这说明如何使用作为 Windows 性能工具包一部分提供的 XPerf 和 GPUView 工具测量 DirectX 应用的一些最重要的性能时间度量。 这不是用于了解工具的完整指南,而是用于分析 DirectX 应用性能的特定适用性。 虽然此处讨论的大多数技术都与所有 DirectX 应用相关,但更适用于使用交换链的 DirectX 应用,而不适用于基于 XAML 使用 SIS/VSIS 和 XAML 动画构建的 DirectX 应用程序。 我们将引导你完成关键性能时间度量、如何获取和安装这些工具,并获取性能度量跟踪,然后对其进行分析,以了解应用瓶颈。
关于工具
XPerf
XPerf 是一组基于 Windows 事件跟踪(ETW)构建的性能分析工具,旨在测量和分析详细的系统和应用性能和资源使用情况。 从 Windows 8 开始,此命令行工具具有图形用户界面,称为 Windows 性能记录器(WPR)和 Windows 性能分析器(WPA)。 有关这些工具的详细信息,请参阅 Windows 性能工具包 (WPT): Windows 性能工具包的网页。
ETW 收集请求的内核事件,并将其保存到名为事件跟踪日志 (ETL) 文件的文件中。 这些内核事件提供有关运行应用时的应用和系统特征的广泛信息。 通过启用跟踪捕获,执行需要分析的应用方案,停止捕获以将数据保存到 ETL 文件中,从而收集数据。 然后,可以使用命令行工具 xperf.exe 或视觉跟踪分析工具 xperfview.exe分析相同或不同计算机上的文件。
GPUView
GPUView 是用于确定图形处理单元(GPU)和 CPU 性能的开发工具。 它查看有关直接内存访问(DMA)缓冲区处理和视频硬件上所有其他视频处理的性能。
对于严重依赖 GPU 的 DirectX 应用, GPUView 是一种功能强大的工具,用于了解在 CPU 与 GPU 上完成的工作之间的关系。 有关 GPUView的详细信息,请参阅 使用 GPUView。
与 XPerf 类似,首先启动跟踪服务来执行 ETW 跟踪,并执行需要对应用进行分析的方案,停止服务并将信息保存在 ETL 文件中。 GPUView 以图形格式呈现 ETL 文件中的数据。
安装 GPUView 工具后,建议在“GPUView 帮助”菜单下阅读“GPUView 的主显示”主题。 它包含有关如何解释 GPUView UI 的有用信息。
安装工具
XPerf 和 GPUView 均包含在 Windows 性能工具包 (WPT) 中。
XPerf 作为适用于 Windows 的 Windows 软件开发工具包(SDK)的一部分提供。 下载 Windows SDK。
GPUView 在 Windows 评估和部署工具包(Windows ADK)中可用。 下载 Windows ADK。
安装后,必须将包含 XPerf 和 GPUView 的目录添加到系统“Path”变量。
单击“开始”按钮,然后键入“系统变量”。 此时会打开“系统属性”窗口。 单击“编辑系统环境变量”。 从“系统属性”对话框中选择“环境变量”。 在“系统变量”下找到“Path”变量。 将包含 xperf.exe和 GPUView.exe的 目录追加到路径。 这些可执行文件位于“Windows 工具包”内的“Windows Performance Toolkit”目录中。 默认位置为: C:\Program Files (x86)\Windows Kits\10\Windows Performance Toolkit。
性能时间测量
大多数应用预期运行平稳且响应用户输入。 但是,根据所需的方案,性能的一个方面可能比另一个方面更重要。 例如,对于在触摸平板电脑电脑上运行的新闻阅读器应用,最重要的方面是一次查看一篇文章,并平移/缩放/滚动浏览同一篇文章或其他文章。 在这种情况下,不需要每个画面帧都具备呈现所有内容的能力。 但是,在触摸手势上顺利滚动浏览文章的能力非常重要。
在另一种情况下,如果帧丢失,使用大量动画的游戏或视频渲染应用会出现故障。 在这种情况下,能够在不中断用户输入的情况下在屏幕上呈现内容,这一点非常重要。
为了了解应用的哪个部分存在问题,第一步是确定最重要的方案。 了解应用的核心方面及其将如何练习后,使用这些工具查找问题会变得更加容易。
下面是一些最常见的性能时间指标:
启动时间
从进程启动到首次画面显示在屏幕上所测量的时间。 当系统暖化时,此度量更有用,这意味着在应用启动几次后进行测量。
每个帧的 CPU 时间
CPU 主动处理一帧的应用工作负荷的时间。 如果应用运行顺利,则一个帧所需的所有处理都在一个 v 同步间隔内发生。 监视器刷新速率为 60Hz 时,每个帧的刷新速率为 16 毫秒。 如果 CPU 时间/帧大于 16 毫秒,则可能需要进行 CPU 优化以确保应用流畅运行。
每个帧的 GPU 时间
GPU 主动处理一帧的应用工作负荷的时间。 当处理一帧数据所花费的时间超过 16 毫秒时,应用将绑定 GPU。
能够了解应用是 CPU 还是 GPU 绑定会缩小代码有问题的部分。
采用性能时间度量跟踪
执行以下步骤以进行追踪:
- 以管理员身份打开命令窗口。
- 如果应用已在运行,请关闭该应用。
- 将目录更改为 Windows Performance Toolkit 文件夹中的 gpuview 目录。
- 键入“log.cmd”以启动事件跟踪。 此选项记录最有趣的事件。 其他可用选项记录事件的不同范围。 例如,“v”或详细日志模式捕获 GPUView 感知的所有事件。
- 启动示例,并以涵盖需要分析的性能路径的方式练习示例。
- 返回到命令窗口并再次键入“log.cmd”以停止日志记录。
- 这会在 gpuview 文件夹中输出名为“merged.etl”的文件。 可以将此文件保存到另一个位置,并且可以在同一台或不同的计算机上对其进行分析。 若要查看堆栈捕获详细信息,请保存与应用关联的符号文件(.pdb)。
测量结果
注释
几何实现样本的测量是在具有集成 DirectX11 图形卡的四核计算机上进行的。 度量值因计算机配置而异。
本部分演示如何测量启动时间以及每帧的 CPU 和 GPU 时间。 您可以在您的计算机上对相同的样本进行性能分析并查看各种测量结果的差异。
若要在 GPUView 中分析跟踪,请使用 GPUView.exe打开“merged.elt”文件。
启动时间
启动时间由应用开始所用的总时间度量,直到内容首次出现在屏幕上。
最好根据上一部分中列出的步骤并进行适当的调整来测量启动时间:
- 如果在首次启动应用时进行启动度量,则称为冷启动。 这可能会因您在短时间内多次启动应用后得到的测量结果而有所不同。 这称为热启动。 根据应用在启动时创建的资源数量,这两个启动时间之间可能存在很大的差异。 根据应用目标,衡量一个或另一个目标可能是可取的。
- 记录性能信息时,一旦第一帧在屏幕上显示,就会终止应用。
使用 GPUView 计算启动时间
在 GPUView 中,向下滚动到相关过程,在本例中 GeometryRealization.exe。
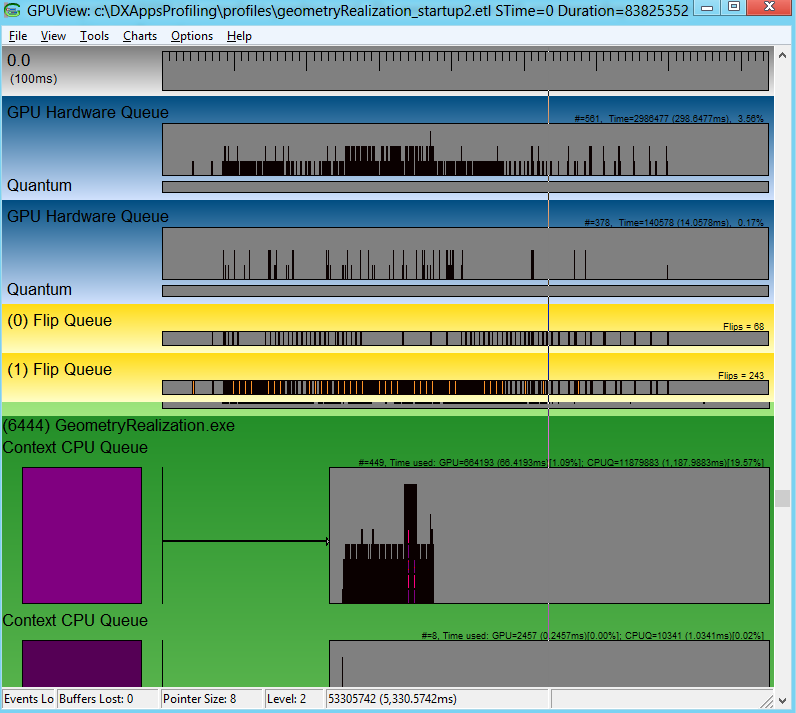
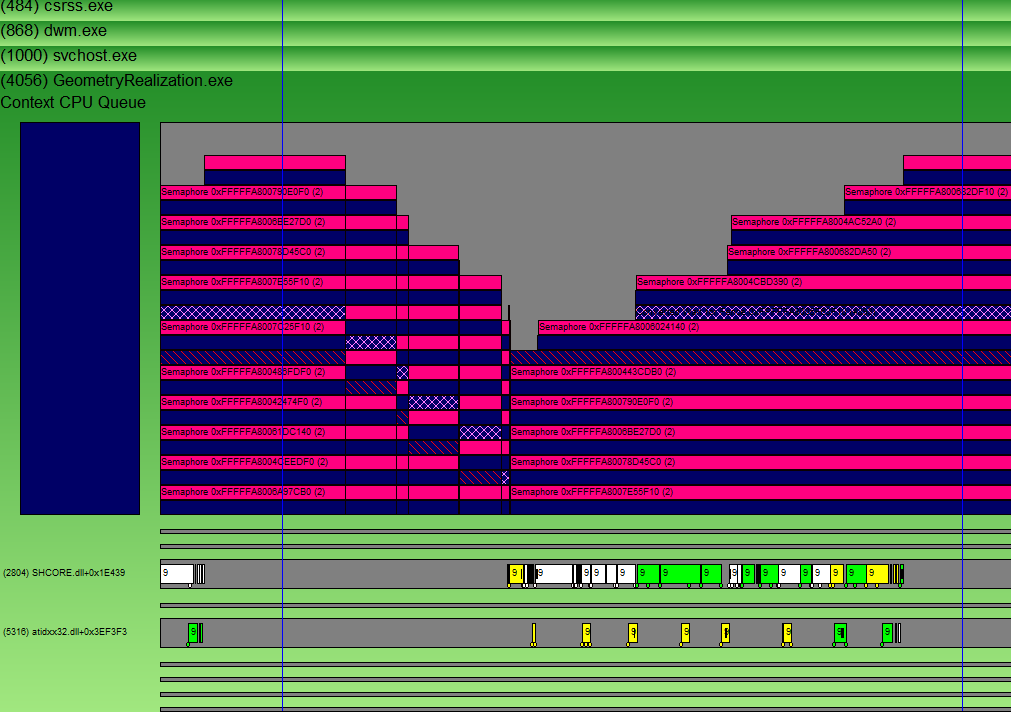
上下文的 CPU 队列表示排队等待硬件处理的图形工作负载,但不一定由硬件处理。 打开跟踪文件时,它会显示在跟踪拍摄时间之间记录的所有事件。 若要计算启动时间,请选择感兴趣的区域,使用 Ctrl +Z 放大第一个上下文 CPU 队列(这是显示活动)的初始部分。 有关 GPUView 控件的详细信息,请参阅 GPUView 帮助文件“ GPUView 控件摘要”。 下图仅显示放大到上下文 CPU 队列的第一部分的 GeometryRealization.exe 进程。 上下文 CPU 队列的颜色由队列正下方的矩形表示,队列中颜色相同的数据包显示在硬件上排队等待的 GPU 工作。 上下文队列中的图案包显示当前的数据包,这意味着应用程序希望硬件在屏幕上呈现内容。

启动时长是指应用程序首次启动(在本例中为 UI 线程入口点模块 SHCORE.dll)到上下文首次出现之间的时间(由标记包标记)。 此处的图突出显示了感兴趣的领域。
注释
实际的当前信息在翻转队列中表示,因此,直到当前数据包在翻转队列中实际完成之前,所需时间都会延长。
下图中完整的状态栏不可见,同时也显示了两段突出显示部分之间经过的时间。 这是应用的启动时间。 在这种情况下,对于上面提到的机器,结果大约是 240 毫秒。
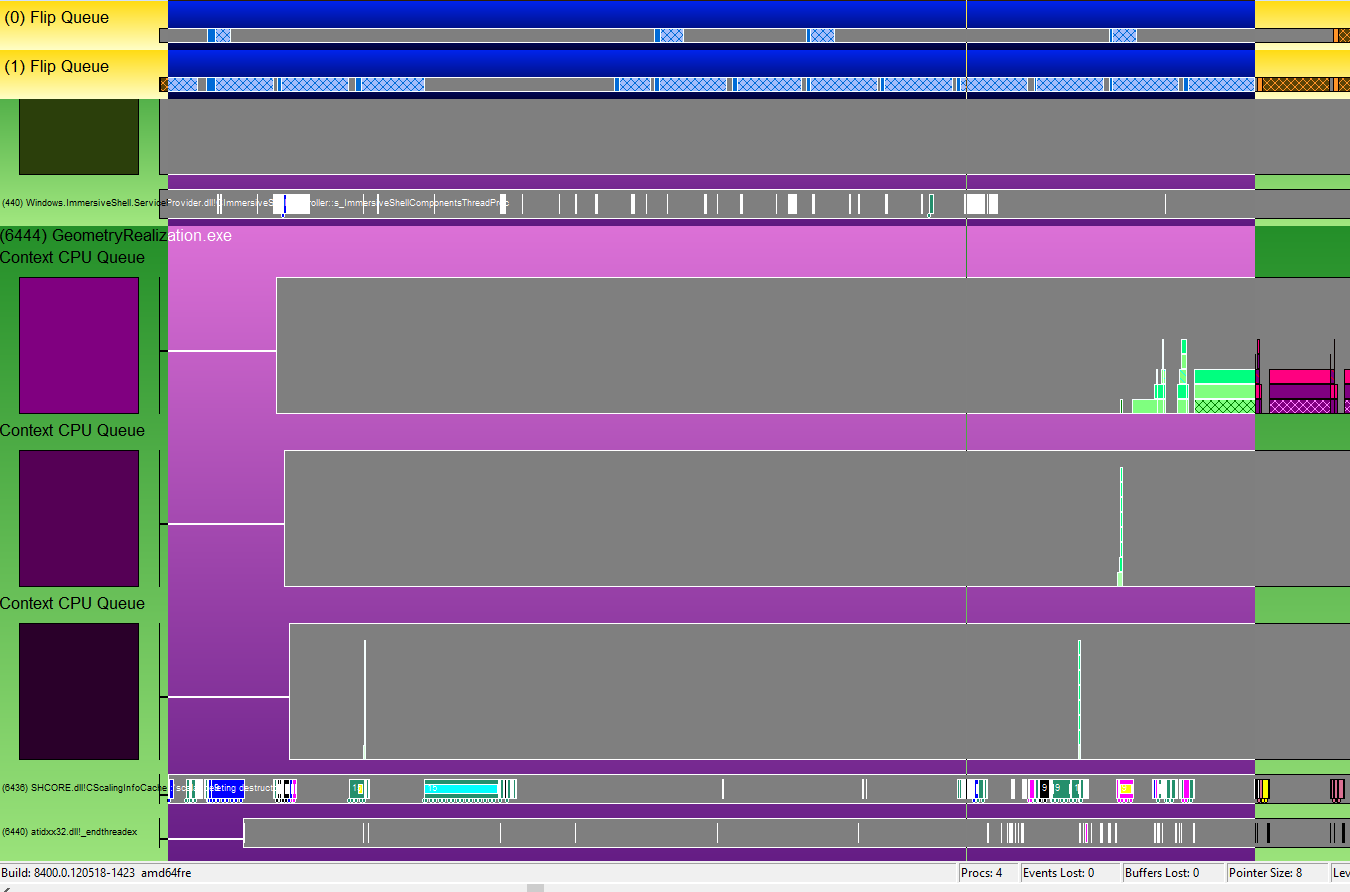
每个帧的 CPU 和 GPU 时间
测量 CPU 时间时需要考虑一些事项。 在跟踪中查找已练习要分析的方案的区域。 例如,在几何体实现样本中,分析的方案之一是从呈现 2048 个基元转换到 8192 个基元的过程,这些基元在每一帧都没有实现,也就是说,几何图形没有在每一帧进行细分。 跟踪清楚地显示出 CPU 和 GPU 活动在基元数量转换前后的差异。
正在分析两种方案,以计算每个帧的 CPU 和 GPU 时间。 它们如下所示。
- 从呈现 2048 个未实现的基元转换为 8192 个未实现的基元。
- 从呈现 8192 实现的基元转换到 8192 未实现的基元。
在这两种情况下,都观察到帧速率大幅下降。 测量 CPU 和 GPU 时间、两者之间的关系以及跟踪中的一些其他模式可以提供有关应用中有问题的区域的有用信息。
计算 2048 基元呈现未实现时的 CPU 和 GPU 时间
使用 GPUView.exe打开跟踪文件。
向下滚动到 GeometryRealization.exe 流程。
选择用于计算 CPU 时间的区域,并使用 CTRL + Z 放大它。
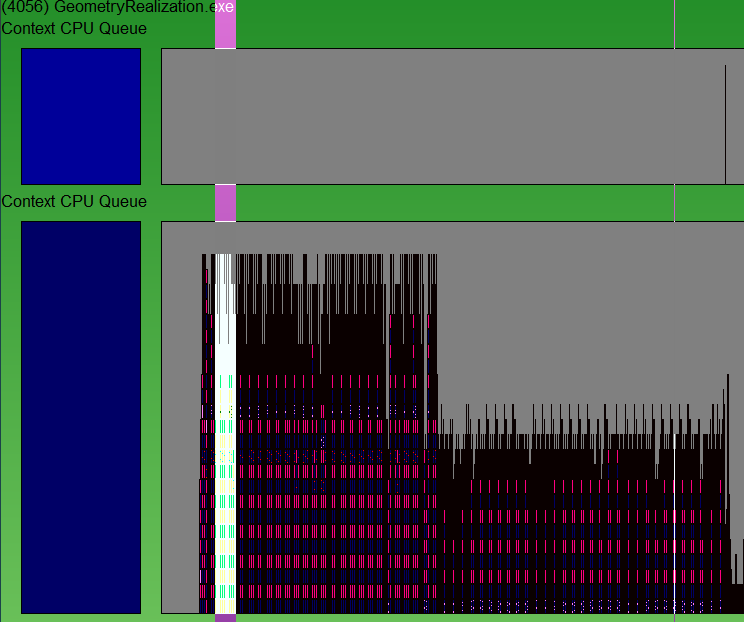
通过在 F8 之间切换来显示 v 同步信息。 继续放大,直到能够清楚地看到一个垂直同步周期的数据。 蓝色线条是 v 同步时间的位置。 通常,每 16 毫秒(60 fps)发生一次,但如果 DWM 遇到性能问题,则运行速度较慢,因此每 32 毫秒(30 fps)就会发生一次。 若要了解时间,请选择从一个蓝色栏到下一个蓝色栏,然后查看 GPUView 窗口右下角显示的毫秒数。
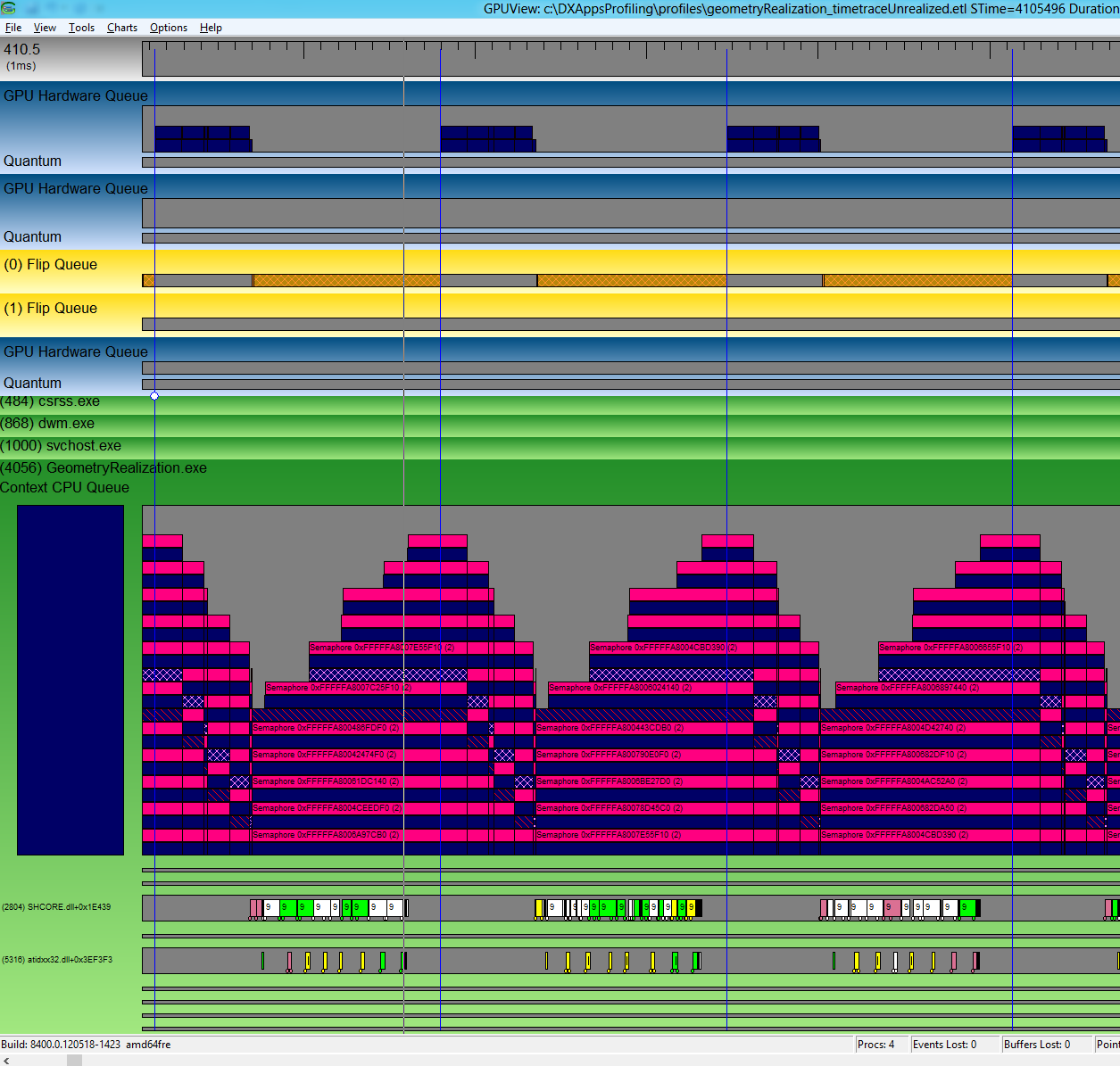
若要测量每个帧的 CPU 时间,请测量呈现所涉及的所有线程所花费的时间长度。 从性能的角度来看,缩小预期最相关的线程可能是值得的。 例如,在几何图形实现示例中,内容正在进行动画处理,并且需要在每一帧中呈现在屏幕上,使 UI 线程成为重要的线程。 确定要查看的线程后,测量此线程上的条形长度。 计算其中一些的平均值会得出每个帧的CPU的时间。 下图显示了在用户界面线程上花费的时间。 它还表明,此时的帧时间恰好位于两个连续垂直同步之间,这意味着它正在达到 60FPS。
还可以通过查看相应时间范围的翻转队列来验证,这可以表明 DWM 能够呈现每个帧。

GPU 时间可以采用与 CPU 时间相同的方式测量。 放大相关区域,就像测量 CPU 时间一样。 测量 GPU 硬件队列中条形的长度,其颜色与上下文 CPU 队列的颜色相同。 只要这些柱能够匹配连续的垂直同步周期,应用程序就在以60帧每秒的频率顺利运行。

计算 8192 基元未实现时的 CPU 和 GPU 时间
如果再次执行相同的步骤,跟踪会显示,一个帧的所有 CPU 工作都无法在一次垂直同步和下一次垂直同步之间完成。 这意味着应用已绑定 CPU。 UI 线程正在让 CPU 负载过高。
显示 UI 线程使 CPU 饱和示例的屏幕截图。
查看翻转队列时,也很明显,DWM 无法显示每个帧。

为了分析时间耗费的地方,请在 XPerf 中打开追踪记录。 若要分析 XPerf 中的启动时间,请先在 GPUView 中查找时间间隔。 将鼠标悬停在间隔左侧和右侧,并注意 GPUView 窗口底部显示的绝对时间。 然后在 XPerf 中打开同一个 .etl 文件,滚动到“CPU 按 CPU 采样”的图表处,右键单击并选择“选择间隔…”,这样就可以输入通过查看 GPU 跟踪发现的感兴趣的时间间隔。
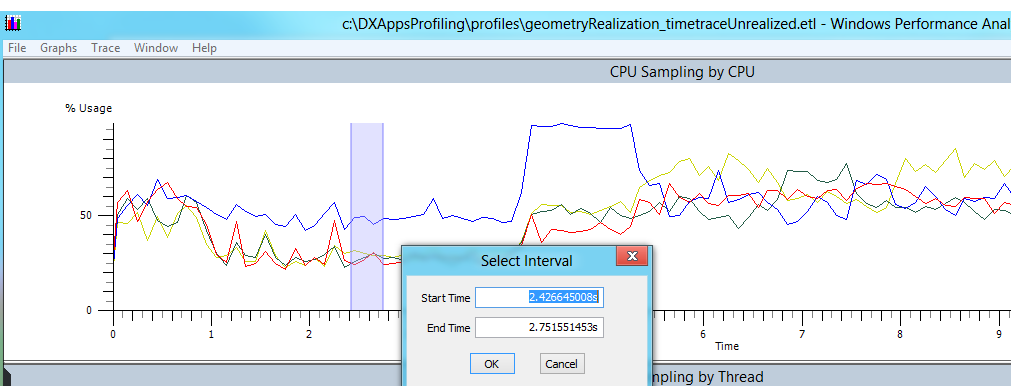
转到“跟踪菜单”,确保“加载符号”已选中。 此外,请转到“跟踪 -> 配置符号路径”,然后键入应用符号路径。 符号文件包含有关独立数据库中编译的可执行文件(.pdb)的调试信息。 此文件通常称为 PDB。 有关符号文件的详细信息,可在此处找到: 符号文件。 此文件可以位于应用目录的“调试”文件夹中。
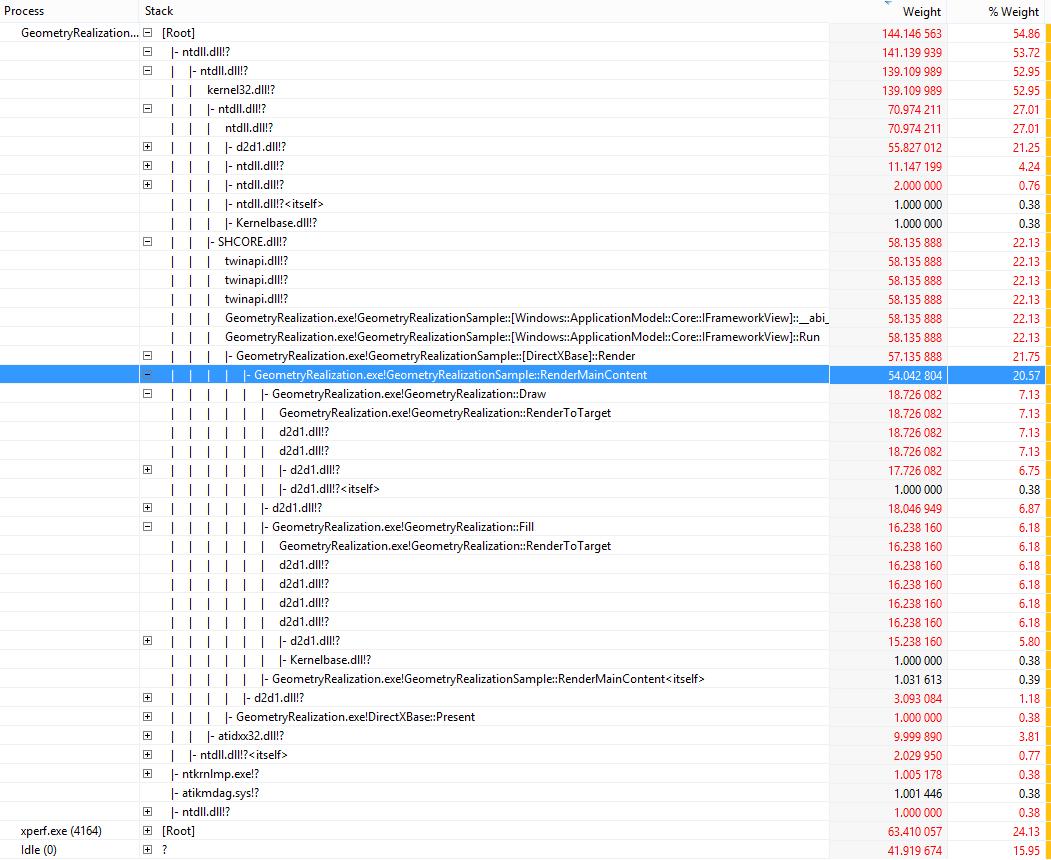
若要获取应用中花费时间的细分,请右键单击上一步中选择的时间间隔,然后单击“摘要表”。 若要大致了解每个 dll 中花费的时间,请从“列”菜单中取消选中“Stack”。 请注意,此处的“Count”列显示给定 dll/函数中的样本数。 由于每毫秒大约会取一个样本,因此该数字可用作估算每个 DLL/函数中所花费时间的最佳参考。 从“列”菜单中选择“堆栈”后,可以看到函数调用图中每个函数所用的总时间。 这将有助于进一步分解问题点。
2048个未实现的基元的堆栈跟踪信息显示,在几何实现过程中消耗了30%的CPU时间。 其中大约 36% 的时间用于几何分割和描边。
8192 未实现基元的堆栈跟踪信息显示,大约 60% CPU 时间(4 个核心)用于几何实现。
计算实现 8192 基元时的 CPU 时间
从配置文件中可以清楚地看出应用已绑定 CPU。 为了减少 CPU 花费的时间,可以创建几何图形一次并缓存。 缓存的内容可以在每一帧呈现,而不会产生每一帧的几何细分成本。 在 GPUView 中查看应用的已实现部分的跟踪时,很明显,DWM 能够呈现每个帧,CPU 时间已大幅减少。
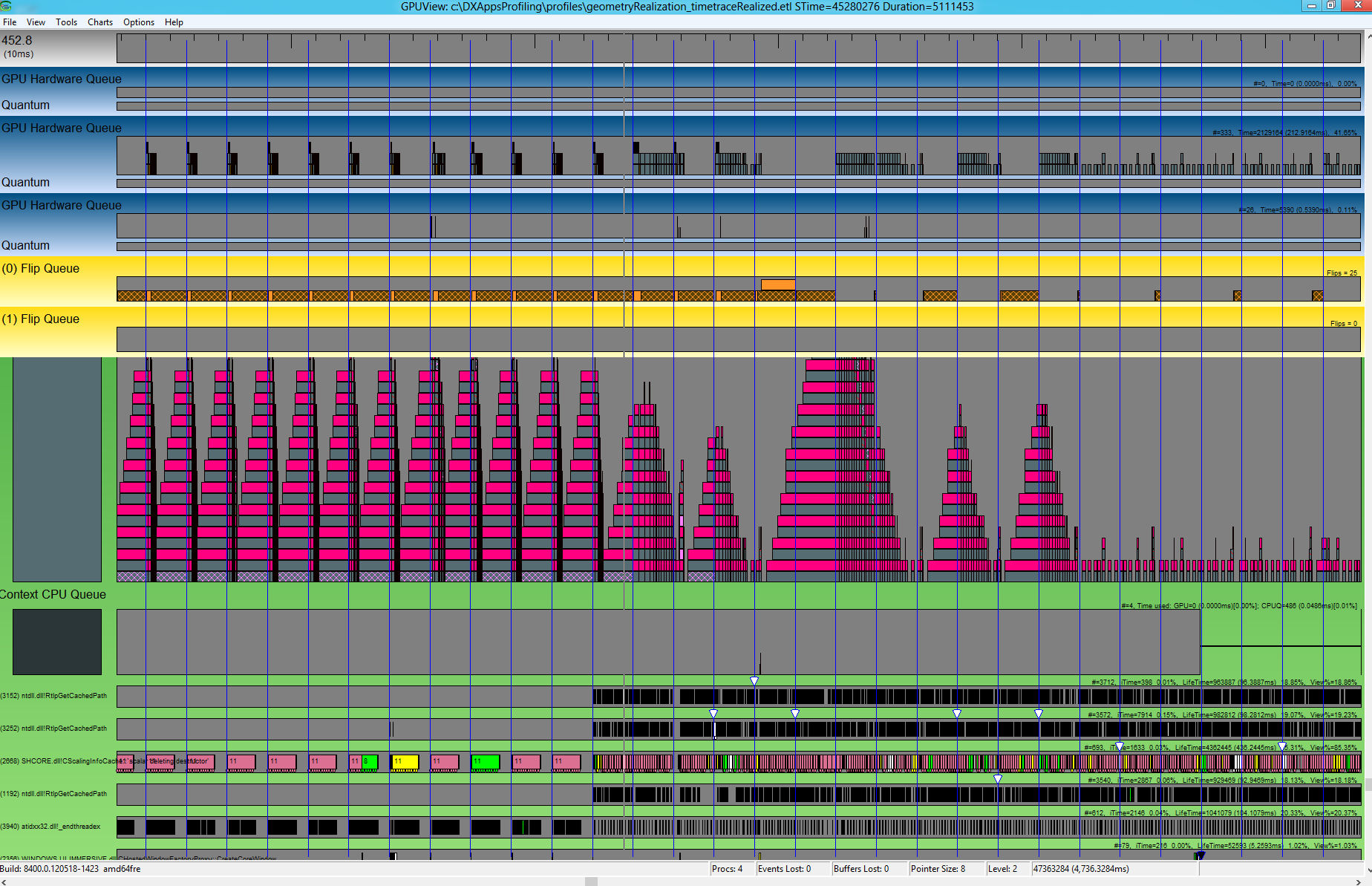
图的第一部分显示了实现的 8192 基元。 每个帧的相应 CPU 时间能够适应两个连续的 v 同步。 在图表的后半部分,这不正确。
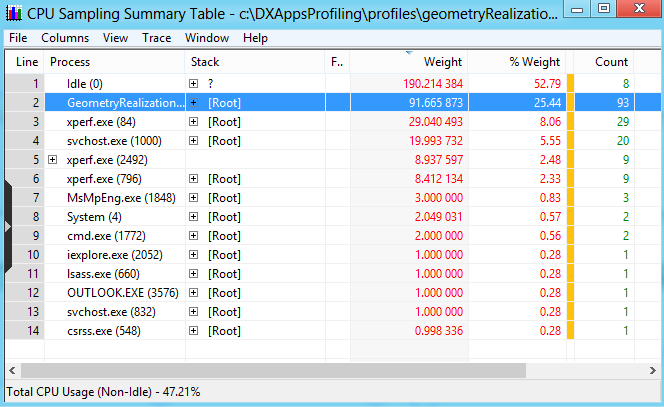
在 XPerf 中,CPU 长时间处于空闲状态,只在几何实现应用上花费大约 25% 的 CPU 时间。
概要
GPUView 和 XPerf 以及用于分析 DirectX 应用性能的强大工具。 本文是使用这些工具并了解基本性能度量和应用特征的入门文章。 除了了解工具的使用外,首先必须了解要分析的应用。 首先找到答案,例如该应用试图实现什么目标? 系统中哪些线程最重要的? 你愿意做出哪些权衡? 分析性能跟踪时,首先查看明显的有问题的位置。 应用 CPU 或 GPU 是否绑定? 应用是否能够显示每个帧? 工具与对应用的理解一起,可以提供非常有用的信息来理解、查找和最终解决性能问题。