
“数据很宝贵,它的持续时间长于系统本身。”
Tim Berners-Lee
对于几乎任何软件应用程序,数据访问都是重要的部分。 ASP.NET Core 支持各种数据访问选项,包括 Entity Framework Core(以及 Entity Framework 6),并且可使用任何 .NET 数据访问框架。 选择使用哪种数据访问框架,具体取决于应用程序的需求。 从 ApplicationCore 和 UI 项目中提取这些选项,并在基础结构中封装实现详细信息,这有助于生成松散耦合的可测试软件。
Entity Framework Core(适用于关系数据库)
如果要编写需要使用关系数据的新的 ASP.NET Core 应用程序,则 Entity Framework Core (EF Core) 是应用程序访问数据的建议方式。 EF Core 是一种支持 .NET 开发人员将对象保存到数据源或从数据源中保存的对象关系映射程序 (O/RM)。 它不要求提供开发人员通常需要编写的大部分数据访问代码。 与 ASP.NET Core 一样,EF Core 经过完全重新编写以支持模块化跨平台应用程序。 将其添加到应用程序作为 NuGet 包,在应用启动过程中配置它,并在需要的任何位置通过依赖关系注入请求它。
若要将 EF Core 用于 SQL Server,请运行以下 dotnet CLI 命令:
dotnet add package Microsoft.EntityFrameworkCore.SqlServer
若要添加对 InMemory 数据源的支持用于测试,请使用:
dotnet add package Microsoft.EntityFrameworkCore.InMemory
DbContext
要使用 EF Core,需要 DbContext 的子类。 此类可保留表示应用程序将使用的实体集合的属性。 eShopOnWeb 示例包含一个 CatalogContext,其中包含项、品牌和类型的集合:
public class CatalogContext : DbContext
{
public CatalogContext(DbContextOptions<CatalogContext> options) : base(options)
{
}
public DbSet<CatalogItem> CatalogItems { get; set; }
public DbSet<CatalogBrand> CatalogBrands { get; set; }
public DbSet<CatalogType> CatalogTypes { get; set; }
}
DbContext 必须包含一个接受 DbContextOptions 的构造函数,并将此参数传递给基础 DbContext 构造函数。 如果应用程序中只有一个 DbContext,可传递 DbContextOptions 的实例,但是如果有多个 DbContext,则必须使用泛型 DbContextOptions<T> 类型,在 DbContext 类型中作为泛型参数进行传递。
配置 EF Core
在 ASP.NET Core 应用程序中,通常会使用应用程序的其他依赖项在 Program.cs 中配置 EF Core。 EF Core 使用 DbContextOptionsBuilder,它支持多个有用的扩展方法来简化其配置。 若要配置 CatalogContext,使其将 SQL Server 数据库与配置中定义的连接字符串一起使用,需要添加以下代码:
builder.Services.AddDbContext<CatalogContext>(
options => options.UseSqlServer(
builder.Configuration.GetConnectionString("DefaultConnection")));
使用内存中数据库:
builder.Services.AddDbContext<CatalogContext>(options =>
options.UseInMemoryDatabase());
安装 EF Core 后,创建 DbContext 子类型,并将类型添加到应用程序的服务中,然后就可使用 EF Core。 可在需要 DbContext 类型实例的任何服务中请求该实例,并通过 LINQ 开始使用持久化实体,就像它们在集合中一样。 EF Core 负责将 LINQ 表达式转换成 SQL 查询,以存储和检索数据。
可通过配置记录器并确保其级别至少设置为“信息”,查看 EF Core 要执行的查询,如图 8-1 所示。
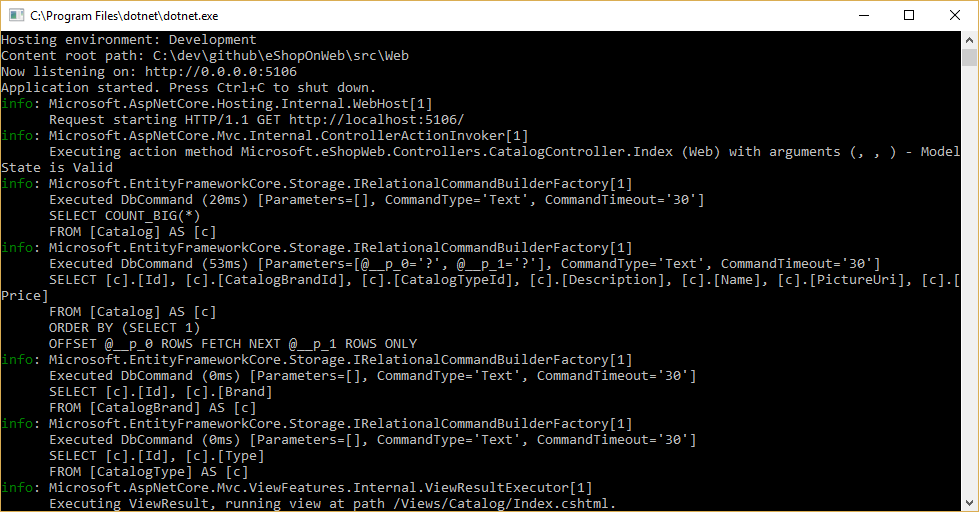
图 8-1。 将 EF Core 查询记录到控制台
提取和存储数据
要从 EF Core 中检索数据,请访问相应的属性,并使用 LINQ 筛选结果。 还可以使用 LINQ 执行投影,将结果从一种类型转换为另一种。 下面的示例会检索 CatalogBrands,这些项按名称排序,按 Enabled 属性进行筛选,并投影到 SelectListItem 类型:
var brandItems = await _context.CatalogBrands
.Where(b => b.Enabled)
.OrderBy(b => b.Name)
.Select(b => new SelectListItem {
Value = b.Id, Text = b.Name })
.ToListAsync();
请务必在上述示例中添加对 ToListAsync 的调用,以立即执行查询。 否则,语句会将 IQueryable<SelectListItem> 分配给 brandItems,后者在被枚举之前不会执行。 从方法中返回 IQueryable 结果有优点,也有缺点。 如果将操作添加到 EF Core 无法转换的查询中,它仍允许对 EF Core 将构造的查询进行进一步修改,但会导致出现仅在运行时发生的错误。 将任何筛选器传递给执行数据访问的方法,并返回内存中集合(例如 List<T>)作为结果,这通常会更安全。
EF Core 可跟踪它从持久性提取的实体上的更改。 要将更改保存到被跟踪实体,只需对 DbContext 调用 SaveChangesAsync 方法,确保它是用于提取实体的同一 DbContext 实例。 直接在 DbSet 属性上完成实体添加和移除操作,同样通过调用 SaveChangesAsync 来执行数据库命令。 下面的示例演示如何从持久性中添加、更新和删除实体。
// create
var newBrand = new CatalogBrand() { Brand = "Acme" };
_context.Add(newBrand);
await _context.SaveChangesAsync();
// read and update
var existingBrand = _context.CatalogBrands.Find(1);
existingBrand.Brand = "Updated Brand";
await _context.SaveChangesAsync();
// read and delete (alternate Find syntax)
var brandToDelete = _context.Find<CatalogBrand>(2);
_context.CatalogBrands.Remove(brandToDelete);
await _context.SaveChangesAsync();
EF Core 同时支持用于提取和保存的同步和异步方法。 在 Web 应用程序中,建议将 async/await 模式与异步方法结合使用,以便在等待数据访问操作完成时不会阻止 Web 服务器线程。
有关详细信息,请参阅缓冲和流式传输。
提取相关数据
EF Core 检索实体时,将填充数据库中直接使用该实体存储的所有属性。 不会填充导航属性(如相关实体列表),且它们的值可能设置为 Null。 此过程可确保 EF Core 仅提取所需的数据,这对 Web 应用程序格外重要,Web 应用程序必须快速处理请求,并以有效的方式返回响应。 要使用预先加载添加与实体的关系,请指定查询上使用 Include 扩展方法的属性,如下所示 :
// .Include requires using Microsoft.EntityFrameworkCore
var brandsWithItems = await _context.CatalogBrands
.Include(b => b.Items)
.ToListAsync();
可添加多种关系,也可使用 ThenInclude 添加子关系。 EF Core 将执行单一查询,检索生成的实体集。 或者,可以通过将“.”分隔的字符串传递给 .Include() 扩展方法来包含导航属性的导航属性,如下所示:
.Include("Items.Products")
除了封装筛选逻辑,规范还可指定要返回的数据的形状,包括要填充的属性。 eShopOnWeb 示例包含几个规范,用于演示如何在规范内封装预先加载信息。 在此处可以查看如何将规范用作查询的一部分:
// Includes all expression-based includes
query = specification.Includes.Aggregate(query,
(current, include) => current.Include(include));
// Include any string-based include statements
query = specification.IncludeStrings.Aggregate(query,
(current, include) => current.Include(include));
加载相关数据的另一个选项是使用显式加载 。 通过显式加载,可以将其他数据加载到已检索的实体中。 由于此方法涉及单独的数据库请求,因此不建议用于 Web 应用程序,Web 应用程序应尽量减少每个请求的数据往返次数。
延迟加载是可在应用程序引用相关数据时自动对其进行加载的一项功能 。 EF Core 2.1 版本中添加了延迟加载支持。 延迟加载默认为不启用,且需要安装 Microsoft.EntityFrameworkCore.Proxies。 与显式加载相同,通常应对 Web 应用禁用延迟加载,因为使用延迟加载将导致在每个 Web 请求内进行额外的数据库查询。 遗憾的是,当延迟较小并且用于测试的数据集通常也较小时,在开发时常常会难以发现延迟加载所产生的开销。 但是,在生产中(涉及更多用户、更多数据和更多延迟),额外的数据库请求常常会导致大量使用延迟加载的 Web 应用性能不佳。
最好在检查应用程序进行的实际数据库查询时测试应用程序。 在某些情况下,EF Core 可能会执行更多或成本更高的查询,而这对于应用程序来说并非是最佳的。 其中一个问题称为笛卡尔爆炸。 EF Core 提供了几种优化运行时行为的方法,其中一种是 AsSplitQuery 方法。
封装数据
EF Core 支持多种功能,使模型能够正确封装其状态。 域模型中的一个常见问题是,它们将集合导航属性公开为可公开访问的列表类型。 此问题使得任何协作方都能操作这些集合类型的内容,这可能会绕过与集合相关的重要业务规则,从而可能使对象处于无效状态。 若要解决该问题,可向相关集合公开只读访问权限,并显式提供一些方法来定义客户端操作这些集合的方式,如本例中所示:
public class Basket : BaseEntity
{
public string BuyerId { get; set; }
private readonly List<BasketItem> _items = new List<BasketItem>();
public IReadOnlyCollection<BasketItem> Items => _items.AsReadOnly();
public void AddItem(int catalogItemId, decimal unitPrice, int quantity = 1)
{
var existingItem = Items.FirstOrDefault(i => i.CatalogItemId == catalogItemId);
if (existingItem == null)
{
_items.Add(new BasketItem()
{
CatalogItemId = catalogItemId,
Quantity = quantity,
UnitPrice = unitPrice
});
}
else existingItem.Quantity += quantity;
}
}
此实体类型不公开公共 List 或 ICollection 属性,而是公开包装有基础列表类型的 IReadOnlyCollection 类型。 使用此模式时,可以指示 Entity Framework Core 使用支持字段,如下所示:
private void ConfigureBasket(EntityTypeBuilder<Basket> builder)
{
var navigation = builder.Metadata.FindNavigation(nameof(Basket.Items));
navigation.SetPropertyAccessMode(PropertyAccessMode.Field);
}
还有一种可改进域模型的方法是对缺少标识且仅通过属性进行区分的类型使用值对象。 使用这些类型作为实体的属性有助于将逻辑特定于它所属的值对象,并且可以避免使用相同概念的多个实体之间的逻辑重复。 在 Entity Framework Core 中,可以通过将类型配置为从属实体来将值对象保存在与其所属实体相同的表中,如下所示:
private void ConfigureOrder(EntityTypeBuilder<Order> builder)
{
builder.OwnsOne(o => o.ShipToAddress);
}
在此示例中,ShipToAddress 属性的类型为 Address。
Address 是一个具有多个属性的值对象,例如 Street 和 City。 EF Core 将 Order 对象映射到其表中,每个 Address 属性有一列,每个列名前面都加有该属性的名称。 在此示例中,Order 表将包含 ShipToAddress_Street 和 ShipToAddress_City 等列。 如果需要,也可以将从属类型存储在单独的表中。
详细了解 EF Core 中的从属实体支持。
弹性连接
外部资源(如 SQL 数据库)偶尔可能不可用。 如果暂时不可用,应用程序可使用重试逻辑避免引发异常。 此方法通常称为连接弹性 。 可以实现指数退避算法的重试技术,方法是尝试重试,等待时间呈指数级增长,直到达到最大重试次数。 该技术接受以下事实:云资源可能出现短时间间歇性不可用情况,导致某些请求失败。
对于 Azure SQL DB,Entity Framework Core 早已提供了内部数据库连接复原和重试逻辑。 但如果想要复原 EF Core 连接,则需要为每个 DbContext 连接启用 Entity Framework 执行策略。
例如,EF Core 连接级别的下列代码可启用复原 SQL 连接,此连接在连接失败时会重试。
builder.Services.AddDbContext<OrderingContext>(options =>
{
options.UseSqlServer(builder.Configuration["ConnectionString"],
sqlServerOptionsAction: sqlOptions =>
{
sqlOptions.EnableRetryOnFailure(
maxRetryCount: 5,
maxRetryDelay: TimeSpan.FromSeconds(30),
errorNumbersToAdd: null);
}
);
});
使用 BeginTransaction 和多个 DbContext 的执行策略和显式事务
在 EF Core 连接中启用重试时,使用 EF Core 执行的每项操作都会成为其自己的可重试操作。 如果发生暂时性故障,每个查询和 SaveChangesAsync 的每次调用都会作为一个单元进行重试。
但是,如果代码使用 BeginTransaction 启动事务,这表示在定义一组自己的操作,这些操作需要被视为一个单元;如果发生故障,事务内的所有内容都会回退。 如果在使用 EF 执行策略(重试策略)时尝试执行该事务,并且事务中包含一些来自多个 DbContext 的 SaveChangesAsync,则你会看到如下所示的异常。
System.InvalidOperationException:已配置的执行策略 SqlServerRetryingExecutionStrategy 不支持用户发起的事务。 使用由 DbContext.Database.CreateExecutionStrategy() 返回的执行策略来执行事务(充当一个可重试单元)中的所有操作。
该解决方案通过代表所有需要执行的委托来手动调用 EF 执行策略。 如果发生暂时性故障,执行策略会再次调用委托。 下面的代码演示如何实现此方法:
// Use of an EF Core resiliency strategy when using multiple DbContexts
// within an explicit transaction
// See:
// https://learn.microsoft.com/ef/core/miscellaneous/connection-resiliency
var strategy = _catalogContext.Database.CreateExecutionStrategy();
await strategy.ExecuteAsync(async () =>
{
// Achieving atomicity between original Catalog database operation and the
// IntegrationEventLog thanks to a local transaction
using (var transaction = _catalogContext.Database.BeginTransaction())
{
_catalogContext.CatalogItems.Update(catalogItem);
await _catalogContext.SaveChangesAsync();
// Save to EventLog only if product price changed
if (raiseProductPriceChangedEvent)
{
await _integrationEventLogService.SaveEventAsync(priceChangedEvent);
transaction.Commit();
}
}
});
第一个 DbContext 是 _catalogContext,第二个 DbContext 位于 _integrationEventLogService 对象中。 最后,“提交”操作将执行多个 DbContext,并使用 EF 执行策略。
引用 - Entity Framework Core
- EF Core 文档https://learn.microsoft.com/ef/
- EF Core:相关数据https://learn.microsoft.com/ef/core/querying/related-data
- 避免延迟加载 ASPNET 应用程序中的实体https://ardalis.com/avoid-lazy-loading-entities-in-asp-net-applications
选择 EF Core 还是微型 ORM?
尽管对于管理持久性以及在大多数情况下封装应用程序开发者提供的数据库详细信息而言,EF Core 是绝佳选择,但它不是唯一的选择。 另一个热门的开源替代选择是一种所谓的微型 ORM,即 Dapper。 微型 ORM 是不具有完整功能的轻量级工具,用于将对象映射到数据结构。 Dapper 在设计上主要关注性能,而不是完全封装用于检索和更新数据的基础查询。 因为它不提取开发人员的 SQL,Dapper“更接近于原型”,使开发人员可以编写要用于给定数据访问操作的确切查询。
EF Core 具有两个重要功能,使其有别于 Dapper ,并且增加其性能开销。 第一个功能是从 LINQ 表达式转换为 SQL。 将缓存这些转换,但即便如此,首次执行它们时仍会产生开销。 第二个功能是对实体进行更改跟踪(以便生成高效的更新语句)。 通过使用 AsNoTracking 扩展,可对特定查询关闭此行为。 EF Core 还会生成通常非常高效的 SQL 查询,并且从性能角度上看,任何情况下都能完全接受,但如果需要执行对精确查询的精细化控制,也可使用 EF Core 传入自定义 SQL(或执行存储过程)。 在这种情况下,Dapper 的性能仍然优于 EF Core,但只有略微优势。 可访问 Dapper 网站,查看各种数据访问方法的当前性能基准数据。
要查看 Dapper 与 EF Core 语法之间的差异,请考虑用于检索一系列项目的相同方法的两个版本:
// EF Core
private readonly CatalogContext _context;
public async Task<IEnumerable<CatalogType>> GetCatalogTypes()
{
return await _context.CatalogTypes.ToListAsync();
}
// Dapper
private readonly SqlConnection _conn;
public async Task<IEnumerable<CatalogType>> GetCatalogTypesWithDapper()
{
return await _conn.QueryAsync<CatalogType>("SELECT * FROM CatalogType");
}
要使用 Dapper 生成更复杂的对象图,需要自行编写相关的查询(这与在 EF Core 中添加 Include 不同)。 此功能受到多种语法支持,包括称为“多映射”的功能,使用该功能可以将各个行映射到多个映射对象中。 例如,给定一个类 Post,其中“所有者”属性是“用户”类型,以下 SQL 将返回所有必要的数据:
select * from #Posts p
left join #Users u on u.Id = p.OwnerId
Order by p.Id
返回的每行同时包括“用户”和“Post”数据。 由于“用户”数据应通过其“所有者”属性附加到 Post 数据,因此使用下面的函数:
(post, user) => { post.Owner = user; return post; }
返回 post 集合的完整代码列表(其中使用相关的用户数据填充其“所有者”属性)为:
var sql = @"select * from #Posts p
left join #Users u on u.Id = p.OwnerId
Order by p.Id";
var data = connection.Query<Post, User, Post>(sql,
(post, user) => { post.Owner = user; return post;});
因为它提供较少封装,Dapper 要求开发人员深入了解如何存储其数据,如何对其进行高效查询,以及如何编写更多代码来提取它。 模型发生更改时,不是单纯地创建新的迁移(另一种 EF Core 功能),并/或在 DbContext 的某一位置更新映射信息,而是必须更新受影响的所有查询。 这些查询没有编译时间保证,因此它们可能在运行时中断,以应对模型或数据库的更改,增加快速检测错误的难度。 Dapper 可提供极快的性能,以补偿这些方面付出的代价。
对于大多数应用程序和几乎所有应用程序的大多数组件而言,EF Core 提供可接受的性能。 因此,其开发人员工作效率优势很可能大于性能开销这一点上的劣势。 对于可受益于缓存的查询,实际查询执行的时间可能只占很小的百分比,因此可以忽略较小的查询性能差异。
选择 SQL 还是 NoSQL
传统上,SQL Server 等关系数据库占领了持久性数据存储的市场,但它们不是唯一可用的解决方案。 NoSQL 数据库(如 MongoDB)可提供用于存储对象的不同方法。 另一种选择是序列化整个对象图并存储结果,而不是将对象映射到表格和行。 此方法的优点(至少在起初阶段)是简单和高性能。 使用密钥存储单个序列化对象当然比将对象分解为多个表格(其中的关系以及更新和行可能自上次从数据库中检索该对象以来已更改)更简单。 同样,从基于密钥的存储中提取和反序列化单个对象通常比复杂联接或多个数据库查询(完全编写关系数据库中的相同对象所需)更快速、更简单。 此外,由于缺少锁定、事务或固定的架构,这使得 NoSQL 数据库适合在多台计算机中缩放,以支持大型数据集。
但是,NoSQL 数据库(人们通常这么称呼该数据库)也有其缺点。 关系数据库利用规范化强制实施一致性并避免数据重复。 此方法可减少数据库的总大小,确保共享数据更新在整个数据库中立即可用。 在关系数据库中,“地址”表可能按 ID 引用“国家/地区”表,这样一来,如果国家/地区名称发生更改,地址记录将受益于更新,而无需自行更新。 但是,对于 NoSQL 数据库,众多存储对象中的“地址”及其相关的“国家/地区”可能会被序列化。 如果对国家/地区或区域名称进行更新,将需要更新所有此类对象,而不是单独的某行。 关系数据库还可通过强制实施外键等规则,确保关系完整性。 NoSQL 数据库通常不提供此类数据约束。
NoSQL 数据库需要处理的另一复杂性是版本控制。 对象的属性发生更改时,可能无法从存储的过去版本进行反序列化。 因此,需要更新具有对象的序列化(以前)版本的所有现有对象,才能符合其新架构。 从概念上讲,此方法与关系数据库没有什么差异,架构更改有时需要更新脚本或映射更新。 但是,需要修改的条目数量通常多于 NoSQL 方法,因为存在更多的重复数据。
可以在 NoSQL 数据库中存储多个对象版本,而这是固定架构关系数据库通常不支持的功能。 但是,在这种情况下,应用程序代码需要考虑以前对象版本的存在,这增加了额外的复杂性。
NoSQL 数据库通常不会强制实施 ACID,这意味着它在性能和可伸缩性方面优于关系数据库。 它们非常适合特别大型的数据集和对象,不适合规范化表格结构中的存储。 根据最适合的情景分别加以利用,单个应用程序能同时获得关系数据库和 NoSQL 数据库带来的好处。
Azure Cosmos DB(Azure 宇宙数据库)
Azure Cosmos DB 是一项完全托管的 NoSQL 数据库服务,可提供基于云的无架构数据存储。 Azure Cosmos DB 旨在实现快速且可预测性能、高可用性、弹性缩放和全球分发。 尽管属于 NoSQL 数据库,但开发人员可对 JSON 数据使用熟悉的一系列 SQL 查询功能。 Azure Cosmos DB 中的所有资源均存储为 JSON 文档。 资源作为“项目”(包含元数据的文档)和“源”(项目集合)管理 。 图 8-2 显示了不同 Azure Cosmos DB 资源之间的关系。

图 8-2。 Azure Cosmos DB 资源组织。
Azure Cosmos DB 查询语言是一种用于查询 JSON 文档的简单而强大的接口。 该语言支持 ANSI SQL 语法的子集,并添加了对 JavaScript 对象、数组、对象结构和函数调用的深度集成。
参考 – Azure Cosmos DB
- Azure Cosmos DB 简介 https://learn.microsoft.com/azure/cosmos-db/introduction
其他持久性选项
除关系数据库和 NoSQL 数据库存储选项外,ASP.NET Core 应用程序还可使用 Azure 存储,以基于云的可缩放方式存储各种数据格式和文件。 Azure 存储可大规模缩放,因此如果应用程序需要存储少量数据并纵向扩展到存储数百或 TB 级数据,可采用 Azure 存储。 Azure 存储支持四种数据:
适用于非结构化文本或二进制储存的 Blob 存储,也称为对象存储。
适用于结构化数据集的表存储,可通过行键进行访问。
适用于可靠且基于队列的消息传送的队列存储。
适用于 Azure 虚拟机和本地应用程序之间的共享文件访问的文件存储。
参考 – Azure 存储
缓存
在 Web 应用程序中,应尽可能在最短的时间内完成每个 Web 请求。 实现此功能的一种方法是限制服务器完成请求必须进行的外部调用次数。 缓存涉及在服务器上存储数据副本(或比数据源更易于查询的其他数据存储)。 Web 应用程序,特别是非 SPA 传统 Web 应用程序,需要对每个请求生成整个用户界面。 此方法通常需要从一个用户请求到下一个用户请求,重复进行多个相同的数据库查询。 在大多数情况下,此类数据很少更改,因此没有必要不断地从数据库进行请求。 ASP.NET Core 支持响应缓存,用于缓存整个页面,以及数据缓存(可支持更精细的缓存行为)。
实现缓存时,请务必记住将问题分离。 避免在数据访问逻辑或用户界面中实现缓存逻辑。 应将缓存封装于其自己的类中,并使用配置管理其行为。 此方法遵循打开/关闭和单一责任原则,以便用户更轻松地随着应用程序发展管理应用程序的缓存使用方式。
ASP.NET Core 响应缓存
ASP.NET Core 支持两种级别的响应缓存。 第一种级别不会在服务器上缓存任何内容,但会向缓存响应添加指示客户端和代理服务器的 HTTP 标头。 实现此功能的方法是通过向各个控制器或操作添加 ResponseCache 属性:
[ResponseCache(Duration = 60)]
public IActionResult Contact()
{
ViewData["Message"] = "Your contact page.";
return View();
}
上述示例将导致将以下标头添加到响应,同时指示客户端缓存结果(最长 60 秒)。
Cache-Control: public,max-age=60
若要将服务器端内存中缓存添加到应用程序,必须引用 Microsoft.AspNetCore.ResponseCaching NuGet 包,然后添加响应缓存中间件。 该中间件在应用启动过程中配置了服务和中间件:
builder.Services.AddResponseCaching();
// other code omitted, including building the app
app.UseResponseCaching();
响应缓存中间件将根据一组可自定义的条件自动缓存响应。 默认情况下,仅缓存通过 GET 或 HEAD 方法请求的 200(正常)响应。 此外,请求必须具有包含缓存控件(公共标头)的响应,且不能包含授权标头或 Set-Cookie。 请参阅响应缓存中间件所用缓存条件的完整列表。
数据缓存
可以缓存各个数据查询的结果,而不是(或除了)缓存完整 web 响应。 对于此功能,可对 Web 服务器使用内存中缓存,或使用分布式缓存。 本节将演示如何实现内存中缓存。
使用以下代码添加对内存(或分布式)缓存的支持:
builder.Services.AddMemoryCache();
builder.Services.AddMvc();
请确保也添加 Microsoft.Extensions.Caching.Memory NuGet 包。
添加服务后,可在需要访问缓存的任何位置,通过依赖关系注入请求 IMemoryCache。 在此示例中,CachedCatalogService 将使用“代理”(或“修饰器”)设计模式,方法是通过提供控制对基础 ICatalogService 实现的访问权限(或向其添加行为)的 CatalogService 的备用实现。
public class CachedCatalogService : ICatalogService
{
private readonly IMemoryCache _cache;
private readonly CatalogService _catalogService;
private static readonly string _brandsKey = "brands";
private static readonly string _typesKey = "types";
private static readonly TimeSpan _defaultCacheDuration = TimeSpan.FromSeconds(30);
public CachedCatalogService(
IMemoryCache cache,
CatalogService catalogService)
{
_cache = cache;
_catalogService = catalogService;
}
public async Task<IEnumerable<SelectListItem>> GetBrands()
{
return await _cache.GetOrCreateAsync(_brandsKey, async entry =>
{
entry.SlidingExpiration = _defaultCacheDuration;
return await _catalogService.GetBrands();
});
}
public async Task<Catalog> GetCatalogItems(int pageIndex, int itemsPage, int? brandID, int? typeId)
{
string cacheKey = $"items-{pageIndex}-{itemsPage}-{brandID}-{typeId}";
return await _cache.GetOrCreateAsync(cacheKey, async entry =>
{
entry.SlidingExpiration = _defaultCacheDuration;
return await _catalogService.GetCatalogItems(pageIndex, itemsPage, brandID, typeId);
});
}
public async Task<IEnumerable<SelectListItem>> GetTypes()
{
return await _cache.GetOrCreateAsync(_typesKey, async entry =>
{
entry.SlidingExpiration = _defaultCacheDuration;
return await _catalogService.GetTypes();
});
}
}
若要配置应用程序来使用服务的缓存版本,但仍允许服务获取其构造函数中需要的 CatalogService 的实例,请在 Program.cs 中添加以下行:
builder.Services.AddMemoryCache();
builder.Services.AddScoped<ICatalogService, CachedCatalogService>();
builder.Services.AddScoped<CatalogService>();
完成以上代码后,将每分钟执行一次提取目录数据的数据库调用,而不是对每个请求执行。 这可能对向数据库提出的查询数,以及当前依赖于此服务公开的所有三个查询的主页平均加载时间产生非常大的影响,具体取决于网站的流量。
缓存实现时将引发的问题是“数据过时” 。也就是说,源中的数据已经更改,但缓存中保留的是过期版本的数据。 缓解此问题的简单方法是使用较短的缓存持续时间,因此对于一个繁忙的应用程序而言,延长数据缓存时长的其他好处非常有限。 例如,假设有一个进行单一数据库查询的网页,每秒对其请求 10 次。 如果此网页缓存一分钟,每分钟执行的数据库查询数将从 600 降为 1,减少了 99.8%。 如果缓存持续时间改为 1 小时,将整体减少 99.997%,但此时过时数据的可能性和潜在期限都可能大幅增加。
另一种方法是在包含的数据更新时主动删除缓存条目。 如果其键已知,可删除任何条目:
_cache.Remove(cacheKey);
如果应用程序公开用于更新其缓存的条目的功能,可在执行更新的代码中删除相应的缓存条目。 有时可能存在众多不同的条目,具体取决于特定数据集。 在这种情况下,使用 CancellationChangeToken 创建缓存条目之间的依赖关系可能非常有用。 使用 CancellationChangeToken,可通过取消令牌同时使多个缓存条目过期。
// configure CancellationToken and add entry to cache
var cts = new CancellationTokenSource();
_cache.Set("cts", cts);
_cache.Set(cacheKey, itemToCache, new CancellationChangeToken(cts.Token));
// elsewhere, expire the cache by cancelling the token\
_cache.Get<CancellationTokenSource>("cts").Cancel();
缓存可以显著提高从数据库重复请求相同值的网页的性能。 请确保在应用缓存前测量数据访问和页面性能,并且仅在发现需要改进性能时才应用缓存。 缓存使用 Web 服务器内存资源并增加应用程序的复杂性,因此,不要过早使用此技术进行优化。
将数据获取到 BlazorWebAssembly 应用
如果要构建使用 Blazor Server 的应用,则可以使用实体框架和其他直接数据访问技术,如本章前面的内容所述。 但是,如果要构建 BlazorWebAssembly 应用(例如其他 SPA 框架),则需要不同的数据访问策略。 通常,这些应用程序通过 Web API 终结点访问数据并与服务器交互。
如果正在执行的数据或操作是敏感的,请务必查看上一章中有关安全性的部分,并保护 API 免受未经授权的访问。
可以在 BlazorAdmin 项目的 Blazor中找到 WebAssembly 应用的示例。 该项目托管在 eShopOnWeb Web 项目中,并允许 Administrators 组中的用户管理商店中的产品。 可以在图 8-3 中看到该应用程序的屏幕截图。
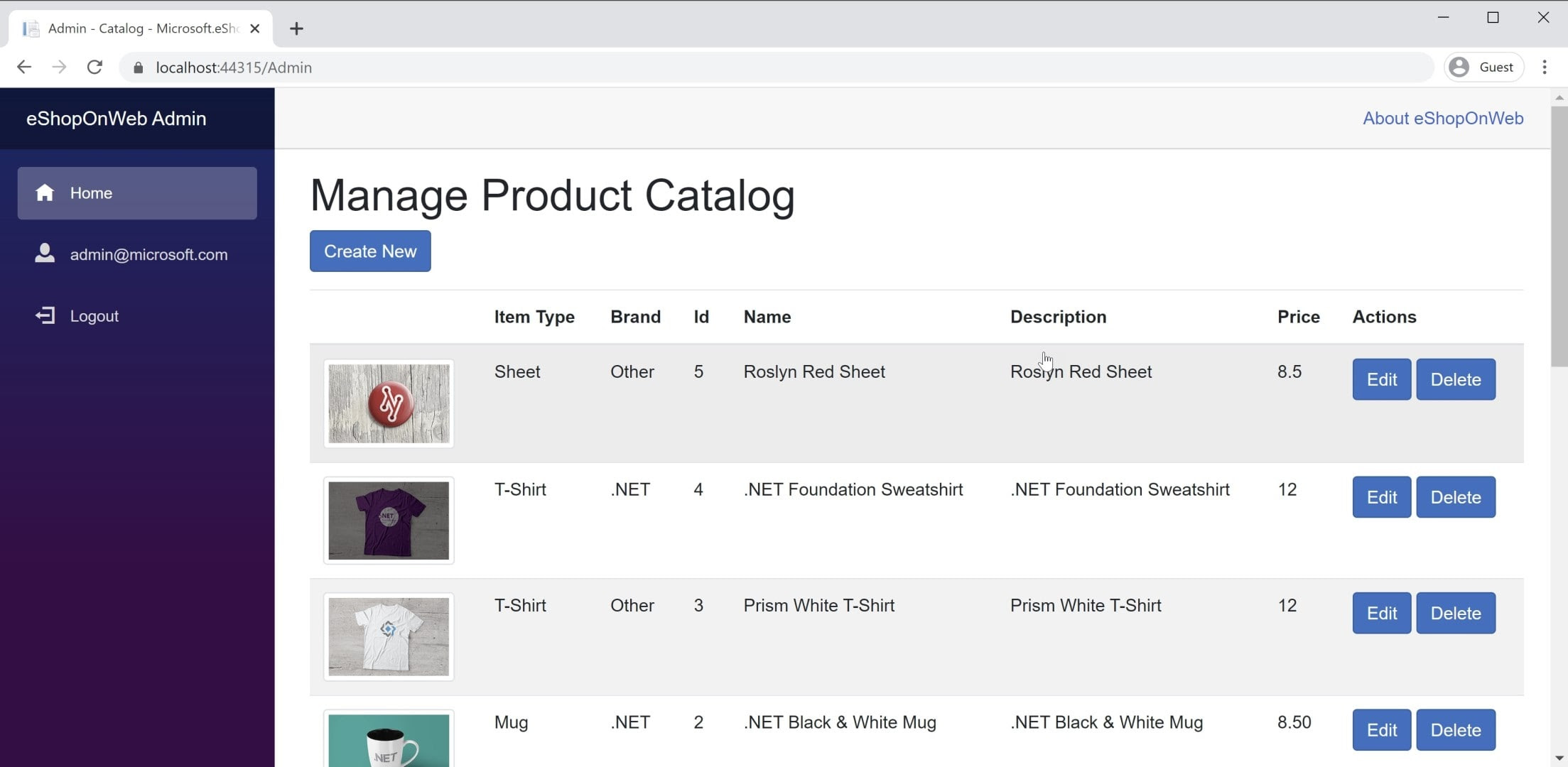
图 8-3。 eShopOnWeb 目录管理屏幕截图。
从 BlazorWebAssembly 应用中的 Web API 提取数据时,就像在任何 .NET 应用程序中操作一样,只需使用 HttpClient 的实例。 涉及的基本步骤包括创建要发送的请求(如有必要,通常是 POST 或 PUT 请求)、等待请求本身、验证状态代码,然后反序列化响应。 如果要对一组给定的 API 发出许多请求,最好封装 API 并集中配置 HttpClient 基址。 这样,如果需要在环境之间调整任何这些设置,只需在一个地方进行更改即可。 应在 Program.Main 中添加对此服务的支持:
builder.Services.AddScoped(sp => new HttpClient
{
BaseAddress = new Uri(builder.HostEnvironment.BaseAddress)
});
如果需要安全地访问服务,则应访问安全令牌并配置 HttpClient,以在每次请求时将此令牌作为身份验证标头传递:
_httpClient.DefaultRequestHeaders.Authorization =
new AuthenticationHeaderValue("Bearer", token);
只要没有在 HttpClient 的生命周期内将 HttpClient 添加到应用程序的服务中,就可以从注入了 Transient 的任何组件中完成此活动。 应用程序中对 HttpClient 的每个引用都引用相同的实例,因此只需在整个应用程序的一个组件流中对其进行更改。 共享组件(例如站点的主导航)是执行此身份验证检查(紧接着指定令牌)的理想位置。 如需详细了解此方法,请参阅 BlazorAdmin的 BlazorAdmin 项目。
与传统的 JavaScript SPA 相比,BlazorWebAssembly 的一个好处是不需要保持数据传输对象 (DTO) 的副本同步。 Blazor WebAssembly 项目和 Web API 项目可以在通用的共享项目中共享相同的 DTO。 此方法避免了开发 SPA 所涉及的一些麻烦。
若要快速从 API 终结点获取数据,可以使用内置的帮助程序方法 GetFromJsonAsync。 也有用于 POST、PUT 等的类似方法。下面显示了如何使用 HttpClientBlazor 应用中配置的 WebAssembly 从 API 终结点获取 CatalogItem:
var item = await _httpClient.GetFromJsonAsync<CatalogItem>($"catalog-items/{id}");
获得所需数据后,通常在本地跟踪更改。 如何希望更新后端数据存储,可调用其他 Web API,以实现此目的。
引用 - Blazor 数据
- 从 ASP.NET Core Blazorhttps://learn.microsoft.com/aspnet/core/blazor/call-web-api 调用 Web API