/hana/data和/hana/log的本地托管磁盘。/hana/data中介绍了/hana/log和 的最小建议存储配置。为
client虚拟网络子网中的每个 VM 部署主要网络接口。 通过 Azure 门户部署 VM 时,系统会自动生成网络接口名称。 在本文中,我们将自动生成的主要网络接口称为 hana-s1-db1-client、hana-s1-db2-client、hana-s1-db3-client 等等 。 这些网络接口附加到clientAzure 虚拟网络子网。重要
请确保你选择的操作系统已通过 SAP 针对你使用的特定 VM 类型上的 SAP HANA 进行的认证。 有关经 SAP HANA 认证的 VM 类型和这些类型的操作系统版本列表,请参阅经 SAP HANA 认证的 IaaS 平台。 深入了解列出的 VM 类型的详细信息,获取该类型的 SAP HANA 支持的操作系统版本的完整列表。
创建六个网络接口,
inter虚拟网络子网中的每个 HANA DB 虚拟机各一个(在此例中为“hana-s1-db1-inter”、“hana-s1-db2-inter、hana-s1-db3-inter”、“hana-s2-db1-inter”、“hana-s2-db2-inter”和“hana-s2-db3-inter”)。创建六个网络接口,
hsr虚拟网络子网中的每个 HANA DB 虚拟机各一个(在此例中为“hana-s1-db1-hsr”、“hana-s1-db2-hsr”、“hana-s1-db3-hsr”、“hana-s2-db1-hsr”、“hana-s2-db2-hsr”和“hana-s2-db3-hsr”)。将新创建的虚拟网络接口附加到相应的虚拟机:
- 转到 Azure 门户中的虚拟机。
- 在左侧窗格中,选择“虚拟机”。 按虚拟机名称筛选(例如,“hana-s1-db1”),然后选择虚拟机。
- 在“概述”窗格中,选择“停止”以解除分配虚拟机。
- 选择“网络”,然后附加网络接口。 在“附加网络接口”下拉列表中,选择已为 和
inter子网创建的网络接口。 - 选择“保存”。
- 对于剩余的虚拟机(在我们的示例中为 hana-s1-db2、hana-s1-db3、hana-s2-db1、hana-s2-db2 和 hana-s2-db3),请重复步骤 b 到 e
- 使虚拟机暂时处于停止状态。
通过执行以下步骤,为 和
inter子网的其他网络接口启用hsr:在 Azure 门户中打开 Azure Cloud Shell。
运行以下命令,为附加到
inter和hsr子网的其他网络接口启用加速网络。az network nic update --id /subscriptions/your subscription/resourceGroups/your resource group/providers/Microsoft.Network/networkInterfaces/hana-s1-db1-inter --accelerated-networking true az network nic update --id /subscriptions/your subscription/resourceGroups/your resource group/providers/Microsoft.Network/networkInterfaces/hana-s1-db2-inter --accelerated-networking true az network nic update --id /subscriptions/your subscription/resourceGroups/your resource group/providers/Microsoft.Network/networkInterfaces/hana-s1-db3-inter --accelerated-networking true az network nic update --id /subscriptions/your subscription/resourceGroups/your resource group/providers/Microsoft.Network/networkInterfaces/hana-s2-db1-inter --accelerated-networking true az network nic update --id /subscriptions/your subscription/resourceGroups/your resource group/providers/Microsoft.Network/networkInterfaces/hana-s2-db2-inter --accelerated-networking true az network nic update --id /subscriptions/your subscription/resourceGroups/your resource group/providers/Microsoft.Network/networkInterfaces/hana-s2-db3-inter --accelerated-networking true az network nic update --id /subscriptions/your subscription/resourceGroups/your resource group/providers/Microsoft.Network/networkInterfaces/hana-s1-db1-hsr --accelerated-networking true az network nic update --id /subscriptions/your subscription/resourceGroups/your resource group/providers/Microsoft.Network/networkInterfaces/hana-s1-db2-hsr --accelerated-networking true az network nic update --id /subscriptions/your subscription/resourceGroups/your resource group/providers/Microsoft.Network/networkInterfaces/hana-s1-db3-hsr --accelerated-networking true az network nic update --id /subscriptions/your subscription/resourceGroups/your resource group/providers/Microsoft.Network/networkInterfaces/hana-s2-db1-hsr --accelerated-networking true az network nic update --id /subscriptions/your subscription/resourceGroups/your resource group/providers/Microsoft.Network/networkInterfaces/hana-s2-db2-hsr --accelerated-networking true az network nic update --id /subscriptions/your subscription/resourceGroups/your resource group/providers/Microsoft.Network/networkInterfaces/hana-s2-db3-hsr --accelerated-networking true注意
无需在 HANA 节点上安装 Azure CLI 包,才能运行
az命令。 可以从已安装 CLI 的任何计算机运行它,也可以使用 Azure Cloud Shell。
启动 HANA DB 虚拟机。
配置 Azure 负载均衡器
在配置 VM 期间,你可以在网络部分中创建或选择现有的负载均衡器。 按照以下步骤设置标准负载均衡器以完成 HANA 数据库的高可用性设置。
注意
- 对于 HANA 横向扩展,请在后端池中添加虚拟机时选择
client子网的 NIC。 - Azure CLI 和 PowerShell 中的完整命令集在后端池中添加具有主 NIC 的 VM。
- Azure 门户
- Azure CLI
- PowerShell
按照创建负载均衡器中的步骤,使用 Azure 门户为高可用性 SAP 系统设置标准负载均衡器。 在设置负载均衡器期间,请注意以下几点:
- 前端 IP 配置:创建前端 IP。 选择与数据库虚拟机相同的虚拟网络和子网名称。
- 后端池:创建后端池并添加数据库 VM。
-
入站规则:创建负载均衡规则。 对两个负载均衡规则执行相同步骤。
- 前端 IP 地址:选择前端 IP。
- 后端池:选择后端池。
- 高可用性端口:选择此选项。
- 协议:选择“TCP”。
-
运行状况探测:创建具有以下详细信息的运行状况探测:
- 协议:选择“TCP”。
- 端口:例如 625<instance-no.>。
- 间隔时间:输入 5。
- 探测阈值:输入 2。
- 空闲超时(分钟):输入 30。
- 启用浮动 IP:选择此选项。
注意
不会遵循运行状况探测配置属性 numberOfProbes(在门户中也称为“运行不正常阈值”)。 若要控制成功或失败的连续探测的数量,请将属性 probeThreshold 设置为 2。 当前无法使用 Azure 门户设置此属性,因此请使用 Azure CLI 或 PowerShell 命令。
注意
使用标准负载均衡器时,应注意以下限制。 当你在内部负载均衡器的后端池中放置无公共 IP 地址的 VM 时,便没有出站 Internet 连接。 若要允许路由到公共终结点,需要执行其他配置。 有关详细信息,请参阅 SAP 高可用性方案中使用 Azure 标准负载均衡器的虚拟机的公共终结点连接。
重要
请勿在放置于 Azure 负载均衡器之后的 Azure VM 上启用 TCP 时间戳。 启用 TCP 时间戳会导致运行状况探测失败。 将参数 net.ipv4.tcp_timestamps 设置为 0。 有关详细信息,请参阅负载均衡器运行状况探测和 SAP 说明 2382421。
部署 NFS
可以使用两个选项为 /hana/shared 部署 Azure 本机 NFS。 可以在 Azure NetApp 文件或 Azure 文件存储上的 NFS 共享中部署 NFS 卷。 Azure 文件存储支持 NFSv4.1 协议,Azure NetApp 文件上的 NFS 支持 NFSv4.1 和 NFSv3。
后续部分介绍部署 NFS 的步骤 - 只需要选择其中一个选项。
提示
你已选择在 /hana/shared或 Azure NetApp 文件上的 NFS 卷中部署 。
部署 Azure NetApp 文件基础结构
为 /hana/shared 文件系统部署 Azure NetApp 文件卷。 对于每个 HANA 系统复制站点,都需要一个单独的 /hana/shared 卷。 有关详细信息,请参阅设置 Azure NetApp 文件基础结构。
在本例中,将使用以下 Azure NetApp 文件卷:
- 卷 HN1-shared-s1 (nfs://10.23.1.7/HN1-shared-s1)
- 卷 HN1-shared-s2 (nfs://10.23.1.7/HN1-shared-s2)
部署 Azure 文件存储上的 NFS 基础结构
为 /hana/shared 文件系统部署 Azure 文件存储 NFS 共享。 每个 HANA 系统复制站点都需要一个单独的 /hana/shared Azure 文件存储 NFS 共享。 有关详细信息,请参阅如何创建 NFS 共享。
此示例使用了以下 Azure 文件存储 NFS 共享:
- 共享 hn1-shared-s1 (sapnfsafs.file.core.windows.net:/sapnfsafs/hn1-shared-s1)
- 共享 hn1-shared-s2 (sapnfsafs.file.core.windows.net:/sapnfsafs/hn1-shared-s2)
操作系统配置和准备
后续各节中的说明以下列缩写之一作为前缀:
- [A] :适用于所有节点
- [AH]:适用于所有 HANA DB 节点
- [M]:适用于多数仲裁节点
- [AH1]:适用于站点 1 上的所有 HANA DB 节点
- [AH2]:适用于站点 2 上的所有 HANA DB 节点
- [1]:仅适用于 HANA DB 节点 1,站点 1
- [2]:仅适用于 HANA DB 节点 1,站点 2
执行以下步骤配置并准备操作系统:
[A] 维护虚拟机上的主机文件。 包括所有子网的条目。 在此示例中,向
/etc/hosts添加了以下条目。# Client subnet 10.23.0.11 hana-s1-db1 10.23.0.12 hana-s1-db1 10.23.0.13 hana-s1-db2 10.23.0.14 hana-s2-db1 10.23.0.15 hana-s2-db2 10.23.0.16 hana-s2-db3 10.23.0.17 hana-s-mm # Internode subnet 10.23.1.138 hana-s1-db1-inter 10.23.1.139 hana-s1-db2-inter 10.23.1.140 hana-s1-db3-inter 10.23.1.141 hana-s2-db1-inter 10.23.1.142 hana-s2-db2-inter 10.23.1.143 hana-s2-db3-inter # HSR subnet 10.23.1.202 hana-s1-db1-hsr 10.23.1.203 hana-s1-db2-hsr 10.23.1.204 hana-s1-db3-hsr 10.23.1.205 hana-s2-db1-hsr 10.23.1.206 hana-s2-db2-hsr 10.23.1.207 hana-s2-db3-hsr[A] 在 Microsoft 的配合下为 Azure 配置设置创建配置文件 /etc/sysctl.d/ms-az.conf。
vi /etc/sysctl.d/ms-az.conf # Add the following entries in the configuration file net.ipv6.conf.all.disable_ipv6 = 1 net.ipv4.tcp_max_syn_backlog = 16348 net.ipv4.conf.all.rp_filter = 0 sunrpc.tcp_slot_table_entries = 128 vm.swappiness=10提示
避免在
net.ipv4.ip_local_port_range配置文件中显式设置net.ipv4.ip_local_reserved_ports和sysctl,以允许 SAP 主机代理管理端口范围。 有关更多详细信息,请参阅 SAP 说明 2382421。[A] 安装 NFS 客户端包。
yum install nfs-utils[AH] Red Hat for HANA 配置。
如 Red Hat 客户门户和以下 SAP 说明中所述配置 RHEL:
- 2292690 - SAP HANA DB: Recommended OS settings for RHEL 7(2292690 - SAP HANA DB:RHEL 7 的建议 OS 设置)
- 2777782 - SAP HANA DB: Recommended OS Settings for RHEL 8(2777782 - SAP HANA DB:RHEL 8 的建议 OS 设置)
- 2455582 - Linux:运行使用 GCC 6.x 编译的 SAP 应用程序
- 2593824 - Linux:运行使用 GCC 7.x 编译的 SAP 应用程序
- 2886607 - Linux:运行使用 GCC 9.x 编译的 SAP 应用程序
准备文件系统
以下各节提供了准备文件系统的步骤。 你已选择在 Azure 文件存储上的 NFS 共享或 Azure NetApp 文件上的 NFS 卷上部署 /hana/shared。
装载共享文件系统(Azure NetApp 文件 NFS)
在此示例中,共享 HANA 文件系统部署在 Azure NetApp 文件上,并通过 NFSv4.1 装载。 请仅在使用 Azure NetApp 文件上的 NFS 时,才执行本部分的步骤。
[AH] 准备 OS 以在具有 NFS 的 NetApp 系统上运行 SAP HANA,如 SAP 说明 3024346 - 适用于 NetApp NFS 的 Linux 内核设置中所述。 为 NetApp 配置设置创建配置文件 /etc/sysctl.d/91-NetApp-HANA.conf。
vi /etc/sysctl.d/91-NetApp-HANA.conf # Add the following entries in the configuration file net.core.rmem_max = 16777216 net.core.wmem_max = 16777216 net.ipv4.tcp_rmem = 4096 131072 16777216 net.ipv4.tcp_wmem = 4096 16384 16777216 net.core.netdev_max_backlog = 300000 net.ipv4.tcp_slow_start_after_idle=0 net.ipv4.tcp_no_metrics_save = 1 net.ipv4.tcp_moderate_rcvbuf = 1 net.ipv4.tcp_window_scaling = 1 net.ipv4.tcp_sack = 1[AH] 根据 SAP 说明 3024346 - NetApp NFS 的 Linux 内核设置,调整 sunrpc 设置。
vi /etc/modprobe.d/sunrpc.conf # Insert the following line options sunrpc tcp_max_slot_table_entries=128[AH] 为 HANA 数据库卷创建装入点。
mkdir -p /hana/shared[AH] 验证 NFS 域设置。 请确保域配置为默认的 Azure NetApp 文件域 (
defaultv4iddomain.com)。 确保映射设置为nobody。
(仅当使用 Azure NetAppFiles NFS v4.1 时,才需要执行此步骤。)重要
确保在 VM 上的
/etc/idmapd.conf中设置 NFS 域,以匹配 Azure NetApp 文件上的默认域配置:“defaultv4iddomain.com”。 如果 NFS 客户端上的域配置和 NFS 服务器之间不匹配,则 VM 上已装载的 Azure NetApp 卷上文件的权限将显示为nobody。sudo cat /etc/idmapd.conf # Example [General] Domain = defaultv4iddomain.com [Mapping] Nobody-User = nobody Nobody-Group = nobody[AH] 验证
nfs4_disable_idmapping。 它应设置为Y。 若要创建nfs4_disable_idmapping所在的目录结构,请运行 mount 命令。 无法在 /sys/modules 下手动创建目录,因为访问权限是为内核或驱动程序保留的。
仅当使用 Azure NetAppFiles NFSv4.1 时,才需要执行此步骤。# Check nfs4_disable_idmapping cat /sys/module/nfs/parameters/nfs4_disable_idmapping # If you need to set nfs4_disable_idmapping to Y mkdir /mnt/tmp mount 10.9.0.4:/HN1-shared /mnt/tmp umount /mnt/tmp echo "Y" > /sys/module/nfs/parameters/nfs4_disable_idmapping # Make the configuration permanent echo "options nfs nfs4_disable_idmapping=Y" >> /etc/modprobe.d/nfs.conf有关如何更改
nfs4_disable_idmapping参数的详细信息,请参阅 Red Hat 客户门户。[AH1] 在 SITE1 HANA DB VM 上装载共享的 Azure NetApp 文件卷。
sudo mount -o rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys 10.23.1.7:/HN1-shared-s1 /hana/shared[AH2] 在 SITE2 HANA DB VM 上装载共享的 Azure NetApp 文件卷。
sudo mount -o rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys 10.23.1.7:/HN1-shared-s2 /hana/shared[AH] 验证是否在使用 NFS 协议版本 NFSv4 的所有 HANA DB VM 上装载了相应的
/hana/shared/文件系统。sudo nfsstat -m # Verify that flag vers is set to 4.1 # Example from SITE 1, hana-s1-db1 /hana/shared from 10.23.1.7:/HN1-shared-s1 Flags: rw,noatime,vers=4.1,rsize=262144,wsize=262144,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.23.0.11,local_lock=none,addr=10.23.1.7 # Example from SITE 2, hana-s2-db1 /hana/shared from 10.23.1.7:/HN1-shared-s2 Flags: rw,noatime,vers=4.1,rsize=262144,wsize=262144,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.23.0.14,local_lock=none,addr=10.23.1.7
装载共享文件系统(Azure 文件存储 NFS)
在此示例中,共享 HANA 文件系统部署在 Azure 文件存储上的 NFS 中。 请仅在使用 Azure 文件存储上的 NFS 时,才执行本部分的步骤。
[AH] 为 HANA 数据库卷创建装入点。
mkdir -p /hana/shared[AH1] 在 SITE1 HANA DB VM 上装载共享的 Azure NetApp 文件卷。
sudo vi /etc/fstab # Add the following entry sapnfsafs.file.core.windows.net:/sapnfsafs/hn1-shared-s1 /hana/shared nfs nfsvers=4.1,sec=sys 0 0 # Mount all volumes sudo mount -a[AH2] 在 SITE2 HANA DB VM 上装载共享的 Azure NetApp 文件卷。
sudo vi /etc/fstab # Add the following entries sapnfsafs.file.core.windows.net:/sapnfsafs/hn1-shared-s2 /hana/shared nfs nfsvers=4.1,sec=sys 0 0 # Mount the volume sudo mount -a[AH] 验证是否在使用 NFS 协议版本 NFSv4.1 的所有 HANA DB VM 上装载了相应的 文件系统。
sudo nfsstat -m # Example from SITE 1, hana-s1-db1 sapnfsafs.file.core.windows.net:/sapnfsafs/hn1-shared-s1 Flags: rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.23.0.19,local_lock=none,addr=10.23.0.35 # Example from SITE 2, hana-s2-db1 sapnfsafs.file.core.windows.net:/sapnfsafs/hn1-shared-s2 Flags: rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.23.0.22,local_lock=none,addr=10.23.0.35
准备数据并记录本地文件系统
在提供的配置中,你在托管磁盘上部署文件系统 /hana/data 和 /hana/log,并将这些文件系统本地附加到每个 HANA DB VM。 运行以下步骤,在每个 HANA DB 虚拟机上创建本地数据和日志卷。
使用“逻辑卷管理器 (LVM)”设置磁盘布局。 以下示例假设每个 HANA 虚拟机上附加了三个用于创建两个卷的数据磁盘。
[AH] 列出所有可用的磁盘:
ls /dev/disk/azure/scsi1/lun*示例输出:
/dev/disk/azure/scsi1/lun0 /dev/disk/azure/scsi1/lun1 /dev/disk/azure/scsi1/lun2[AH] 为想要使用的所有磁盘创建物理卷:
sudo pvcreate /dev/disk/azure/scsi1/lun0 sudo pvcreate /dev/disk/azure/scsi1/lun1 sudo pvcreate /dev/disk/azure/scsi1/lun2[AH] 为数据文件创建卷组。 将一个卷组用于日志文件,将另一个卷组用于 SAP HANA 的共享目录:
sudo vgcreate vg_hana_data_HN1 /dev/disk/azure/scsi1/lun0 /dev/disk/azure/scsi1/lun1 sudo vgcreate vg_hana_log_HN1 /dev/disk/azure/scsi1/lun2[AH] 创建逻辑卷。 线性卷是使用不带 开关的
lvcreate创建的。 我们建议你创建一个带区卷,以获得更好的 I/O 性能。 将带区大小与 SAP HANA VM 存储配置中记录的值保持一致。-i参数应表示基础物理卷的数量,-I参数则表示带区大小。 在本文中,两个物理卷用于数据卷,因此-i开关参数设置为2。 数据卷的带区大小为256 KiB。 一个物理卷用于日志卷,因此无需将-i或-I开关显式用于日志卷命令。重要
对每个数据或日志卷使用多个物理卷时,请使用
-i开关,并将其设置为基础物理卷的数量。 创建带区卷时,请使用-I开关来指定带区大小。 有关建议的存储配置,包括带区大小和磁盘数量,请参阅 SAP HANA VM 存储配置。sudo lvcreate -i 2 -I 256 -l 100%FREE -n hana_data vg_hana_data_HN1 sudo lvcreate -l 100%FREE -n hana_log vg_hana_log_HN1 sudo mkfs.xfs /dev/vg_hana_data_HN1/hana_data sudo mkfs.xfs /dev/vg_hana_log_HN1/hana_log[AH] 创建装载目录,并复制所有逻辑卷的 UUID:
sudo mkdir -p /hana/data/HN1 sudo mkdir -p /hana/log/HN1 # Write down the ID of /dev/vg_hana_data_HN1/hana_data and /dev/vg_hana_log_HN1/hana_log sudo blkid[AH] 为逻辑卷创建
fstab条目并进行装载:sudo vi /etc/fstab将以下行插入
/etc/fstab文件:/dev/disk/by-uuid/UUID of /dev/mapper/vg_hana_data_HN1-hana_data /hana/data/HN1 xfs defaults,nofail 0 2 /dev/disk/by-uuid/UUID of /dev/mapper/vg_hana_log_HN1-hana_log /hana/log/HN1 xfs defaults,nofail 0 2装载新卷:
sudo mount -a
安装
在此示例中,使用 Azure VM 上的 HSR 以横向扩展配置部署 SAP HANA 时,使用了 HANA 2.0 SP4。
准备 HANA 安装
[AH] 安装 HANA 之前,请设置根密码。 可以在安装完成后禁用根密码。 运行
root命令passwd以设置密码。[1,2] 更改对
/hana/shared的权限。chmod 775 /hana/shared[1] 验证是否可以通过安全外壳 (SSH) 登录 hana-s1-db2 和 hana-s1-db3,而不会提示输入密码 。 如果不是这种情况,则按
ssh中所述交换 密钥。ssh root@hana-s1-db2 ssh root@hana-s1-db3[2] 验证是否可以通过 SSH 登录 hana-s2-db2 和 hana-s2-db3,而不会提示输入密码 。 如果不是这种情况,则按
ssh中所述交换 密钥。ssh root@hana-s2-db2 ssh root@hana-s2-db3[AH] 安装 HANA 2.0 SP4 所需的其他包。 有关详细信息,请参阅 RHEL 7 的 SAP 说明 2593824。
# If using RHEL 7 yum install libgcc_s1 libstdc++6 compat-sap-c++-7 libatomic1 # If using RHEL 8 yum install libatomic libtool-ltdl.x86_64[A] 暂时禁用防火墙,使其不会干扰 HANA 安装。 在 HANA 安装完成后,可以重新启用它。
# Execute as root systemctl stop firewalld systemctl disable firewalld
每个站点上第一个节点上的 HANA 安装
[1] 按照 SAP HANA 2.0 Installation and Update guide(SAP HANA 2.0 安装和更新指南)中的说明安装 SAP HANA。 接下来的说明将介绍如何在站点 1 的第一个节点上安装 SAP HANA。
以
hdblcm身份从 HANA 安装软件目录启动root程序。 使用internal_network参数并传递子网的地址空间,用于内部 HANA 节点间通信。./hdblcm --internal_network=10.23.1.128/26在提示符处输入以下值:
- 对于“选择操作”,输入 1(用于安装)。
- 对于“要安装的其他组件”,输入 2、3 。
- 对于安装路径:按 Enter(默认为 /hana/shared)。
- 对于“本地主机名”,按 Enter 接受默认值。
- 对于“是否要将主机添加到系统?”,输入 n。
- 对于“SAP HANA 系统 ID”,输入 HN1。
- 对于“实例号”[00],输入 03。
- 对于“本地主机辅助角色组”[默认值],按 Enter 接受默认值。
- 对于“选择系统使用情况/输入索引[4]”,输入 4(用于自定义)。
- 对于“数据卷的位置”[/hana/data/HN1],按 Enter 接受默认值。
- 对于“日志卷的位置”[/hana/log/HN1],按 Enter 接受默认值。
- 对于“是否限制最大内存分配?”[n],请输入 n。
- 对于“主机 hana-s1-db1 的证书主机名”[hana-s1-db1],按 Enter 接受默认值。
- 对于“SAP 主机代理用户 (sapadm) 密码”,输入密码。
- 对于“确认 SAP 主机代理用户 (sapadm) 密码”,输入密码。
- 对于“系统管理员(hn1adm)密码”,输入密码。
- 对于“系统管理员主目录”[/usr/sap/HN1/home],按 Enter 接受默认值。
- 对于“系统管理员登录 Shell”[/bin/sh],按 Enter 接受默认值。
- 对于“系统管理员用户 ID”[1001],按 Enter 接受默认值。
- 对于“用户组的输入 ID (sapsys)”[79],按 Enter 接受默认值。
- 对于“系统数据库用户(system)密码”输入系统的密码。
- 对于“确认系统数据库用户(system)密码”输入系统的密码。
- 对于“重新引导计算机后是否重启系统?”[n],请输入 n。
- 对于“是否要继续(y/n)”,验证摘要,如果一切正常,请输入 y。
[2] 重复上一步,在站点 2 上的第一个节点上安装 SAP HANA。
[1,2] 验证 global.ini。
显示 global.ini,并确保 SAP HANA 内部节点间通信的配置已就位。 验证
communication部分。 它应该具有inter子网的地址空间,并且listeninterface应设置为.internal。 验证internal_hostname_resolution部分。 它应该具有属于inter子网的 HANA 虚拟机的 IP 地址。sudo cat /usr/sap/HN1/SYS/global/hdb/custom/config/global.ini # Example from SITE1 [communication] internal_network = 10.23.1.128/26 listeninterface = .internal [internal_hostname_resolution] 10.23.1.138 = hana-s1-db1 10.23.1.139 = hana-s1-db2 10.23.1.140 = hana-s1-db3[1,2] 准备好 global.ini 以在非共享环境中安装,如 SAP 说明 2080991 中所述。
sudo vi /usr/sap/HN1/SYS/global/hdb/custom/config/global.ini [persistence] basepath_shared = no[1,2] 重启 SAP HANA 以激活更改。
sudo -u hn1adm /usr/sap/hostctrl/exe/sapcontrol -nr 03 -function StopSystem sudo -u hn1adm /usr/sap/hostctrl/exe/sapcontrol -nr 03 -function StartSystem[1,2] 验证客户端接口是否使用
client子网中的 IP 地址进行通信。# Execute as hn1adm /usr/sap/HN1/HDB03/exe/hdbsql -u SYSTEM -p "password" -i 03 -d SYSTEMDB 'select * from SYS.M_HOST_INFORMATION'|grep net_publicname # Expected result - example from SITE 2 "hana-s2-db1","net_publicname","10.23.0.14"有关如何验证配置的信息,请参阅 SAP 说明 2183363 - Configuration of SAP HANA internal network(2183363 - SAP HANA 内部网络配置)。
[AH] 更改对数据和日志目录的权限,以避免 HANA 安装错误。
sudo chmod o+w -R /hana/data /hana/log[1] 安装辅助 HANA 节点。 此步骤中的示例说明适用于站点 1。
以
hdblcm身份启动常驻root程序。cd /hana/shared/HN1/hdblcm ./hdblcm在提示符处输入以下值:
- 对于“选择操作”,输入 2(用于添加主机)。
- 对于“输入要添加的逗号分隔的主机名”,hana-s1-db2、hana-s1-db3。
- 对于“要安装的其他组件”,输入 2、3 。
- 对于“输入根用户名 [root]”,按 Enter 接受默认值。
- 对于“选择主机 'hana-s1-db2' 的角色 [1]”,选择 1(适用于辅助角色)。
- 对于“输入主机 'hana-s1-db2' 的主机故障转移组 [默认值]”,按 Enter 接受默认值。
- 对于“输入主机 'hana-s1-db2' 的存储分区号 [<<自动分配>>]”,请按 Enter 接受默认值。
- 对于“输入主机 'hana-s1-db2' 的辅助角色组 [默认值]”,按 Enter 接受默认值。
- 对于“选择主机 'hana-s1-db3' 的角色 [1]”,选择 1(适用于辅助角色)。
- 对于“输入主机 'hana-s1-db3' 的主机故障转移组 [默认值]”,按 Enter 接受默认值。
- 对于“输入主机 'hana-s1-db3' 的存储分区号 [<<自动分配>>]”,请按 Enter 接受默认值。
- 对于“输入主机 'hana-s1-db3' 的辅助角色组 [默认值]”,按 Enter 接受默认值。
- 对于“系统管理员(hn1adm)密码”,输入密码。
- 对于“输入 SAP 主机代理用户 (sapadm) 密码”,输入密码。
- 对于“确认 SAP 主机代理用户 (sapadm) 密码”,输入密码。
- 对于“主机 hana-s1-db2 的证书主机名”[hana-s1-db2],按 Enter 接受默认值。
- 对于“主机 hana-s1-db3 的证书主机名”[hana-s1-db3],按 Enter 接受默认值。
- 对于“是否要继续(y/n)”,验证摘要,如果一切正常,请输入 y。
[2] 重复上一步以在站点 2 上安装辅助 SAP HANA 节点。
配置 SAP HANA 2.0 系统复制
以下步骤可以帮助你设置系统复制:
[1] 在站点 1 上配置系统复制:
以 hn1adm 身份备份数据库:
hdbsql -d SYSTEMDB -u SYSTEM -p "passwd" -i 03 "BACKUP DATA USING FILE ('initialbackupSYS')" hdbsql -d HN1 -u SYSTEM -p "passwd" -i 03 "BACKUP DATA USING FILE ('initialbackupHN1')"注意
使用本地安全存储(LSS)时,SAP HANA 备份是独立的,需要为加密密钥设置备份密码。 有关详细说明,请参阅 SAP 说明 3571561 。 必须为 SYSTEMDB 和单个租户数据库设置密码。
将系统 PKI 文件复制到辅助站点:
scp /usr/sap/HN1/SYS/global/security/rsecssfs/data/SSFS_HN1.DAT hana-s2-db1:/usr/sap/HN1/SYS/global/security/rsecssfs/data/ scp /usr/sap/HN1/SYS/global/security/rsecssfs/key/SSFS_HN1.KEY hana-s2-db1:/usr/sap/HN1/SYS/global/security/rsecssfs/key/创建主站点:
hdbnsutil -sr_enable --name=HANA_S1[2] 在站点 2 上配置系统复制:
注册第二个站点以启动系统复制。 以 <hanasid>adm 身份运行以下命令:
sapcontrol -nr 03 -function StopWait 600 10 hdbnsutil -sr_register --remoteHost=hana-s1-db1 --remoteInstance=03 --replicationMode=sync --name=HANA_S2 sapcontrol -nr 03 -function StartSystem[1] 检查复制状态并等待,直到所有数据库都保持同步。
sudo su - hn1adm -c "python /usr/sap/HN1/HDB03/exe/python_support/systemReplicationStatus.py" # | Database | Host | Port | Service Name | Volume ID | Site ID | Site Name | Secondary | Secondary | Secondary | Secondary | Secondary | Replication | Replication | Replication | # | | | | | | | | Host | Port | Site ID | Site Name | Active Status | Mode | Status | Status Details | # | -------- | ------------- | ----- | ------------ | --------- | ------- | --------- | ------------- | --------- | --------- | --------- | ------------- | ----------- | ----------- | -------------- | # | HN1 | hana-s1-db3 | 30303 | indexserver | 5 | 1 | HANA_S1 | hana-s2-db3 | 30303 | 2 | HANA_S2 | YES | SYNC | ACTIVE | | # | SYSTEMDB | hana-s1-db1 | 30301 | nameserver | 1 | 1 | HANA_S1 | hana-s2-db1 | 30301 | 2 | HANA_S2 | YES | SYNC | ACTIVE | | # | HN1 | hana-s1-db1 | 30307 | xsengine | 2 | 1 | HANA_S1 | hana-s2-db1 | 30307 | 2 | HANA_S2 | YES | SYNC | ACTIVE | | # | HN1 | hana-s1-db1 | 30303 | indexserver | 3 | 1 | HANA_S1 | hana-s2-db1 | 30303 | 2 | HANA_S2 | YES | SYNC | ACTIVE | | # | HN1 | hana-s1-db2 | 30303 | indexserver | 4 | 1 | HANA_S1 | hana-s2-db2 | 30303 | 2 | HANA_S2 | YES | SYNC | ACTIVE | | # # status system replication site "2": ACTIVE # overall system replication status: ACTIVE # # Local System Replication State # # mode: PRIMARY # site id: 1 # site name: HANA_S1[1,2] 更改 HANA 配置,以便 HANA 系统复制通信通过 HANA 系统复制虚拟网络接口进行。
在两个站点上停止 HANA.
sudo -u hn1adm /usr/sap/hostctrl/exe/sapcontrol -nr 03 -function StopSystem HDB编辑 global.ini 以便为 HANA 系统复制添加主机映射。 使用
hsr子网中的 IP 地址。sudo vi /usr/sap/HN1/SYS/global/hdb/custom/config/global.ini #Add the section [system_replication_hostname_resolution] 10.23.1.202 = hana-s1-db1 10.23.1.203 = hana-s1-db2 10.23.1.204 = hana-s1-db3 10.23.1.205 = hana-s2-db1 10.23.1.206 = hana-s2-db2 10.23.1.207 = hana-s2-db3在两个站点上启动 HANA。
sudo -u hn1adm /usr/sap/hostctrl/exe/sapcontrol -nr 03 -function StartSystem HDB
有关详细信息,请参阅系统复制的主机名解析。
[AH] 重新启用防火墙并打开所需的端口。
重新启用防火墙。
# Execute as root systemctl start firewalld systemctl enable firewalld打开所需防火墙端口。 需要为 HANA 实例编号调整端口。
重要
创建防火墙规则以允许 HANA 节点间通信和客户端流量。 所有 SAP 产品的 TCP/IP 端口上均列出了所需端口。 以下命令是一些示例。 此方案使用了系统编号 03。
# Execute as root sudo firewall-cmd --zone=public --add-port={30301,30303,30306,30307,30313,30315,30317,30340,30341,30342,1128,1129,40302,40301,40307,40303,40340,50313,50314,30310,30302}/tcp --permanent sudo firewall-cmd --zone=public --add-port={30301,30303,30306,30307,30313,30315,30317,30340,30341,30342,1128,1129,40302,40301,40307,40303,40340,50313,50314,30310,30302}/tcp
创建 Pacemaker 群集
若要创建基本 Pacemaker 群集,请按照在 Azure 中的 Red Hat Enterprise Linux 上设置 Pacemaker 的步骤进行操作。 包括所有虚拟机,其中包括群集中的多数仲裁虚拟机。
重要
不要将 quorum expected-votes 设置为 2。 这不是双节点群集。 确保已启用群集属性 concurrent-fencing,以便反序列化节点隔离。
创建文件系统资源
此过程的下一部分需要创建文件系统资源。 下面介绍如何操作:
[1,2] 在两个复制站点上停止 SAP HANA。 以 <sid>adm 身份运行。
sapcontrol -nr 03 -function StopSystem[AH] 卸载临时安装在所有 HANA DB VM 上的文件系统
/hana/shared。 需要先停止正在使用该文件系统的所有进程和会话,再将其卸载。umount /hana/shared[1] 为处于禁用状态的
/hana/shared创建文件系统群集资源。 使用--disabled因为必须在启用装载之前定义位置约束。
你已选择在 Azure 文件存储上的 NFS 共享或 Azure NetApp 文件上的 NFS 卷上部署 /hana/shared。在此示例中,“/hana/shared”文件系统部署在 Azure NetApp 文件上,通过 NFSv4.1 进行装载。 请仅在使用 Azure NetApp 文件上的 NFS 时,才执行本部分的步骤。
# /hana/shared file system for site 1 pcs resource create fs_hana_shared_s1 --disabled ocf:heartbeat:Filesystem device=10.23.1.7:/HN1-shared-s1 directory=/hana/shared \ fstype=nfs options='defaults,rw,hard,timeo=600,rsize=262144,wsize=262144,proto=tcp,noatime,sec=sys,nfsvers=4.1,lock,_netdev' op monitor interval=20s on-fail=fence timeout=120s OCF_CHECK_LEVEL=20 \ op start interval=0 timeout=120 op stop interval=0 timeout=120 # /hana/shared file system for site 2 pcs resource create fs_hana_shared_s2 --disabled ocf:heartbeat:Filesystem device=10.23.1.7:/HN1-shared-s1 directory=/hana/shared \ fstype=nfs options='defaults,rw,hard,timeo=600,rsize=262144,wsize=262144,proto=tcp,noatime,sec=sys,nfsvers=4.1,lock,_netdev' op monitor interval=20s on-fail=fence timeout=120s OCF_CHECK_LEVEL=20 \ op start interval=0 timeout=120 op stop interval=0 timeout=120 # clone the /hana/shared file system resources for both site1 and site2 pcs resource clone fs_hana_shared_s1 meta clone-node-max=1 interleave=true pcs resource clone fs_hana_shared_s2 meta clone-node-max=1 interleave=true
建议的超时值允许群集资源承受与 Azure NetApp 文件上的 NFSv4.1 租约续订相关的、特定于协议的暂停。 有关详细信息,请参阅 NetApp 最佳做法中的 NFS。
在此示例中,“/hana/shared”文件系统部署在 Azure 文件存储上的 NFS 中。 请仅在使用 Azure 文件存储上的 NFS 时,才执行本部分的步骤。
# /hana/shared file system for site 1 pcs resource create fs_hana_shared_s1 --disabled ocf:heartbeat:Filesystem device=sapnfsafs.file.core.windows.net:/sapnfsafs/hn1-shared-s1 directory=/hana/shared \ fstype=nfs options='defaults,rw,hard,proto=tcp,noatime,nfsvers=4.1,lock' op monitor interval=20s on-fail=fence timeout=120s OCF_CHECK_LEVEL=20 \ op start interval=0 timeout=120 op stop interval=0 timeout=120 # /hana/shared file system for site 2 pcs resource create fs_hana_shared_s2 --disabled ocf:heartbeat:Filesystem device=sapnfsafs.file.core.windows.net:/sapnfsafs/hn1-shared-s2 directory=/hana/shared \ fstype=nfs options='defaults,rw,hard,proto=tcp,noatime,nfsvers=4.1,lock' op monitor interval=20s on-fail=fence timeout=120s OCF_CHECK_LEVEL=20 \ op start interval=0 timeout=120 op stop interval=0 timeout=120 # clone the /hana/shared file system resources for both site1 and site2 pcs resource clone fs_hana_shared_s1 meta clone-node-max=1 interleave=true pcs resource clone fs_hana_shared_s2 meta clone-node-max=1 interleave=true在监视操作中添加
OCF_CHECK_LEVEL=20属性,以便监视操作在文件系统上执行读取/写入测试。 如果没有此属性,则监视操作仅验证是否已装载文件系统。 这可能是一个问题,因为连接丢失时,尽管无法访问文件系统,但它仍可能保持装载状态。on-fail=fence属性也会添加到监视操作中。 使用此选项时,如果监视操作在节点上失败,则会立即隔离该节点。 如果不使用此选项,则默认行为是停止依赖于失败资源的所有资源,然后重启失败的资源,再启动依赖于失败资源的所有资源。 当 SAP HANA 资源依赖于失败的资源时,此行为不仅费时,还可能彻底失败。 如果持有 SAP HANA 二进制文件的 NFS 共享不可访问,则 SAPHana 资源无法成功停止。上述配置中的超时可能需要适应特定的 SAP 设置。
[1] 配置并验证节点属性。 复制站点 1 上的所有 SAP HANA DB 节点均为分配的属性
S1,并且复制站点 2 上的所有 SAP HANA DB 节点均为分配的属性S2。# HANA replication site 1 pcs node attribute hana-s1-db1 NFS_SID_SITE=S1 pcs node attribute hana-s1-db2 NFS_SID_SITE=S1 pcs node attribute hana-s1-db3 NFS_SID_SITE=S1 # HANA replication site 2 pcs node attribute hana-s2-db1 NFS_SID_SITE=S2 pcs node attribute hana-s2-db2 NFS_SID_SITE=S2 pcs node attribute hana-s2-db3 NFS_SID_SITE=S2 # To verify the attribute assignment to nodes execute pcs node attribute[1] 配置约束,用于确定 NFS 文件系统的装载位置,并启用文件系统资源。
# Configure the constraints pcs constraint location fs_hana_shared_s1-clone rule resource-discovery=never score=-INFINITY NFS_SID_SITE ne S1 pcs constraint location fs_hana_shared_s2-clone rule resource-discovery=never score=-INFINITY NFS_SID_SITE ne S2 # Enable the file system resources pcs resource enable fs_hana_shared_s1 pcs resource enable fs_hana_shared_s2启用文件系统资源后,群集将装载
/hana/shared文件系统。[AH] 验证是否在两个站点的所有 HANA DB VM 上的
/hana/shared下都装载了 Azure NetApp 文件卷。示例(如果使用 Azure NetApp 文件):
sudo nfsstat -m # Verify that flag vers is set to 4.1 # Example from SITE 1, hana-s1-db1 /hana/shared from 10.23.1.7:/HN1-shared-s1 Flags: rw,noatime,vers=4.1,rsize=262144,wsize=262144,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.23.0.11,local_lock=none,addr=10.23.1.7 # Example from SITE 2, hana-s2-db1 /hana/shared from 10.23.1.7:/HN1-shared-s2 Flags: rw,noatime,vers=4.1,rsize=262144,wsize=262144,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.23.0.14,local_lock=none,addr=10.23.1.7示例(如果使用 Azure 文件存储 NFS):
sudo nfsstat -m # Example from SITE 1, hana-s1-db1 sapnfsafs.file.core.windows.net:/sapnfsafs/hn1-shared-s1 Flags: rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.23.0.19,local_lock=none,addr=10.23.0.35 # Example from SITE 2, hana-s2-db1 sapnfsafs.file.core.windows.net:/sapnfsafs/hn1-shared-s2 Flags: rw,relatime,vers=4.1,rsize=1048576,wsize=1048576,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.23.0.22,local_lock=none,addr=10.23.0.35
[1] 配置和克隆属性资源,并配置约束,如下所示:
# Configure the attribute resources pcs resource create hana_nfs_s1_active ocf:pacemaker:attribute active_value=true inactive_value=false name=hana_nfs_s1_active pcs resource create hana_nfs_s2_active ocf:pacemaker:attribute active_value=true inactive_value=false name=hana_nfs_s2_active # Clone the attribute resources pcs resource clone hana_nfs_s1_active meta clone-node-max=1 interleave=true pcs resource clone hana_nfs_s2_active meta clone-node-max=1 interleave=true # Configure the constraints, which will set the attribute values pcs constraint order fs_hana_shared_s1-clone then hana_nfs_s1_active-clone pcs constraint order fs_hana_shared_s2-clone then hana_nfs_s2_active-clone提示
如果配置包括
hana/shared之外的文件系统,并且这些文件系统已装载 NFS,则包括sequential=false选项。 此选项可确保文件系统之间没有排序依赖关系。 所有 NFS 装载的文件系统都必须在相应的属性资源之前启动,但是不需要以彼此相对的顺序启动。 有关详细信息,请参阅当 HANA 文件系统为 NFS 共享时,如何在 Pacemaker 群集中配置 SAP HANA 横向扩展 HSR。[1] 将 Pacemaker 置于维护模式,以便为创建 HANA 群集资源做准备。
pcs property set maintenance-mode=true
创建 SAP HANA 群集资源
现在便可以创建群集资源:
[A] 在所有群集节点上安装 HANA 横向扩展资源代理,包括多数仲裁节点。
yum install -y resource-agents-sap-hana-scaleout注意
有关操作系统版本的
resource-agents-sap-hana-scaleout包的最小受支持版本,请参阅 RHEL HA 群集的支持策略 - 在群集中管理 SAP HANA。[1,2] 在每个系统复制站点的一个 HANA DB 节点上配置 HANA 系统复制挂钩。 SAP HANA 应仍为关闭状态。
resource-agents-sap-hana-scaleout版本 0.185.3-0 或更高包括 SAPHanaSR 挂钩和 ChkSrv 挂钩。 必须执行正确的群集操作才能启用 SAPHanaSR 挂钩。 强烈建议同时配置 SAPHanaSR 和 ChkSrv Python 挂钩。调整
global.ini。# add to global.ini [ha_dr_provider_SAPHanaSR] provider = SAPHanaSR path = /usr/share/SAPHanaSR-ScaleOut execution_order = 1 [ha_dr_provider_chksrv] provider = ChkSrv path = /usr/share/SAPHanaSR-ScaleOut execution_order = 2 action_on_lost = kill [trace] ha_dr_saphanasr = info ha_dr_chksrv = info
如果将参数
path指向默认的/usr/share/SAPHanaSR-ScaleOut位置,Python 挂钩代码将通过 OS 更新自动更新。 HANA 在下一次重启时使用挂钩代码更新。 通过使用可选自有路径(如/hana/shared/myHooks),可将 OS 更新与 HANA 将使用的挂钩版本分离。可以使用
ChkSrv参数调整action_on_lost挂钩的行为。 有效值为 [ignore|stop|kill]。有关 SAP HANA 挂钩实现的详细信息,请参阅启用 SAP HANA srConnectionChanged() 挂钩和为 hdbindexserver 进程失败操作(可选)启用 SAP HANA srServiceStateChanged() 挂钩。
[AH] 群集需要在群集节点上为 <sid>adm 配置 sudoers。 在此示例中,通过创建新文件来实现此目的。 以
root的身份运行命令。sudo visudo -f /etc/sudoers.d/20-saphana # Insert the following lines and then save Cmnd_Alias SOK = /usr/sbin/crm_attribute -n hana_hn1_glob_srHook -v SOK -t crm_config -s SAPHanaSR Cmnd_Alias SFAIL = /usr/sbin/crm_attribute -n hana_hn1_glob_srHook -v SFAIL -t crm_config -s SAPHanaSR Cmnd_Alias SRREBOOT = /usr/sbin/crm_attribute -n hana_hn1_gsh -v * -l reboot -t crm_config -s SAPHanaSR hn1adm ALL=(ALL) NOPASSWD: SOK, SFAIL, SRREBOOT Defaults!SOK, SFAIL, SRREBOOT !requiretty[1,2] 在两个复制站点上启动 SAP HANA。 以 <sid>adm 身份运行。
sapcontrol -nr 03 -function StartSystem[1] 验证是否安装了挂钩。 在活动 HANA 系统复制站点上以 <sid>adm 身份运行。
cdtrace awk '/ha_dr_SAPHanaSR.*crm_attribute/ \ { printf "%s %s %s %s\n",$2,$3,$5,$16 }' nameserver_* # Example entries # 2020-07-21 22:04:52.782774 ha_dr_SAPHanaSR SFAIL # 2020-07-21 22:04:53.117492 ha_dr_SAPHanaSR SFAIL # 2020-07-21 22:06:35.599324 ha_dr_SAPHanaSR SOK[1] 验证 ChkSrv 挂钩安装。 在活动 HANA 系统复制站点上以 <sid>adm 身份运行。
cdtrace tail -20 nameserver_chksrv.trc[1] 创建 HANA 群集资源。 以
root身份运行以下命令。请确保群集已处于维护模式。
接下来,创建 HANA 拓扑资源。
如果要生成 RHEL 7.x 群集,请使用以下命令:pcs resource create SAPHanaTopology_HN1_HDB03 SAPHanaTopologyScaleOut \ SID=HN1 InstanceNumber=03 \ op start timeout=600 op stop timeout=300 op monitor interval=10 timeout=600 pcs resource clone SAPHanaTopology_HN1_HDB03 meta clone-node-max=1 interleave=true如果要生成一个 RHEL >= 8.x 的群集,请使用以下命令:
pcs resource create SAPHanaTopology_HN1_HDB03 SAPHanaTopology \ SID=HN1 InstanceNumber=03 meta clone-node-max=1 interleave=true \ op methods interval=0s timeout=5 \ op start timeout=600 op stop timeout=300 op monitor interval=10 timeout=600 pcs resource clone SAPHanaTopology_HN1_HDB03 meta clone-node-max=1 interleave=true创建 HANA 实例资源。
注意
本文包含对 Microsoft 不再使用的术语的引用。 在从软件中删除该术语后,我们会将其从本文中删除。
如果要生成 RHEL 7.x 群集,请使用以下命令:
pcs resource create SAPHana_HN1_HDB03 SAPHanaController \ SID=HN1 InstanceNumber=03 PREFER_SITE_TAKEOVER=true DUPLICATE_PRIMARY_TIMEOUT=7200 AUTOMATED_REGISTER=false \ op start interval=0 timeout=3600 op stop interval=0 timeout=3600 op promote interval=0 timeout=3600 \ op monitor interval=60 role="Master" timeout=700 op monitor interval=61 role="Slave" timeout=700 pcs resource master msl_SAPHana_HN1_HDB03 SAPHana_HN1_HDB03 \ meta master-max="1" clone-node-max=1 interleave=true如果要生成一个 RHEL >= 8.x 的群集,请使用以下命令:
pcs resource create SAPHana_HN1_HDB03 SAPHanaController \ SID=HN1 InstanceNumber=03 PREFER_SITE_TAKEOVER=true DUPLICATE_PRIMARY_TIMEOUT=7200 AUTOMATED_REGISTER=false \ op demote interval=0s timeout=320 op methods interval=0s timeout=5 \ op start interval=0 timeout=3600 op stop interval=0 timeout=3600 op promote interval=0 timeout=3600 \ op monitor interval=60 role="Master" timeout=700 op monitor interval=61 role="Slave" timeout=700 pcs resource promotable SAPHana_HN1_HDB03 \ meta master-max="1" clone-node-max=1 interleave=true重要
在执行故障转移测试时,最好将
AUTOMATED_REGISTER设置为false,以防止故障的主实例自动注册为辅助实例。 测试后,最佳做法是将AUTOMATED_REGISTER设置为true,以便在接管后系统复制可以自动继续。创建虚拟 IP 和关联的资源。
pcs resource create vip_HN1_03 ocf:heartbeat:IPaddr2 ip=10.23.0.18 op monitor interval="10s" timeout="20s" sudo pcs resource create nc_HN1_03 azure-lb port=62503 sudo pcs resource group add g_ip_HN1_03 nc_HN1_03 vip_HN1_03创建群集约束。
如果要生成 RHEL 7.x 群集,请使用以下命令:
#Start HANA topology, before the HANA instance pcs constraint order SAPHanaTopology_HN1_HDB03-clone then msl_SAPHana_HN1_HDB03 pcs constraint colocation add g_ip_HN1_03 with master msl_SAPHana_HN1_HDB03 4000 #HANA resources are only allowed to run on a node, if the node's NFS file systems are mounted. The constraint also avoids the majority maker node pcs constraint location SAPHanaTopology_HN1_HDB03-clone rule resource-discovery=never score=-INFINITY hana_nfs_s1_active ne true and hana_nfs_s2_active ne true如果要生成一个 RHEL >= 8.x 的群集,请使用以下命令:
#Start HANA topology, before the HANA instance pcs constraint order SAPHanaTopology_HN1_HDB03-clone then SAPHana_HN1_HDB03-clone pcs constraint colocation add g_ip_HN1_03 with master SAPHana_HN1_HDB03-clone 4000 #HANA resources are only allowed to run on a node, if the node's NFS file systems are mounted. The constraint also avoids the majority maker node pcs constraint location SAPHanaTopology_HN1_HDB03-clone rule resource-discovery=never score=-INFINITY hana_nfs_s1_active ne true and hana_nfs_s2_active ne true
[1] 将群集退出维护模式。 确保群集状态为
ok,并且所有资源都已启动。sudo pcs property set maintenance-mode=false #If there are failed cluster resources, you may need to run the next command pcs resource cleanup注意
上述配置中的超时只是示例,可能需要根据特定的 HANA 设置进行调整。 例如,如果启动 SAP HANA 数据库需要较长时间,则可能需要增加启动超时。
配置启用 HANA 活动/读取的系统复制
从 SAP HANA 2.0 SPS 01 开始,SAP 允许对 SAP HANA 系统复制使用启用活动/读取的设置。 借助此功能,SAP HANA 系统复制的辅助系统可积极用于读取密集型工作负载。 若要在群集中支持此类设置,需要提供第二个虚拟 IP 地址,以便客户端能够访问启用了辅助读取的 SAP HANA 数据库。 若要确保辅助复制站点在接管后仍可以访问,群集需要将虚拟 IP 地址与 SAP HANA 资源的辅助地址一起移动。
本部分介绍使用第二个虚拟 IP 地址在 Red Hat 高可用性群集中管理此类系统复制时必须执行的其他步骤。
在继续下一步之前,请确保已完全配置管理 SAP HANA 数据库的 Red Hat 高可用性群集,如本文前面所述。
在 Azure 负载均衡器中进行其他设置,以实现启用活动/读取设置
若要继续预配第二个虚拟 IP,请确保已按照配置 Azure 负载均衡器部分所述配置 Azure 负载均衡器。
对于“标准”负载均衡器,请在前面部分中创建的同一负载平衡器上按照以下附加步骤进行操作。
创建第二个前端 IP 池:
- 打开负载均衡器,选择前端 IP 池,然后选择“添加”。
- 输入第二个新前端 IP 池的名称(例如“hana-secondaryIP”)。
- 将“分配”设置为“静态”并输入 IP 地址(例如,“10.23.0.19”)。
- 选择“确定”。
- 创建新前端 IP 池后,请记下池 IP 地址。
接下来创建运行状况探测:
- 打开负载均衡器,选择运行状况探测,然后选择“添加”。
- 输入新运行状况探测的名称(例如“hana-secondaryhp”)。
- 选择“TCP”作为协议,并选择端口“62603” 。 将“间隔”值保留设置为 5,将“不正常阈”值设置为 2。
- 选择“确定”。
接下来,创建负载均衡规则:
- 打开负载均衡器,选择负载均衡规则,然后选择“添加”。
- 输入新负载均衡器规则的名称(例如“hana-secondarylb”)。
- 选择前面创建的前端 IP 地址、后端池和运行状况探测(例如“hana-secondaryIP”、“hana-backend”和“hana-secondaryhp”)。
- 选择“HA 端口”。
- 确保启用浮动 IP。
- 选择“确定”。
配置启用 HANA 活动/读取的系统复制
配置 SAP HANA 2.0 系统复制部分介绍了配置 HANA 系统复制的步骤。 如果部署已启用读取的辅助方案,则在第二个节点上配置系统复制的同时,请以“hanasid”adm 身份运行以下命令:
sapcontrol -nr 03 -function StopWait 600 10
hdbnsutil -sr_register --remoteHost=hana-s1-db1 --remoteInstance=03 --replicationMode=sync --name=HANA_S2 --operationMode=logreplay_readaccess
为已启用活动/读取设置添加辅助虚拟 IP 地址资源
可以通过以下命令配置第二个虚拟 IP 和其他约束。 如果辅助实例关闭,辅助虚拟 IP 将切换为主虚拟 IP。
pcs property set maintenance-mode=true
pcs resource create secvip_HN1_03 ocf:heartbeat:IPaddr2 ip="10.23.0.19"
pcs resource create secnc_HN1_03 ocf:heartbeat:azure-lb port=62603
pcs resource group add g_secip_HN1_03 secnc_HN1_03 secvip_HN1_03
# RHEL 8.x:
pcs constraint location g_ip_HN1_03 rule score=500 role=master hana_hn1_roles eq "master1:master:worker:master" and hana_hn1_clone_state eq PROMOTED
pcs constraint location g_secip_HN1_03 rule score=50 hana_hn1_roles eq 'master1:master:worker:master'
pcs constraint order promote SAPHana_HN1_HDB03-clone then start g_ip_HN1_03
pcs constraint order start g_ip_HN1_03 then start g_secip_HN1_03
pcs constraint colocation add g_secip_HN1_03 with Slave SAPHana_HN1_HDB03-clone 5
# RHEL 7.x:
pcs constraint location g_ip_HN1_03 rule score=500 role=master hana_hn1_roles eq "master1:master:worker:master" and hana_hn1_clone_state eq PROMOTED
pcs constraint location g_secip_HN1_03 rule score=50 hana_hn1_roles eq 'master1:master:worker:master'
pcs constraint order promote msl_SAPHana_HN1_HDB03 then start g_ip_HN1_03
pcs constraint order start g_ip_HN1_03 then start g_secip_HN1_03
pcs constraint colocation add g_secip_HN1_03 with Slave msl_SAPHana_HN1_HDB03 5
pcs property set maintenance-mode=false
确保群集状态为 ok,并且所有资源都已启动。 第二个虚拟 IP 将与 SAP HANA 辅助资源一起在辅助站点上运行。
# Example output from crm_mon
#Online: [ hana-s-mm hana-s1-db1 hana-s1-db2 hana-s1-db3 hana-s2-db1 hana-s2-db2 hana-s2-db3 ]
#
#Active resources:
#
#rsc_st_azure (stonith:fence_azure_arm): Started hana-s-mm
#Clone Set: fs_hana_shared_s1-clone [fs_hana_shared_s1]
# Started: [ hana--s1-db1 hana-s1-db2 hana-s1-db3 ]
#Clone Set: fs_hana_shared_s2-clone [fs_hana_shared_s2]
# Started: [ hana-s2-db1 hana-s2-db2 hana-s2-db3 ]
#Clone Set: hana_nfs_s1_active-clone [hana_nfs_s1_active]
# Started: [ hana-s1-db1 hana-s1-db2 hana-s1-db3 ]
#Clone Set: hana_nfs_s2_active-clone [hana_nfs_s2_active]
# Started: [ hana-s2-db1 hana-s2-db2 hana-s2-db3 ]
#Clone Set: SAPHanaTopology_HN1_HDB03-clone [SAPHanaTopology_HN1_HDB03]
# Started: [ hana-s1-db1 hana-s1-db2 hana-s1-db3 hana-s2-db1 hana-s2-db2 hana-s2-db3 ]
#Master/Slave Set: msl_SAPHana_HN1_HDB03 [SAPHana_HN1_HDB03]
# Masters: [ hana-s1-db1 ]
# Slaves: [ hana-s1-db2 hana-s1-db3 hana-s2-db1 hana-s2-db2 hana-s2-db3 ]
#Resource Group: g_ip_HN1_03
# nc_HN1_03 (ocf::heartbeat:azure-lb): Started hana-s1-db1
# vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hana-s1-db1
#Resource Group: g_secip_HN1_03
# secnc_HN1_03 (ocf::heartbeat:azure-lb): Started hana-s2-db1
# secvip_HN1_03 (ocf::heartbeat:IPaddr2): Started hana-s2-db1
在下一部分中,可以找到要运行的典型故障转移测试组。
在测试使用已启用读取辅助配置的 HANA 群集时,请注意第二个虚拟 IP 的以下行为:
当群集资源 SAPHana_HN1_HDB03 移动到辅助站点 (S2) 时,第二个虚拟 IP 将移动到另一个站点,即移动到 hana-s1-db1 。 如果已配置
AUTOMATED_REGISTER="false",且未自动注册 HANA 系统复制,则第二个虚拟 IP 将在 hana-s2-db1 上运行。测试服务器故障时,第二个虚拟 IP 资源 (secvip_HN1_03) 和 Azure 负载均衡器端口资源 (secnc_HN1_03) 将在主服务器上与主虚拟 IP 资源一起运行 。 当辅助服务器关闭时,连接到启用读取的 HANA 数据库的应用程序将连接到主 HANA 数据库。 这是预期的行为。 它允许连接到已启用读取的 HANA 数据库的应用程序在辅助服务器不可用的情况下运行。
在故障转移和回退过程中,使用第二个虚拟 IP 连接到 HANA 数据库的应用程序的现有连接可能会中断。
测试 SAP HANA 故障转移
在开始测试前,请检查群集和 SAP HANA 系统复制状态。
验证是否不存在失败的群集操作。
#Verify that there are no failed cluster actions pcs status # Example #Stack: corosync #Current DC: hana-s-mm (version 1.1.19-8.el7_6.5-c3c624ea3d) - partition with quorum #Last updated: Thu Sep 24 06:00:20 2020 #Last change: Thu Sep 24 05:59:17 2020 by root via crm_attribute on hana-s1-db1 # #7 nodes configured #45 resources configured # #Online: [ hana-s-mm hana-s1-db1 hana-s1-db2 hana-s1-db3 hana-s2-db1 hana-s2-db2 hana-s2-db3 ] # #Active resources: # #rsc_st_azure (stonith:fence_azure_arm): Started hana-s-mm #Clone Set: fs_hana_shared_s1-clone [fs_hana_shared_s1] # Started: [ hana--s1-db1 hana-s1-db2 hana-s1-db3 ] #Clone Set: fs_hana_shared_s2-clone [fs_hana_shared_s2] # Started: [ hana-s2-db1 hana-s2-db2 hana-s2-db3 ] #Clone Set: hana_nfs_s1_active-clone [hana_nfs_s1_active] # Started: [ hana-s1-db1 hana-s1-db2 hana-s1-db3 ] #Clone Set: hana_nfs_s2_active-clone [hana_nfs_s2_active] # Started: [ hana-s2-db1 hana-s2-db2 hana-s2-db3 ] #Clone Set: SAPHanaTopology_HN1_HDB03-clone [SAPHanaTopology_HN1_HDB03] # Started: [ hana-s1-db1 hana-s1-db2 hana-s1-db3 hana-s2-db1 hana-s2-db2 hana-s2-db3 ] #Master/Slave Set: msl_SAPHana_HN1_HDB03 [SAPHana_HN1_HDB03] # Masters: [ hana-s1-db1 ] # Slaves: [ hana-s1-db2 hana-s1-db3 hana-s2-db1 hana-s2-db2 hana-s2-db3 ] #Resource Group: g_ip_HN1_03 # nc_HN1_03 (ocf::heartbeat:azure-lb): Started hana-s1-db1 # vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hana-s1-db1验证 SAP HANA 系统复制是否同步。
# Verify HANA HSR is in sync sudo su - hn1adm -c "python /usr/sap/HN1/HDB03/exe/python_support/systemReplicationStatus.py" #| Database | Host | Port | Service Name | Volume ID | Site ID | Site Name | Secondary | Secondary| Secondary | Secondary | Secondary | Replication | Replication | Replication | #| | | | | | | | Host | Port | Site ID | Site Name | Active Status | Mode | Status | Status Details | #| -------- | ----------- | ----- | ------------ | --------- | ------- | --------- | ------------- | -------- | --------- | --------- | ------------- | ----------- | ----------- | -------------- | #| HN1 | hana-s1-db3 | 30303 | indexserver | 5 | 2 | HANA_S1 | hana-s2-db3 | 30303 | 1 | HANA_S2 | YES | SYNC | ACTIVE | | #| HN1 | hana-s1-db2 | 30303 | indexserver | 4 | 2 | HANA_S1 | hana-s2-db2 | 30303 | 1 | HANA_S2 | YES | SYNC | ACTIVE | | #| SYSTEMDB | hana-s1-db1 | 30301 | nameserver | 1 | 2 | HANA_S1 | hana-s2-db1 | 30301 | 1 | HANA_S2 | YES | SYNC | ACTIVE | | #| HN1 | hana-s1-db1 | 30307 | xsengine | 2 | 2 | HANA_S1 | hana-s2-db1 | 30307 | 1 | HANA_S2 | YES | SYNC | ACTIVE | | #| HN1 | hana-s1-db1 | 30303 | indexserver | 3 | 2 | HANA_S1 | hana-s2-db1 | 30303 | 1 | HANA_S2 | YES | SYNC | ACTIVE | | #status system replication site "1": ACTIVE #overall system replication status: ACTIVE #Local System Replication State #~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ #mode: PRIMARY #site id: 1 #site name: HANA_S1
验证节点无法访问 NFS 共享 (
/hana/shared) 的故障情况下的群集配置。SAP HANA 资源代理依赖于二进制文件,这些文件存储在
/hana/shared中,以便在故障转移过程中执行操作。 文件系统/hana/shared以所提供的配置通过 NFS 装载。 可以执行的一项测试是创建临时防火墙规则,用于在某个主站点 VM 上阻止访问/hana/sharedNFS 装载的文件系统。 此方法验证如果在活动系统复制站点上丢失对/hana/shared的访问权限,群集是否会进行故障转移。预期结果:在某个主站点 VM 上阻止访问 NFS 装载的文件系统时,对文件系统执行读/写操作的监视操作将会失败,因为它无法访问文件系统并将触发 HANA 资源故障转移。 当 HANA 节点失去对 NFS 共享的访问权限时,会出现相同的结果。
可以通过运行
crm_mon或pcs status来检查群集资源的状态。 开始测试之前的资源状态:# Output of crm_mon #7 nodes configured #45 resources configured #Online: [ hana-s-mm hana-s1-db1 hana-s1-db2 hana-s1-db3 hana-s2-db1 hana-s2-db2 hana-s2-db3 ] # #Active resources: #rsc_st_azure (stonith:fence_azure_arm): Started hana-s-mm # Clone Set: fs_hana_shared_s1-clone [fs_hana_shared_s1] # Started: [ hana-s1-db1 hana-s1-db2 hana-s1-db3 ] # Clone Set: fs_hana_shared_s2-clone [fs_hana_shared_s2] # Started: [ hana-s2-db1 hana-s2-db2 hana-s2-db3 ] # Clone Set: hana_nfs_s1_active-clone [hana_nfs_s1_active] # Started: [ hana-s1-db1 hana-s1-db2 hana-s1-db3 ] # Clone Set: hana_nfs_s2_active-clone [hana_nfs_s2_active] # Started: [ hana-s2-db1 hana-s2-db2 hana-s2-db3 ] # Clone Set: SAPHanaTopology_HN1_HDB03-clone [SAPHanaTopology_HN1_HDB03] # Started: [ hana-s1-db1 hana-s1-db2 hana-s1-db3 hana-s2-db1 hana-s2-db2 hana-s2-db3 ] # Master/Slave Set: msl_SAPHana_HN1_HDB03 [SAPHana_HN1_HDB03] # Masters: [ hana-s1-db1 ] # Slaves: [ hana-s1-db2 hana-s1-db3 hana-s2-db1 hana-s2-db2 hana-s2-db3 ] # Resource Group: g_ip_HN1_03 # nc_HN1_03 (ocf::heartbeat:azure-lb): Started hana-s1-db1 # vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hana-s1-db1若要模拟
/hana/shared的故障,请执行以下操作:- 如果使用 ANF 上的 NFS,请先在主站点上确认
/hana/sharedANF 卷的 IP 地址。 可以通过运行df -kh|grep /hana/shared来实现此目的。 - 如果使用 Azure 文件存储上的 NFS,请先确定存储帐户的专用终结点的 IP 地址。
然后,设置一个临时防火墙规则来阻止访问
/hana/sharedNFS 文件系统的 IP 地址,方法是在某个主 HANA 系统复制站点 VM 上执行以下命令。在此示例中,该命令已在 hana-s1-db1 上针对 ANF 卷
/hana/shared执行。iptables -A INPUT -s 10.23.1.7 -j DROP; iptables -A OUTPUT -d 10.23.1.7 -j DROP丢失对
/hana/shared的访问权限的 HANA VM 应根据群集配置重启或停止。 群集资源将迁移到其他 HANA 系统复制站点。如果在重启的 VM 上未启动群集,则通过运行以下命令启动群集:
# Start the cluster pcs cluster start群集启动时,将自动装载文件系统
/hana/shared。 如果设置AUTOMATED_REGISTER="false",则需要在辅助站点上配置 SAP HANA 系统复制。 在这种情况下,可以运行以下命令来将 SAP HANA 重新配置为辅助站点。# Execute on the secondary su - hn1adm # Make sure HANA is not running on the secondary site. If it is started, stop HANA sapcontrol -nr 03 -function StopWait 600 10 # Register the HANA secondary site hdbnsutil -sr_register --name=HANA_S1 --remoteHost=hana-s2-db1 --remoteInstance=03 --replicationMode=sync # Switch back to root and clean up failed resources pcs resource cleanup SAPHana_HN1_HDB03测试后资源的状态:
# Output of crm_mon #7 nodes configured #45 resources configured #Online: [ hana-s-mm hana-s1-db1 hana-s1-db2 hana-s1-db3 hana-s2-db1 hana-s2-db2 hana-s2-db3 ] #Active resources: #rsc_st_azure (stonith:fence_azure_arm): Started hana-s-mm # Clone Set: fs_hana_shared_s1-clone [fs_hana_shared_s1] # Started: [ hana-s1-db1 hana-s1-db2 hana-s1-db3 ] # Clone Set: fs_hana_shared_s2-clone [fs_hana_shared_s2] # Started: [ hana-s2-db1 hana-s2-db2 hana-s2-db3 ] # Clone Set: hana_nfs_s1_active-clone [hana_nfs_s1_active] # Started: [ hana-s1-db1 hana-s1-db2 hana-s1-db3 ] # Clone Set: hana_nfs_s2_active-clone [hana_nfs_s2_active] # Started: [ hana-s2-db1 hana-s2-db2 hana-s2-db3 ] # Clone Set: SAPHanaTopology_HN1_HDB03-clone [SAPHanaTopology_HN1_HDB03] # Started: [ hana-s1-db1 hana-s1-db2 hana-s1-db3 hana-s2-db1 hana-s2-db2 hana-s2-db3 ] # Master/Slave Set: msl_SAPHana_HN1_HDB03 [SAPHana_HN1_HDB03] # Masters: [ hana-s2-db1 ] # Slaves: [ hana-s1-db1 hana-s1-db2 hana-s1-db3 hana-s2-db2 hana-s2-db3 ] # Resource Group: g_ip_HN1_03 # nc_HN1_03 (ocf::heartbeat:azure-lb): Started hana-s2-db1 # vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hana-s2-db1- 如果使用 ANF 上的 NFS,请先在主站点上确认
最好同时执行 RHEL 上的 Azure VM 上的 HA for SAP HANA 中记录的测试,来全面测试 SAP HANA 群集配置。
后续步骤
- 适用于 SAP 的 Azure 虚拟机规划和实施
- 适用于 SAP 的 Azure 虚拟机部署
- 适用于 SAP 的 Azure 虚拟机 DBMS 部署
- 适用于 SAP HANA 的 Azure NetApp 文件上的 NFS v4.1 卷
- 若要了解如何在 Azure VM 上建立 SAP HANA 的高可用性和灾难恢复计划,请参阅 Azure VM 上的 SAP HANA 的高可用性。