本主题介绍索引过程的三个阶段以及每个阶段所涉及的主要组件,说明索引活动的时间安排,并为希望为其数据存储或文件格式编制索引的第三方开发人员提供一些说明。
本主题的组织方式如下:
概述
Windows 搜索支持对不同文件格式的文件(例如.doc或 .jpeg 格式)和数据存储(如文件系统或 Windows Outlook 邮箱)中的属性和内容编制索引。 有两种类型的索引:允许按属性的整个值进行筛选和排序的值索引,以及索引文本属性或内容中的单词的倒排索引。 如果你有自定义文件格式或数据存储,则需要了解 Windows 搜索如何编制索引,以便正确为项目编制索引。
索引过程分三个阶段进行,由名为 Gatherer 的 Windows 搜索组件控制。 在第一阶段,收集器将 URL 添加到队列。 URL 标识要编制索引的项,而队列只是 URL 的优先级列表。 在第二阶段,收集器协调其他 Windows 搜索和第三方组件以访问项并收集有关这些项目的数据。 最后,在第三阶段,收集的数据将添加到索引中。
下图显示了通过索引编制过程的主要组件和数据流。 收集索引数据涉及许多组件。 其中一些是 Windows 搜索的一部分,有些来自第三方应用程序。 如果你有自定义数据存储或文件格式,Windows Search 依赖于你的协议处理程序和筛选器来访问 URL 并发出索引属性。 Windows 搜索组件显示为蓝色,第三方组件显示为绿色。
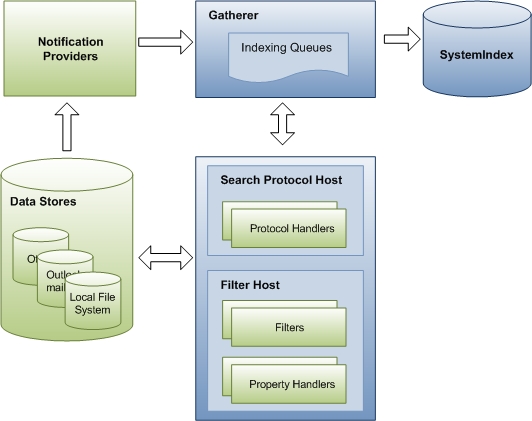
阶段 1:排队 URL 以用于编制索引
在索引编制的第一阶段,收集器收集有关数据存储更新的信息,将该信息与已知的爬网范围进行比较,然后生成要遍历的 URL 队列,以收集索引的数据。 对于不基于通知的源(如 FAT 驱动器),收集器会定期启动爬网范围的完整遍历,以便索引中的数据保持最新。 对于 NTFS 等源,只有一个爬网,其他所有内容都由 来自 USN 更改日记的通知处理。 此外,Microsoft Outlook 也没有爬网。 下图显示了非爬网索引的队列过程的高级视图。
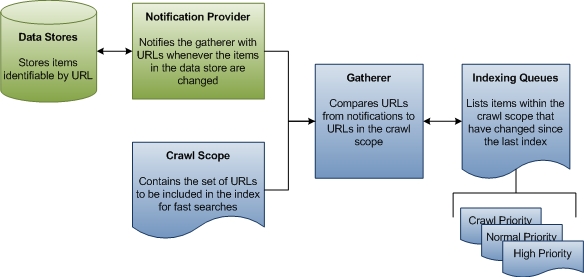
本部分的其余部分介绍 Windows 搜索如何确定要爬网的 URL,并定义过程中的一些重要术语。
爬网范围 爬网范围是 Windows 搜索遍历的一组 URL,用于收集有关用户希望为更快搜索编制索引的项目的数据。 默认情况下,Windows 搜索会向爬网范围添加一些 URL,例如用户 “文档” 和“ 图片” 文件夹的路径。 其他 URL 可由第三方应用程序、用户和组策略添加。 最后,用户和组策略都可以显式排除 URL。 Windows 搜索会获取所有添加的 URL,并删除排除的 URL 以确定爬网范围。 这是收集器从中开始工作的工作 URL 集。
采集 gatherer 是一个 Windows 搜索组件,用于收集有关爬网范围内 URL 的信息,并创建一个 URL 队列供索引器进行爬网。 添加、删除或更新爬网范围内的项时,数据存储的通知提供程序会通知收集器。 有一个初始爬网,收集器从爬网范围根目录开始。 URL 将传递到协议处理程序,然后传递到相应的 IFilter。 筛选器通常是生成更多 URL 的目录枚举。 通知是稳定状态。 通常,每个数据存储都有自己的协议处理程序,用于提供这些通知。 例如,在本地文件系统上, USN 更改日志 充当 file:// 协议下所有 URL 的通知提供程序。 同样,Microsoft Outlook 充当 mapi:// 协议下所有 URL 的通知提供程序。 当用户收到、移动或删除电子邮件时,Outlook 会通知收集者电子邮件的更改状态。 从这些通知中,gatherer 创建要爬网的 URL 的索引队列。
索引队列 索引队列是标识需要编制索引或重新编制索引的项的 URL 列表。 收集器将其从通知提供程序接收的 URL 与爬网范围内的 URL 进行比较。 来自属于爬网范围的通知提供程序的每个 URL 都会添加到队列中,收集器使用该队列确定接下来要处理的 URL 的优先级。
有三个队列:高优先级通知、正常通知和定期爬网。 高优先级队列适用于应立即处理的通知。 例如,当用户在 Windows 资源管理器中更改项的标题属性时,需要在更改后立即更新 Windows 资源管理器视图。 正常的通知队列适用于所有剩余的更改通知。 通知队列在爬网队列之前进行处理,因为用户更可能关注更改的项。 收集器按先入先出 (FIFO) 顺序访问每个队列上的 URL 的数据。
有关 Windows 7 中引入的优先级和事件 API 的详细信息,请参阅 Windows 7 中的索引优先级和行集事件。 有关爬网范围管理和通知的详细信息,请参阅 提供更改通知 和使用 爬网范围管理器。
阶段 2:爬网 URL
在索引编制的第二阶段,收集器在队列中爬网,访问数据存储和检索项流。 首先,收集器为每个 URL 查找相应的协议处理程序。 然后,收集器将 URL 传递给协议处理程序。 协议处理程序访问项并将项元数据传递回收集器。 收集器使用元数据来标识正确的筛选器。
下图显示了 URL 爬网过程的高级视图。 此阶段包括组件之间的大量协调和通信。
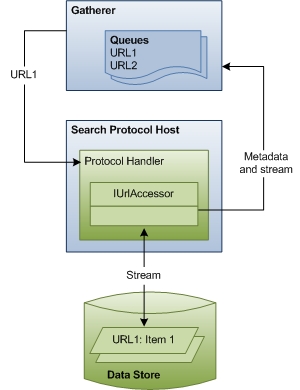
本部分的其余部分介绍 Windows 搜索如何访问项以编制索引,并说明所涉及的每个组件的角色。
采集 在阶段 2(爬网阶段)中,收集器处理队列中的 URL,从高优先级队列开始。 检查每个 URL 以标识其协议。 然后,收集器查找为该协议注册的协议处理程序,并将其实例化到搜索协议主机进程中。
搜索协议主机 搜索协议主机只是协议处理程序的装箱主机进程。 通常,Windows 搜索会创建两个此类主机进程,一个在系统安全上下文中运行,一个在用户安全上下文中运行。 这种分离可确保特定于用户的数据永远不会在系统上下文中运行。
Windows 搜索还使用主机进程将协议处理程序的实例与其他进程或应用程序隔离开来。 这样,任何外部应用程序都无法访问协议处理程序的特定实例,如果协议处理程序意外失败,则只会影响索引过程。 由于主机进程 (协议处理程序) 运行第三方代码,因此 Windows 搜索会定期回收进程,以最大程度地减少成功攻击利用进程中的信息的时间。 除此之外,搜索协议主机不会影响 URL 的爬网或项的索引。
协议处理程序 协议处理程序使用数据存储的协议提供对数据存储区中的项的访问。 例如,NTFS 协议处理程序使用 file:// 协议提供对本地驱动器上的文件的访问。 协议处理程序知道如何遍历数据存储、识别新的或更新的项,以及通知收集器。 然后,在爬网开始时,协议处理程序向收集器提供 IUrlAccessor 对象,以绑定到项的基础流并返回项元数据,例如安全限制和上次修改时间。
注意
协议处理程序不是 Windows 搜索组件;它们是设计为要访问的特定协议和数据存储的组件。 如果想要为自定义数据存储编制索引,则需要实现协议处理程序。 有关协议处理程序以及如何实现协议处理程序的详细信息,请参阅 开发协议处理程序。
元数据和流 使用协议处理程序的 IUrlAccessor 对象返回的元数据,收集器标识 URL 的正确筛选器。 收集器分析项的文件扩展名,并查找为该扩展名注册的筛选器。 如果收集器找不到筛选器,Windows 搜索将使用元数据派生一组最少的系统属性信息, (如 System.ItemName) 并更新索引。 否则,如果收集器找到筛选器,则索引编制的第三个阶段将开始。
阶段 3:更新索引
在索引编制的第三阶段,收集器为 URL 实例化正确的筛选器,并使用 来自 IUrlAccessor 对象的流初始化筛选器。 然后,筛选器访问该项并返回索引的内容。 如果你有自定义文件格式,则 Windows 搜索依赖于你的筛选器来访问 URL 并发出内容和属性进行索引。
下图显示了数据访问过程的高级视图。 此阶段包括组件之间的大量协调和通信。
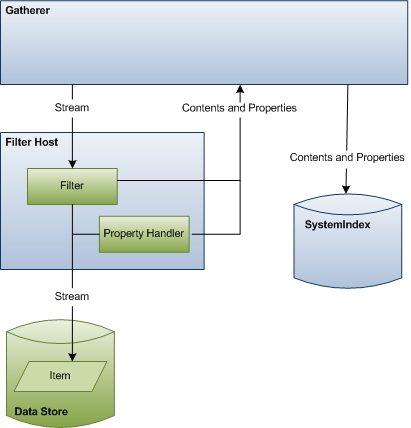
本部分的其余部分介绍 Windows 搜索如何访问项数据以编制索引,并说明所涉及的每个组件的角色。
采集 在此阶段开始时,收集器的角色是实例化项的正确筛选器,并将其传递给项流。 在此阶段结束时,收集器获取筛选器和属性处理程序发出的内容和属性,并更新索引。
筛选器主机 筛选器主机只是筛选器和属性处理程序的主机进程,其用途类似于搜索协议主机。 主机进程出于与搜索协议主机进程隔离协议处理程序相同的安全性和稳定性原因,将筛选器和属性处理程序与系统的其余部分隔离开来。 主机进程以最少的权限运行, (它甚至无法访问文件系统) ,偶尔会回收以防止安全攻击。 Windows 搜索还监视资源使用情况,以便在筛选器消耗过多资源时回收主机进程。
过滤 器 筛选器是索引过程中为收集器发出项信息的关键组件。 筛选器以其实现中使用的主体接口 (即 IFilter 接口)命名,因此有时称为 IFilters。 有两种类型的筛选器:一种与单个项(如文件)交互,另一种与文件夹等容器交互。 两者都为索引提供数据。
使用协议处理程序的 IUrlAccessor 对象返回的元数据,收集器标识特定 URL 的正确筛选器,并将其传递给流。 收集器通过协议处理程序或通过文件扩展名、MIME 类型或类标识符 (CLSID) 标识正确的筛选器。 如果 URL 指向容器,筛选器会发出容器的属性,并枚举容器中的项 (子 URL) 。 如果 URL 指向某个项,则筛选器将返回文本内容(如果任何属性读取内容),并且比属性处理程序更复杂。 通常,我们建议筛选器发出项内容,而属性处理程序发出项属性。 但是,如果筛选器需要使用不识别属性处理程序的旧应用程序,也可以实现筛选器以发出属性。
注意
筛选器不是 Windows 搜索组件;它们是与它们设计为要访问的特定文件格式或容器相关的组件。 有关筛选器以及如何为自定义文件格式或容器实现筛选器的详细信息,请参阅 在 Windows 搜索中创建筛选器处理程序的最佳做法。
下表列出了收集器在索引过程中从 筛选器 (IFilter) 和属性处理程序 (IPropertyStore) 接收的结果。
| IFilter | IPropertyStore | |
|---|---|---|
| 允许写入 | 否 | 是 |
| 混合内容和属性 | 是 | 否 |
| 多 语种 | 是 | 否 |
| 发出链接 | 是 | 否 |
| MIME | 是 | 否 |
| 文本边界 | 句子、段落、章节 | 无 |
| 客户端/服务器 | 两者 | 客户端 |
| 实现 | Complex | 简单 |
属性处理程序 属性处理程序是读取和写入特定文件格式的属性的组件。 它们以与筛选器对内容相同的方式访问项和发出收集器的属性。 属性处理程序比筛选器更容易实现。 如果基于文本的文件格式非常简单,或者预期文件很小,则属性处理程序可以同时发出属性和内容。
注意
属性处理程序不是 Windows 搜索组件;它们是与其设计为要访问的特定文件格式相关的组件。 有关属性处理程序以及如何为自定义文件格式实现属性处理程序的详细信息,请参阅 为 Windows 搜索开发属性处理程序。
性能 Windows 搜索提供一个 包含大型属性 库的属性系统。 任何属性都可以显示在筛选器或属性处理程序定义的任何项上。 如果你有自定义文件格式,则可以将文件格式的属性映射到这些系统属性,并且可以创建新的自定义属性。 当筛选器或属性处理程序发出这些属性时,收集器会更新索引,以便用户可以使用你的属性进行搜索。 有关创建和注册文件格式的自定义属性的详细信息,请参阅 属性系统。
SystemIndex 该索引(称为 SystemIndex)存储索引数据,由属性存储、项属性的属性和内容的索引以及文本内容和属性的倒排索引组成。 收集器更新索引后,Windows 搜索和其他应用程序可以查询索引。 有关查询索引的方法的详细信息,请参阅 以编程方式查询索引。
注意
请记住,重新注册架构时,索引器可能不会遵循对以前定义属性的属性所做的更改。 解决方案是重新生成索引,或引入反映更改的新属性,而不是更新旧属性, (不建议) 。 有关详细信息,请参阅属性系统概述中的说明实现者。
如何计划索引
首次安装 Windows Search 时,它会对爬网范围执行完整索引,在 I/O 和用户活动较高期间暂停。 默认爬网范围包括默认库位置,例如 文档、 音乐、 图片和 视频。 即使在初始爬网完成之前,也会处理通知。 有时,收集器会从完全爬网范围对 URL 进行爬网。 这些完全爬网可确保索引中的数据是全新的。 例如,如果通知提供程序无法发送通知,或者 Windows 搜索服务意外终止,则收集器将不知道新项或更改的项目,并且不会为这些项目编制索引。 有两种类型的源:仅通知和已启用通知。 在这两个源中,收集器最初对索引进行爬网。 初始爬网后,仅通知源将永远不会再次执行完全爬网,除非失败,例如 USN 更改日志 滚动更新。 启用通知的源在索引器启动时执行增量爬网,但在运行时侦听通知。 NTFS 和 Microsoft Outlook 仅为通知。 Internet Explorer 和 FAT 已启用通知。
实施者说明
索引中的数据质量和索引过程的效率在很大程度上取决于筛选器和属性处理程序实现。 由于每次 URL 标识文件格式时都会调用筛选器,因此如果筛选器效率低下,索引过程可能会显著减慢。 如果属性处理程序未将所有文件属性正确映射到系统属性或未正确发出这些属性,则索引中的数据将不正确,稍后搜索这些属性将返回不正确的结果。 如果筛选器或属性处理程序失败,索引器将无法为数据编制索引。
Windows 搜索以外的应用程序和进程依赖于协议处理程序、筛选器和属性处理程序。 实现可能会以你可能不希望的方式影响这些应用程序。 Windows 搜索开发指南提供有关设计选择和测试其中每个组件的建议。