你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
重要
Azure Synapse Analytics 数据资源管理器(预览版)将于 2025 年 10 月 7 日停用。 在此日期之后,Synapse 数据资源管理器上运行的工作负荷将被删除,关联的应用程序数据将丢失。 强烈建议迁移到 Microsoft Fabric 中的 Eventhouse 。
Microsoft云迁移工厂(CMF)计划旨在帮助客户迁移到 Fabric。 该计划向客户免费提供动手键盘资源。 这些资源在 6-8 周内分配,并具有预定义和同意的范围。 客户提名可以通过 Microsoft 帐户团队接受,或者直接提交《帮助请求》给 CMF 团队。
数据引入是用于从一个或多个源加载数据记录以将数据导入 Azure Synapse 数据资源管理器池中的表的过程。 摄取后,数据即可用于查询。
负责数据引入的 Azure Synapse 数据资源管理器数据管理服务实现以下过程:
- 从外部源批量拉取数据或流式传输数据,并从挂起的 Azure 队列读取请求。
- 流向同一数据库和表的批处理数据已针对引入吞吐量进行优化。
- 验证初始数据,并在必要时转换格式。
- 进一步的数据操作,包括匹配模式、组织、索引、编码和压缩数据。
- 根据设置的保留策略将数据保存在存储中。
- 引入的数据提交到引擎中,可在其中进行查询。
支持的数据格式、属性和权限
引入属性:影响数据引入方式的属性(例如标记、映射、创建时间)。
权限:若要引入数据,该过程需要 数据库引入器级别权限。 其他作(如查询)可能需要数据库管理员、数据库用户或表管理员权限。
批处理与流式引入
批量引入执行数据批处理,并针对高引入吞吐量进行优化。 此方法是引入的首选且性能最高。 数据根据引入属性进行批处理。 合并并优化了少量数据,以便快速查询结果。 可以在数据库或表上设置 引入批处理 策略。 默认情况下,最大批处理值为 5 分钟、1000 个项目或总大小为 1 GB。 批处理引入命令的数据大小限制为 4 GB。
流式引入是来自流式处理源的正在进行的数据引入。 流式引入针对每个表的小型数据允许近乎实时的延迟。 数据最初引入到行存储,然后移动到列存储盘区。
引入方法和工具
Azure Synapse 数据资源管理器支持多种引入方法,每个方法都有其自己的目标方案。 这些方法包括引入工具、连接器和插件到各种服务、托管管道、使用 SDK 进行编程引入,以及直接访问引入。
使用托管管道的引入
对于希望通过外部服务进行管理(限制、重试、监视、警报等)的组织,使用连接器可能是最合适的解决方案。 排队引入适合大数据量。 Azure Synapse 数据资源管理器支持以下 Azure Pipelines:
- 事件中心:将事件从服务传输到 Azure Synapse 数据资源管理器的管道。 有关详细信息,请参阅 将数据从事件中心引入 Azure Synapse 数据资源管理器。
- Synapse 管道: 用于 Synapse 管道 中分析工作负荷的完全托管数据集成服务与 90 多个受支持的源连接,以提供高效且可复原的数据传输。 Synapse 管道准备、转换和扩充数据,以提供可通过不同方式监视的见解。 此服务可作为一次性解决方案、定期使用或因特定事件而启动。
使用 SDK 的编程引入
Azure Synapse 数据资源管理器提供可用于查询和数据引入的 SDK。 通过最大程度地减少引入过程中和之后的存储事务,对编程引入优化以降低引入成本(COG)。
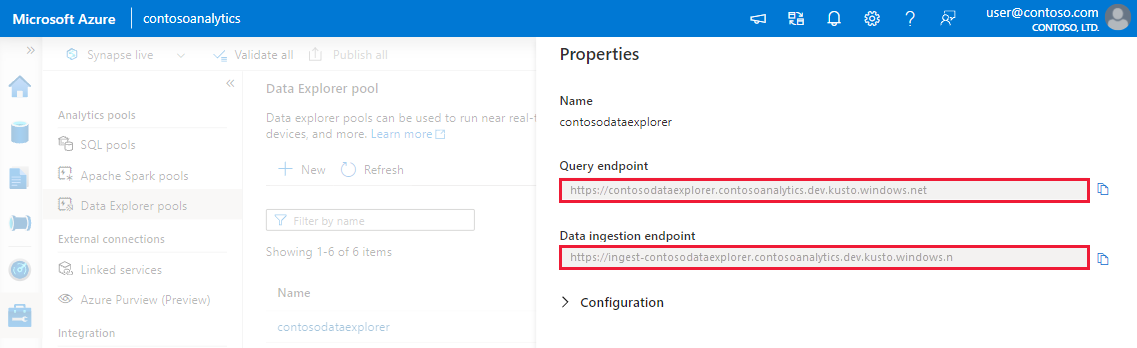
在开始之前,请使用以下步骤获取数据资源管理器池终结点以配置编程引入。
在 Synapse Studio 的左侧窗格中,选择 管理>数据资源管理器池。
选择要用于查看其详细信息的数据资源管理器池。
记下查询和数据引入终结点。 在配置到数据资源管理器池的连接时,请使用查询终结点作为群集。 为数据引入配置 SDK 时,请使用数据引入终结点。
可用的 SDK 和开源项目
工具
- 一键式引入:通过创建和调整各种源类型的表,可以快速引入数据。 一键导入会自动根据 Azure Synapse 数据浏览器中的数据源建议表格和映射结构。 一键式引入可用于一次性引入,或通过将数据引入到的容器上的事件网格定义连续引入。
Kusto 查询语言引入控制命令
有多种方法可以通过 Kusto 查询语言(KQL)命令将数据直接引入引擎。 由于此方法绕过数据管理服务,因此它仅适用于探索和原型制作。 请勿在生产或大容量方案中使用此方法。
内联引入:将控制命令 .ingest inline 发送到引擎,待引入的数据已包含在命令文本中。 此方法旨在用于即兴测试目的。
从查询引入:将控件命令 .set、.append、.set-or-append 或 .set-or-replace 发送到引擎,并将间接指定的数据指定为查询或命令的结果。
从存储引入(拉取):向引擎发送控制命令 .ingest into,数据存储在某个外部存储(例如 Azure Blob 存储)中,可供引擎访问,命令也可以指向它。
有关使用引入控件命令的示例,请参阅 “使用数据资源管理器进行分析”。
引入过程
为需求选择最适合的引入方法后,请执行以下步骤:
设置保留策略
引入 Azure Synapse 数据资源管理器中的表的数据必须遵循该表的有效保留策略。 除非在表上明确进行设置,否则具体的保留策略源自数据库的保留策略。 热保留是群集大小和保留策略的功能。 引入超过可用空间的数据将强制首先进入的数据进行冷保留。
确保数据库的保留策略适合你的需求。 如果并非如此,请在表级别显式重写它。 有关详细信息,请参阅 保留策略。
创建表
若要引入数据,需要事先创建表。 使用以下选项之一:
使用命令创建表。 有关使用创建表命令的示例,请参阅 “使用数据资源管理器分析”。
使用 一键式引入创建表。
注释
如果记录不完整或字段无法分析为所需的数据类型,则相应的表列将填充 null 值。
创建架构映射
架构映射 有助于将源数据字段绑定到目标表列。 通过映射,可以根据定义的属性将数据从不同的源导入同一个表。 支持不同类型的映射,包括面向行的映射(CSV、JSON 和 AVRO),以及面向列的映射(Parquet)。 在大多数方法中,还可以在表上预先创建映射,并从数据导入命令参数中引用映射。
设置更新策略 (可选)
某些数据格式映射(Parquet、JSON 和 Avro)支持简单且有用的引入时间转换。 如果方案需要在引入时进行更复杂的处理,请使用更新策略,以便使用 Kusto 查询语言命令进行轻型处理。 更新策略会自动对原始表上的引入数据运行提取和转换,并将生成的数据引入到一个或多个目标表中。 设置 更新策略。