重要
对机器学习工作室(经典)的支持将于 2024 年 8 月 31 日结束。 建议在该日期之前转换到 Azure 机器学习。
从 2021 年 12 月 1 日开始,你将无法创建新的机器学习工作室(经典)资源。 在 2024 年 8 月 31 日之前,可继续使用现有的机器学习工作室(经典)资源。
ML 工作室(经典)文档即将停用,将来可能不会更新。
使指定的概率分布函数适合数据集
类别: 统计函数
模块概述
本文介绍如何使用 机器学习 Studio (经典) 中的“评估概率函数”模块来计算描述列分布的统计度量值,例如伯努利、帕托或 Poisson 分布。
若要使用此模型,请连接包含至少一列数值的数据集,然后选择要测试的概率分布。 该模块返回一个数据表,其中包含指定概率函数中的值。
可以为所选概率分布计算以下任何值:
- 累积分布函数 (cdf)
- inverseCdf) inverseCdf (逆累积分布函数
- pdf) 的概率密度函数 (
为什么概率分布很有用?
根据概率分布评估数据时,将针对具有已知属性的一组值映射列值。 通过知道数据是否对应于这些已知分布之一,你也许能够推断出数据的其他属性。 一般而言,可以确定最适合该数据的分布时,便可以从模型中获得更好的预测。
具体使用哪个概率分布函数取决于当前测量的数据和变量。 例如,某些分布旨在描述离散值的概率;其他变量仅用于连续数值变量。 对于某些分发版,还必须提前知道预期平均值、自由度等。 有关详细信息,请参阅 支持的概率分布
如何配置 Evaluate Probability 函数
所有选项都会根据要计算的概率分布类型而更改。 如果更改概率分布方法,则可能已重置其他选择。
因此,请务必首先选择 “分发 ”选项!
用作输入的数据集应包含数值数据。 将忽略其他类型的数据。
对于每个分析,可以应用单个概率分布方法。 若要计算不同的概率分布,请为要测试的每个分布添加模块的单独实例。
连接包含至少一列数字的数据集。
使用 “分布 ”选项选择要计算的概率分布类型。 有关选项列表及其必需参数,请参阅 支持的概率分布 。
设置该分布所需的任何参数。
选择要创建的三个统计信息之一:累积分布函数 (cdf) 、反向累积分布函数 (InverseCdf) ,或 pdf) 的概率密度 (函数。
使用列选择器选择要计算所选概率分布的列。
选择的所有列都必须具有数值数据类型。
对于所选的概率函数,列中的数据范围还必须是有效的。 否则可能会出现错误或 NaN 结果。
对于稀疏列,将不处理对应于背景零的任何值。
使用 结果模式 选项指定如何输出结果。 你可以将列值替换为概率分布值,将新值追加到数据集,也可以只返回概率分布值。
运行试验,或右键单击 “评估概率函数 ”模块,然后单击 “运行”已选中。
结果
下表包含使用 Append 选项对 森林火灾 示例数据集中的单个温度列的结果示例。
| temp | StandardNormal.Cdf (temp) | StandardNormal.Pdf (临时) | FFisher.cdf (temp | FFisher.cdf (temp |
|---|---|---|---|---|
| 8.2 | 1 | 1 | 0.984774 | 0.004349 |
| 18 | 1 | 1 | 0.997896 | 0.000311 |
| 14.6 | 1 | 1 | 0.996352 | 0.000648 |
| 8.3 | 1 | 1 | 0.985201 | 0.004187 |
| 11.4 | 1 | 1 | 0.993147 | 0.001502 |
生成的列的标题包含使用的概率分布。
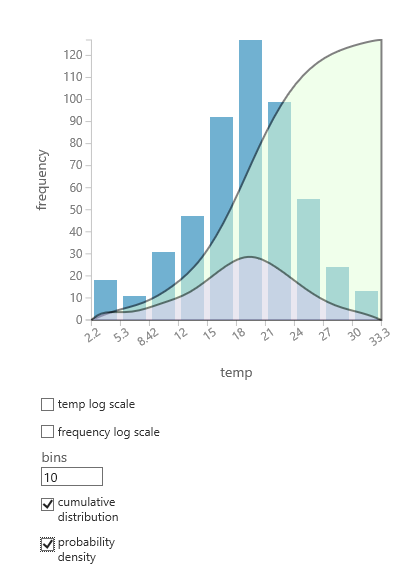
如果不确定哪些概率分布可能适合数据,可以为任何数值列创建累积分布和概率密度的快速图表。
- 右键单击数据集或模块输出,然后选择“ 可视化”。
- 选择感兴趣的列,然后在 直方图 窗格中,选择 累积分布 或 概率密度。
- 分布图(如下所示)叠加在表示数据的直方图上。
支持的概率分布
评估概率函数模块支持以下分布:
伯努利
伯努利分布是二进制值的分布:换句话说,当可能只有两个值时,它对预期分布进行建模。
若要计算,请选择 Bernoulli,并设置以下选项:
- 成功的概率
参数 p 指定生成 1 的概率。 键入一个介于 0.0 和 1.0 之间的数字 (float),用于指定成功的概率。 默认值为 .5。
Beta
Beta 分布是连续的单变量分布。
若要计算,请选择 Beta,并设置以下选项:
形状
键入一个用于更改分布形状的值。形状参数是概率分布的任意参数,不用于定义分布的位置或比例。 因此,当你输入一个形状值时,该参数将更改分布的形状,但不会移动、拉伸或收缩分布。
该值必须是一个数字 (
double)。 默认值为 1.0。缩放
键入用于缩放分布的数字。通过将缩放值应用于分布,可以收缩或拉伸分布。
默认值为 1.0。 值必须是正数。
上限
键入一个数字 (double) 来表示分布的上限。 默认值为 1.0。下限
键入一个数字 (double) 来表示分布的下限。 默认值为 0.0。
二项
二项式分布是离散的单变量分布。 二项分布用于为样本中的成功次数建模。 在采样时使用替换。 对于未使用替换的采样,请使用超几何分布。
若要计算,请选择 二项式,并设置以下选项:
成功的概率
键入一个介于 0.0 和 1.0 之间的数字 (float),用于指示成功的概率。 默认值为 .5。试验的次数
指定试验的次数。使用最小值为 1 的 a
integer。 默认值为 3。
柯西
柯西分布是对称而连续的概率分布。
若要计算,请选择 Cauchy,并设置以下选项:
位置
键入表示第 0 个元素位置的数字 (double) 。通过指定“位置”参数的值,你可以上移或下移数字比例。
默认值为 0.0。
卡方
奇方分布是 k 独立、标准、正态、随机变量的平方和。
若要计算,请选择 ChiSquare,并设置以下选项:
- 自由度数 键入数字 (
double) 以指定自由度。 默认值为 1.0。
ChiSquareRightTailed
此选项提供右尾奇方分布。
若要计算,请选择 ChiSquareRightTailed,并设置以下选项:
- 自由度数
键入一个数字 (double) 来指定自由度。 默认值为 1.0。
指数
指数分布是通过一个非负参数进行参数化的实数的分布。
若要计算,请选择 “指数”,并设置以下选项:
- Lambda
键入一个数字 (double) 来用作 lambda 参数。 默认值为 1.0。
FFisher
为样本(也称为 Fisher F 分布)生成 Fisher 统计信息的概率。 此分布为双尾。
若要计算,请选择 FFisher,并设置以下选项:
自由度的分子
键入一个数字 (double) 来指定在分子中使用的自由度。 默认值为 3.0。自由度的分母
键入一个数字 (double) 来指定在分母中使用的自由度。 默认值为 6.0。
FFisher 右尾
创建右尾费舍尔分布。 Fisher 分布也称为 Fisher F-分布、Snedecor 分布或 Fisher Snedecor 分布。 此特定形式的分布为右尾。
若要计算,请选择 FFisherRightTailed,并设置以下选项:
自由度的分子
键入一个数字 (double) 来指定在分子中使用的自由度。 默认值为 3.0。自由度的分母
键入一个数字 (double) 来指定在分母中使用的自由度。 默认值为 6.0。
Gamma
Gamma 分布是一系列连续的概率分布,具有两个参数。 例如,卡方分布是 Gamma 分布的一个特例。
若要计算,请选择 Gamma 并设置以下选项:
缩放
键入用于缩放分布的值。通过将缩放值应用于分布,可以收缩或拉伸分布。
默认值为 1.0。 值必须是正数。
位置
键入表示第 0 个元素位置的数字 (double) 。通过指定“位置”参数的值,你可以上移或下移数字比例。
默认值为 0.0。
广义极值
创建开发用于处理极端值的分布。 通用极值 (GEV) 分布实际上是一组连续概率分布,它结合了古贝尔、弗雷切特和韦布尔分布 (也称为类型 I、II 和 III 极端值分布) 。
有关极端价值理论的详细信息,请参阅维基百科文章: Fisher-Tippet-Gnedenko 定理。
若要计算,请选择 GeneralizedExtremeValues,并设置以下选项:
形状
键入一个用于更改分布形状的值。形状参数是概率分布的任意参数,不用于定义分布的位置或比例。 因此,当你输入一个形状值时,该参数将更改分布的形状,但不会移动、拉伸或收缩分布。
该值必须是一个数字 (
double)。 默认值为 1.0。缩放
键入用于缩放分布的值。通过将缩放值应用于分布,可以收缩或拉伸分布。
默认值为 1.0。 值必须是正数。
位置
键入表示第 0 个元素位置的数字 (double) 。通过键入“位置”参数的值,你可以上移或下移数字比例。
默认值为 0.0。
几何
几何分布是一个正整数的分布,由一个正实数参数化。
若要计算,请选择 “几何”,并设置以下选项:
- 成功的概率
键入一个介于 0.0 和 1.0 之间的数字 (float),用于指示成功的概率。 默认值为 .5。
注意
几何分布的此实现不会生成零。
耿贝尔最大极值
耿贝尔分布是几个极值分布中的一个。 GumbelMax 选项用于实现最大极值类型 1 分布。
若要计算,请选择 GumbelMax,并设置以下选项:
缩放
键入用于缩放分布的值。通过将缩放值应用于分布,可以收缩或拉伸分布。
默认值为 1.0。 值必须是正数。
位置
键入表示第 0 个元素位置的数字 (double) 。通过键入“位置”参数的值,你可以上移或下移数字比例。
默认值为 0.0。
耿贝尔最小极值
耿贝尔分布是几个极值分布中的一个。 耿贝尔分布也称为最小极值 (SEV) 分布或最小极值(类型 I)分布。 GumbelMin 选项实现最小极值类型 1 分布。
若要计算,请选择 GumbelMin,必须设置以下选项:
缩放
键入用于缩放分布的值。通过将缩放值应用于分布,可以收缩或拉伸分布。
默认值为 1.0。 值必须是正数。
位置
键入表示第 0 个元素位置的数字 (double) 。通过键入“位置”参数的值,你可以上移或下移数字比例。
默认值为 0.0。
超几何
超对称分布是一种离散概率分布,用于描述 n 个序列中成功次数,该序列中的成功数与不替换的有限群体相差,就像二项式分布描述使用替换绘制的成功次数一样。
若要计算,请选择 “超对称”,并设置以下选项:
样本数
键入一个整数来指示要使用的样本数。 默认值为 9。成功的次数
键入一个整数来定义成功的次数值。 默认值为 24。群体大小
指定在估算超几何分布时要使用的群体大小。
拉普拉斯
Laplace 分布是实数的分布,由平均值和刻度参数参数参数。
若要计算,请选择 Laplace 分布,并设置以下选项:
缩放
键入用于缩放分布的值。通过将缩放值应用于分布,可以收缩或拉伸分布。
默认值为 1.0。 值必须是正数。
位置
键入表示第 0 个元素位置的数字 (double) 。通过键入“位置”参数的值,你可以上移或下移数字比例。
默认值为 0.0。
逻辑
逻辑分布类似于正态分布,但它对分布的左侧没有限制。 逻辑分布在逻辑回归和神经网络模型中使用,用于对生命科学数据进行建模。
若要计算,请选择 “逻辑”,并设置以下选项:
缩放
键入用于缩放分布的值。通过将缩放值应用于分布,可以收缩或拉伸分布。
默认值为 1.0。 值必须是正数。
中间线
键入一个数字 (double) 来指示分布的估算平均值。 默认值为 0.0。
对数正态
对数正态分布是连续的单变量分布。
若要计算,请选择 Lognormal,并设置以下选项:
中间线
键入一个数字 (double) ,该值指示分布的估计平均值。 默认值为 0.0。标准偏差
键入一个正数 (double) 来指示分布的估算标准偏差。 默认值为 1.0。
负二项
负二项分布是自然数的分布,具有两个参数(r、p)。 在一个整数的特殊情况下 r ,当头的概率为 p 时,可以将分布解释为 rth head 之前的尾数。
若要计算,请选择 NegativeBinomial 并设置以下选项:
成功的概率
键入一个介于 0.0 和 1.0 之间的数字 (float),用于指示成功的概率。 默认值为 .5。成功的次数
键入一个整数来指定成功的次数值。 默认值为 24。
普通
正态分布也称为高斯分布。
若要计算,请选择 “普通”,并设置以下选项:
中间线
键入一个数字 (double) ,该值指示分布的估计平均值。 默认值为 0.0。标准偏差
键入一个正数 (double) 来指示分布的估算标准偏差。 默认值为 1.0。
帕雷托
帕雷托分布是幂定律的概率分布,与社会、科学、地球物理、保险精算以及许多其他类型的可观察现象相符合。
若要计算,请选择 Pareto,并设置以下选项:
形状
键入一个用于更改分布形状的值(可选)。形状参数是概率分布的任意参数,不用于定义分布的位置或比例。 因此,当你输入一个形状值时,该参数将更改分布的形状,但不会移动、拉伸或收缩分布。
该值必须是一个数字 (
double)。 默认值为 1.0。缩放
键入值 (可选) 以更改分布的规模。 通过将缩放值应用于分布,可以收缩或拉伸分布。该值必须是一个数字 (
double)。 默认值为 1.0。
泊松
在此实现中,使用 Knuth 的方法来生成泊松分布随机变量。 有关 Poisson 分布的详细信息,请参阅 Poisson 回归。
若要计算,请选择 Poisson,并设置以下选项:
- 中间线
键入一个数字 (double) ,该值指示分布的估计平均值。 默认值为 0.0。
瑞利
瑞利分布是连续的概率分布。 如果二维风速向量的组成部分是不相关的并且以相等的方差呈现正态分布,则风速将具有瑞利分布,此示例介绍了瑞利分布的应用。
若要计算,请选择 Rayleigh,并设置以下选项:
- 下限
键入一个数字 (double) 来表示分布的下限。 默认值为 0.0。
标准正态
此选项提供标准正态分布,没有其他参数。
若要计算,请选择 StandardNormal,然后选择列。
TStudent
此选项实现单变量学生的 t 分布。
若要计算,请选择 TStudent 并设置以下选项:
- 自由度数
键入一个数字 (double) 来指定自由度。 默认值为 1.0。
TStudentRightTailed
通过使用一个右尾实现单变量学生 t-分布。
若要计算,请选择 TStudentRightTailed,并设置以下选项:
- 自由度数
键入一个数字 (double) 来指定自由度。 默认值为 1.0。
TStudentTwoTailed
实现双尾学生 t-分布。
若要计算,请选择 TStudentTwoTailed,并设置以下选项:
- 自由度数
键入一个数字 (double) 来指定自由度。 默认值为 1.0。
Uniform
均匀分布也称为是矩形分布。
若要计算,请选择 “统一”,并设置以下选项:
下限
键入一个数字 (double) 来表示分布的下限。 默认值为 0.0。上限
键入一个数字 (double) 来表示分布的上限。 默认值为 1.0。
韦伯
韦伯分布在可靠性工程中广泛使用。 可以使用 其 Shape 参数对许多其他分布进行建模。
若要计算,请选择 Weibull,并设置以下选项:
形状
键入一个用于更改分布形状的值(可选)。形状参数是概率分布的任意参数,不用于定义分布的位置或比例。 因此,当你输入一个形状值时,该参数将更改分布的形状,但不会移动、拉伸或收缩分布。
该值必须是一个数字 (
double)。 默认值为 1.0。缩放
键入值 (可选) 以更改分布的规模。 通过将缩放值应用于分布,可以收缩或拉伸分布。该值必须是一个数字 (
double)。 默认值为 1.0。
技术说明
本部分包含实现详情、使用技巧和常见问题解答。
实现详细信息
此模块支持在开放源代码 MATH.NET 数字库中提供的所有分布。 有关详细信息,请参阅 Math.Net.Numerics.Distribution 库的文档。
右尾和双尾分布显示为单独的分布,而不是基本分发的参数化版本。 当前行为是为了保持与 Excel 兼容。
定义
此模块支持计算指定分布的任何这些值:
cdf 或 累积分布函数
返回复合事件的概率,当随机变量采用小于某些特定值 x 的值时,定义为 ocurrence 的总和。
换句话说,它回答了以下问题:“小于或等于此值的示例有多常见?
此函数可与连续和离散数值变量一起使用。
InverseCdf 或 反向累积分布函数
返回与特定累积概率值关联的值 (cdf) 。
换句话说,它回答了以下问题:“cdf 函数返回累积概率 y 的 x 值是多少?
pdf 或 概率密度函数
描述随机变量成为特定值的相对可能性。
换句话说,它回答了以下问题:“样本在该值上有多常见?
预期输入
| 名称 | 类型 | 说明 |
|---|---|---|
| 数据集 | 数据表 | 输入数据集 |
模块参数
| 名称 | 范围 | 类型 | 默认 | 说明 |
|---|---|---|---|---|
| 分发 | Any | 概率分布 | 标准正态 | 选择要生成的概率分布类型。 |
| 方法 | Any | 概率分布方法 | Cdf | 选择在计算所选概率分布时使用的方法。 选项为累积分布函数 (cdf)、反转累积分布函数 (InverseCdf) 和概率密度函数或质量函数 (pdf)。 |
| 负二项分布方法 | Any | 负二项概率分布方法 | Cdf | 如果你选择负二项分布,请指定用于计算该分布的方法。 |
| 成功的概率 | [0.0;1.0] | Float | 0.5 | 键入要用作成功概率的值。 |
| 形状 | Any | Float | 1.0 | 键入一个用于修改分布形状的值。 |
| 缩放 | >=0.0 | Float | 1.0 | 键入一个用于更改分布比例的值,以放大或缩小分布。 |
| 试验的次数 | >=1 | Integer | 3 | 指定试验的次数。 |
| 下限 | Any | Float | 0.0 | 键入一个数字来用作分布的下限 |
| 上限 | Any | Float | 1.0 | 键入一个数字来用作分布的上限 |
| 位置 | Any | Float | 0.0 | 键入分布中零元素的位置。 |
| 自由度数 | Any | Float | 1.0 | 指定自由度数。 |
| 自由度的分子 | Any | Float | 3.0 | 指定分子中的自由度数。 |
| 自由度的分母 | Any | Float | 6.0 | 指定分母中的自由度数。 |
| Lambda | >=0.0 | Float | 1.0 | 指定 Lambda 参数的值。 |
| 样本数 | 任意 | Integer | 9 | 指定样本数。 |
| 成功的次数 | 任意 | Integer | 24 | 键入要用作成功次数的值。 |
| 群体大小 | 任意 | Integer | 52 | 指定群体大小。 |
| 平均值 | Any | Float | 0.0 | 键入估算的平均值。 |
| 标准偏差 | >=0.0 | Float | 1.0 | 键入估算的标准偏差。 |
| 列集 | Any | ColumnSelection | 选择要计算概率分布的列。 | |
| 结果模式 | Any | OutputTo | ResultOnly | 指定如何在输出数据集中保存结果。 选择包括:追加新列、替换现有列,或仅输出结果。 |
输出
| 名称 | 类型 | 说明 |
|---|---|---|
| 结果数据集 | 数据表 | 输出数据集 |
异常
有关错误消息的完整列表,请参阅 模块错误代码。
| 例外 | 描述 |
|---|---|
| 错误 0017 | 如果一个或多个指定列具有当前模块不支持的类型,则会发生异常。 |
有关特定于 Studio (经典) 模块的错误列表,请参阅机器学习错误代码。
有关 API 异常的列表,请参阅 机器学习 REST API 错误代码。