你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
通过使用 Data Box 设备,可将数据从 Hadoop 群集的本地 HDFS 存储迁移到 Azure 存储(Blob 存储或 Data Lake Storage)。 您可以从 Data Box 磁盘、容量为 80、120 或 525 TiB 的 Data Box 或容量为 770 TiB 的 Data Box Heavy 中进行选择。
本文将帮助你完成以下任务:
- 为迁移数据做准备
- 将数据复制到 Data Box Disk、Data Box 或 Data Box Heavy 设备
- 将设备寄回 Microsoft
- 将访问权限应用于文件和目录(仅限 Data Lake Storage)
先决条件
要完成迁移,你需要准备好以下各项。
一个 Azure 存储帐户。
一个包含源数据的本地 Hadoop 群集。
-
为 Data Box 或 Data Box Heavy 布线并将其连接到本地网络。
如果你准备好了,那我们就开始吧。
将数据复制到 Data Box 设备
如果你的数据刚好能容纳在单台 Data Box 设备中,则将数据复制到该 Data Box 设备。
如果数据大小超出了 Data Box 设备的容量,请使用(可选过程)跨多台 Data Box 设备拆分数据,然后执行此步骤。
若要将数据从本地 HDFS 存储复制到 Data Box 设备,请进行几项设置,然后使用 DistCp 工具。
请按照以下步骤,通过 Blob/对象存储的 REST API 将数据复制到 Data Box 设备。 REST API 接口使设备显示为群集的 HDFS 存储。
通过 REST 复制数据之前,请确定要连接到 Data Box 或 Data Box Heavy 中的 REST 接口的安全性和连接基元。 登录 Data Box 的本地 Web UI,转到“连接并复制”页面。 根据设备的 Azure 存储帐户,在“访问设置”下找到并选择“REST”。

在“访问存储帐户并上传数据”对话框中,复制 Blob 服务终结点和存储帐户密钥 。 省略 Blob 服务终结点中的
https://和尾随斜杠。这样的话,终结点为:
https://mystorageaccount.blob.mydataboxno.microsoftdatabox.com/。 你使用的 URI 的主机部分是:mystorageaccount.blob.mydataboxno.microsoftdatabox.com。 有关示例,请查看如何通过 HTTP 连接到 REST。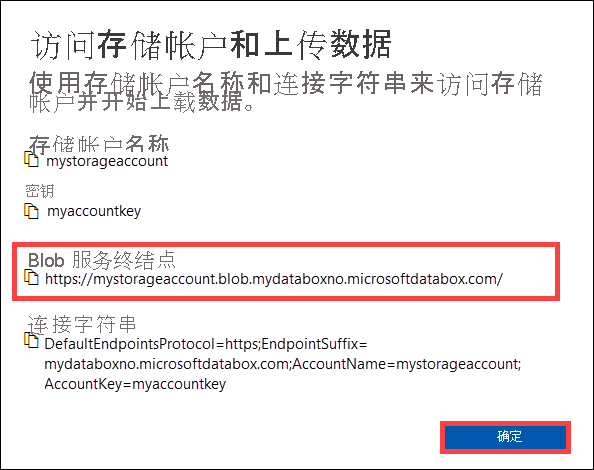
将终结点和 Data Box 或 Data Box Heavy 节点 IP 地址添加到每个节点上的
/etc/hosts。10.128.5.42 mystorageaccount.blob.mydataboxno.microsoftdatabox.com如果要对 DNS 使用其他某种机制,应确保可解析 Data Box 终结点。
将 shell 变量
azjars设为 jar 文件hadoop-azure和azure-storage的位置。 可在 Hadoop 安装目录下找到这些文件。若要确定这些文件是否存在,请使用以下命令:
ls -l $<hadoop_install_dir>/share/hadoop/tools/lib/ | grep azure。 请将<hadoop_install_dir>占位符替换为安装 Hadoop 的目录路径。 请务必使用完全限定的路径。示例:
azjars=$hadoop_install_dir/share/hadoop/tools/lib/hadoop-azure-2.6.0-cdh5.14.0.jarazjars=$azjars,$hadoop_install_dir/share/hadoop/tools/lib/microsoft-windowsazure-storage-sdk-0.6.0.jar创建要用于数据复制的存储容器。 还应指定目标目录,作为此命令的一部分。 目前,它可能是一个虚拟的目标目录。
hadoop fs -libjars $azjars \ -D fs.AbstractFileSystem.wasb.Impl=org.apache.hadoop.fs.azure.Wasb \ -D fs.azure.account.key.<blob_service_endpoint>=<account_key> \ -mkdir -p wasb://<container_name>@<blob_service_endpoint>/<destination_directory>请将
<blob_service_endpoint>占位符替换为 Blob 服务终结点的名称。请将
<account_key>占位符替换为帐户的访问密钥。请将
<container-name>占位符替换为容器的名称。请将
<destination_directory>占位符替换为要将数据复制到的目录的名称。
运行 list 命令,确保容器和目录均已创建。
hadoop fs -libjars $azjars \ -D fs.AbstractFileSystem.wasb.Impl=org.apache.hadoop.fs.azure.Wasb \ -D fs.azure.account.key.<blob_service_endpoint>=<account_key> \ -ls -R wasb://<container_name>@<blob_service_endpoint>/请将
<blob_service_endpoint>占位符替换为 Blob 服务终结点的名称。请将
<account_key>占位符替换为帐户的访问密钥。请将
<container-name>占位符替换为容器的名称。
将数据从 Hadoop HDFS 复制到 Data Box Blob 存储,然后放入前面创建的容器。 如果找不到要复制到的目录,命令会自动创建该目录。
hadoop distcp \ -libjars $azjars \ -D fs.AbstractFileSystem.wasb.Impl=org.apache.hadoop.fs.azure.Wasb \ -D fs.azure.account.key.<blob_service_endpoint<>=<account_key> \ -filters <exclusion_filelist_file> \ [-f filelist_file | /<source_directory> \ wasb://<container_name>@<blob_service_endpoint>/<destination_directory>请将
<blob_service_endpoint>占位符替换为 Blob 服务终结点的名称。请将
<account_key>占位符替换为帐户的访问密钥。请将
<container-name>占位符替换为容器的名称。请将
<exclusion_filelist_file>占位符替换为包含文件排除列表的文件名称。请将
<source_directory>占位符替换为包含要复制的数据的目录名称。请将
<destination_directory>占位符替换为要将数据复制到的目录的名称。
使用
-libjars选项将hadoop-azure*.jar和依赖的azure-storage*.jar文件设为可用于distcp。 对于某些群集,可能已发生此情况。以下示例演示如何使用
distcp命令复制数据。hadoop distcp \ -libjars $azjars \ -D fs.AbstractFileSystem.wasb.Impl=org.apache.hadoop.fs.azure.Wasb \ -D fs.azure.account.key.mystorageaccount.blob.mydataboxno.microsoftdatabox.com=myaccountkey \ -filter ./exclusions.lst -f /tmp/copylist1 -m 4 \ /data/testfiles \ wasb://hdfscontainer@mystorageaccount.blob.mydataboxno.microsoftdatabox.com/data若要提高复制速度:
尝试更改映射器数目。 (映射器的默认数量为 20。上面的示例使用
m= 4 个映射器。)试用
-D fs.azure.concurrentRequestCount.out=<thread_number>。 将<thread_number>替换为每个映射器的线程数。 映射器的数量和每个映射器的线程数m*<thread_number>的乘积不应超过 32。尝试并行运行多个
distcp。请记住,大文件的性能优于小文件。
如果你的文件大于 200 GB,我们建议使用以下参数将块大小更改为 100 MB:
hadoop distcp \ -libjars $azjars \ -Dfs.azure.write.request.size= 104857600 \ -Dfs.AbstractFileSystem.wasb.Impl=org.apache.hadoop.fs.azure.Wasb \ -Dfs.azure.account.key.<blob_service_endpoint<>=<account_key> \ -strategy dynamic \ -Dmapreduce.map.memory.mb=16384 \ -Dfs.azure.concurrentRequestCount.out=8 \ -Dmapreduce.map.java.opts=-Xmx8196m \ -m 4 \ -update \ /data/bigfile wasb://hadoop@mystorageaccount.blob.core.windows.net/bigfile
将 Data Box 寄送到 Microsoft
按照以下步骤准备 Data Box 设备并将其寄送到 Microsoft。
设备准备完成后,下载 BOM 文件。 你使用这些 BOM 或清单文件来验证上传到 Azure 的数据。
关闭设备并拔下电缆。
安排 UPS 取件。
有关 Data Box 设备的信息,请查看寄送 Data Box。
有关 Data Box Heavy 设备的信息,请查看寄送 Data Box Heavy。
Microsoft 收到你的设备后,会将它连接到数据中心网络,数据会被上传到你在设备下单时指定的存储帐户。 根据 BOM 文件验证所有数据是否均已上传到 Azure。
将访问权限应用于文件和目录(仅限 Data Lake Storage)
你已将数据上传到 Azure 存储帐户。 现在,你将应用对文件和目录的访问权限。
注意
仅当使用 Azure Data Lake Storage 作为数据存储时,才需要执行此步骤。 如果只使用不带分层命名空间的 Blob 存储帐户作为数据存储,可跳过此部分。
为启用了 Azure Data Lake Storage 的帐户创建服务主体
若要创建服务主体,请查看如何:使用门户创建可访问资源的 Microsoft Entra 应用程序和服务主体。
执行该文中将应用程序分配给角色部分中的步骤时,请确保将“存储 Blob 数据参与者”角色分配给服务主体。
执行本文获取用于登录的值部分中的步骤时,请将应用程序 ID 和客户端密码值另存到文本文件中。 你很快就会需要这些值。
生成具有相应权限的已复制文件的列表
在本地 Hadoop 群集中,运行以下命令:
sudo -u hdfs ./copy-acls.sh -s /{hdfs_path} > ./filelist.json
此命令会生成具有相应权限的已复制文件的列表。
注意
根据 HDFS 中的文件数,运行此命令可能需要很长时间。
生成标识列表,并将其映射到 Microsoft Entra 标识
下载
copy-acls.py脚本。 请查看本文的下载帮助程序脚本并设置边缘节点以运行它们部分。运行以下命令,生成唯一标识的列表。
./copy-acls.py -s ./filelist.json -i ./id_map.json -g此脚本会生成一个名为
id_map.json的文件,其中包含需要映射到基于 ADD 的标识的标识。在文本编辑器中打开
id_map.json文件。对于文件中显示的每个 JSON 对象,请更新 Microsoft Entra 用户主体名称 (UPN) 或 ObjectId (OID) 的
target属性,使其显示相应已映射的标识。 完成后,保存文件。 下一步需要用到该文件。
将权限应用于已复制的文件并应用标识映射
运行以下命令,将权限应用于你复制到已启用 Data Lake Storage 的帐户中的数据:
./copy-acls.py -s ./filelist.json -i ./id_map.json -A <storage-account-name> -C <container-name> --dest-spn-id <application-id> --dest-spn-secret <client-secret>
将
<storage-account-name>占位符替换为存储帐户的名称。请将
<container-name>占位符替换为容器的名称。将
<application-id>和<client-secret>占位符替换为创建服务主体时收集的应用程序 ID 和客户端密码。
附录:跨多台 Data Box 设备拆分数据
在将数据移动到 Data Box 设备之前,你需要下载一些帮助程序脚本,确保对数据进行整理以将其容纳到一台 Data Box 设备中,并排除所有不必要的文件。
下载帮助程序脚本并设置边缘节点以运行它们
在本地 Hadoop 群集的边缘节点或头节点中,运行以下命令:
git clone https://github.com/jamesbak/databox-adls-loader.git cd databox-adls-loader该命令会克隆包含帮助程序脚本的 GitHub 存储库。
确保已在本地计算机上安装了 jq 包。
sudo apt-get install jq安装 python 包 Requests。
pip install requests设置对所需脚本的执行权限。
chmod +x *.py *.sh
确保已整理数据以适应一台 Data Box 设备
如果数据大小超出了一台 Data Box 设备的大小,可将数据拆分为组,将其存储到多台 Data Box 设备。
如果数据不超过单台 Data Box 设备的容量,可以继续下一部分。
借助提升的权限,按照上一部分中的指南运行已下载的
generate-file-list脚本。命令参数的说明如下:
sudo -u hdfs ./generate-file-list.py [-h] [-s DATABOX_SIZE] [-b FILELIST_BASENAME] [-f LOG_CONFIG] [-l LOG_FILE] [-v {DEBUG,INFO,WARNING,ERROR}] path where: positional arguments: path The base HDFS path to process. optional arguments: -h, --help show this help message and exit -s DATABOX_SIZE, --databox-size DATABOX_SIZE The size of each Data Box in bytes. -b FILELIST_BASENAME, --filelist-basename FILELIST_BASENAME The base name for the output filelists. Lists will be named basename1, basename2, ... . -f LOG_CONFIG, --log-config LOG_CONFIG The name of a configuration file for logging. -l LOG_FILE, --log-file LOG_FILE Name of file to have log output written to (default is stdout/stderr) -v {DEBUG,INFO,WARNING,ERROR}, --log-level {DEBUG,INFO,WARNING,ERROR} Level of log information to output. Default is 'INFO'.将生成的文件列表复制到 HDFS,以便 DistCp 作业可访问这些列表。
hadoop fs -copyFromLocal {filelist_pattern} /[hdfs directory]
排除不必要的文件
你需要从 DisCp 作业中排除某些目录。 例如,排除包含使群集保持运行的状态信息的目录。
在计划启动 DistCp 作业的本地 Hadoop 群集中,创建一个文件来指定要排除的目录列表。
下面是一个示例:
.*ranger/audit.*
.*/hbase/data/WALs.*
后续步骤
了解如何将 Data Lake Storage 与 HDInsight 群集配合使用。 有关详细信息,请参阅将 Azure Data Lake Storage 与 Azure HDInsight 群集配合使用。