在Power Query中,可以通过根据一列或多列中的值对行进行分组,将各种行中的值分组为单个值。 可以从两种类型的分组操作中进行选择:
列分组。
行分组。
在本教程中,你将使用以下示例表。
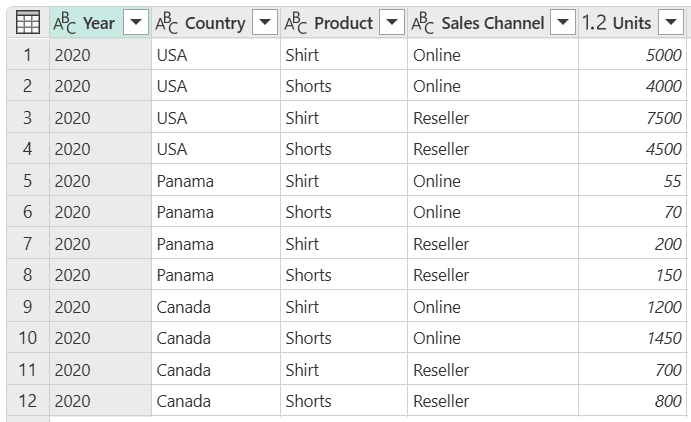
显示年份(2020)、国家/地区(美国、巴拿马或加拿大)、产品(衬衫或短裤)、销售渠道(在线或经销商)和数量(从 55 到 7500 的各种值)的表格的屏幕截图
在哪里可以找到“分组依据”按钮
可以在三个位置通过 按钮找到
在“主页”选项卡的“转换”组中。

在“转换”选项卡的“表”组中。

在快捷菜单上,右键单击以选择列。
使用聚合函数按一个或多个列进行分组
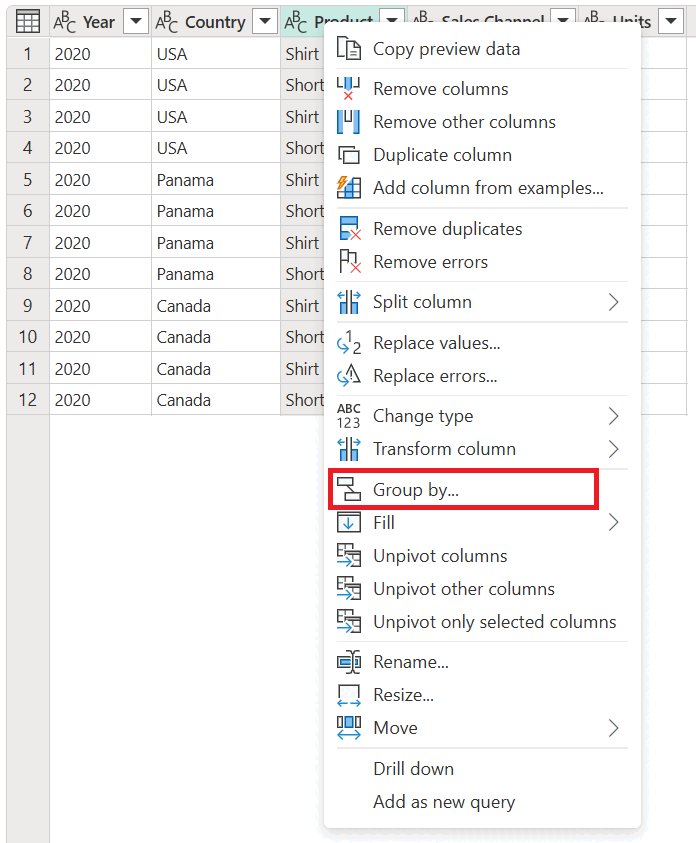
在此示例中,目标是汇总国家/地区和销售渠道级别销售的总单位数。 可以使用“国家/地区”和“销售渠道”列来执行“分组依据”操作。
- 选择分组依据在主页选项卡上。
- 选择“高级”选项,以便选择分组所依据的多个列。
- 选择“国家/地区”列。
- 选择添加分组。
- 选择“销售渠道”列。
- 在 新列名中,输入 单位总数,在 操作中,选择 总和,然后在 列中,选择 单位。
- 选择“确定”

此操作生成下列表格。

可用操作
使用 Group by 功能,可以使用两种方式对可用操作进行分类:
- 行级操作
- 列级操作
下表描述了其中每个操作。
| 操作名称 | 类别 | 描述 |
|---|---|---|
| 求和 | 列操作 | 汇总列中的所有值 |
| 平均值 | 列操作 | 计算列中的平均值 |
| 中值 | 列操作 | 从列计算中值 |
| 最小值 | 列操作 | 计算列中的最小值 |
| 最大值 | 列操作 | 计算列中的最大值 |
| 百分位数 | 列操作 | 使用来自列的输入值(范围为0到100)计算百分位数 |
| 统计非重复值 | 列操作 | 计算列中非重复值的数量 |
| 统计行数 | 行操作 | 计算给定组中的总行数 |
| 统计非重复行 | 行操作 | 计算给定组中的非重复行数 |
| 所有行 | 行操作 | 输出没有聚合的表值中的所有分组行 |
注意
计数不同值和 百分位数 操作仅在 Power Query Online 中可用。
执行按一个或多个列分组的操作
从原始示例开始,在本示例中,将创建一个包含总量的列,以及另外两个列,其中提供了绩效最高的产品的名称和销量,并在国家/地区和销售渠道级别进行汇总。

使用以下列作为“分组依据”列:
- 国家
- 销售渠道
按照以下步骤创建两个新列:
- 通过“求和”操作对“数量”列进行聚合。 将此列命名为 总单位数。
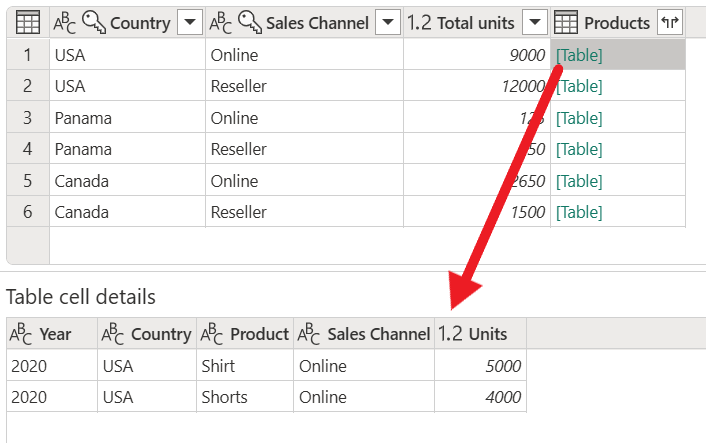
- 使用“所有行”操作添加一个新的“产品”列。

操作完成后,请注意 “产品” 列每个单元格中显示了 [表] 值。 每个 [表] 值都包含原始表中的 “国家/地区 ”和 “销售频道 ”列分组的所有行。 可以选择单元格内的空白区域,以查看对话框底部表格内容的预览。
注意
详细信息预览窗格可能不会显示用于分组依据操作的所有行。 可以选择 [表] 值以查看与相应分组操作相关的所有行。
接下来,需要在新“产品”列中提取表的“数量”列中具有最高值的行,并将该新列命名为“绩优产品”。
提取性能最高的产品信息
使用具有 [表]值的“新产品”列,可以通过转到功能区上的“添加列”选项卡并选择“常规”组中的“自定义”列来创建新的自定义列。
![]()
将新列命名为“Top performer product”。 在“自定义列公式”中输入公式 Table.Max([Products], "Units" )。

该公式的结果使用 [Record] 值创建新列。 这些记录值实质上是一个仅包含一行的表。 这些记录包含“产品”列中每个[表]值的单位列最大值的行。

使用此包含 [Record] 值的全新顶级产品列,可以选择展开图标,选择![]() “产品和单位”字段,然后选择“确定”。
“产品和单位”字段,然后选择“确定”。

删除 “产品 ”列并设置新扩展列的数据类型后,结果如下图所示。

模糊分组
注意
以下功能仅在 Power Query Online 中可用。
若要演示如何执行“模糊分组”,请考虑下图所示的示例表。
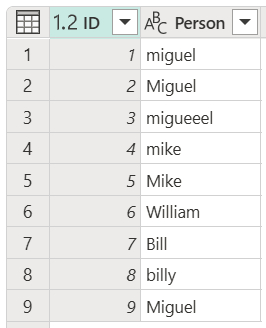
模糊分组的目标是执行一种对文本字符串使用近似匹配算法的分组操作。 Power Query使用 Jaccard 相似性算法来度量实例对之间的相似性。 然后,它将凝聚层次聚类用于将实例归类在一起。 下图展示了预期的输出,其中表已根据“人员”列进行分组。
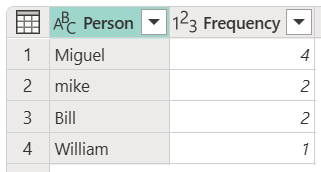
若要执行模糊分组,请执行本文前面所述的相同步骤。 唯一的区别在于,这次在“分组依据”对话框中选中“使用模糊分组”复选框。

对于每组行,Power Query选择最常见的实例作为“规范”实例。 如果多个实例出现的频率相同,Power Query选取第一个实例。 在“分组依据”对话框中选择“确定”后,将得到预期的结果。
但是,通过展开 模糊组选项,您可以更好地控制模糊分组操作。

以下选项可用于模糊分组:
- 相似性阈值(可选):此选项指示必须将两个值组合在一起的方式。 最小设置为零(0)会导致所有值组合在一起。 最大设置为 1 仅允许完全匹配的值组合在一起。 默认值为 0.8。
- 忽略大小写:比较文本字符串时,将忽略大小写。 此选项默认处于启用状态。
- 组合文本部件:算法尝试将文本部件(如将 Micro 和 soft 合并为 Microsoft) 来对值进行分组。
- 显示相似性分数:在模糊分组后显示输入值与计算代表值之间的相似性分数。 需要添加诸如“所有行”的操作以逐行显示这些信息。
- 转换表(可选):可以选择一个转换表,将值(例如将 MSFT 映射到 Microsoft)来将它们组合在一起。
在此示例中,转换表用于演示如何映射值。 转换表有两列:
- 从:要在表中查找的文本字符串。
- 到:用于替换“从”列中的文本字符串的文本字符串。
下图显示了此示例中使用的转换表。
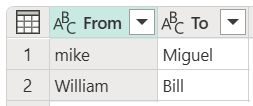
重要
转换表必须具有相同的列和列名称,如上图中所示(它们必须标记为“From”和“To”)。 否则,Power Query无法将表识别为转换表。
返回到“ 分组依据 ”对话框,展开 模糊组选项,将操作从 “计数行 ”更改为“ 所有行”,启用“ 显示相似性分数 ”选项,然后选择“ 转换表 ”下拉菜单。

选择转换表后,选择“确定”。 该操作的结果提供以下信息:

在此示例中,已启用 “忽略大小写” 选项,因此转换表的 From 列中的值用于查找文本字符串,而不考虑字符串的大小写。 此转换操作首先发生,然后执行模糊分组操作。
相似性分数也显示在人员列旁边的表值中,这反映了值分组方式及其各自的相似性分数。 如果需要,可以展开此列,或使用新 频率 列中的值进行其他类型的转换。
注意
按多个列分组时,如果替换值会增加相似性分数,转换表会在所有列中执行替换操作。
有关转换表工作原理的更多信息,请访问 转换表原理。