以下示例显示自定义指标的各种计算方法,重点是正确地选择上下文/聚合。 要获取受支持的运算符(如统计信息、日历或数学函数)的完整列表,请转到自定义指标。
数据集说明
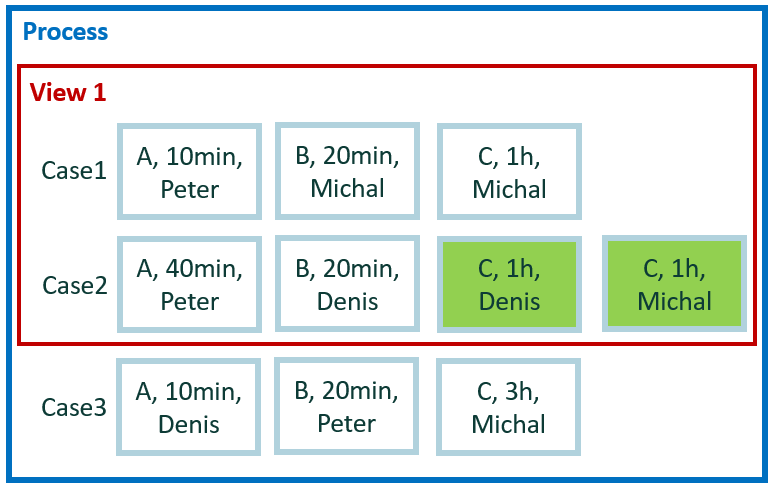
这些示例使用微小数据集。 它包含 3 个案例,10 个事件,有一个定义的视图—三个案例中的两个。 为了便于手动计算,我们假设事件之间的等待时间为零;因此,案例持续时间是事件持续时间的简单总和。 此外,事件之间没有并行性。
1. 事件级聚合(视图)
视图中事件的总持续时间是多长? 我们在实际视图中寻找整个数据集的单个结果。
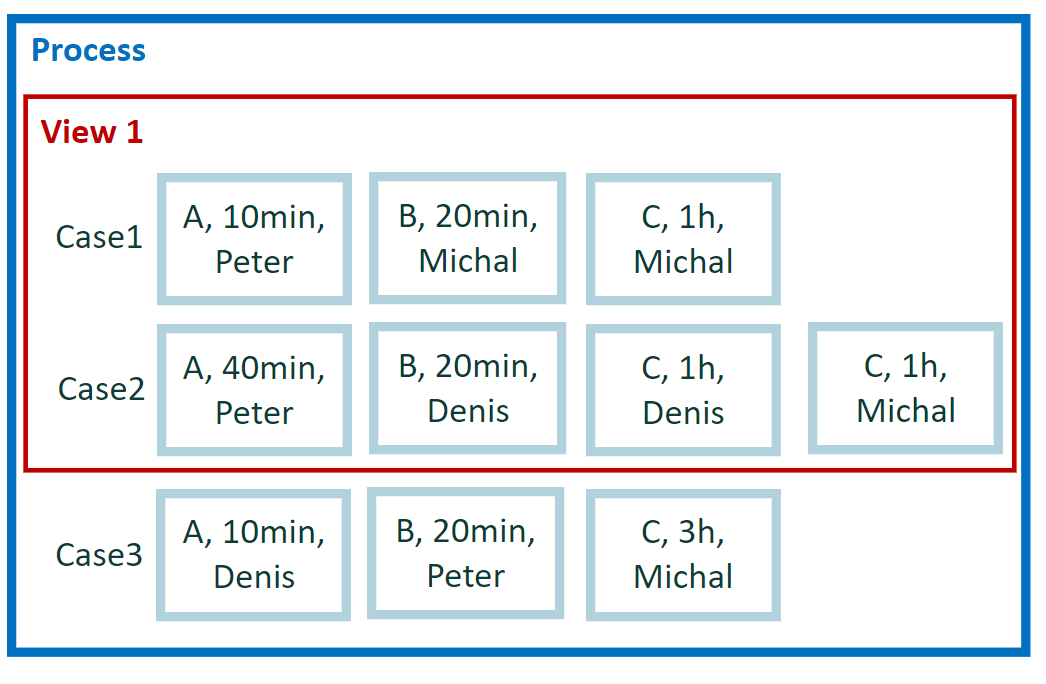
示例 1 的计算
我们需要在视图中对所有可用事件运行。 不考虑将事件分配到案例。 此类计算在整个视图中提供单个结果。当我们手动对所有事件持续时间求和时,我们将得到请求的结果。
示例 1 的结果
4:30 小时(案例 1 中的事件 = 90 分钟 + 案例 2 中的事件 = 180 分钟 = 270 分钟,总计 4:3 小时)
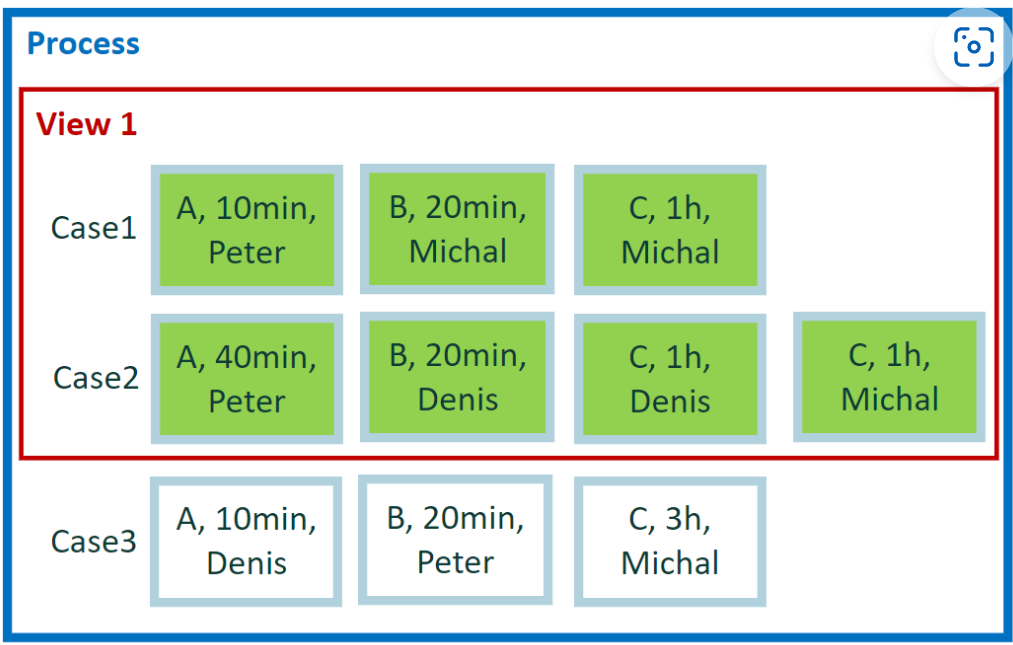
自定义指标公式中的表达式
示例 1 的用法
自定义指标编辑器指示结果适用于 Power Automate Process Mining 桌面应用中的任何地方。 原因是单个结果是一个数值常数,可以用于任何表达式和显示指标的任何地方。 此类指标 - 返回的单个值可以显示在流程图、案例概述统计信息、属性统计信息、筛选器或根本原因分析中。
2. 事件级聚合(流程)
流程中事件的总持续时间是多长? 我们在查找单个全局结果,但不是在视图范围内,而是在完整流程数据的范围内。
示例 2 的计算
在此示例中,我们需要对流程中的所有可用事件运行,而不考虑案例或任何按视图筛选。此类计算在整个视图(流程)中提供单个结果。当我们手动对所有事件持续时间求和时,我们将得到请求的结果。
示例 2 的结果
8:00 小时(案例 1 中的事件 = 1 小时 30 分钟 + 案例 2 中的事件 = 3 小时 + 案例 3 中的事件 = 3 小时 30 分钟,总计 8:00 小时)
自定义指标编辑器中的表达式

示例 2 的用法
结果适用于 Process Mining 桌面应用中的任何地方。 与以上示例相同的应用程序逻辑。
3. 案例事件聚合
每个案例的事件的总持续时间是多长? 我们要求每个案例的结果,而不是单个全局结果。
示例 3 的计算
我们需要计算每个案例的事件持续时间。 由于视图包含两个案例,因此结果数为二 (2)。 每个结果计算为单个案例中事件持续时间的总和。
示例 3 的结果
结果针对每个案例计算。 按案例 1 中的事件和案例 2 中的事件计算,但最重要的是结果针对每个案例计算。
- 案例 1 = 1:30 小时(案例 1 中的事件)
- 案例 2 = 3:00 小时(案例 2 中的事件)
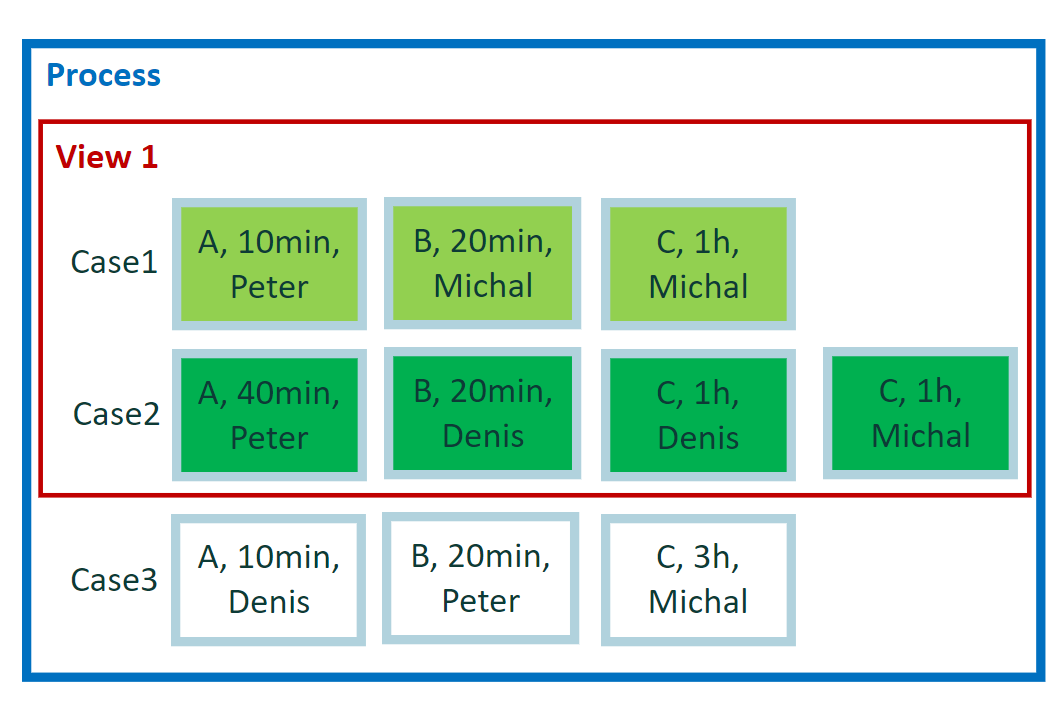
自定义指标编辑器中的表达式

计算上下文 CaseEvents(和 CaseEvents)非常有用,它允许创建使用案例事件计算的其他案例级指标。 然后,用户可以根据计算值评估单个案例。
示例 3 的用法
由于当前视图中每个案例都有一个结果,结果仅在显示每个案例的结果的屏幕中提供:
案例指标筛选器
案例概述统计信息面板
根本原因分析
CaseEvents 或 CaseEdges 的结果不适用于流程图。 理论上,流程图能够显示每个案例的结果,但默认聚合(行业标准)针对每个活动。
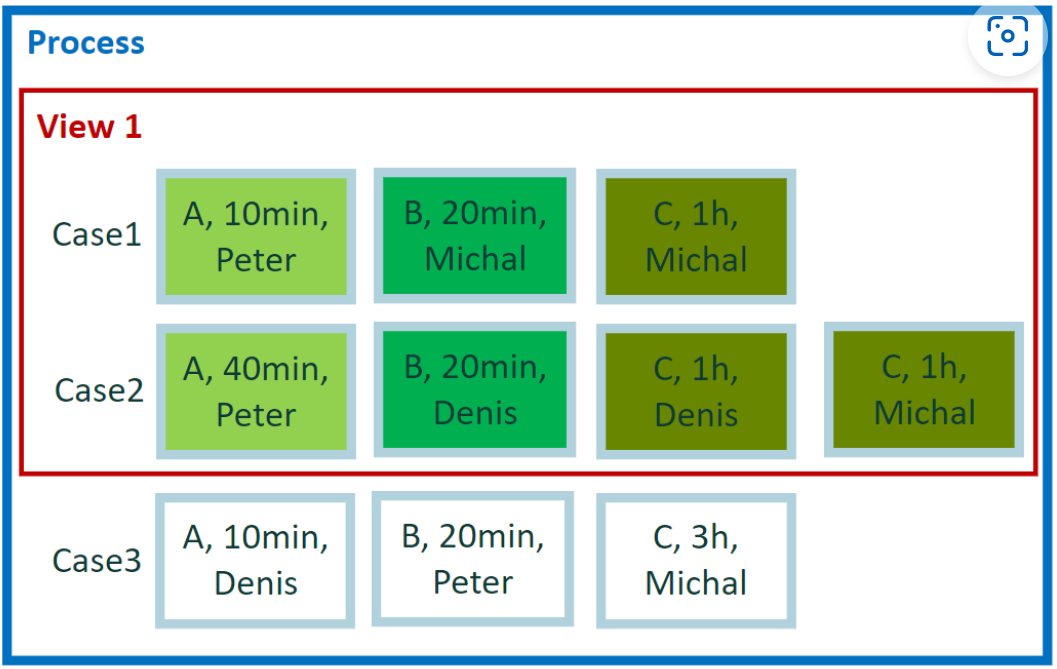
4. 属性聚合
每个活动的总持续时间是多长? 我们对活动的评估感兴趣。 与上一个示例相比,这是一个不同的计算。
示例 4 的计算
如何正确计算每个活动的结果? 我们不关心事件在案例之间的分布。 我们所考虑的只是事件在活动之间的分布。 视图中的所有事件都根据活动值分组。 我们有活动“A”、“B”和“C”。 对于每组事件,我们分别计算结果 - 事件持续时间的总和。
示例 4 的结果
- A = 50 分钟
- B = 40 分钟
- C = 3 个小时
自定义指标编辑器中的表达式

示例 4 的用法
在当前视图中,每个活动有一个结果。结果显示在屏幕上,包含每个活动值的聚合事件:
流程图(节点)
统计信息 – 活动
属性条件筛选器(要了解更多信息,请转到 7 额外:属性条件筛选器。)
任何属性(包括活动)的流程图和统计信息面板共享相同的计算范围。 尽管视觉效果不同,但两个屏幕都显示按活动值分组的结果。
属性条件筛选器包含单个事例中的属性聚合。 例如,案例 2 包含两个具有活动“C”的事件。 属性条件筛选器对这些事件进行聚合,将计算聚合值。 要了解有关此筛选器的行为的详细信息,请转到 7 额外:属性条件筛选器。
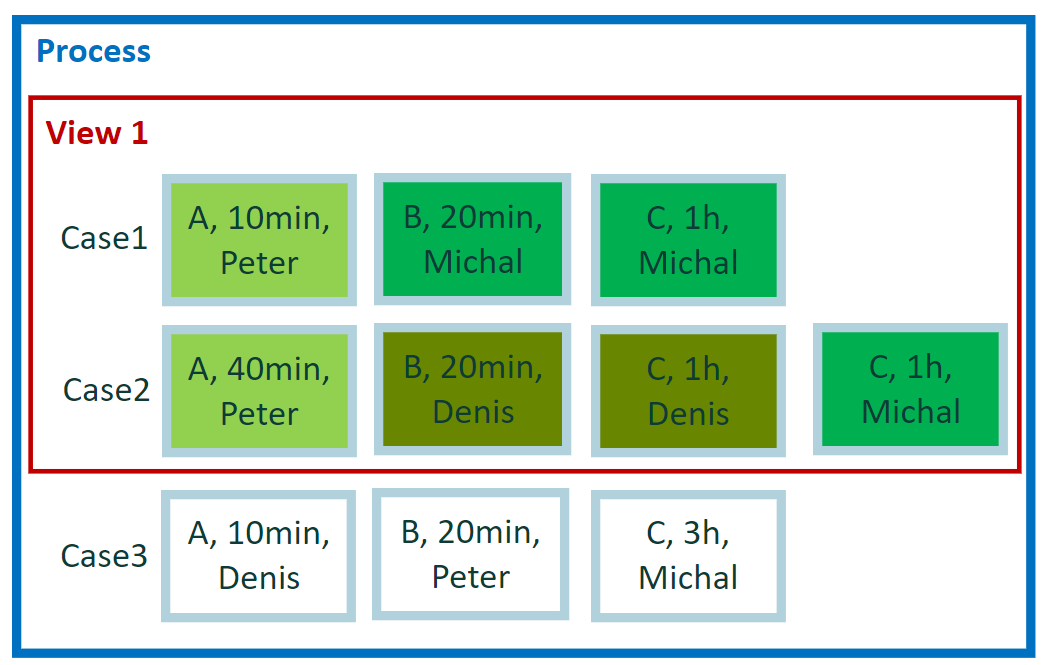
5 一般属性聚合
每个用户的总持续时间是多长? 我们关心的是花费的总时间,不是按活动,而是按用户。
示例 5 的计算
此示例与前一个示例相似。 我们再次考虑事件在其中一个属性中的分布。 这一次是用户属性。 我们有用户“Peter”、“Michal”和“Denis”。 对于每组事件,我们分别计算结果 - 事件持续时间的总和。
示例 5 的结果
- Peter = 50 分钟(案例 1 中的事件 = 10 分钟 + 案例 2 中的事件 = 40 分钟,总计 50 分钟)
- Michal = 2:20 小时(案例 1 中的事件 = 1:20 小时 + 案例 2 中的事件 = 1 小时,总计 2:20 小时)
- Denis = 1:20 小时(案例 2 中的事件 = 1:20 小时)
自定义指标编辑器中的表达式:
为什么表达式与上一个表达式相同? 很简单。 每个属性值的计算对于任何事件属性都是相同的。 活动只是一个特殊的必需事件属性。 所有指标计算都以与任何其他属性相同的方式应用于活动。
示例 5 的用法
在当前视图中,每个属性值同样有一个结果。结果显示在屏幕上,包含每个属性值的聚合事件:
流程图(为什么?)
统计信息 – 任何属性
属性条件筛选器(要了解更多信息,请转到 7 额外:属性条件筛选器。)
如果您想要在 Process Mining 桌面应用中查看每个用户的结果,请转到“用户属性的统计信息”。 会显示按用户属性聚合的事件。 如果我们打开另一个属性的流程图或统计信息面板会怎样。 在这种情况下,结果将按所选属性聚合。 例如,在流程图中,默认为活动属性。
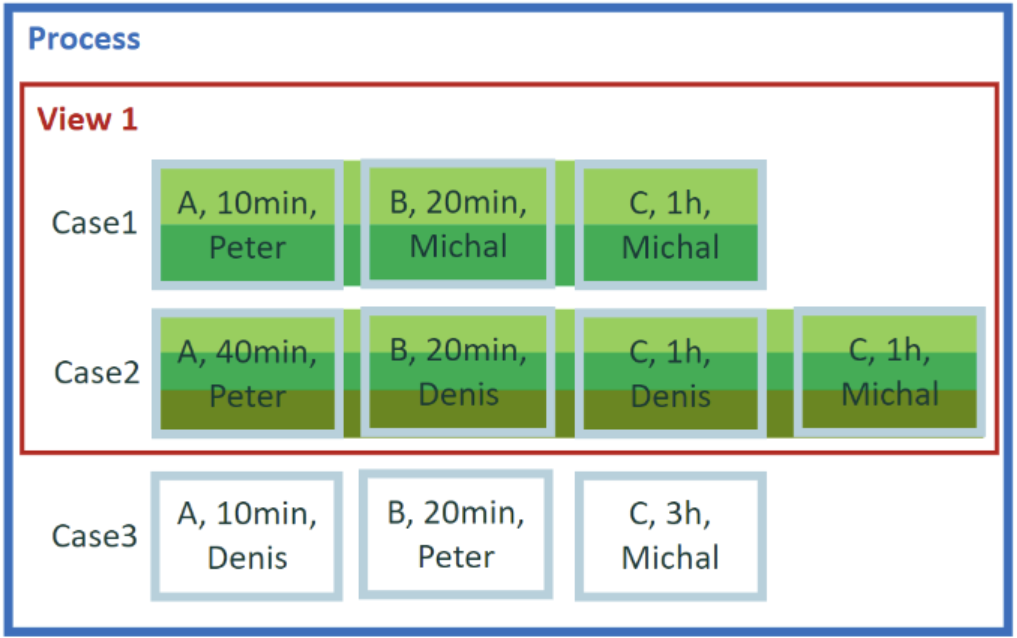
6 案例聚合基于的属性
每个用户处理的案例的总持续时间是多长? 我们同样关注每个用户的结果,但这次我们想要知道用户参与的案例的总持续时间。
示例 6 的计算
此请求的计算逻辑与上一个请求非常相似。 我们按用户属性的值对用户进行分组。 我们有用户“Peter”、“Michal”和“Denis”。 区别在于我们将要汇总的值。 对于每一个事件,我们使用案例的持续时间,而不是事件的持续时间。 用户“Denis”只处理了案例 2,所以对他的答案是案例 2 的持续时间。 用户“Peter”和“Michal”都参与了这两个案例,因此答案是案例 1 和案例 2 的持续时间的组合。
示例 6 的结果
- Peter = 4 小时 30 分钟
- Michal = 4 小时 30 分钟
- Denis = 3 小时
正如您所看到的,我们不关心案例中用户完成了多少事件。 给定用户完成一个或多个事件,案例的长度没有明显改变。 我们不想为同一用户多次使用单个案例的持续时间。 将为每个用户计算结果(属性值),采用案例级指标(案例持续时间,无事件持续时间),结果中最多使用每个案例一次。
虽然此计算看起来很奇怪,但它是用于标准财务案例级指标的非常基本的计算。 无论案例中发生了多少事件、多少返工,发票总计仍然相同。 由于某些事件(活动或用户)在发票处理过程中多次发生,发票总计不会相乘。
自定义指标编辑器中的表达式
示例 6 的用法
每个属性值将生成一个结果,因此属性聚合的所有显示都可用。 当我们使用案例级指标时,结果也适用于边缘(在流程图和统计信息中):
流程图(节点和边缘)
统计信息属性面板(为什么不在案例概述中?)
属性/边缘条件筛选器
不会为每个案例计算结果,而是为每个属性值计算,因此案例概述和案例/事件指标不能用于此类计算。
7 额外:属性条件筛选器
属性条件筛选器包含单个事例中的属性聚合。 这说明在此筛选器中使用按属性值聚合的指标的适用性。
如何筛选 C 活动总持续时间超过 1 小时 30 分钟的案例? 活动 C 的事件数量在案例中并不重要。 唯一的条件是此类事件的总持续时间。
示例 7 的计算
此问题需要按单个案例评估数据集。 在每个案例中,我们查看活动 C 中所有事件的总持续时间,并将其与定义的限制 1 小时 30 分钟进行比较。 案例可能包含零个、一个或多个具有活动 C 的事件,但它不相关。
示例 7 的结果
案例 2
属性条件筛选器是案例级筛选器,评估单个案例。 对于每个案例,它计算每个选定属性值的结果(在我们的示例中为活动 C),并将计算结果与筛选要求进行比较(大于 1 小时 30 分钟)。 由于案例可能包含符合条件(活动 C)的多个事件,因此(必须)根据筛选要求(所有事件的总计)聚合这些事件级值,以在与筛选要求进行比较之前提供单个值。
筛选器定义
筛选器评估首先计算每个案例的每个属性值(活动 C)的聚合结果(总计),然后将此结果与筛选要求进行比较(大于 1 小时 30 分钟)。 因此,聚合每个属性值的结果的任何标准或自定义指标也适用于属性条件筛选器。