本教程演示如何使用语义链接检测公共 Synthea 数据集中的关系。
使用新数据或在不使用现有数据模型的情况下工作时,自动发现关系会很有帮助。 此关系检测可帮助你:
- 大致了解模型,
- 在探索数据分析期间获取更多见解,
- 验证更新的数据或新传入的数据
- 清除数据。
即使关系事先已知,搜索关系也有助于更好地了解数据模型或识别数据质量问题。
在本教程中,你将从一个简单的基线示例开始,其中只试验了三个表,以便它们之间的连接易于遵循。 然后,会显示一个更复杂的示例,其中包含更大的表集。
本教程介绍如何:
- 使用语义链接的 Python 库(SemPy)的组件,这些组件支持与 Power BI 集成,并帮助自动执行数据分析。 这些组件包括:
- FabricDataFrame - 一种类似 panda 的结构,通过其他语义信息进行了增强。
- 用于将语义模型从 Fabric 工作区拉取到笔记本中的函数。
- 自动化发现和可视化语义模型中关系的功能。
- 对具有多个表和相互依赖性的语义模型的关系发现过程进行故障排除。
先决条件
获取 Microsoft Fabric 订阅。 或者,注册免费的 Microsoft Fabric 试用版。
登录 Microsoft Fabric。
使用主页左下侧的体验切换器切换到 Fabric。
- 从左侧导航窗格中选择 工作区 以查找并选择工作区。 此工作区将成为当前工作区。
在笔记本中继续操作
本教程随附 relationships_detection_tutorial.ipynb 笔记本。
若要打开本教程随附的笔记本,请按照 为数据科学教程准备系统 中的说明将笔记本导入工作区。
如果要复制并粘贴此页面中的代码,可以 创建新的笔记本。
在开始运行代码之前,请务必将湖屋连接到笔记本。
设置笔记本
在本部分中,你将使用必要的模块和数据设置笔记本环境。
使用笔记本中的
SemPy内联安装功能从 PyPI 安装%pip:%pip install semantic-link导入稍后会用到的 SemPy 模块:
import pandas as pd from sempy.samples import download_synthea from sempy.relationships import ( find_relationships, list_relationship_violations, plot_relationship_metadata )导入 pandas 以强制执行有助于格式化输出的配置选项:
import pandas as pd pd.set_option('display.max_colwidth', None)拉取示例数据。 本教程中,您将使用合成医疗记录的 Synthea 数据集(为了简化,选择小版本):
download_synthea(which='small')
检测一小部分 Synthea 表之间的关系
从较大的集合中选择三个表:
-
patients指定患者信息 -
encounters指定有医疗接触的患者(例如医疗预约、程序) -
providers指定哪些医疗服务提供者照顾了病人
encounters表解析patients与providers之间的多对多关系,可描述为 关联实体:patients = pd.read_csv('synthea/csv/patients.csv') providers = pd.read_csv('synthea/csv/providers.csv') encounters = pd.read_csv('synthea/csv/encounters.csv')-
使用 SemPy 的
find_relationships函数查找表之间的关系:suggested_relationships = find_relationships([patients, providers, encounters]) suggested_relationships使用 SemPy 的
plot_relationship_metadata函数将关系数据帧可视化为图形。plot_relationship_metadata(suggested_relationships)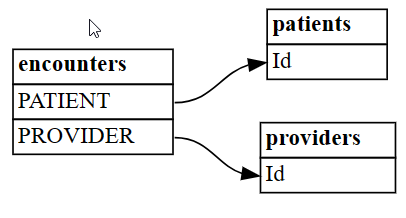
该函数将关系层次结构从左侧布局到右侧,对应于输出中的“from”和“to”表。 换言之,左侧的独立“from”表使用其外键指向右侧的“to”依赖项表。 每个实体框显示参与关系的“from”或“to”一方的列。
默认情况下,关系将生成为“m:1”(而不是“1:m”)或“1:1”。 “1:1”关系可以通过一种或两种方式生成,具体取决于映射值与所有值的比率在一个或两个方向上是否超过
coverage_threshold。 在本教程的后面部分,你将介绍"m:m"关系中不太常见的情况。

对关系检测问题进行故障排除
基线示例显示了对干净 Synthea 数据的成功关系检测。 实际上,数据很少干净,这可以防止成功检测。 在数据不干净时,有几个方法很有用。
本教程的本节介绍语义模型包含脏数据时的关系检测。
首先操作原始 DataFrame 以获取“脏”数据,并输出脏数据的大小。
# create a dirty 'patients' dataframe by dropping some rows using head() and duplicating some rows using concat() patients_dirty = pd.concat([patients.head(1000), patients.head(50)], axis=0) # create a dirty 'providers' dataframe by dropping some rows using head() providers_dirty = providers.head(5000) # the dirty dataframes have fewer records than the clean ones print(len(patients_dirty)) print(len(providers_dirty))为了进行比较,原表格的打印尺寸:
print(len(patients)) print(len(providers))使用 SemPy 的
find_relationships函数查找表之间的关系:find_relationships([patients_dirty, providers_dirty, encounters])代码的输出表明,由于你之前引入的错误创建了杂乱的语义模型,因此未检测到任何关系。
使用验证
验证是排查关系检测失败的最佳工具,因为:
- 它清楚地报告了为什么特定关系不遵循外键规则,因此无法检测到。
- 它使用大型语义模型快速运行,因为它只关注声明的关系,并且不执行搜索。
验证可以使用任何与 find_relationships 生成的列类似的任何 DataFrame。 在以下代码中,suggested_relationships DataFrame 引用 patients 而不是 patients_dirty,但可以使用字典对 DataFrame 进行别名:
dirty_tables = {
"patients": patients_dirty,
"providers" : providers_dirty,
"encounters": encounters
}
errors = list_relationship_violations(dirty_tables, suggested_relationships)
errors
放宽搜索条件
在更模糊的方案中,可以尝试松动搜索条件。 此方法会增加假正的可能性。
设置
include_many_to_many=True并评估它是否有帮助:find_relationships(dirty_tables, include_many_to_many=True, coverage_threshold=1)结果显示检测到从
encounters到patients的关系,但存在两个问题:- 该关系指示从
patients到encounters的方向,这是预期关系的反转。 这是因为所有patients都发生在encounters(Coverage From为 1.0)中,而encounters(patients= 0.85) 仅部分覆盖Coverage To(因为患者行缺失)。 - 在低基数
GENDER列中发生意外匹配,这两个表中的名称和值恰好匹配,但它不是所关注的的“m:1”关系。 低基数由Unique Count From和Unique Count To列指示。
- 该关系指示从
重新运行
find_relationships,仅查找“m:1”关系,但使用较低的coverage_threshold=0.5:find_relationships(dirty_tables, include_many_to_many=False, coverage_threshold=0.5)结果显示从
encounters到providers的关系的正确方向。 但是,不会检测到从encounters到patients的关系,因为patients并不唯一,因此它不能位于“m:1”关系的“一”侧。include_many_to_many=True和coverage_threshold=0.5均放宽:find_relationships(dirty_tables, include_many_to_many=True, coverage_threshold=0.5)现在,两种关注的关系都可见,但有了更多的噪音:
- 存在
GENDER上的低基数匹配。 -
ORGANIZATION上出现更高的基数“m:m”匹配,因此很明显,ORGANIZATION可能是两个表的去规范化列。
- 存在
匹配列名称
默认情况下,SemPy 仅将显示名称相似的属性视为匹配项,并利用数据库设计者通常以相同方式命名相关列这一事实。 此行为有助于避免出现虚假关系,这些关系最常与低基数整数键发生。 例如,如果存在 1,2,3,...,10 产品类别和 1,2,3,...,10 订单状态代码,则仅查看值映射而不考虑列名时,它们将相互混淆。 对于类似 GUID 的键,虚假关系应该不是问题。
SemPy 查看列名称和表名之间的相似性。 匹配是近似的,不区分大小写。 它忽略最常遇到的“修饰器”子字符串,例如“id”、“code”、“name”、“key”、“pk”、“fk”。 因此,最典型的匹配情况是:
- 实体“foo”中名为“column”的属性与实体“bar”中名为“column”(也可为“COLUMN”或“Column”)的属性匹配。
- 实体“foo”中名为“column”的属性与“bar”中名为“column_id”的属性匹配。
- 实体“foo”中名为“bar”的属性与“bar”中名为“code”的属性匹配。
通过首先匹配列名,检测运行速度会更快。
匹配列名称:
- 若要了解选择哪些列进行进一步评估,请使用
verbose=2选项(verbose=1仅列出正在处理的实体)。 -
name_similarity_threshold参数确定列的比较方式。 阈值为 1 表示你仅对 100 个% 匹配感兴趣。
find_relationships(dirty_tables, verbose=2, name_similarity_threshold=1.0);以 100% 的相似性运行时,无法考虑到名称之间的细微差异。 在示例中,表具有带“s”后缀的复数形式,因此无法完全匹配。 默认的
name_similarity_threshold=0.8可以很好地处理这个问题。- 若要了解选择哪些列进行进一步评估,请使用
使用默认
name_similarity_threshold=0.8重新运行:find_relationships(dirty_tables, verbose=2, name_similarity_threshold=0.8);请注意,现在复数形式
patients的 ID 与单数形式patient进行比较,同时不会在执行时间中添加太多其他不必要的比较。使用默认
name_similarity_threshold=0重新运行:find_relationships(dirty_tables, verbose=2, name_similarity_threshold=0);将
name_similarity_threshold更改为 0 是另一种极端值,它指示要比较所有列。 这很少是必需的,并且会导致执行时间和需要审查的虚假匹配增加。 观察详细输出中的比较数。
故障排除提示摘要
- 从“m:1”关系的完全匹配开始(即默认
include_many_to_many=False和coverage_threshold=1.0)。 这通常是你想要的。 - 对较小的表格子集使用窄焦点。
- 使用验证检测数据质量问题。
- 如果要了解要针对关系考虑哪些列,请使用
verbose=2。 这可能会导致大量的输出。 - 请注意对搜索参数的权衡。
include_many_to_many=True和coverage_threshold<1.0可能会产生虚假的关系,这些关系可能难以分析和筛选。
检测完整 Synthea 数据集上的关系
简单的基线示例是一种方便的学习和故障排除工具。 实际上,可以从语义模型(例如完整的 Synthea 数据集)开始,该数据集具有更多表。 按如下所示浏览完整的 synthea 数据集。
从 synthea/csv 目录中读取所有文件:
all_tables = { "allergies": pd.read_csv('synthea/csv/allergies.csv'), "careplans": pd.read_csv('synthea/csv/careplans.csv'), "conditions": pd.read_csv('synthea/csv/conditions.csv'), "devices": pd.read_csv('synthea/csv/devices.csv'), "encounters": pd.read_csv('synthea/csv/encounters.csv'), "imaging_studies": pd.read_csv('synthea/csv/imaging_studies.csv'), "immunizations": pd.read_csv('synthea/csv/immunizations.csv'), "medications": pd.read_csv('synthea/csv/medications.csv'), "observations": pd.read_csv('synthea/csv/observations.csv'), "organizations": pd.read_csv('synthea/csv/organizations.csv'), "patients": pd.read_csv('synthea/csv/patients.csv'), "payer_transitions": pd.read_csv('synthea/csv/payer_transitions.csv'), "payers": pd.read_csv('synthea/csv/payers.csv'), "procedures": pd.read_csv('synthea/csv/procedures.csv'), "providers": pd.read_csv('synthea/csv/providers.csv'), "supplies": pd.read_csv('synthea/csv/supplies.csv'), }使用 SemPy 的
find_relationships函数查找表之间的关系:suggested_relationships = find_relationships(all_tables) suggested_relationships可视化关系:
plot_relationship_metadata(suggested_relationships)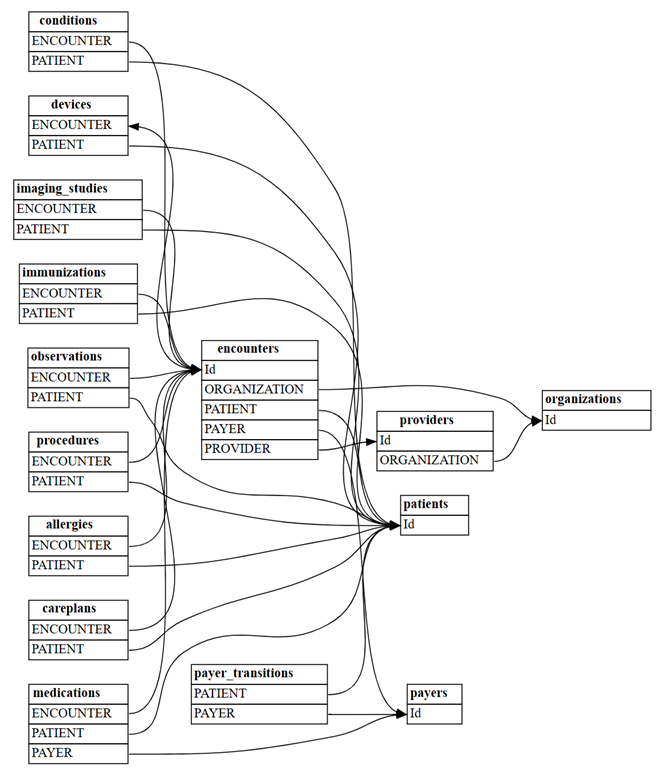
计算使用
include_many_to_many=True会发现多少个新“m:m”关系。 这些关系除了先前展示的“m:1”关系外,因此,您必须对multiplicity进行筛选。suggested_relationships = find_relationships(all_tables, coverage_threshold=1.0, include_many_to_many=True) suggested_relationships[suggested_relationships['Multiplicity']=='m:m']可以按各种列对关系数据进行排序,以便更深入地了解其性质。 例如,可以选择按
Row Count From和Row Count To对输出进行排序,这有助于标识最大的表。suggested_relationships.sort_values(['Row Count From', 'Row Count To'], ascending=False)在不同的语义模型中,应该着重关注
Null Count From或Coverage To的 null 数。此分析可以帮助你确定是否有任何关系可能无效,以及是否需要将其从候选项列表中删除。

相关内容
查看有关语义链接/SemPy 的其他教程: