概要
| 条目 | DESCRIPTION |
|---|---|
| 发布状态 | 一般可用性 |
| 产品 | Excel Power BI (语义模型) Power BI (数据流) Fabric(Dataflow Gen2) Power Apps(数据流) 分析服务 |
| 支持的身份验证类型 | 基本 数据库 Windows操作系统 |
| 功能参考文档 | SapHana.Database |
注释
由于部署计划和主机特定功能的缘故,某些功能可能在一个产品中存在,而在其他产品中不存在。
先决条件
需要一个 SAP 帐户才能登录到网站并下载驱动程序。 如果不确定,请联系组织中的 SAP 管理员。
若要在 Power BI Desktop 或 Excel 中使用 SAP HANA,必须在本地客户端计算机上安装 SAP HANA ODBC 驱动程序,以便 SAP HANA 数据连接正常工作。 可以从 SAP 开发工具下载 SAP HANA 客户端工具,其中包含必要的 ODBC 驱动程序。 或者,可以从 SAP 软件下载中心获取它。 在软件门户中,搜索适用于 Windows 计算机的 SAP HANA 客户端。 由于 SAP 软件下载中心会频繁更改其结构,因此有关导航该网站的更具体指南不可用。 有关安装 SAP HANA ODBC 驱动程序的说明,请转到 在 Windows 64 位上安装 SAP HANA ODBC 驱动程序。
若要在 Excel 中使用 SAP HANA,必须在本地客户端计算机上安装 32 位或 64 位 SAP HANA ODBC 驱动程序(具体取决于使用的是 32 位还是 64 位版本的 Excel)。
仅当你拥有 Office 2019 或 Microsoft 365 订阅时,才能在 Excel for Windows 中使用此功能。 如果你是 Microsoft 365 订阅者, 请确保拥有最新版本的 Office。
支持 HANA 1.0 SPS 12rev122.09、2.0 SPS 3rev30 和 BW/4HANA 2.0。
支持的功能
- 进口
- 直接查询 (Power BI 语义模型)
- 高级
- SQL 语句
从 Power Query Desktop 连接到 SAP HANA 数据库
若要从 Power Query Desktop 连接到 SAP HANA 数据库,请执行以下作:
在 Power BI Desktop 中选择“获取数据 SAP HANA 数据库”,或者在 Excel 的数据功能区中选择“从数据库>从 SAP HANA 数据库”。
输入要连接到的 SAP HANA 服务器的名称和端口。 下图示例在端口
30015上使用了SAPHANATestServer。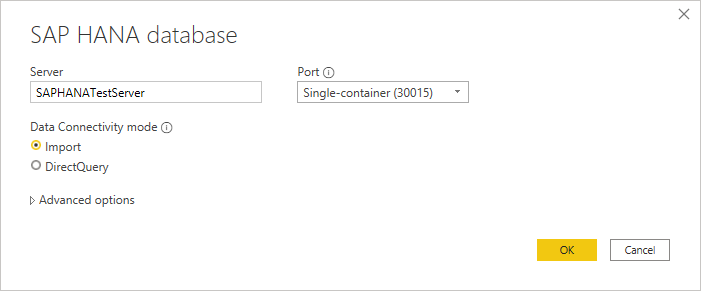
默认情况下,端口号设置为支持单个容器数据库。 如果 SAP HANA 数据库可以包含多个多租户数据库容器,请选择“多容器系统数据库”(30013)。 如果要连接到具有非默认实例编号的租户数据库或数据库,请从“端口”下拉菜单中选择“自定义”。
如果要从 Power BI Desktop 连接到 SAP HANA 数据库,则还可以选择 “导入 ”或“ DirectQuery”。 本文中的示例使用 “导入”,这是默认模式(也是 Excel 的唯一模式)。 有关在 Power BI Desktop 中使用 DirectQuery 连接到数据库的详细信息,请转到 在 Power BI 中使用 DirectQuery 连接到 SAP HANA 数据源。
还可以输入 SQL 语句或从 高级选项启用列绑定。 更多信息,请使用高级选项进行连接
输入所有选项后,选择“ 确定”。
如果第一次访问数据库,系统会要求输入凭据进行身份验证。 在此示例中,SAP HANA 服务器需要数据库用户凭据,因此请选择 “数据库 ”,然后输入用户名和密码。 如有必要,请输入服务器证书信息。
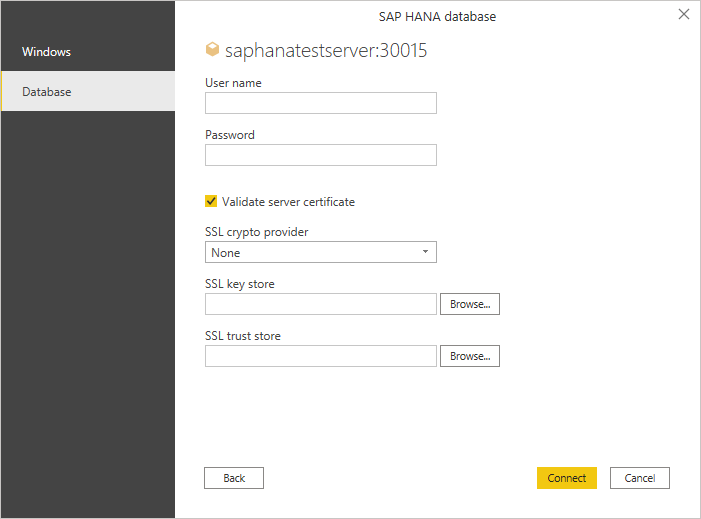
此外,可能需要验证服务器证书。 有关使用验证服务器证书选择的详细信息,请参阅 使用 SAP HANA 加密。 在 Power BI Desktop 和 Excel 中,默认启用验证服务器证书选择。 如果已在 ODBC 数据源管理员中设置这些选择,请清除 “验证服务器证书 ”复选框。 若要详细了解如何使用 ODBC 数据源管理员设置这些选择,请转到 配置 SSL 以便 ODBC 客户端访问 SAP HANA。
有关身份验证的详细信息,请转到 使用数据源进行身份验证。
填写所有必需信息后,选择 “连接”。
在 “导航器 ”对话框中,可以通过选择“ 转换数据”来转换 Power Query 编辑器中的数据,也可以通过选择“ 加载”来加载数据。
从 Power Query Online 连接到 SAP HANA 数据库
若要从 Power Query Online 连接到 SAP HANA 数据,请执行以下作:
在 “数据源 ”页中,选择 “SAP HANA 数据库”。
输入要连接到的 SAP HANA 服务器的名称和端口。 以下图中的示例中,使用
SAPHANATestServer在端口30015上。(可选)输入 高级选项中的 SQL 语句。 有关详细信息, 请使用高级选项进行连接
选择要用于访问数据库的本地数据网关的名称。
注释
无论数据是在本地还是在线,都必须使用本地安装的数据网关来连接此连接器。
选择要用于访问数据的身份验证类型。 还需要输入用户名和密码。
注释
目前,Power Query Online 仅支持基本身份验证。
如果使用任何加密连接,请选择“ 使用加密连接 ”,然后选择 SSL 加密提供程序。 如果未使用加密连接,请清除 “使用加密连接”。 详细信息: 为 SAP HANA 启用加密
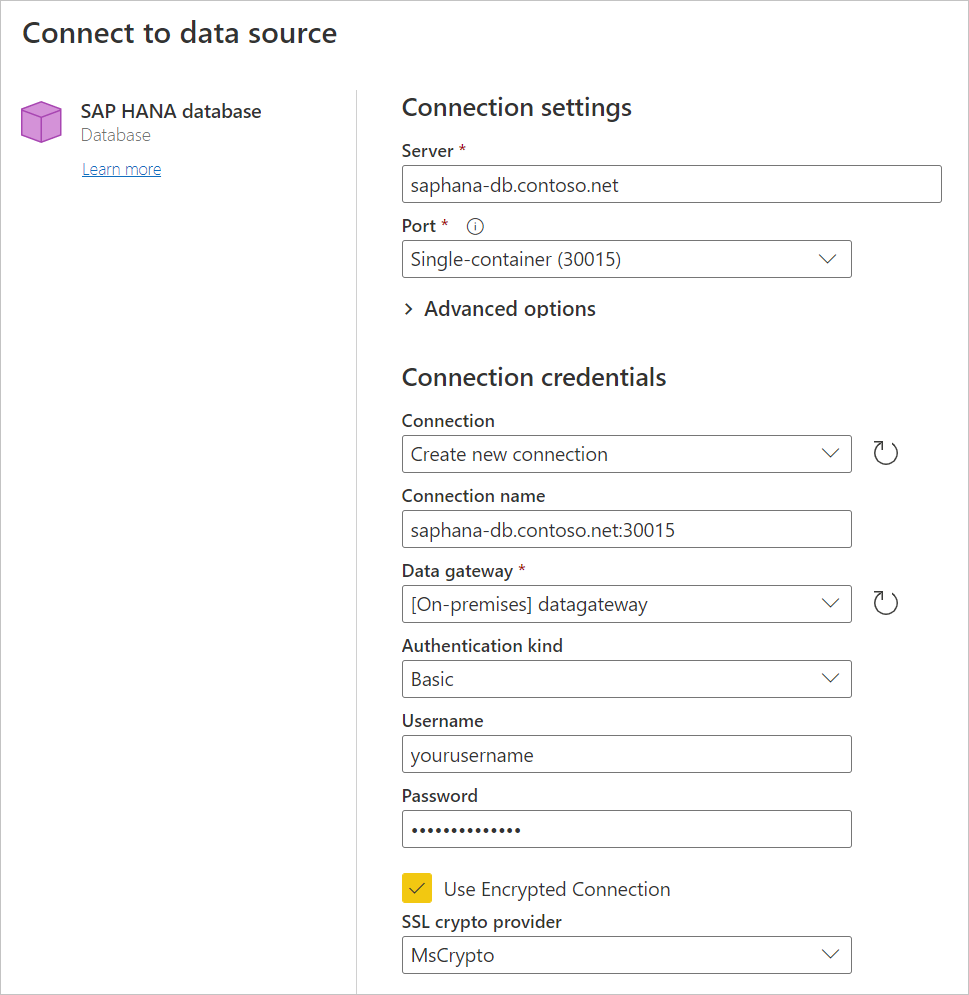
选择“下一步”继续操作。
在 “导航器 ”对话框中,可以通过选择“ 转换数据”来转换 Power Query 编辑器中的数据,也可以通过选择“ 加载”来加载数据。
使用高级选项进行连接
Power Query 提供一组高级选项,可以根据需要将这些选项添加到查询中。
下表描述了可在 Power Query 中设置的所有高级选项。
| 高级选项 | DESCRIPTION |
|---|---|
| SQL 语句 | 有关详细信息,请使用本地数据库查询从数据库导入数据 |
| 启用列绑定 | 在提取数据时,将变量绑定到 SAP HANA 结果集的列。 可能会以略高内存利用率的成本提高性能。 此选项仅在 Power Query Desktop 中可用。 详细信息: 启用列绑定 |
| ConnectionTimeout | 一个持续时间,用于控制在放弃尝试与服务器建立连接之前等待的时间。 默认值为 15 秒。 |
| CommandTimeout | 一个持续时间,用于控制允许服务器端查询在取消之前运行的时间。 默认值为 10 分钟。 |
SAP HANA 支持的功能
以下列表显示了 SAP HANA 支持的功能。 SAP HANA 数据库连接器的所有实现都不支持此处列出的所有功能。
适用于 SAP HANA 数据库的 Power BI Desktop 和 Excel 连接器都使用 SAP ODBC 驱动程序来提供最佳用户体验。
在 Power BI Desktop 中,SAP HANA 支持 DirectQuery 和导入选项。
Power BI Desktop 支持 HANA 信息模型(如分析和计算视图),并具有优化的导航。
借助 SAP HANA,还可以使用本机数据库查询 SQL 语句中的 SQL 命令连接到 HANA 目录表中的行表和列表,这些表不包括在导航器体验提供的分析/计算视图中。 还可以使用 ODBC 连接器 查询这些表。
Power BI Desktop 包含针对 HANA 模型的优化导航。
Power BI Desktop 支持 SAP HANA 变量和输入参数。
Power BI Desktop 支持基于 HDI 容器的计算视图。
SapHana.Database 函数现在支持连接和命令超时。 详细信息:使用高级选项进行连接
若要在 Power BI 中访问基于 HDI 容器的计算视图,请确保用于 Power BI 的 HANA 数据库用户有权访问存储要访问的视图的 HDI 运行时容器。 若要授予此访问权限,请创建一个允许访问 HDI 容器的角色。 然后将角色分配给将用于 Power BI 的 HANA 数据库用户。 (此用户还必须有权像往常一样从_SYS_BI架构中的系统表读取。有关如何创建和分配数据库角色的详细说明,请参阅官方 SAP 文档。 此 SAP 博客文章 可能是一个很好的起点。
目前,附加到基于 HDI 的计算视图的 HANA 变量存在一些限制。 这些限制是由于 HANA 端的错误。 首先,无法将 HANA 变量应用于基于 HDI 容器的计算视图的共享列。 若要修复此限制,请升级到 HANA 2 版本 37.02 及更高版本或 HANA 2 版本 42 及更高版本。 其次,变量和参数的多条目默认值当前不会显示在 Power BI UI 中。 SAP HANA 中的错误会导致此限制,但 SAP 尚未宣布修复。
启用列绑定
从数据源提取的数据将返回到应用程序为此分配的变量中。 在完成此作之前,应用程序必须将这些变量关联或 绑定到结果集的列;从概念上讲,此过程与将应用程序变量绑定到语句参数相同。 当应用程序将变量绑定到结果集列时,它会将变量(地址、数据类型等)描述到驱动程序。 驱动程序将此信息存储在它为该语句维护的结构中,并在提取行时使用该信息从列中返回值。
目前,使用 Power Query Desktop 连接到 SAP HANA 数据库时,可以选择 “启用列绑定 高级”选项来启用列绑定。
还可以通过在 Power Query 编辑栏或高级编辑器中手动将 EnableColumnBinding 选项添加到连接设置,来启用现有查询或 Power Query Online 中使用的查询的列绑定。 例如:
SapHana.Database("myserver:30015", [Implementation = "2.0", EnableColumnBinding = true]),
存在与手动添加 EnableColumnBinding 选项相关的限制:
- 启用列绑定在“导入”和“DirectQuery”模式下都有效。 但是,无法改造现有的 DirectQuery 查询以使用此高级选项。 相反,必须创建一个新查询才能使此功能正常工作。
- 在 SAP HANA Server 2.0 或更高版本中,列绑定全部或全无。 如果某些列无法绑定,则不会绑定任何列,并且用户将收到异常,例如
DataSource.Error: Column MEASURE_UNIQUE_NAME of type VARCHAR cannot be bound (20002 > 16384)。 - SAP HANA 版本 1.0 服务器并不总是报告正确的列长度。 在此上下文中,
EnableColumnBinding允许部分列绑定。 对于某些查询,这可能意味着没有绑定任何列。 如果未绑定任何列,则不会获得性能优势。
SAP HANA 数据库连接器中的本机查询支持
Power Query SAP HANA 数据库连接器支持原生查询。 有关如何在 Power Query 中使用本机查询的信息,请转到 使用本机数据库查询从数据库导入数据。
基于原生查询的查询折叠
Power Query 的 SAP HANA 数据库连接器现在可以支持对本机查询进行查询折叠。 详细信息:在本机查询中实现查询折叠
注释
在 Power Query SAP HANA 数据库连接器中,当 EnableFolding 设置为 true 时,原生查询不支持重复的列名。
本机查询中的参数
Power Query SAP HANA 数据库连接器现在支持本地查询中的参数。 可以使用 Value.NativeQuery 语法在本机查询中指定参数。
与其他连接器不同,SAP HANA 数据库连接器支持 EnableFolding = True 并同时指定参数。
若要在查询中使用参数,请将问号(?)放在代码中作为占位符。 若要指定参数,请在 Value 中使用 SqlType 文本值和该参数的 SqlType 值。
Value 可以是任何 M 值,但必须分配给指定的 SqlType值。
可通过多种方式指定参数:
仅以列表的形式提供值:
{ “Seattle”, 1, #datetime(2022, 5, 27, 17, 43, 7) }提供值和类型作为列表:
{ [ SqlType = "CHAR", Value = "M" ], [ SqlType = "BINARY", Value = Binary.FromText("AKvN", BinaryEncoding.Base64) ], [ SqlType = "DATE", Value = #date(2022, 5, 27) ] }请任意搭配这两者:
{ “Seattle”, 1, [ SqlType = "SECONDDATE", Value = #datetime(2022, 5, 27, 17, 43, 7) ] }
SqlType 遵循 SAP HANA 定义的标准类型名称。 例如,以下列表包含最常用的类型:
- BIGINT
- 二进制
- 布尔
- 煳
- 日期
- 十进制
- 双倍
- 整数
- NVARCHAR
- SECONDDATE
- SHORTTEXT
- SMALLDECIMAL
- SMALLINT
- 时间
- 时间戳
- VARBINARY
- VARCHAR
以下示例演示如何提供参数值列表。
let
Source = Value.NativeQuery(
SapHana.Database(
"myhanaserver:30015",
[Implementation = "2.0"]
),
"select ""VARCHAR_VAL"" as ""VARCHAR_VAL""
from ""_SYS_BIC"".""DEMO/CV_ALL_TYPES""
where ""VARCHAR_VAL"" = ? and ""DATE_VAL"" = ?
group by ""VARCHAR_VAL""
",
{"Seattle", #date(1957, 6, 13)},
[EnableFolding = true]
)
in
Source
以下示例演示如何提供记录列表(或混合值和记录):
let
Source = Value.NativeQuery(
SapHana.Database(Server, [Implementation="2.0"]),
"select
""COL_VARCHAR"" as ""COL_VARCHAR"",
""ID"" as ""ID"",
sum(""DECIMAL_MEASURE"") as ""DECIMAL_MEASURE""
from ""_SYS_BIC"".""DEMO/CV_ALLTYPES""
where
""COL_ALPHANUM"" = ? or
""COL_BIGINT"" = ? or
""COL_BINARY"" = ? or
""COL_BOOLEAN"" = ? or
""COL_DATE"" = ?
group by
""COL_ALPHANUM"",
""COL_BIGINT"",
""COL_BINARY"",
""COL_BOOLEAN"",
""COL_DATE"",
{
[ SqlType = "CHAR", Value = "M" ], // COL_ALPHANUM - CHAR
[ SqlType = "BIGINT", Value = 4 ], // COL_BIGINT - BIGINT
[ SqlType = "BINARY", Value = Binary.FromText("AKvN", BinaryEncoding.Base64) ], // COL_BINARY - BINARY
[ SqlType = "BOOLEAN", Value = true ], // COL_BOOLEAN - BOOLEAN
[ SqlType = "DATE", Value = #date(2022, 5, 27) ], // COL_DATE - TYPE_DATE
} ,
[EnableFolding=false]
)
in
Source
支持动态属性
SAP HANA 数据库连接器处理计算列的方式得到了改进。 SAP HANA 数据库连接器是一个“多维数据集”连接器,有一组操作(添加项、折叠列等)发生在“多维数据集”空间中。 此立方体空间在 Power Query Desktop 和 Power Query Online 的用户界面中通过“立方体”图标展示,替代了更常见的“表”图标。
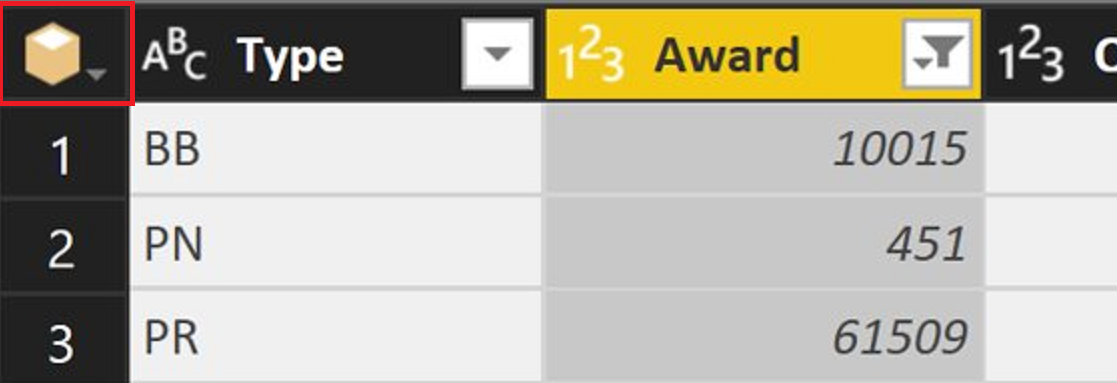
之前,当您添加表列(或进行另一个会在内部增加列的转换)时,查询将“脱离多维数据集空间”,所有操作都将在表级别进行。 在某些时候,此退出可能会导致查询停止折叠。 在添加列之后,执行多维数据集操作已不可行。
通过此更改,添加的列被视为多维数据集中的 动态属性 。 如果查询仍保留在多维数据集空间中,其优点是即使在添加列后也可继续进行多维数据集操作。
注释
只有在连接到 SAP HANA Server 2.0 或更高版本中的计算视图时,此新功能才可用。
以下示例查询利用这一新功能。 过去,当应用Cube.CollapseAndRemoveColumns 时,会收到“该值不是立方体”的异常。
let
Source = SapHana.Database(“someserver:someport”, [Implementation="2.0"]),
Contents = Source{[Name="Contents"]}[Data],
SHINE_CORE_SCHEMA.sap.hana.democontent.epm.models = Contents{[Name="SHINE_CORE_SCHEMA.sap.hana.democontent.epm.models"]}[Data],
PURCHASE_ORDERS1 = SHINE_CORE_SCHEMA.sap.hana.democontent.epm.models{[Name="PURCHASE_ORDERS"]}[Data],
#"Added Items" = Cube.Transform(PURCHASE_ORDERS1,
{
{Cube.AddAndExpandDimensionColumn, "[PURCHASE_ORDERS]", {"[HISTORY_CREATEDAT].[HISTORY_CREATEDAT].Attribute", "[Product_TypeCode].[Product_TypeCode].Attribute", "[Supplier_Country].[Supplier_Country].Attribute"}, {"HISTORY_CREATEDAT", "Product_TypeCode", "Supplier_Country"}},
{Cube.AddMeasureColumn, "Product_Price", "[Measures].[Product_Price]"}
}),
#"Inserted Year" = Table.AddColumn(#"Added Items", "Year", each Date.Year([HISTORY_CREATEDAT]), Int64.Type),
#"Filtered Rows" = Table.SelectRows(#"Inserted Year", each ([Product_TypeCode] = "PR")),
#"Added Conditional Column" = Table.AddColumn(#"Filtered Rows", "Region", each if [Supplier_Country] = "US" then "North America" else if [Supplier_Country] = "CA" then "North America" else if [Supplier_Country] = "MX" then "North America" else "Rest of world"),
#"Filtered Rows1" = Table.SelectRows(#"Added Conditional Column", each ([Region] = "North America")),
#"Collapsed and Removed Columns" = Cube.CollapseAndRemoveColumns(#"Filtered Rows1", {"HISTORY_CREATEDAT", "Product_TypeCode"})
in
#"Collapsed and Removed Columns"
局限性
以下限制适用于 Power Query SAP HANA 数据库连接器。
通过代理连接到 SAP HANA 数据库
SAP HANA 数据库连接器不支持通过代理连接到云数据库。 若要解决此问题,请改用 ODBC 连接器 ,并在 DSN 或连接字符串中指定代理设置。
后续步骤
以下文章包含更多信息,您在连接到 SAP HANA 数据库时可能会发现这些信息很有用。