在 本教程的上一阶段,我们获取了用于使用 PyTorch 训练数据分析模型的数据集。 现在,是时候利用这些数据了。
若要使用 PyTorch 训练数据分析模型,需要完成以下步骤:
- 加载数据。 如果你已经完成了本教程的上一步,那么你已经处理过这个了。
- 定义神经网络。
- 定义损失函数。
- 使用训练数据训练模型。
- 使用测试数据测试网络。
定义神经网络
在本教程中,你将构建一个包含三个线性层的基本神经网络模型。 模型的结构如下所示:
Linear -> ReLU -> Linear -> ReLU -> Linear
线性层将线性转换应用于传入数据。 您必须指定输入特征的数量,以及与类数对应的输出特征数量。
ReLU 层是一种激活函数,用于将所有输入特征设定为 0 或更高值。 因此,应用 ReLU 层时,小于 0 的任何数字都更改为零,而其他数字则保持不变。 我们将在两个隐藏层上应用激活层,在最后一个线性层上不应用激活。
模型参数
模型参数取决于我们的目标和训练数据。 输入大小取决于我们馈送模型的特征数 - 在本例中为 4 个。 输出大小为 3,因为有三种可能的鸢尾花类型。
拥有三个线性层的(4,24) -> (24,24) -> (24,3)网络将有744个权重(96+576+72)。
学习速率 (lr) 设置你根据损失梯度调整网络权重的程度控制。 速率越低,训练速度就越慢。 本教程将 lr 设置为 0.01。
网络的工作原理是什么?
在这里,我们正在构建一个前馈网络。 在训练过程中,网络将处理所有层的输入,计算损失以了解图像的预测标签与正确标签相差多远,并将梯度传播回网络以更新层的权重。 通过迭代庞大的输入数据集,网络将“学习”设置其权重以获得最佳结果。
向前函数计算损失函数的值,向后函数计算可学习参数的渐变。 使用 PyTorch 创建神经网络时,只需定义前向函数。 后向函数会自动定义。
- 将以下代码复制到
DataClassifier.pyVisual Studio 中的文件中,以定义模型参数和神经网络。
# Define model parameters
input_size = list(input.shape)[1] # = 4. The input depends on how many features we initially feed the model. In our case, there are 4 features for every predict value
learning_rate = 0.01
output_size = len(labels) # The output is prediction results for three types of Irises.
# Define neural network
class Network(nn.Module):
def __init__(self, input_size, output_size):
super(Network, self).__init__()
self.layer1 = nn.Linear(input_size, 24)
self.layer2 = nn.Linear(24, 24)
self.layer3 = nn.Linear(24, output_size)
def forward(self, x):
x1 = F.relu(self.layer1(x))
x2 = F.relu(self.layer2(x1))
x3 = self.layer3(x2)
return x3
# Instantiate the model
model = Network(input_size, output_size)
还需要根据电脑上的可用设备定义执行设备。 PyTorch 没有用于 GPU 的专用库,但可以手动定义执行设备。 如果计算机上存在 Nvidia GPU,则该设备为 Nvidia GPU;如果没有,则为 CPU。
- 复制以下代码以定义执行设备:
# Define your execution device
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("The model will be running on", device, "device\n")
model.to(device) # Convert model parameters and buffers to CPU or Cuda
- 最后一步,定义用于保存模型的函数:
# Function to save the model
def saveModel():
path = "./NetModel.pth"
torch.save(model.state_dict(), path)
注释
想要详细了解如何使用 PyTorch 创建神经网络? 查看 PyTorch 文档。
定义损失函数
损失函数计算一个值,该值可估计输出与目标之间的差距。 主要目标是通过神经网络中的反向传播改变权重向量值来减少损失函数的值。
丢失值不同于模型准确性。 损失函数表示模型在训练集的每次优化迭代后的表现。 模型的准确性根据测试数据计算,并显示正确预测的百分比。
在 PyTorch 中,神经网络包包含各种损失函数,这些函数构成了深层神经网络的构建基块。 如果想了解更多具体细节,请从上面的说明开始。 在这里,我们将使用针对此类分类进行优化的现有函数,并使用 Classification Cross-Entropy loss 函数和 Adam 优化器。 在优化器中,学习率(lr)控制的是网络权重相对于损失梯度的调整幅度。 你将在此处设定值为 0.001 —— 数值越低,训练速度越慢。
- 将以下代码复制到 Visual Studio 中的
DataClassifier.py文件中,以定义损失函数和优化器。
# Define the loss function with Classification Cross-Entropy loss and an optimizer with Adam optimizer
loss_fn = nn.CrossEntropyLoss()
optimizer = Adam(model.parameters(), lr=0.001, weight_decay=0.0001)
使用训练数据训练模型。
要训练模型,必须循环访问数据迭代器,将输入馈送到网络并进行优化。 若要验证结果,只需在每次训练纪元后,将预测标签与验证数据集中的实际标签进行比较。
该程序将显示训练损失、验证损失和模型对于每个纪元或训练集的每个完整迭代的准确性。 它将保存精度最高的模型,在 10 个时期之后,程序将显示最终的准确性。
- 将以下代码添加到
DataClassifier.py文件
# Training Function
def train(num_epochs):
best_accuracy = 0.0
print("Begin training...")
for epoch in range(1, num_epochs+1):
running_train_loss = 0.0
running_accuracy = 0.0
running_vall_loss = 0.0
total = 0
# Training Loop
for data in train_loader:
#for data in enumerate(train_loader, 0):
inputs, outputs = data # get the input and real species as outputs; data is a list of [inputs, outputs]
optimizer.zero_grad() # zero the parameter gradients
predicted_outputs = model(inputs) # predict output from the model
train_loss = loss_fn(predicted_outputs, outputs) # calculate loss for the predicted output
train_loss.backward() # backpropagate the loss
optimizer.step() # adjust parameters based on the calculated gradients
running_train_loss +=train_loss.item() # track the loss value
# Calculate training loss value
train_loss_value = running_train_loss/len(train_loader)
# Validation Loop
with torch.no_grad():
model.eval()
for data in validate_loader:
inputs, outputs = data
predicted_outputs = model(inputs)
val_loss = loss_fn(predicted_outputs, outputs)
# The label with the highest value will be our prediction
_, predicted = torch.max(predicted_outputs, 1)
running_vall_loss += val_loss.item()
total += outputs.size(0)
running_accuracy += (predicted == outputs).sum().item()
# Calculate validation loss value
val_loss_value = running_vall_loss/len(validate_loader)
# Calculate accuracy as the number of correct predictions in the validation batch divided by the total number of predictions done.
accuracy = (100 * running_accuracy / total)
# Save the model if the accuracy is the best
if accuracy > best_accuracy:
saveModel()
best_accuracy = accuracy
# Print the statistics of the epoch
print('Completed training batch', epoch, 'Training Loss is: %.4f' %train_loss_value, 'Validation Loss is: %.4f' %val_loss_value, 'Accuracy is %d %%' % (accuracy))
使用测试数据测试模型。
训练模型后,可以使用测试数据集测试模型。
我们将添加两个测试函数。 第一个函数测试你在上一部分保存的模型。 它将使用 45 个项目的测试数据集测试模型,并输出模型的准确性。 第二个是一个可选函数,用于测试模型预测三种虹膜物种中的每一种的信心,由每个物种成功分类的概率表示。
- 将以下代码添加到
DataClassifier.py文件。
# Function to test the model
def test():
# Load the model that we saved at the end of the training loop
model = Network(input_size, output_size)
path = "NetModel.pth"
model.load_state_dict(torch.load(path))
running_accuracy = 0
total = 0
with torch.no_grad():
for data in test_loader:
inputs, outputs = data
outputs = outputs.to(torch.float32)
predicted_outputs = model(inputs)
_, predicted = torch.max(predicted_outputs, 1)
total += outputs.size(0)
running_accuracy += (predicted == outputs).sum().item()
print('Accuracy of the model based on the test set of', test_split ,'inputs is: %d %%' % (100 * running_accuracy / total))
# Optional: Function to test which species were easier to predict
def test_species():
# Load the model that we saved at the end of the training loop
model = Network(input_size, output_size)
path = "NetModel.pth"
model.load_state_dict(torch.load(path))
labels_length = len(labels) # how many labels of Irises we have. = 3 in our database.
labels_correct = list(0. for i in range(labels_length)) # list to calculate correct labels [how many correct setosa, how many correct versicolor, how many correct virginica]
labels_total = list(0. for i in range(labels_length)) # list to keep the total # of labels per type [total setosa, total versicolor, total virginica]
with torch.no_grad():
for data in test_loader:
inputs, outputs = data
predicted_outputs = model(inputs)
_, predicted = torch.max(predicted_outputs, 1)
label_correct_running = (predicted == outputs).squeeze()
label = outputs[0]
if label_correct_running.item():
labels_correct[label] += 1
labels_total[label] += 1
label_list = list(labels.keys())
for i in range(output_size):
print('Accuracy to predict %5s : %2d %%' % (label_list[i], 100 * labels_correct[i] / labels_total[i]))
最后,让我们添加主代码。 这将启动模型训练、保存模型并在屏幕上显示结果。 我们将在训练集上仅运行两次迭代 [num_epochs = 25],因此训练过程不会花费太长时间。
- 将以下代码添加到
DataClassifier.py文件。
if __name__ == "__main__":
num_epochs = 10
train(num_epochs)
print('Finished Training\n')
test()
test_species()
让我们运行测试! 确保顶部工具栏中的下拉菜单设置为 Debug。 如果您的设备是 64 位,请更改 Solution Platform 为 x64 以在本地计算机上运行项目;如果是 32 位,则更改为 x86 以运行项目。
- 若要运行项目,请单击
Start Debugging工具栏上的按钮,或按F5。
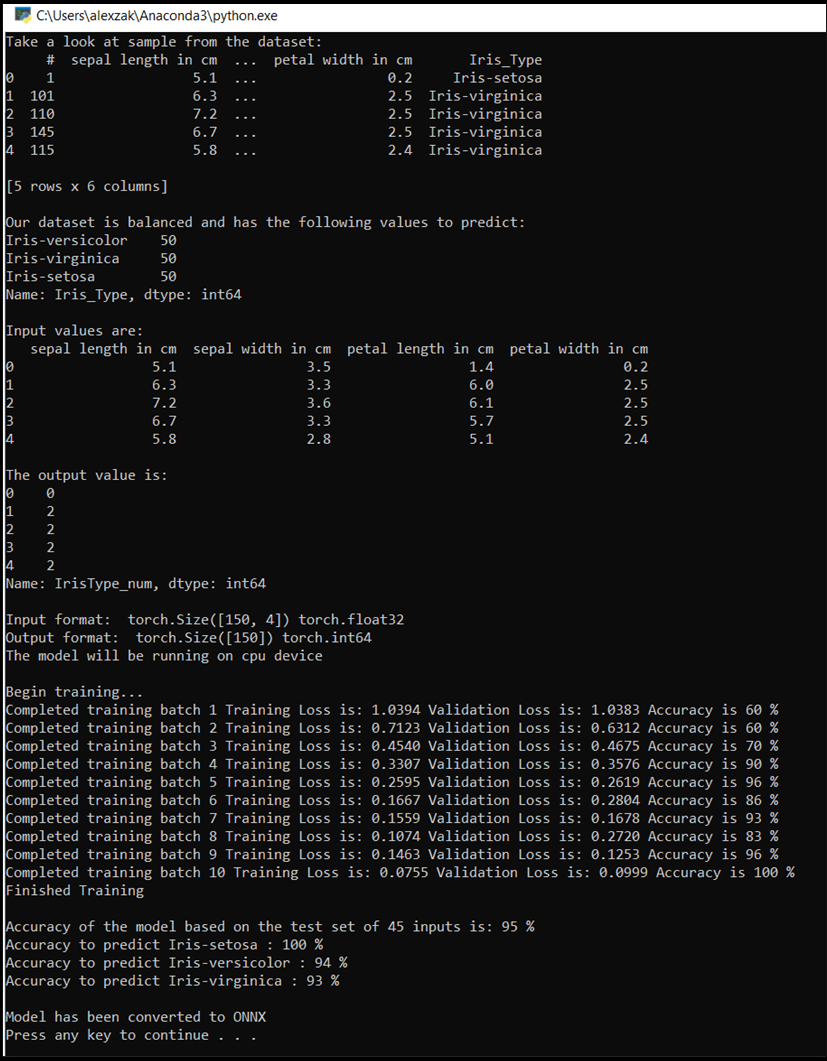
控制台窗口将弹出,你将看到训练过程。 如定义的一样,将对每个 epoch 打印丢失值。 预期是损失值随每个循环而减少。
训练完成后,应会看到类似于下面的输出。 你的数字不会完全相同,因为训练取决于许多因素,因此不会总是返回完全相同的结果,但它们看起来应该相似。
后续步骤
现在我们已经有了一个分类模型,下一步是 将模型转换为 ONNX 格式。