本文介绍 Dataflow Gen2 中用于 Microsoft Fabric 数据工厂的增量数据刷新。 使用数据流进行数据引入和转换时,在某些情况下,需要特别刷新新数据或更新的数据 - 尤其是在数据不断增长的情况下。 增量刷新功能可以减少刷新时间、通过避免长时间运行的操作来增强可靠性并最大限度地减少资源使用,从而满足此需求。
先决条件
若要在 Dataflow Gen2 中使用增量刷新,需要满足以下先决条件:
- 必须具备 Fabric 容量。
- 数据源支持折叠(推荐),并且需要包含一个可用于筛选数据的日期或日期时间列。
- 应该有一个支持增量刷新的数据目标。 有关详细信息,请访问目标支持。
- 在开始之前,请确保你已查看增量刷新的限制。 有关详细信息,请转到限制。
目的地支持
增量刷新支持以下数据目标:
- Fabric Lakehouse (预览版)
- Fabric Warehouse
- Azure SQL 数据库
- Azure Synapse Analytics
其他目标可与增量刷新结合使用,通过一个引用暂存数据的第二个查询来更新数据目标。 这样,你仍然可以使用增量刷新来减少需要从源系统处理和检索的数据量。 但是,需要执行从临时数据到数据目标的完全刷新。
如何使用增量刷新
创建新的 Dataflow Gen2 或打开现有的 Dataflow Gen2。
在数据流编辑器中,创建一个新的查询,以检索要增量刷新的数据。
请检查数据预览,以确保查询返回的数据中包含可用于筛选的日期时间、日期或日期时区列。
确保查询完全折叠,这意味着查询已完全推送到源系统。 如果查询未完全折叠,则需要修改查询以使其完全折叠。 可以通过检查查询编辑器中的查询步骤来确保查询完全折叠。
右键单击查询并选择“增量刷新”。
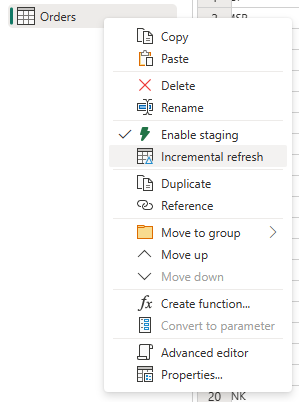
提供增量刷新所需的设置。
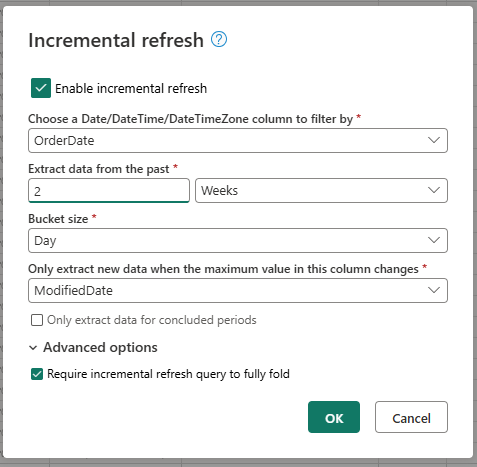
- 选择要作为筛选依据的日期/时间列。
- 从过去提取数据。
- 存储桶大小。
- 仅在此列中的最大值发生更改时提取新数据。
根据需要配置高级设置。
- 要求增量刷新查询完全折叠。
选择“确定”以保存设置。
如果需要,现在可以为查询设置数据目标。 确保在第一次增量刷新之前完成此设置,否则数据目标将仅包含自上次刷新以来增量更改的数据。
发布 Dataflow Gen2。
配置增量刷新后,数据流会根据你提供的设置自动增量刷新数据。 数据流仅检索自上次刷新以来发生更改的数据。 因此,数据流的运行速度更快,消耗的资源更少。
增量刷新的后台工作原理
增量刷新的工作原理是根据日期/时间列将数据划分为存储桶。 每个存储桶包含自上次刷新以来发生更改的数据。 数据流通过检查指定列中的最大值来了解更改的内容。 如果该存储桶的最大值已更改,则数据流将检索整个存储桶并替换目标中的数据。 如果最大值未更改,则数据流不会检索任何数据。 以下部分简要概述了增量刷新的分步工作。
第一步:评估更改
数据流运行时,会首先评估数据源中的更改。 它通过将日期/时间列中的最大值与上次刷新中的最大值进行比较来进行此评估。 如果最大值已更改,或者这是第一次刷新,则数据流会将存储桶标记为“已更改”并将其列出以进行处理。 如果最大值未更改,则数据流将跳过存储桶,并且不会对其进行处理。
第二步:检索数据
现在,数据流已准备好检索数据。 它会检索每个已更改存储桶的数据。 数据流将并行执行此检索以提高性能。 数据流从源系统检索数据并将其加载到临时区域。 数据流仅检索存储桶范围内的数据。 换句话说,数据流仅检索自上次刷新以来发生更改的数据。
最后一步:替换数据目标中的数据
数据流将目标中的数据替换为新数据。 数据流使用 replace 方法替换目标中的数据。 也就是说,数据流会先删除该存储桶的目标中的数据,然后插入新数据。 数据流不会影响存储桶范围之外的数据。 因此,如果目标中的数据早于第一个存储桶,则增量刷新不会以任何方式影响此数据。
增量刷新设置说明
若要配置增量刷新,需要指定以下设置。
常规设置
常规设置是必需的,用于指定增量刷新的基本配置。
选择要作为筛选依据的日期/时间列
此设置是必需的,并指定用于数据流筛选数据的列。 此列应为日期/时间、日期或日期/时区列。 数据流使用此列来筛选数据,并且仅检索自上次刷新以来发生更改的数据。
从过去提取数据
此设置是必需的,用于指定数据流应提取多久以前的数据。 此设置用于检索初始数据加载。 数据流从源系统检索指定时间范围内的所有数据。 可能的值为:
- x 天
- x 周
- x 个月
- x 个季度
- x 年
例如,如果指定 1 个月,则数据流会从源系统中检索上个月内的所有新数据。
存储桶大小
此设置是必需的,用于指定数据流用来筛选数据的存储桶的大小。 数据流根据日期/时间列将数据划分为不同的分组。 每个存储桶包含自上次刷新以来发生更改的数据。 存储桶大小决定每次迭代处理的数据量。 较小的存储桶大小意味着数据流每次迭代处理的数据较少,也意味着处理所有数据所需的迭代次数更多。 较大的存储桶大小意味着数据流每次迭代处理的数据较多,也意味着处理所有数据所需的迭代次数更少。
仅在此列中的最大值发生更改时提取新数据
此设置是必需的,用于指定数据流用来确定数据是否发生更改的列。 数据流会将此列中的最大值与上次刷新中的最大值进行比较。 如果最大值已更改,则数据流将检索自上次刷新以来发生更改的数据。 如果最大值未更改,则数据流不会检索任何数据。
仅提取已结束时间段的数据
此设置是可选的,用于指定数据流是否应仅提取已结束时间段的数据。 如果启用此设置,数据流将仅提取已结束时间段的数据。 因此,数据流将仅提取已完成且不包含任何未来数据的时间段的数据。 如果禁用此设置,则数据流将提取所有时间段的数据,包括未完成且包含未来数据的时间段。
例如,如果你有一个包含交易日期的日期/时间列,并且只想刷新完整月份,则可以结合存储桶大小 (month) 启用此设置。 这样,数据流将仅提取完整月份的数据,而不提取不完整月份的数据。
高级设置
某些设置被视为高级设置,在大多数情况下不是必需的。
要求增量刷新查询完全折叠
此设置是可选的,用于指定用于增量刷新的查询是否必须完全折叠。 如果启用此设置,则用于增量刷新的查询必须完全折叠。 换句话说,必须将查询完全推送到源系统。 如果禁用此设置,则用于增量刷新的查询无需完全折叠。 在这种情况下,可以将查询部分推送到源系统。 我们强烈建议启用此设置以提高性能,以避免检索不必要和未筛选的数据。
限制
支持 Lakehouse 系统的同时,还附带额外注意事项。
将 Lakehouse 用作数据目标时,需要注意以下限制:
- 并发评估的最大数目为 10。 这意味着数据流只能并行评估 10 个存储桶。 如果存储桶数超过 10 个,则需要限制存储桶数或限制并发评估数。
- 当你向数据湖库写入数据时,数据流会维护自己所写入文件的记录。 这符合标准的湖屋模式。 但是,这意味着,如果 Spark 等其他编写器或其他进程写入同一个表,则可能会导致增量刷新出现问题。 建议在使用增量刷新时,不要使用其他编写器写入同一个表。 如果如此,则需要确保其他编写者不会干扰增量刷新过程。 使用增量刷新时,不支持表维护和清扫等过程。
数据目标必须设置为固定架构
数据目标必须设置为固定架构,这意味着数据目标中的表的架构必须是固定的,无法更改。 如果数据目标中的表的架构设置为动态架构,则需要在配置增量刷新之前将其更改为固定架构。
数据目标中唯一支持的更新方法是 replace
数据目标中唯一支持的更新方法是 replace,这意味着数据流会将数据目标中每个存储桶的数据替换为新数据。 但是,存储桶范围之外的数据不受影响。 因此,如果数据目标中的数据早于第一个存储桶,则增量刷新不会以任何方式影响此数据。
单个查询的最大存储桶数为 50,整个数据流的最大存储桶数为 150
数据流支持的每个查询的最大存储桶数为 50。 如果存储桶数量超过 50 个,则需要增加存储桶大小或减少存储桶范围以减少存储桶的数量。 对于整个数据流,最大存储桶数为 150。 如果数据流中的存储桶超过 150 个,则需要减少增量刷新查询的数量或增加存储桶大小以减少存储桶的数量。
Dataflow Gen1 和 Dataflow Gen2 中的增量刷新之间的差异
Dataflow Gen1 和 Dataflow Gen2 在增量刷新的工作方式上存在一些差异。 以下列表解释了 Dataflow Gen1 和 Dataflow Gen2 中增量刷新的主要差异。
- 增量刷新现在是 Dataflow Gen2 中的一流功能。 在 Dataflow Gen1 中,必须在发布数据流后配置增量刷新。 在 Dataflow Gen2 中,增量刷新现在是一类功能,可以在数据流编辑器中直接对其进行配置。 此功能使配置增量刷新变得更加容易,并且能够降低出错的风险。
- 在 Dataflow Gen1 中,必须在配置增量刷新时指定历史数据范围。 在 Dataflow Gen2 中,无需指定历史数据范围。 数据流不会从目标中删除任何超出存储桶范围的数据。 因此,如果目标中的数据早于第一个存储桶,则增量刷新不会以任何方式影响此数据。
- 在 Dataflow Gen1 中,必须在配置增量刷新时指定增量刷新的参数。 在 Dataflow Gen2 中,无需指定增量刷新的参数。 作为查询的最后一步,数据流会自动添加筛选器和参数。 因此,无需手动指定增量刷新的参数。
常见问题解答
我收到一条警告,提示我对检测更改和筛选使用了相同的列。 这是什么意思呢?
如果你收到一条警告,提示你对检测更改和筛选使用了相同的列,则意味着你为检测更改而指定的列同时用于筛选数据。 我们不建议这种用法,因为它可能会导致意外结果。 相反,我们建议使用不同的列来检测更改和过滤数据。 如果数据在存储桶之间移动,数据流可能无法正确检测到更改,并可能在目标中创建重复数据。 您可以使用不同的列来检测更改和筛选数据,以解决此警告。 或者,如果你确定指定列的数据在刷新之间不会发生变化,则可以忽略警告。
我想要对不受支持的数据目标使用增量刷新。 我该怎么办?
如果想要对不受支持的数据目标使用增量刷新,则可以在查询上启用增量刷新,并使用另一个引用临时数据的查询来更新数据目标。 这样,你仍然可以使用增量刷新来减少需要从源系统处理和检索的数据量,但需要执行从临时数据到数据目标的完全刷新。 确保正确设置窗口和存储桶大小,因为我们不保证临时数据保留在存储桶范围之外。 另一个选项是使用模式以增量方式积累数据。 我们在此处提供了有关如何执行此作的指南: 使用数据流 Gen2 增量积累数据
如何知道我的查询是否启用了增量刷新?
可以通过检查数据流编辑器中查询旁边的图标来查看查询是否启用了增量刷新。 如果图标包含蓝色三角形,则表示已启用增量刷新。 如果图标不包含蓝色三角形,则表示未启用增量刷新。
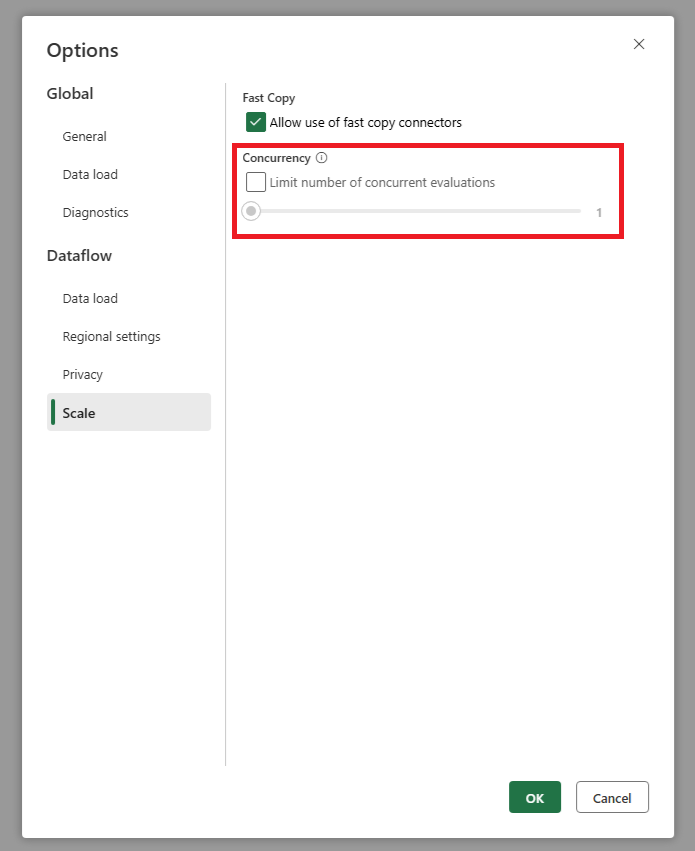
当我使用增量刷新时,我的源收到的请求过多。 我该怎么办?
我们添加了一个设置,让你可以设置并行查询评估的最大数量。 此设置可以在数据流的全局设置中找到。 通过将此值设置为较小的数字,可以减少发送到源系统的请求数。 此设置有助于减少并发请求数并提高源系统的性能。 若要设置并行查询执行的最大数量,请转到数据流的全局设置,导航到“刻度”选项卡,然后设置并行查询评估的最大数量。 除非遇到源系统问题,否则不建议启用此限制。
我想使用增量刷新,但看到启用后,数据流需要更长的时间才能刷新。 我该怎么办?
本文中所述的增量刷新旨在减少需要从源系统进行处理和检索的数据量。 然而,如果在启用增量刷新后数据流刷新所需的时间更长,这可能是由于检查数据变化和处理存储桶带来了额外的开销,这种开销超过了处理较少数据所节省的时间。 在这种情况下,建议检查增量刷新的设置,并对其进行调整,以便更适合你的场景。 例如,可以增加存储桶大小以减少存储桶的数量以及处理存储桶的开销。 或者,可以通过增加存储桶大小来减少存储桶数量。 如果在调整设置后仍遇到低性能,则可以禁用增量刷新并使用完整刷新,因为在这种情况下可能更高效。