使用结构化文档处理模型 (布局方法) 自动标识字段和表值。 它最适合结构化或半结构化文档,例如表单和发票。
使用任意格式文档处理模型 (任意多边形选择方法) 自动从非结构化文档和任意格式文档(如字母和合同)中提取信息。
注意
Microsoft尊重用于在 Syntex 中训练和处理模型的数据的隐私和所有权。 Microsoft使用或传输任何组织数据来训练 AI 模型、大语言模型或任何其他模型。 数据安全地保留在组织的租户中。 有关详细信息,请参阅 Microsoft数据保护和隐私。
结构化模型和任意多边形模型简介
Microsoft Syntex使用 Microsoft Power Apps AI Builder 直接在 SharePoint 文档库中启用结构化和任意格式的文档处理。
借助 AI Builder,你可以创建使用机器学习识别和提取各种文档类型的键值对和表数据的模型,包括结构化或半结构化格式(如表单和发票)以及合同和信件等非结构化格式。
例如,组织通常通过邮件、传真或电子邮件接收大量发票。 手动处理和输入此数据可能非常耗时。 Syntex 使用 AI 提取文本、键值对和表,从而简化了此过程,自动捕获数据并减少手动工作量。
可以创建结构化或任意格式的文档处理模型,这些模型可自动识别并提取上传到 SharePoint 文档库的文件中的重要信息。
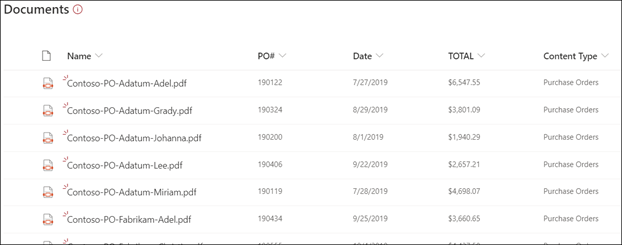
若要开始,请使用示例文件来训练模型。 Microsoft Syntex使用这些示例来了解文档的布局,并确定键值对和表。 你只需要五个示例文档即可开始。 在训练期间,可以查看和手动标记未自动检测到的任何字段。 AI Builder 还允许使用示例文件测试模型的准确性。
只能在启用了 Syntex 的 SharePoint 库中创建文档处理模型。 如果可用,可在库的命令栏中看到 “分类和提取 ”选项。
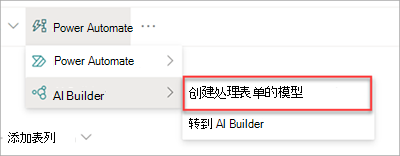
如果未看到此选项,请与 Microsoft 365 管理员联系,为库启用Microsoft Syntex。
要求和限制
有关选择此模型时要考虑的要求的信息,请参阅 结构化和自由格式文档处理的要求和限制。