适用于:✅ Fabric Data Engineering and Data Science
借助 Fabric Livy API,可以将 Spark 批处理和会话作业直接从远程客户端提交到 Fabric Spark 计算,而无需使用Fabric门户。 在本文中,你将创建一个 Lakehouse,使用Microsoft Entra令牌进行身份验证,发现 Livy API 终结点,并提交和监视 Spark 会话作业。
先决条件
使用 Lakehouse Fabric Premium 或 试用容量
为 Livy API 启用租户管理员设置
具有 Jupyter 笔记本支持、PySpark 和适用于 Python 的 Microsoft Authentication Library (MSAL) 的远程客户端,例如 Visual Studio Code。
要么是 Microsoft Entra 应用令牌。 在 Microsoft Identity 平台上注册应用程序
或者Microsoft Entra SPN(服务主体)令牌。 在 Microsoft Entra ID 中添加和管理应用凭据
选择 REST API 客户端
可以从任何支持 HTTP 请求的客户端与 Livy API 进行交互,包括 curl 之类的工具或 HTTP 库的任何语言。 本文中的示例将 Visual Studio Code 与 Jupyter Notebooks、PySpark 和 Microsoft Authentication Library (MSAL) 用于 Python。
如何授权 Livy API 请求
若要使用 Livy API,需要使用 Microsoft Entra ID对请求进行身份验证。 有两种授权方法可用:
Entra SPN Token (服务主体):应用程序使用客户端机密或证书等凭据自行进行身份验证。 此方法适用于无需用户交互的自动化过程和后台服务。
Entra 应用令牌 (委托):应用程序在已登录用户的权限下执行操作。 如果希望应用程序访问具有经过身份验证的用户权限的资源,则此方法适用。
选择最适合你的方案的授权方法,并遵循下面的相应部分。
如何使用 Microsoft Entra SPN 令牌授权 Livy API 请求
若要使用包括 Livy API 在内的Fabric API,首先需要创建Microsoft Entra应用程序,并在代码中创建机密并使用该机密。 应用程序需要进行充分注册和配置,以便针对Fabric执行 API 调用。 有关详细信息,请参阅
创建应用注册后,创建客户端密码。
创建客户端密码时,请确保复制该值。 稍后在代码中需要此密钥,但此密钥将不再可见。 除了代码中的机密外,还需要应用程序(客户端)ID 和目录(租户 ID)。
接下来,将服务主体添加到您的工作区。
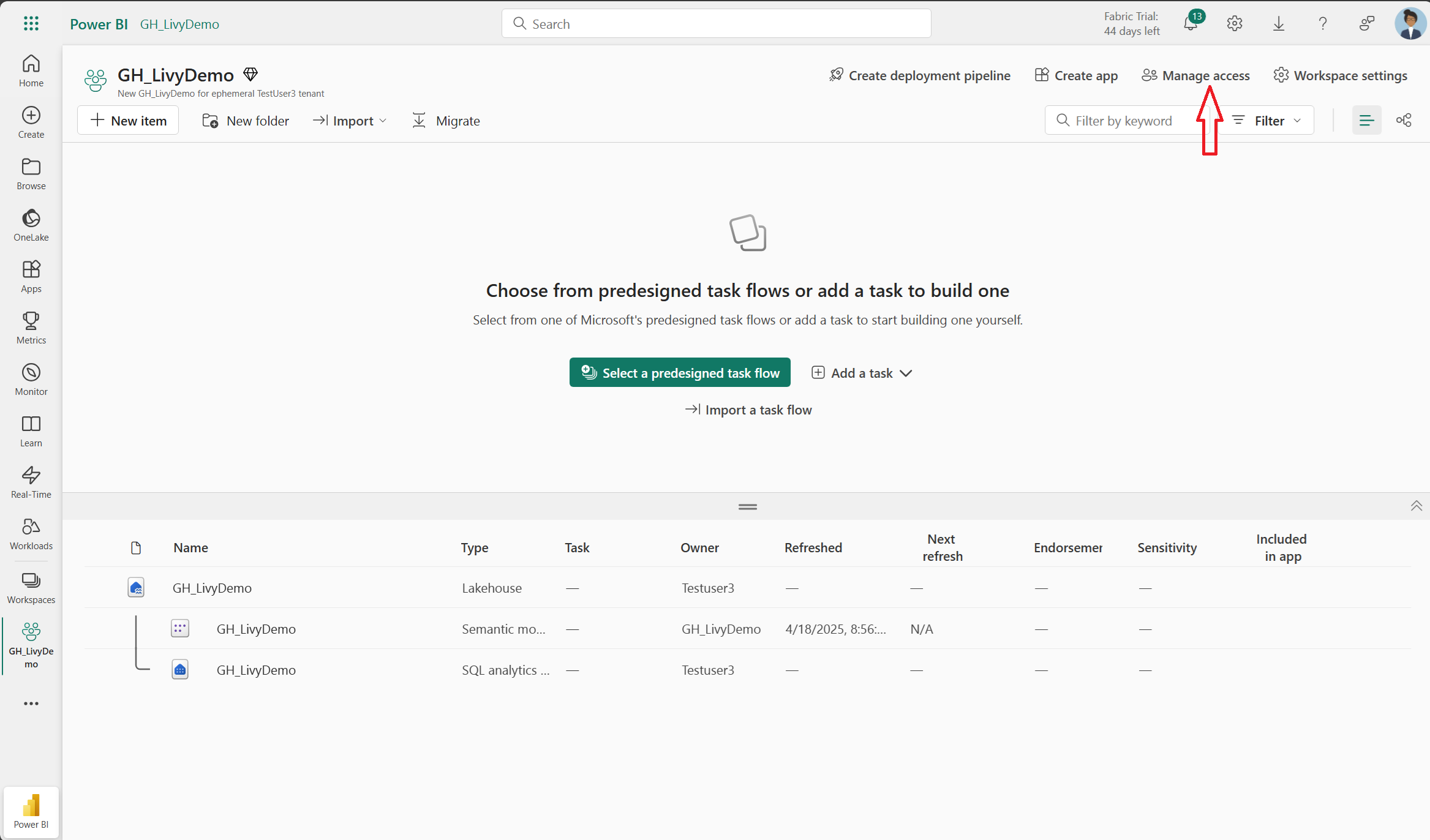
使用应用程序(客户端)ID 或名称搜索Microsoft Entra应用程序,将其添加到工作区,并确保服务主体具有“参与者”权限。


如何使用 Entra 应用令牌授权 Livy API 请求
若要使用包括 Livy API 在内的Fabric API,首先需要创建Microsoft Entra应用程序并获取令牌。 应用程序需要进行充分注册和配置,以便针对Fabric执行 API 调用。 有关详细信息,请参阅 使用 Microsoft identity platform 注册应用程序。
执行 Livy API 作业需要以下Microsoft Entra范围权限:
必需的作用域
| Scope | 说明 |
|---|---|
Lakehouse.Execute.All |
在 Fabric lakehouses 中执行操作。 |
Lakehouse.Read.All |
读取 Lakehouse 元数据。 |
Code.AccessFabric.All |
允许获取Microsoft Fabric的访问令牌。 所有 Livy API 操作都是必需的。 |
Code.AccessStorage.All |
允许获取用于 OneLake 和 Azure 存储的访问令牌。 在数据湖仓库中读取和写入数据所必需的。 |
可选 Code.* 作用域
仅当 Spark 作业需要在运行时访问相应的Azure服务时,才添加这些范围。
| Scope | 说明 | 何时使用 |
|---|---|---|
Code.AccessAzureKeyvault.All |
允许获取对 Azure Key Vault 的访问令牌。 | Spark 代码从Azure Key Vault检索机密、密钥或证书。 |
Code.AccessAzureDataLake.All |
允许获取Azure Data Lake Storage Gen1的访问令牌。 | Spark 代码读取或写入Azure Data Lake Storage Gen1帐户。 |
Code.AccessAzureDataExplorer.All |
允许获取用于访问Azure Data Explorer(Kusto)的令牌。 | Spark 代码查询或从Azure Data Explorer群集引入数据。 |
Code.AccessSQL.All |
允许获取用于Azure SQL的访问令牌。 | Spark 代码需要连接到Azure SQL数据库。 |
注册应用程序时,需要应用程序(客户端)ID 和目录(租户)ID。

调用 API 的经过身份验证的用户需要是 Livy API 和数据源项所在的工作区成员,并具有参与者角色。 有关详细信息,请参阅授予用户对工作区的访问权限。
了解 Livy API 的 Code.* 作用域
通过 Livy API 运行 Spark 作业时, Code.* 范围控制 Spark 运行时可以代表经过身份验证的用户访问的外部服务。 需要两个;其余项是可选的,具体取决于工作负荷。
所需的 Code.* 范围
| Scope | 说明 |
|---|---|
Code.AccessFabric.All |
允许获取Microsoft Fabric的访问令牌。 所有 Livy API 操作都是必需的。 |
Code.AccessStorage.All |
允许获取用于 OneLake 和 Azure 存储的访问令牌。 在数据湖仓库中读取和写入数据所必需的。 |
可选 Code.* 作用域
仅当 Spark 作业需要在运行时访问相应的Azure服务时,才添加这些范围。
| Scope | 说明 | 何时使用 |
|---|---|---|
Code.AccessAzureKeyvault.All |
允许获取对 Azure Key Vault 的访问令牌。 | Spark 代码从Azure Key Vault检索机密、密钥或证书。 |
Code.AccessAzureDataLake.All |
允许获取Azure Data Lake Storage Gen1的访问令牌。 | Spark 代码读取或写入Azure Data Lake Storage Gen1帐户。 |
Code.AccessAzureDataExplorer.All |
允许获取用于访问Azure Data Explorer(Kusto)的令牌。 | Spark 代码查询或从Azure Data Explorer群集引入数据。 |
Code.AccessSQL.All |
允许获取用于Azure SQL的访问令牌。 | Spark 代码需要连接到Azure SQL数据库。 |
注意
这些 Lakehouse.Execute.All 和 Lakehouse.Read.All 范围也是必需的,但不属于 Code.* 家族。 它们分别授予对Fabric lakehouses 执行操作和读取元数据的权限。
如何发现 Fabric Livy API 终结点
需要 Lakehouse 工件才能访问 Livy 终结点。 创建湖屋后,可以在设置面板中找到 Livy API 终结点。

Livy API 终结点将遵循以下模式:
https://api.fabric.microsoft.com/v1/workspaces/><ws_id>/lakehouses/<lakehouse_id>/livyapi/versions/2023-12-01/
URL 附加有 <sessions> 或 <batches>,具体取决于您的选择。
下载 Livy API Swagger 文件
Livy API 的完整 Swagger 文件可在此处获取。
高并发会话
高并发(HC)支持允许客户端获取多个独立的执行上下文(称为 高并发会话)来启用并发 Spark 执行。
每个 HC 会话表示一个映射到 Spark REPL(读-求值-输出循环)的逻辑执行环境。 在不同 HC 会话下提交的 Spark 指令可以并发执行。
这允许:
- 跨 HC 会话并行执行
- 可预测的资源使用情况
- 并发请求之间的隔离
- 与为每个请求创建新会话相比,开销更低
对所有请求使用单个会话会导致语句按顺序执行。 为每个请求创建新会话会引入不必要的开销和资源使用不足。
注意
HC 会话获取不是幂等的。 多个具有相同sessionTag的获取请求会返回不同的HC会话ID,即使这些请求依托于相同的基础Livy会话。
要获取结合示例代码的分步指南,请参阅Fabric高并发会话的Livy API入门指南。 有关概念概述,请参阅 Fabric Livy API 中的高并发支持。
提交 Livy API 作业
完成 Livy API 的设置后,可以选择提交批处理或会话作业。
与Fabric环境的集成
默认情况下,此 Livy API 会话针对工作区的默认初学者池运行。 或者,可以使用 Fabric 环境 创建、配置和使用 Microsoft Fabric 中的环境来自定义 Livy API 会话使用的 Spark 作业的 Spark 池。
若要在 Livy Spark 会话中使用Fabric环境,请更新 json 以包含此有效负载。
create_livy_session = requests.post(livy_base_url, headers = headers, json={
"conf" : {
"spark.fabric.environmentDetails" : "{\"id\" : \""EnvironmentID""}"}
}
)
若要在 Livy Spark 批处理会话中使用Fabric环境,请更新 json 有效负载,如下所示:
payload_data = {
"name":"livybatchdemo_with"+ newlakehouseName,
"file":"abfss://YourABFSPathToYourPayload.py",
"conf": {
"spark.targetLakehouse": "Fabric_LakehouseID",
"spark.fabric.environmentDetails" : "{\"id\" : \""EnvironmentID"\"}" # Replace "EnvironmentID" with your environment ID, or remove this line to use starter pools instead of an environment
}
}
如何监视请求历史记录
可以使用监控中心查看之前的 Livy API 提交,并调试任何提交错误。

相关内容
- Apache Livy REST API 文档
- 开始进行Fabric容量管理员设置
Microsoft Fabric 中的 Apache Spark 工作区管理设置 - 在 Microsoft Identity 平台上注册应用程序
- Microsoft Entra权限和同意概述
- Fabric REST API 范围
- Apache Spark 监视概述
- Apache Spark 应用程序详细信息