自訂語音是文字到語音功能,可讓您為您的應用程式建立一種自定義的合成語音。 使用自訂語音,您可以藉由提供人類語音範例作為微調數據,為您的品牌或角色創建高度自然的聲音。
現成可用的 文字轉語音 可以使用每個 支援語言的標準語音。 如果不需要唯一的語音,標準語音在大部分文字到語音案例中都運作良好。
自定義語音是以類神經文字語音技術和多語系、多說話者、通用模型為基礎。 您可以建立具有豐富說話樣式或可跨語言調整的合成語音。 自定義語音的逼真自然聲音可以代表品牌、個人化機器,並允許使用者與應用程式交談互動。 請參閱自定義語音 支援的語言 。
如何運作?
若要建立自定義語音,請使用 Speech Studio 上傳錄製的音訊和對應的腳本、將模型定型,以及將語音部署至自定義端點。
建立絕佳的自定義語音需要在每個步驟中仔細進行品質控制,從語音設計和數據準備,到將語音模型部署到您的系統。
在您開始使用 Speech Studio 之前,以下是一些考量:
- 使用角色簡介文件來為您的品牌設計代表語音角色。 此文件會定義語音功能及語音角色等要素。 這有助於引導創建自定義語音模型的流程,包括定義台詞、選擇您的配音演員、進行訓練和語音調校。
- 選取錄製腳本以代表您語音的使用者案例。 例如,如果您要建立客戶服務機器人,可以使用機器人對話中的片語作為錄製腳本。 請在腳本中納入不同的句子類型,包括陳述句、疑問句和感嘆句。
以下是在Speech Studio中建立自訂語音的步驟概觀:
- 建立專案,以包含您的資料、語音模型、測試和端點。 每個專案都是針對特定的國家/地區或區域和語言。 如果您要建立多個語音,建議您為每個語音建立一個專案。
- 設定語音配音員。 在您可以微調專業語音之前,您必須提交語音人才同意聲明的錄音。 聲音人才聲明是聲音人才錄制的一段聲音,其中他們表示同意將其聲音數據用於專業語音微調。
- 以正確的格式準備微調數據。 在專業品質的錄音室中擷取音訊錄製內容是個不錯的主意,可以取得高訊噪比。 語音模型的質量取決於您的微調數據。 一致的音量、語速、音調和語音表達方式是不可或缺的。
- 將語音模型定型。 選取至少 300 個語句以建立自訂語音。 上傳後,系統會自動執行一連串的資料品質檢查。 若要組建高品質的語音模型,您應先修正任何錯誤後再重新提交。
- 測試您的語音。 為您的語音模型準備測試指令碼,且需涵蓋應用程式的不同使用案例。 建議在定型資料集內、外都使用指令碼,以便更全面地測試不同內容的品質。
- 在您的應用程式中部署和使用您的語音模型。
您可以微調、調整及使用自定義語音,就像使用標準語音一樣。 即時將文字轉換成語音,或使用文字輸入來產生離線音訊內容。 您會使用 REST API、語音 SDK 或 Speech Studio。
提示
請查看 GitHub 上語音 SDK 存放庫中 的程式代碼範例,以瞭解如何在應用程式中使用自訂語音。
定型語音模型的風格和特性,取決定型所用之配音員的風格和特質。 不過,當您對語音模型進行 API 呼叫以產生合成語音時,可以使用 SSML (語音合成標記語言) 進行數項調整。 SSML 是用於與文字轉換語音服務溝通,以將文字轉換成音訊的標記語言。 您可以做出的調整包括變更音調、速率、聲調和發音校正。 如果語音模型是以多種風格來組建,也可以使用 SSML 來轉換風格。
元件順序
自訂語音包含三個主要元件:文字分析器、類神經聲學模型和類神經語音編碼器。 為了要從文字產生自然合成語音,首先會將文字輸入文字分析器,以音素序列的形式輸出。 「音素」是聲音的基本單位,可區分特定語言中的字詞。 音素序列會定義文字中提供的單字發音。
接下來,音素序列會進入神經原音模型,以預測定義語音訊號的原音特徵。 原音特徵包括音色、說話風格、速度、音調和重音模式。 最後,神經聲碼器會將原音特徵轉換成有聲聲波,以產生合成語音。
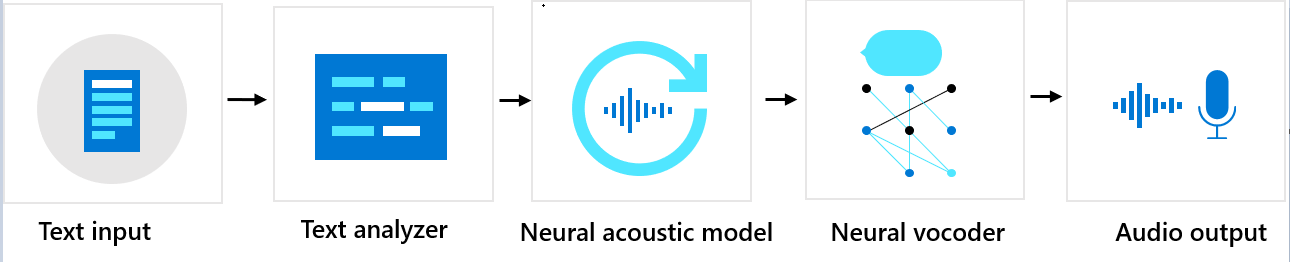
神經文字轉換語音的語音模型會根據人聲的錄音樣本,使用深度神經網路進行定型。 如需詳細資訊,請參閱本 Microsoft 部落格文章 (英文)。 若要深入了解如何定型神經聲碼器的相關資訊,請參閱本 Microsoft 部落格文章 (英文)。
負責 AI
AI 系統不僅包含技術,也包含使用該技術的人員、受其影響的人員及部署的環境。 閱讀透明度資訊,了解在系統中負責任 AI 的使用和部署資訊。
- 自訂語音的透明性說明和使用案例
- 使用自訂語音的特性和限制
- 自定義語音的有限使用權限
- 負責部署合成語音技術的指導方針
- 語音配音員公開
- 公開設計指導方針
- 公開設計模式
- 文字轉換語音整合的管理辦法
- 自訂語音的數據、隱私權和安全性