你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
本文是一个包含七部分内容的系列的第二部分,该系列提供有关如何从 Oracle 迁移到 Azure Synapse Analytics 的指导。 本文的重点是 ETL 和负载迁移的最佳做法。
数据迁移注意事项
在将数据、ETL 和负载从旧版 Oracle 数据仓库和数据集市迁移到 Azure Synapse 时,需要考虑很多因素。
有关从 Oracle 迁移数据的初始决策
规划从现有 Oracle 环境进行的迁移时,请考虑以下与数据相关的问题:
是否应迁移未使用的表结构?
要最大程度地降低用户风险和影响,最佳迁移方法是什么?
迁移数据市场时,是保持物理状态还是转为虚拟状态?
接下来的部分将在从 Oracle 迁移的背景下讨论这些问题。
是否迁移未使用的表?
只迁移正在使用的表格是明智的。 可对非活动状态的表进行存档,而不是迁移,以便将来在需要时可使用这些数据。 若要确定正在使用哪些表,最好使用系统元数据和日志文件(而不是文档),因为文档可能已过时。
Oracle 系统目录表和日志包含的信息可用于确定给定表的上次访问时间,而这些信息又可用于确定表是否适合迁移。
如果已获得 Oracle 诊断包的许可,则可以访问活动会话历史记录,该历史记录可用于确定上次访问表的时间。
提示
在旧系统中,表随着时间推移而变得冗余的情况很常见,在大多数情况下不需要迁移这些表。
下面是一个示例查询,查找给定时间范围内特定表的使用情况:
SELECT du.username,
s.sql_text,
MAX(ash.sample_time) AS last_access ,
sp.object_owner ,
sp.object_name ,
sp.object_alias as aliased_as ,
sp.object_type ,
COUNT(*) AS access_count
FROM v$active_session_history ash
JOIN v$sql s ON ash.force_matching_signature = s.force_matching_signature
LEFT JOIN v$sql_plan sp ON s.sql_id = sp.sql_id
JOIN DBA_USERS du ON ash.user_id = du.USER_ID
WHERE ash.session_type = 'FOREGROUND'
AND ash.SQL_ID IS NOT NULL
AND sp.object_name IS NOT NULL
AND ash.user_id <> 0
GROUP BY du.username,
s.sql_text,
sp.object_owner,
sp.object_name,
sp.object_alias,
sp.object_type
ORDER BY 3 DESC;
如果一直在运行大量查询,则此查询可能需要一段时间才能运行。
若要最大程度地降低用户风险和影响,最佳迁移方法是什么?
这个问题经常出现,因为公司可能希望降低更改对数据仓库数据模型的影响,以提高敏捷性。 在 ETL 迁移过程中,公司通常会看到进一步实现数据现代化或转换的机会。 这种方法具有更高的风险,因为它同时改变了多个因素,从而很难比较新旧系统的结果。 在此处进行数据模型更改也可能会影响其他系统的上游或下游 ETL 作业。 由于存在这种风险,因此最好在数据仓库迁移后于此范围内重新设计。
即使在整体迁移过程中有意更改了数据模型,最好也将现有模型按原样迁移到 Azure Synapse,而不是在新平台上进行任何重新设计。 此方法可最大程度地降低对现有生产系统的影响,同时可利用 Azure 平台的性能和灵活的可伸缩性来完成一次性重新设计任务。
提示
最初按原样迁移现有模型(即使计划将来对数据模型进行更改)。
数据市场迁移:保持物理状态还是转为虚拟状态?
在旧版 Oracle 数据仓库环境中,通常会创建许多数据市场,以便为组织中的给定部门或业务职能的即席自助查询和报表提供良好的性能。 数据市场通常由数据仓库的一部分组成,并包含数据的聚合版本,其形式使用户能够以快速响应时间轻松查询这些数据。 用户可使用用户友好型查询工具(如 Microsoft Power BI),这些工具支持业务用户与数据市场交互。 数据市场中的数据形式通常是一个维度数据模型。 数据市场的一种用途是以可用形式公开数据,即使基础仓库数据模型不同(如数据保管库)。
可以针对组织中各个业务部门使用单独的数据市场,实现可靠的数据安全方案。 仅限访问与用户相关的特定数据市场,并消除、模糊处理或匿名敏感数据。
如果将这些数据市场作为物理表实现,它们将需要额外的存储资源和处理才能定期生成和刷新。 此外,市场中数据的更新情况仅与最后一次刷新操作保持一致,因此可能不适合高度易失的数据仪表板。
提示
将数据市场虚拟化可节省存储和处理资源。
随着成本较低的可缩放 MPP 体系结构(如 Azure Synapse)的出现,及其固有性能特征,你可以提供数据市场功能,而无需将市场实例化为一组物理表。 一种方法是通过 SQL 视图将数据市场有效地直观呈现到主数据仓库。 另一种方法是通过虚拟化层将数据集市虚拟化,可以使用 Azure 中的视图功能或 第三方虚拟化产品。 此方法简化或免去了额外的存储和聚合处理,并减少了要迁移的数据库对象总数。
此方法有另一个潜在好处。 通过在虚拟化层内实现聚合和联接逻辑,并通过虚拟化视图呈现外部报告工具,创建这些视图所需的处理会“向下推送”到数据仓库中。 数据仓库通常是执行联接、聚合以及其他相关操作的大数据环境中最佳平台。
实现虚拟数据市场而不是物理数据市场的主要驱动因素包括:
更加敏捷:虚拟数据市场比物理表和关联的 ETL 流程更易于更改。
总拥有成本更低:虚拟化实现需要的数据存储和数据副本更少。
无需使用 ETL 作业即可在虚拟化环境中迁移和简化数据仓库体系结构。
性能:尽管物理数据市场历来性能更高,但现在虚拟化产品可实现智能缓存技术来缩小这种差异。
提示
Azure Synapse 的性能和可伸缩性使虚拟化可在不牺牲性能的情况下实现。
从 Oracle 迁移数据
了解数据
计划迁移时应详细了解要迁移的数据量,因为这可能影响有关迁移方法的决策。 使用系统元数据来确定要迁移的表内的原始数据会占用的物理空间。 在这种情况下,“原始数据”是指表中数据行使用的空间量,不包括索引和压缩等开销。 最大的事实数据表通常包含 95% 以上的数据。
此查询将提供 Oracle 中的数据库总大小:
SELECT
( SELECT SUM(bytes)/1024/1024/1024 data_size
FROM sys.dba_data_files ) +
( SELECT NVL(sum(bytes),0)/1024/1024/1024 temp_size
FROM sys.dba_temp_files ) +
( SELECT SUM(bytes)/1024/1024/1024 redo_size
FROM sys.v_$log ) +
( SELECT SUM(BLOCK_SIZE*FILE_SIZE_BLKS)/1024/1024/1024 controlfile_size
FROM v$controlfile ) "Size in GB"
FROM dual
数据库大小等于 (data files + temp files + online/offline redo log files + control files) 的大小。 数据库总大小包括已用空间和可用空间。
以下示例查询提供了表数据和索引使用的磁盘空间明细:
SELECT
owner, "Type", table_name "Name", TRUNC(sum(bytes)/1024/1024) Meg
FROM
( SELECT segment_name table_name, owner, bytes, 'Table' as "Type"
FROM dba_segments
WHERE segment_type in ('TABLE','TABLE PARTITION','TABLE SUBPARTITION' )
UNION ALL
SELECT i.table_name, i.owner, s.bytes, 'Index' as "Type"
FROM dba_indexes i, dba_segments s
WHERE s.segment_name = i.index_name
AND s.owner = i.owner
AND s.segment_type in ('INDEX','INDEX PARTITION','INDEX SUBPARTITION')
UNION ALL
SELECT l.table_name, l.owner, s.bytes, 'LOB' as "Type"
FROM dba_lobs l, dba_segments s
WHERE s.segment_name = l.segment_name
AND s.owner = l.owner
AND s.segment_type IN ('LOBSEGMENT','LOB PARTITION','LOB SUBPARTITION')
UNION ALL
SELECT l.table_name, l.owner, s.bytes, 'LOB Index' as "Type"
FROM dba_lobs l, dba_segments s
WHERE s.segment_name = l.index_name
AND s.owner = l.owner
AND s.segment_type = 'LOBINDEX')
WHERE owner in UPPER('&owner')
GROUP BY table_name, owner, "Type"
HAVING SUM(bytes)/1024/1024 > 10 /* Ignore really small tables */
ORDER BY SUM(bytes) desc;
此外,Microsoft 数据库迁移团队还提供许多资源,包括 Oracle 清单脚本项目。 Oracle 清单脚本项目工具包含一个 PL/SQL 查询,该查询访问 Oracle 系统表,并按架构类型、对象类型和状态提供对象计数。 该工具还提供每个架构中原始数据和表大小的粗略估算,结果以 CSV 格式存储。 包含的计算器电子表格将 CSV 用作输入并提供尺寸数据。
对于任何表,都可通过将具有代表性的数据样本(例如,一百万行)提取到未压缩的分隔平面 ASCII 数据文件中,准确地估计需要迁移的数据量。 然后,使用该文件的大小获取每行的平均原始数据大小。 最后,将该平均大小乘以全表中的总行数,得出该表的原始数据大小。 在计划中使用该原始数据大小。
使用 SQL 查询查找数据类型
通过查询 Oracle 静态数据字典 DBA_TAB_COLUMNS 视图,可以确定架构中使用的数据类型以及是否需要更改其中任何数据类型。 使用 SQL 查询可在任何 Oracle 架构中找到数据类型未直接映射到 Azure Synapse 中的数据类型的列。 同样,可使用查询来计算未直接映射到 Azure Synapse 的每种 Oracle 数据类型的出现次数。 通过将这些查询的结果与数据类型比较表结合使用,可确定需要在 Azure Synapse 环境中更改哪些数据类型。
要查找数据类型未映射到 Azure Synapse 中数据类型的列,请在将 <owner_name> 替换为架构的相关所有者后运行以下查询:
SELECT owner, table_name, column_name, data_type
FROM dba_tab_columns
WHERE owner in ('<owner_name>')
AND data_type NOT IN
('BINARY_DOUBLE', 'BINARY_FLOAT', 'CHAR', 'DATE', 'DECIMAL', 'FLOAT', 'LONG', 'LONG RAW', 'NCHAR', 'NUMERIC', 'NUMBER', 'NVARCHAR2', 'SMALLINT', 'RAW', 'REAL', 'VARCHAR2', 'XML_TYPE')
ORDER BY 1,2,3;
若要计算不可映射的数据类型的数量,请使用以下查询:
SELECT data_type, count(*)
FROM dba_tab_columns
WHERE data_type NOT IN
('BINARY_DOUBLE', 'BINARY_FLOAT', 'CHAR', 'DATE', 'DECIMAL', 'FLOAT', 'LONG', 'LONG RAW', 'NCHAR', 'NUMERIC', 'NUMBER', 'NVARCHAR2', 'SMALLINT', 'RAW', 'REAL', 'VARCHAR2', 'XML_TYPE')
GROUP BY data_type
ORDER BY data_type;
Microsoft 提供适用于 Oracle 的 SQL Server 迁移助手 (SSMA),用于自动从旧版 Oracle 环境迁移数据仓库,包括数据类型的映射。 你还可使用 Azure 数据库迁移服务来帮助规划和执行从 Oracle 等环境进行的迁移。 第三方供应商也提供各种工具和服务来自动执行迁移。 如果已在 Oracle 环境中使用第三方 ETL 工具,可使用该工具来实现任何所需的数据转换。 下一部分将探讨现有 ETL 流程的迁移。
ETL 迁移注意事项
有关 Oracle ETL 迁移的初始决策
对于 ETL/ELT 处理,旧版 Oracle 数据仓库通常使用自定义生成的脚本、第三方 ETL 工具或随时间演变的方法组合。 在计划迁移到 Azure Synapse 时,需确定在新环境中实现所需 ETL/ELT 处理的最佳方式,同时还应最大程度地降低成本和风险。
提示
提前计划 ETL 迁移方法,并在适当的情况下利用 Azure 设施。
以下流程图总结了一种方法:
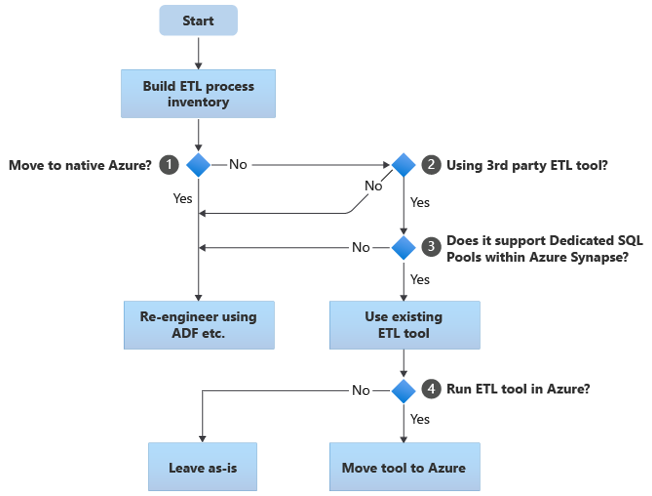
如流程图所示,第一步始终是构建需要迁移的 ETL/ELT 流程清单。 使用标准的内置 Azure 功能时,某些现有流程可能无需移动。 为了进行规划,请务必了解迁移规模。 接下来,请考虑流程图决策树中的问题:
迁移到本机 Azure? 答案取决于你是否要纯粹迁移到 Azure 原生环境。 如果是,建议使用 Azure 数据工厂中的管道和活动或 Azure Synapse 管道重新设计 ETL 处理。
使用第三方 ETL 工具? 如果不是纯粹迁移到 Azure 原生环境,则检查是否已在使用现有的第三方 ETL 工具。 在 Oracle 环境中,你可能会发现部分或全部的 ETL 处理是由自定义脚本(它们使用 Oracle SQL Developer、Oracle SQL*Loader 或 Oracle Data Pump 等特定于 Oracle 的实用工具)执行的。 在这种情况下,方法是使用 Azure 数据工厂重新设计。
第三方是否支持 Azure Synapse 中的专用 SQL 池? 考虑第三方 ETL 工具中是否有大量技能投资,或者现有工作流和计划是否使用该工具。 如果是,请确定该工具能否有效地支持 Azure Synapse 作为目标环境。 理想情况下,该工具将包含本机连接器,这些连接器可以使用 PolyBase 或 COPY INTO 等 Azure 设施进行最高效的数据加载。 但是,即使没有本机连接器,通常也可调用外部进程(例如 PolyBase 或
COPY INTO)并传递适用的参数。 在这种情况下,可使用现有技能和工作流,并将 Azure Synapse 作为新的目标环境。如果使用 Oracle Data Integrator (ODI) 进行 ELT 处理,则需要用于 Azure Synapse 的 ODI 知识模块。 如果这些模块在你的组织中不可用,但你有 ODI,则可以使用 ODI 生成平面文件。 然后,可将这些平面文件移动到 Azure 并引入到 Azure Data Lake Storage,以便加载到 Azure Synapse 中。
在 Azure 中运行 ETL 工具? 如果决定保留现有第三方 ETL 工具,可在 Azure 环境中(而不是在现有本地 ETL 服务器上)运行该工具并让数据工厂处理现有工作流的整个业务流程。 因此,要决定是让现有工具按原样运行还是将其移至 Azure 环境以获得成本、性能和可伸缩性方面的好处。
提示
请考虑在 Azure 中运行 ETL 工具,以利用性能、可伸缩性和成本方面的优势。
重新设计特定于 Oracle 的现有脚本
如果部分或全部的现有 Oracle 仓库 ETL/ELT 处理是由自定义脚本(它们使用 Oracle SQL*Plus、Oracle SQL Developer、Oracle SQL*Loader 或 Oracle Data Pump 等特定于 Oracle 的实用工具)处理的,则需要为 Azure Synapse 环境重新编码这些脚本。 同样,如果已在 Oracle 中使用存储过程实现了 ETL 流程,则需要重新编码这些流程。
ETL 流程的一些元素很容易迁移,例如,通过直接从外部文件将数据批量加载到临时表中。 甚至可以将流程的这些部分自动化,例如,通过 Azure Synapse COPY INTO 或 PolyBase 而不是 SQL*Loader 来实现。 流程中包含任意复杂 SQL 和/或存储过程的其他部分将需要更多时间来重新设计。
提示
要迁移的 ETL 任务的清单应包括脚本和存储过程。
测试 Oracle SQL 是否与 Azure Synapse 兼容的方法之一是从 Oracle v$active_session_history 和 v$sql 的联接中捕获一些具有代表性的 SQL 语句以获得 sql_text,然后在这些查询前加上 EXPLAIN 前缀。 假设在 Azure Synapse 中有一个对等的迁移数据模型,在 Azure Synapse 中运行那些 EXPLAIN 语句。 任何不兼容的 SQL 都将返回错误。 你可使用此信息来确定重编码任务的规模。
提示
使用 EXPLAIN 查找 SQL 的不兼容情况。
在最坏的情况下,可能需要手动重新编码。 但是,Microsoft 合作伙伴提供了一些产品和服务,可帮助重新设计特定于 Oracle 的代码。
提示
合作伙伴提供各种产品和技能来帮助重新设计特定于 Oracle 的代码。
使用现有第三方 ETL 工具
在许多情况下,现有的旧数据仓库系统已由第三方 ETL 产品填充和维护。 请查看 Azure Synapse Analytics 数据集成合作伙伴,获取有关 Azure Synapse 的当前 Microsoft 数据集成合作伙伴列表。
Oracle 社区经常使用几个常用的 ETL 产品。 以下段落讨论了 Oracle 仓库最常用的 ETL 工具。 你可在 Azure 中的 VM 内运行所有这些产品,并使用它们读取和写入 Azure 数据库和文件。
提示
利用对现有第三方工具的投资来降低成本和风险。
从 Oracle 加载数据
从 Oracle 加载数据时的可用选项
准备从 Oracle 数据仓库迁移数据时,请确定如何将数据从现有本地环境物理迁移到云中的 Azure Synapse,以及使用哪些工具来执行传输和加载。 考虑以下问题,这些问题将在后续部分中讨论。
您是会将数据提取到文件,还是直接通过网络连接传输数据?
您是要从源系统还是从 Azure 目标环境主导流程?
将使用哪些工具来自动化和管理迁移过程?
通过文件还是网络连接传输数据?
在 Azure Synapse 中创建要迁移的数据库表后,可以将用于填充这些表的数据移出旧 Oracle 系统,然后移到新环境中。 有两种基本方法:
文件提取:将数据从 Oracle 表中提取到带分隔符的平面文件中,通常采用 CSV 格式。 可通过多种方式提取表数据:
- 使用标准 Oracle 工具,例如 SQL*Plus、SQL Developer 和 SQLcl。
- 使用 Oracle Data Integrator (ODI) 生成平面文件。
- 使用数据工厂中的 Oracle 连接器并行卸载 Oracle 表,以便按分区加载数据。
- 使用第三方 ETL 工具。
有关如何提取 Oracle 表数据的示例,请参阅附录一文。
这种方法需要空间来放置提取的数据文件。 此空间可以是 Oracle 源数据库的本地空间(如果有足够的存储空间),也可以是 Azure Blob 存储的远程空间。 在本地写入文件时,可实现最佳性能,因为这样避免了网络开销。
若要最大程度地减少存储和网络传输需求,请使用 gzip 等实用工具压缩提取的数据文件。
提取后,将平面文件移动到 Azure Blob 存储。 Microsoft 提供了各种用于移动大量数据的选项,包括:
- AzCopy,用于跨网络将文件移动到 Azure 存储。
- Azure ExpressRoute,用于通过专用网络连接移动批量数据。
- Azure Data Box,用于将文件移到你寄送至 Azure 数据中心的物理存储设备进行加载。
有关详细信息,请参阅将数据传入和传出 Azure。
通过网络直接提取和加载:目标 Azure 环境将数据提取请求(通常通过 SQL 命令)发送到旧版 Oracle 系统以提取数据。 结果通过网络发送并直接加载到 Azure Synapse,而无需将数据放置到中间文件中。 通常,此方案的限制因素在于 Oracle 数据库与 Azure 环境之间的网络连接带宽。 对于数据量异常大的情况,此方法可能不实用。
提示
了解要迁移的数据量和可用的网络带宽,因为这些因素会影响关于迁移方法的决策。
还有一种利用这两种方法的混合方法。 例如,可以针对较小的维度表和较大的事实数据表样本使用直接网络提取方法,以便在 Azure Synapse 中快速提供测试环境。 对于大量历史事实数据表,可以通过 Azure Data Box 使用文件提取和传输方法。
通过 Oracle 还是 Azure 协调?
迁移到 Azure Synapse 时,建议使用 SSMA 或数据工厂协调从 Azure 环境提取和加载数据的过程。 使用关联的实用工具(如 PolyBase 或 COPY INTO)来实现最高效的数据加载。 此方法受益于内置的 Azure 功能,可减少构建可重用数据加载管道的工作量。 你可使用元数据驱动的数据加载管道自动执行迁移过程。
建议的方法还可最大程度地减少数据加载过程中对现有 Oracle 环境的性能影响,因为管理和加载过程在 Azure 中运行。
现有数据迁移工具
数据转换和移动是所有 ETL 产品的基本功能。 如果已在现有 Oracle 环境中使用数据迁移工具,并且该工具支持将 Azure Synapse 作为目标环境,可考虑使用它来简化数据迁移过程。
即使现在还没有 ETL 工具,Azure Synapse Analytics 数据集成合作伙伴也提供 ETL 工具来简化数据迁移任务。
最后,如果计划使用 ETL 工具,可考虑在 Azure 环境中运行该工具,以利用 Azure 云性能、可伸缩性和成本方面的优势。 此方法还可释放 Oracle 数据中心内的资源。
总结
简而言之,有关将数据和关联的 ETL 流程从 Oracle 迁移到 Azure Synapse 的建议如下:
提前计划,确保迁移操作成功。
尽快生成要迁移的数据和流程的详细清单。
使用系统元数据和日志文件准确了解数据和流程使用情况。 不要依赖文档,因为文档可能已过时。
了解要迁移的数据量,以及本地数据中心和 Azure 云环境之间的网络带宽。
考虑使用 Azure VM 中的 Oracle 实例作为从旧 Oracle 环境卸载迁移的跳板。
利用标准的内置 Azure 功能,最大限度地减少迁移工作负载。
确定并了解在 Oracle 和 Azure 环境中提取和加载数据的最有效工具。 在过程中的每个阶段使用相应的工具。
使用 Azure 设施(例如 Azure 数据工厂)协调和自动化迁移过程,同时最大程度地降低对 Oracle 系统的影响。
附录:提取 Oracle 数据的方法示例
从 Oracle 迁移到 Azure Synapse 时,可使用多种方法提取 Oracle 数据。 下一部分演示如何使用 Oracle SQL Developer 和数据工厂中的 Oracle 连接器提取 Oracle 数据。
使用 Oracle SQL Developer 提取数据
你可使用 Oracle SQL Developer UI 将表数据导出到多种格式(包括 CSV),如以下屏幕截图所示:

其他导出选项包括 JSON 和 XML。 可使用 UI 将一组表名添加到“购物车”,然后将导出应用于购物车中的整组表名:

还可使用 Oracle SQL Developer 命令行 (SQLcl) 导出 Oracle 数据。 此选项支持使用 shell 脚本实现自动化。
对于相对较小的表,如果在通过直接连接提取数据时遇到问题,你可能会发现此方法很有用。
在 Azure 数据工厂中使用 Oracle 连接器进行并行复制
可以使用数据工厂中的 Oracle 连接器并行卸载大型 Oracle 表。 Oracle 连接器提供内置的数据分区,用于从 Oracle 并行复制数据。 可以在复制活动的“源”选项卡中找到数据分区选项。

若要了解如何配置 Oracle 连接器以进行并行复制,请参阅从 Oracle 进行并行复制。
有关数据工厂复制活动性能和可伸缩性的详细信息,请参阅复制活动性能和可伸缩性指南。
后续步骤
若要了解安全访问操作,请参阅本系列中的下一篇文章:Oracle 迁移的安全性、访问权限和操作。