你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
适用于:✅Microsoft Fabric✅Azure 数据资源管理器Azure Monitor✅Microsoft✅ Sentinel
使用聚合函数可以将多个行中的数据分组与合并成一个汇总值。 得到的汇总值取决于所选的函数,例如计数、最大值或平均值。
本教程介绍以下操作:
本教程中的示例使用 StormEvents 表,该表已在帮助群集中公开提供。 若要使用自己的数据进行探索, 请创建自己的免费群集。
本教程中的示例使用StormEvents在天气分析示例数据中公开提供的表。
本教程是在第一篇教程了解常用运算符的基础上制作的。
先决条件
若要运行以下查询,需要一个有权访问示例数据的查询环境。 你可以使用以下项之一:
- 用于登录到帮助群集的 Microsoft 帐户或 Microsoft Entra 用户标识
- Microsoft帐户或Microsoft Entra 用户标识
- 启用了 Microsoft Fabric 容量的 Fabric 工作区
使用 summarize 运算符
要对数据执行聚合,summarize 运算符至关重要。 summarize 运算符根据 by 子句将行分组在一起,然后使用提供的聚合函数将每个组合并为一行。
使用 summarize 和 count 聚合函数按状态查找事件数。
StormEvents
| summarize TotalStorms = count() by State
输出
| 状态 | TotalStorms |
|---|---|
| 德克萨斯 | 4701 |
| KANSAS | 3166 |
| 衣阿华州 | 2337 |
| ILLINOIS | 2022 |
| MISSOURI | 2016 |
| ... | ... |
可视化查询结果
将图表或图形中的查询结果可视化可帮助你识别数据中的模式、趋势和离群值。 可以使用 render 运算符执行此操作。
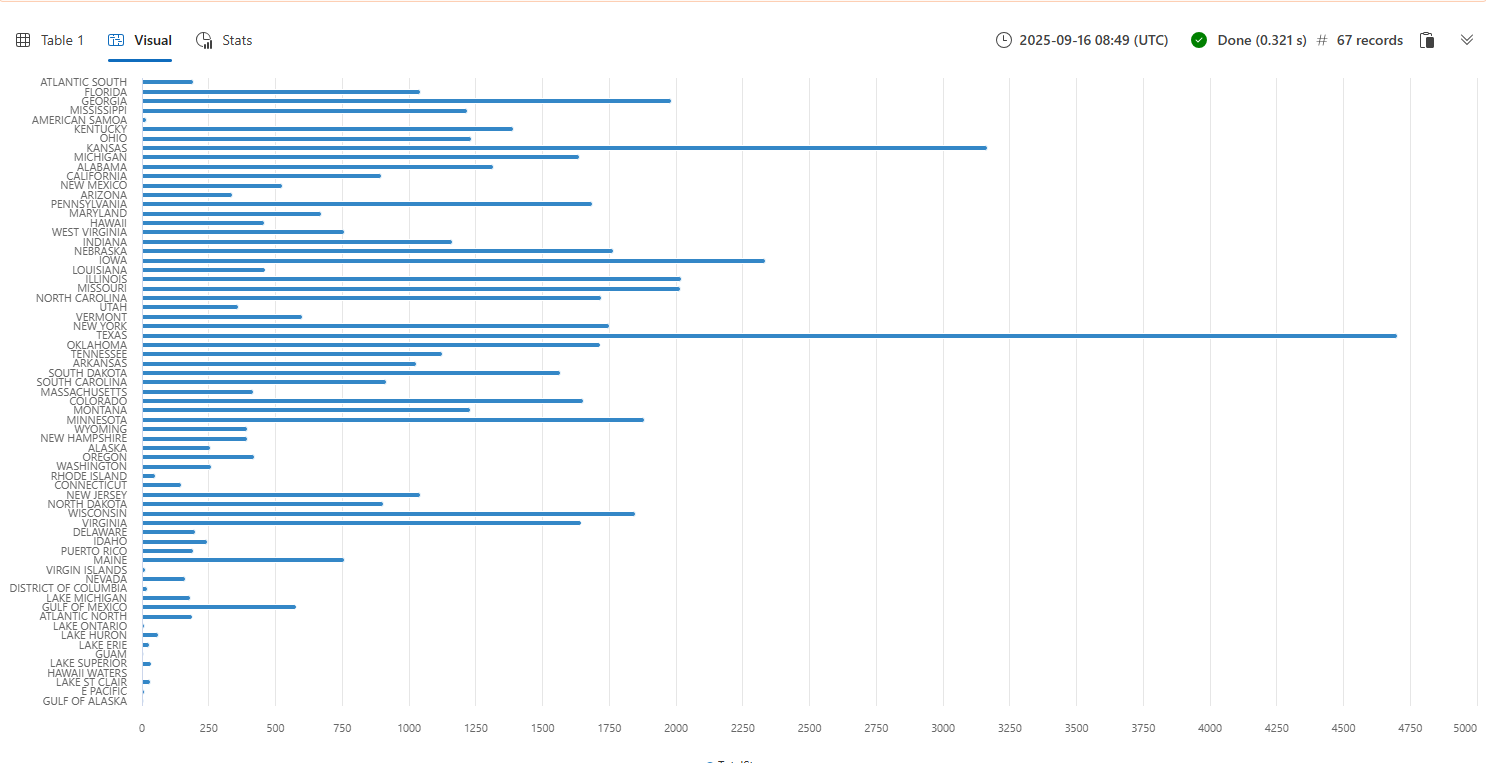
整篇教程提供了有关如何使用 render 显示结果的示例。 现在,让我们使用 render 在条形图中查看以上查询的结果。
StormEvents
| summarize TotalStorms = count() by State
| render barchart
按条件统计行数
分析数据时,可以使用 countif() 根据特定的条件统计行数,以了解有多少行满足给定的条件。
以下查询使用 countif() 来统计造成了损害的风暴。 然后,该查询使用 top 运算符筛选结果,并显示风暴造成的农作物损害最严重的州。
StormEvents
| summarize StormsWithCropDamage = countif(DamageCrops > 0) by State
| top 5 by StormsWithCropDamage
输出
| 状态 | StormsWithCropDamage |
|---|---|
| 衣阿华州 | 359 |
| 內布拉斯加州 | 201 |
| 密西西比州 | 105 |
| NORTH CAROLINA | 82 |
| MISSOURI | 78 |
将数据分组到箱中
若要按数字或时间值聚合,首先需要使用 bin() 函数将数据分组到箱中。 使用 bin() 可以帮助你了解值在特定范围内的分布情况,并对不同的时间段进行比较。
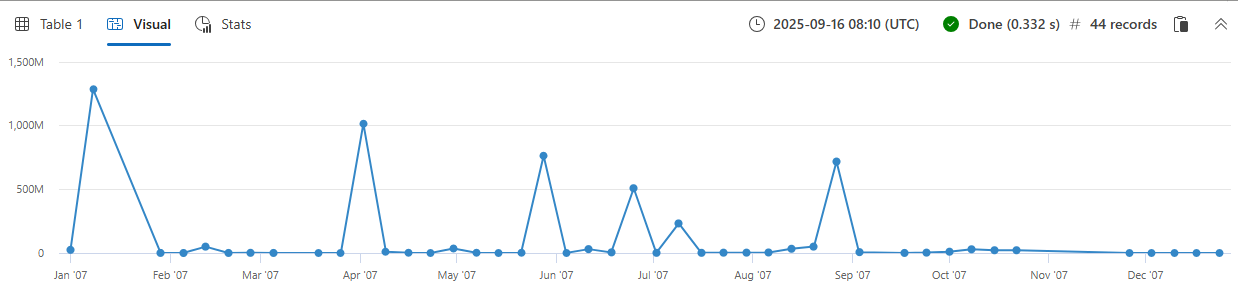
以下查询统计 2007 年每周造成农作物损害的风暴次数。 7d 参数表示一周,因为该函数需要有效的时间范围值。
StormEvents
| where StartTime between (datetime(2007-01-01) .. datetime(2007-12-31))
and DamageCrops > 0
| summarize EventCount = count() by bin(StartTime, 7d)
输出
| StartTime | EventCount |
|---|---|
| 2007-01-01T00:00:00Z | 16 |
| 2007-01-08T00:00:00Z | 20 |
| 2007-01-29T00:00:00Z | 8 |
| 2007-02-05T00:00:00Z | 1 |
| 2007-02-12T00:00:00Z | 3 |
| ... | ... |
将 | render timechart 添加到查询的末尾以将结果可视化。
注意
bin() 类似于其他编程语言中的 floor() 函数。 它将每个值缩减为最接近提供的模数的倍数,并允许 summarize 将行分配到组。
计算最小值、最大值、平均值和总和
若要详细了解造成农作物损害的风暴类型,请计算每种事件类型造成的农作物损害的 min()、max() 和 avg() 值,然后按平均损害程度将结果排序。
请注意,可以在单个 summarize 运算符中使用多个聚合函数来生成多个计算列。
StormEvents
| where DamageCrops > 0
| summarize
MaxCropDamage=max(DamageCrops),
MinCropDamage=min(DamageCrops),
AvgCropDamage=avg(DamageCrops)
by EventType
| sort by AvgCropDamage
输出
| EventType | MaxCropDamage | MinCropDamage | AvgCropDamage |
|---|---|---|---|
| 霜冻/冰冻 | 568600000 | 3000 | 9106087.5954198465 |
| 野火 | 21000000 | 10000 | 7268333.333333333 |
| Drought | 700000000 | 2000 | 6763977.8761061952 |
| 洪水 | 500000000 | 1000 | 4844925.23364486 |
| 雷雨大风 | 22000000 | 100 | 920328.36538461538 |
| ... | ... | ... | ... |
以上查询的结果表明,“霜冻/冰冻”事件平均造成的农作物损害最大。 但是,bin() 查询表明,造成农作物损害的事件大多发生在夏季。
使用 sum() 检查损害的农作物总数,而不是造成某种损害的事件的数量,就像在前面的 bin() 查询中使用 count() 所做的那样。
StormEvents
| where StartTime between (datetime(2007-01-01) .. datetime(2007-12-31))
and DamageCrops > 0
| summarize CropDamage = sum(DamageCrops) by bin(StartTime, 7d)
| render timechart
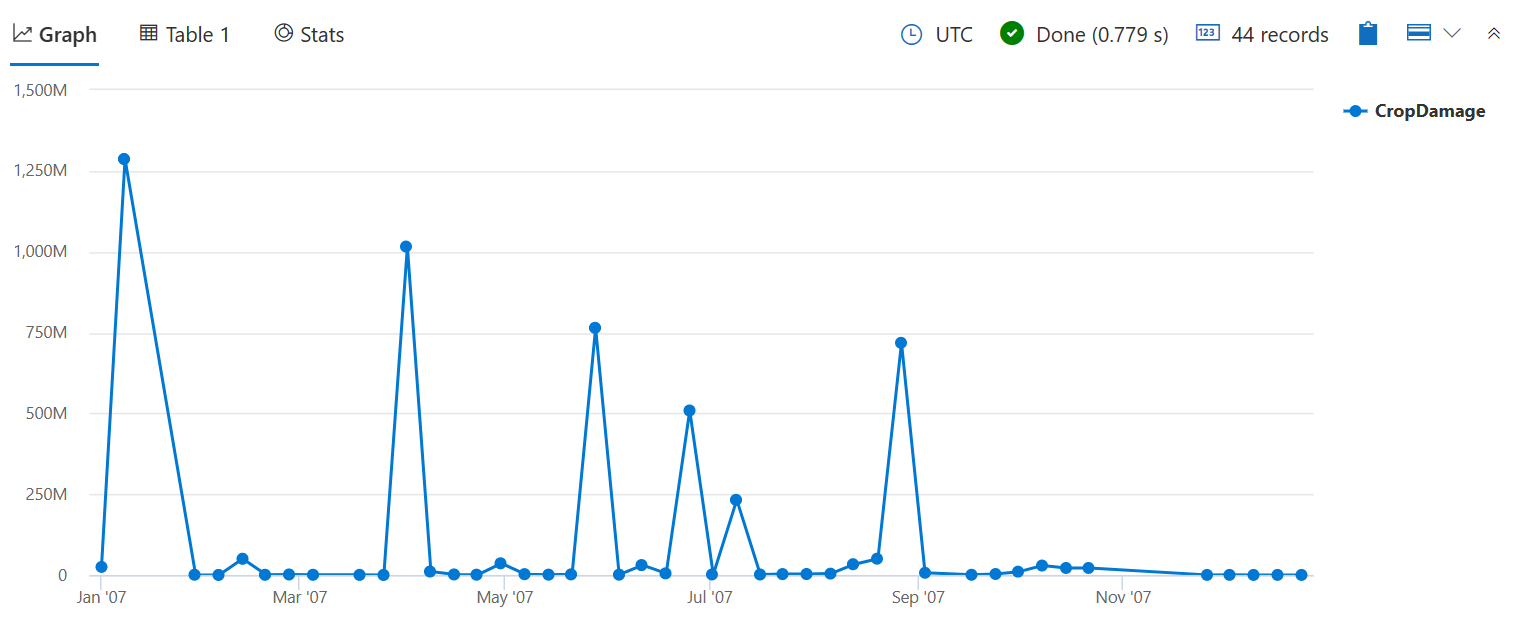
现在可以看到,1 月份的农作物损害达到高峰,这可能是由于霜冻/冰冻造成的。
计算百分比
计算百分比可帮助你了解数据中不同值的分布和比例。 本部分介绍使用 Kusto 查询语言 (KQL) 计算百分比的两种常用方法。
基于两列计算百分比
使用 count() 和 countif 查找每个州造成农作物损害的风暴事件的百分比。 首先,计算每个州的风暴总数。 然后,计算每个州造成农作物损害的风暴次数。
最后,使用 extend 计算两列之间的百分比,方法是将造成农作物损失的风暴数除以风暴总数再乘以 100。
为确保获得小数结果,请在执行除法之前,使用 todouble() 函数将至少一个整数计数值转换为双精度值。
StormEvents
| summarize
TotalStormsInState = count(),
StormsWithCropDamage = countif(DamageCrops > 0)
by State
| extend PercentWithCropDamage =
round((todouble(StormsWithCropDamage) / TotalStormsInState * 100), 2)
| sort by StormsWithCropDamage
输出
| 州/省/市/自治区 | TotalStormsInState | StormsWithCropDamage | PercentWithCropDamage |
|---|---|---|---|
| 衣阿华州 | 2337 | 359 | 15.36 |
| 內布拉斯加州 | 1766 | 201 | 11.38 |
| 密西西比州 | 1218 | 105 | 8.62 |
| NORTH CAROLINA | 1721 | 82 | 4.76 |
| MISSOURI | 2016 | 78 | 3.87 |
| ... | ... | ... | ... |
注意
计算百分比时,请使用 todouble() 或 toreal()转换除法中的至少一个整数值。 这可以确保不会因整数除法而得到截断的结果。 有关详细信息,请参阅算术运算的类型规则。
基于表大小计算百分比
若要将按事件类型划分的风暴数与数据库中的风暴总数进行比较,首先请将数据库中的风暴总数保存为变量。 Let 语句用于在查询中定义变量。
由于表格表达式语句返回表格结果,因此请使用 toscalar() 函数将 count() 函数的表格结果转换为标量值。 然后,可以在百分比计算中使用该数值。
let TotalStorms = toscalar(StormEvents | summarize count());
StormEvents
| summarize EventCount = count() by EventType
| project EventType, EventCount, Percentage = todouble(EventCount) / TotalStorms * 100.0
输出
| EventType | EventCount | 百分比 |
|---|---|---|
| 雷雨大风 | 13015 | 22.034673077574237 |
| 冰雹 | 12711 | 21.519994582331627 |
| 山洪 | 3688 | 6.2438627975485055 |
| Drought | 3616 | 6.1219652592015716 |
| 冬季天气 | 3349 | 5.669928554498358 |
| ... | ... | ... |
提取唯一值
使用 make_set() 将表中选择的行转换为唯一值的数组。
以下查询使用 make_set() 来创建导致每个州发生死亡的事件类型的数组。 然后按照每个数组中风暴类型的数量将结果表排序。
StormEvents
| where DeathsDirect > 0 or DeathsIndirect > 0
| summarize StormTypesWithDeaths = make_set(EventType) by State
| project State, StormTypesWithDeaths
| sort by array_length(StormTypesWithDeaths)
输出
| 状态 | StormTypesWithDeaths |
|---|---|
| CALIFORNIA | ["雷雨大风","巨浪","冷风/寒风","强风","裂流","高温","极端高温","野火","沙尘暴","天文低潮","浓雾","冬季天气"] |
| 德克萨斯 | ["山洪暴","雷雨大风","龙卷风","闪电","洪水","冰暴","冬季天气","裂流","极端高温","浓雾","飓风(台风)","冷风/寒风"] |
| OKLAHOMA | ["山洪暴","龙卷风","冷风/寒风","冬季风暴","大雪","极端高温","冰暴","冬季天气","浓雾"] |
| NEW YORK | ["洪水","闪电","雷雨大风","山洪暴","冬季天气","冰暴","极端冷风/寒风","冬季风暴","大雪"] |
| KANSAS | ["雷雨大风","暴雨","龙卷风","洪水","山洪暴","闪电","大雪","冬季天气","暴雪"] |
| ... | ... |
按条件将数据分桶
case() 函数根据指定的条件将数据分组到桶中。 该函数为第一个满足的谓词返回相应的结果表达式,如果不满足任何谓词,则返回最终的 else 表达式。
此示例根据公民遭受的风暴相关伤害数量对州进行分组。
StormEvents
| summarize InjuriesCount = sum(InjuriesDirect) by State
| extend InjuriesBucket = case (
InjuriesCount > 50,
"Large",
InjuriesCount > 10,
"Medium",
InjuriesCount > 0,
"Small",
"No injuries"
)
| sort by State asc
输出
| 状态 | InjuriesCount | InjuriesBucket |
|---|---|---|
| ALABAMA | 494 | 大 |
| ALASKA | 0 | 无伤害 |
| AMERICAN SAMOA | 0 | 无伤害 |
| ARIZONA | 6 | 小 |
| ARKANSAS | 54 | 大 |
| ATLANTIC NORTH | 15 | 中等 |
| ... | ... | ... |
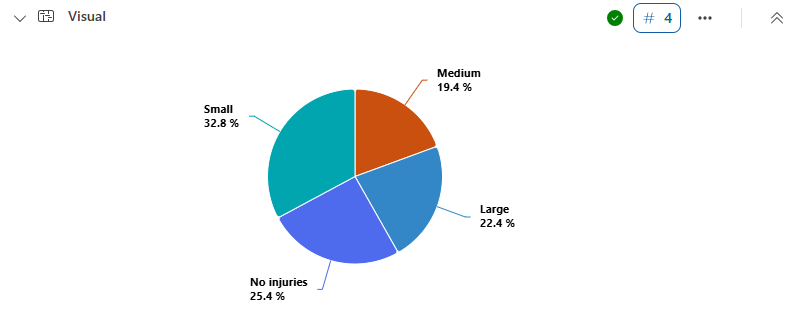
创建饼图,以将风暴导致了大量、中等数量或少量伤害的州的比例可视化。
StormEvents
| summarize InjuriesCount = sum(InjuriesDirect) by State
| extend InjuriesBucket = case (
InjuriesCount > 50,
"Large",
InjuriesCount > 10,
"Medium",
InjuriesCount > 0,
"Small",
"No injuries"
)
| summarize InjuryBucketByState=count() by InjuriesBucket
| render piechart
对滑动窗口执行聚合
以下示例展示了如何使用滑动窗口来汇总列。
该查询使用 7 天的滑动窗口计算龙卷风、洪水和野火的最小、最大和平均财产损失。 结果集中的每条记录都聚合前七天的数据,并且结果包含分析期内每一天的记录。
下面是查询的分步说明:
- 将每个记录放入一天箱中(相对于
windowStart)。 - 将箱值加 7 天以设置每条记录的结束范围。 如果值超出由
windowStart和windowEnd确定的范围,则相应地调整该值。 - 从记录的当前日期开始,为每条记录创建一个 7 天的数组。
- 使用 mv-expand 扩展步骤 3 中的数组,以便将每条记录复制为 7 条记录,每条记录之间间隔一天。
- 每天执行聚合。 由于步骤 4 的缘故,此步骤实际上汇总了过去 7 天的数据。
- 从最终结果中排除前 7 天,因为它们没有 7 天的回溯期。
let windowStart = datetime(2007-07-01);
let windowEnd = windowStart + 13d;
StormEvents
| where EventType in ("Tornado", "Flood", "Wildfire")
| extend bin = bin_at(startofday(StartTime), 1d, windowStart) // 1
| extend endRange = iff(bin + 7d > windowEnd, windowEnd,
iff(bin + 7d - 1d < windowStart, windowStart,
iff(bin + 7d - 1d < bin, bin, bin + 7d - 1d))) // 2
| extend range = range(bin, endRange, 1d) // 3
| mv-expand range to typeof(datetime) // 4
| summarize min(DamageProperty), max(DamageProperty), round(avg(DamageProperty)) by Timestamp=bin_at(range, 1d, windowStart), EventType // 5
| where Timestamp >= windowStart + 7d; // 6
输出
以下结果表是截断的。 若要查看完整输出,请运行查询。
| 时间戳 | EventType | min_DamageProperty | max_DamageProperty | avg_DamageProperty |
|---|---|---|---|---|
| 2007-07-08T00:00:00Z | 龙卷风 | 0 | 30000 | 6905 |
| 2007-07-08T00:00:00Z | 洪水 | 0 | 200000 | 9261 |
| 2007-07-08T00:00:00Z | 野火 | 0 | 200000 | 14033 |
| 2007-07-09T00:00:00Z | 龙卷风 | 0 | 100000 | 14783 |
| 2007-07-09T00:00:00Z | 洪水 | 0 | 200000 | 12529 |
| 2007-07-09T00:00:00Z | 野火 | 0 | 200000 | 14033 |
| 2007-07-10T00:00:00Z | 龙卷风 | 0 | 100000 | 31400 |
| 2007-07-10T00:00:00Z | 洪水 | 0 | 200000 | 12263 |
| 2007-07-10T00:00:00Z | 野火 | 0 | 200000 | 11694 |
| ... | ... | ... |
下一步
熟悉常用的查询运算符和聚合函数后,请继续学习下一篇教程,了解如何联接多个表中的数据。