使用 Azure Data Factory 或 Synapse Analytics 在適用於 PostgreSQL 的 Azure 資料庫中複製和轉換資料
適用於: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
提示
試用 Microsoft Fabric 中的 Data Factory,這是適用於企業的全方位分析解決方案。 Microsoft Fabric 涵蓋從資料移動到資料科學、即時分析、商業智慧和報告的所有項目。 了解如何免費開始新的試用!
本文章概述如何使用 Azure Data Factory 和 Synapse Analytics 管道中的「複製活動」,在適用於 PostgreSQL 的 Azure 資料庫中來回複製資料,以及如何使用資料流程在適用於 PostgreSQL 的 Azure 資料庫中轉換資料。 若要深入了解,請閱讀 Azure Data Factory 和 Synapse Analytics 的介紹文章。
此連接器是專用於適用於 PostgreSQL 的 Azure 資料庫服務。 若要從位於內部部署或雲端的一般 PostgreSQL 資料庫複製資料,請使用 PostgreSQL 連接器 (部分機器翻譯)。
支援的功能
下列功能支援此適用於 PostgreSQL 的 Azure 資料庫連接器:
| 支援的功能 | IR | 受控私人端點 |
|---|---|---|
| 複製活動 (來源/接收) | 4.9 | |
| 對應資料流 (來源/接收) | 5 | |
| 查閱活動 | 4.9 |
① Azure 整合執行階段 ② 自我裝載整合執行階段
在所有適用於 PostgreSQL 的 Azure 資料庫部署選項中,這三個活動均適用:
開始使用
若要透過管線執行複製活動,您可以使用下列其中一個工具或 SDK:
使用 UI 建立連結到適用於 PostgreSQL 的 Azure 資料庫的服務
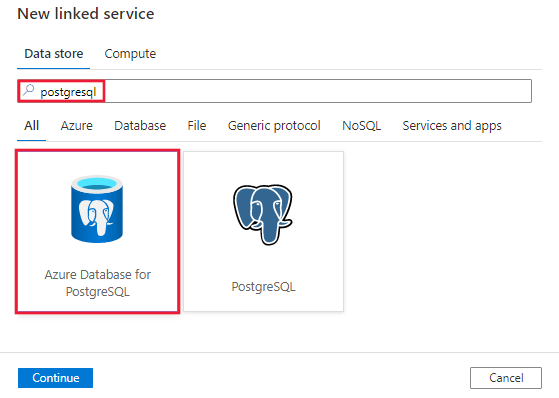
使用下列步驟,在 Azure 入口網站 UI 建立連結到適用於 PostgreSQL 的 Azure 資料庫的服務。
前往 Azure Data Factory 或 Synapse 工作區的 [管理] 索引標籤,選取 [連結服務],然後按一下 [新增]:
搜尋 PostgreSQL,然後選取適用於 PostgreSQL 的 Azure 資料庫連接器。
設定服務詳細資料,測試連線,然後建立新的連結服務。

連接器設定詳細資料
下列各節提供屬性的相關詳細資料,這些屬性是用來定義適用於 PostgreSQL 的 Azure 資料庫連接器專屬的 Data Factory 實體。
連結服務屬性
以下是針對適用於 PostgreSQL 的 Azure 資料庫連結服務支援的屬性:
| 屬性 | 描述 | 必要 |
|---|---|---|
| type | 類型屬性必須設為:AzurePostgreSql。 | Yes |
| connectionString | ODBC 連接字串,用於連線到適用於 PostgreSQL 的 Azure 資料庫。 您也可以將密碼放在 Azure Key Vault 中,並從連接字串中提取 password 設定。 請參閱下列範例和在 Azure Key Vault 中儲存認證 (部分機器翻譯),以獲得更多詳細資料。 |
Yes |
| connectVia | 此屬性代表用來連線到資料存放區的整合執行階段。 您可以使用 Azure Integration Runtime 或「自我裝載 Integration Runtime」(如果您的資料存放區位於私人網路中)。 如果未指定,就會使用預設的 Azure Integration Runtime。 | No |
一般的連接字串為 Server=<server>.postgres.database.azure.com;Database=<database>;Port=<port>;UID=<username>;Password=<Password>。 以下是您可以依據案例設定的更多屬性:
| 屬性 | 說明 | 選項。 | 必要 |
|---|---|---|---|
| EncryptionMethod (EM) | 驅動程式用來加密在驅動程式和資料庫伺服器之間傳送之資料的方法。 例如,EncryptionMethod=<0/1/6>; |
0 (無加密) (預設) / 1 (SSL) / 6 (RequestSSL) | No |
| ValidateServerCertificate (VSC) | 決定啟用 SSL 加密時,驅動程式是否驗證由資料庫伺服器所傳送的憑證 (加密方法 = 1)。 例如,ValidateServerCertificate=<0/1>; |
0 (停用) (預設) / 1 (啟用) | No |
範例:
{
"name": "AzurePostgreSqlLinkedService",
"properties": {
"type": "AzurePostgreSql",
"typeProperties": {
"connectionString": "Server=<server>.postgres.database.azure.com;Database=<database>;Port=<port>;UID=<username>;Password=<Password>"
}
}
}
範例:
在 Azure Key Vault 中儲存密碼
{
"name": "AzurePostgreSqlLinkedService",
"properties": {
"type": "AzurePostgreSql",
"typeProperties": {
"connectionString": "Server=<server>.postgres.database.azure.com;Database=<database>;Port=<port>;UID=<username>;",
"password": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
}
}
}
資料集屬性
如需定義資料集的區段和屬性完整清單,請參閱資料集。 本節提供適用於 PostgreSQL 的 Azure 資料庫資料集的支援屬性清單。
若要從適用於 PostgreSQL 的 Azure 資料庫複製資料,將資料集的類型屬性設定為 AzurePostgreSqlTable。 以下是支援的屬性:
| 屬性 | 描述 | 必要 |
|---|---|---|
| type | 資料集的類型屬性必須設為:AzurePostgreSqlTable | Yes |
| tableName | 資料表的名稱 | 否 (如果已指定活動來源中的「查詢」) |
範例:
{
"name": "AzurePostgreSqlDataset",
"properties": {
"type": "AzurePostgreSqlTable",
"linkedServiceName": {
"referenceName": "<AzurePostgreSql linked service name>",
"type": "LinkedServiceReference"
},
"typeProperties": {}
}
}
複製活動屬性
如需可用來定義活動的區段和屬性完整清單,請參閱管線和活動。 本節提供適用於 PostgreSQL 的 Azure 資料庫來源所支援的屬性清單。
以適用於 PostgreSQL 的 Azure 資料庫作為來源
若要從適用於 PostgreSQL 的 Azure 資料庫複製資料,將複製活動中的來源類型設定為 AzurePostgreSqlSource。 複製活動的 source 區段支援下列屬性:
| 屬性 | 描述 | 必要 |
|---|---|---|
| type | 複製活動來源的類型屬性必須設為 AzurePostgreSqlSource | Yes |
| query | 使用自訂 SQL 查詢來讀取資料。 例如:SELECT * FROM mytable 或 SELECT * FROM "MyTable"。 請注意,在 PostgreSQL 中,如果未加上引號,實體名稱會被視為不區分大小寫。 |
否 (如果已指定資料集的 tableName 屬性) |
| partitionOptions | 指定用來從 Azure SQL Database 載入資料的資料分割選項。 允許的值為:None (預設值)、PhysicalPartitionsOfTable 和 DynamicRange。 啟用分割區選項後 (即不是 None),從 Azure SQL Database 並行載入資料的平行處理程度,會由複製活動的 parallelCopies 設定所控制。 |
No |
| partitionSettings | 指定資料分割的設定群組。 當分割選項不是 None 時套用。 |
No |
在 partitionSettings 之下: |
||
| partitionNames | 需要複製的實體分割區清單。 當分割選項是 PhysicalPartitionsOfTable 時套用。 如果您使用查詢來取出來源資料,請在 WHERE 子句中加上 ?AdfTabularPartitionName。 如需範例,請參閱平行複製適用於 PostgreSQL 的 Azure 資料庫一節。 |
No |
| partitionColumnName | 以整數類型或日期/日期時間類型 (int、smallint、bigint、date、timestamp without time zone、timestamp with time zone 或 time without time zone) 指定來源資料行的名稱,供平行複製的範圍分割使用。 如果未指定,則會自動偵測資料表的主索引鍵作為分割資料行。當分割選項是 DynamicRange 時套用。 如果您使用查詢來取出來源資料,請在 WHERE 子句中加上 ?AdfRangePartitionColumnName 。 如需範例,請參閱平行複製適用於 PostgreSQL 的 Azure 資料庫一節。 |
No |
| partitionUpperBound | 從分割資料行複製出資料時的最大值。 當分割選項是 DynamicRange 時套用。 如果您使用查詢來取出來源資料,請在 WHERE 子句中加上 ?AdfRangePartitionUpbound。 如需範例,請參閱平行複製適用於 PostgreSQL 的 Azure 資料庫一節。 |
No |
| partitionLowerBound | 從分割資料行複製出資料時的最小值。 當分割選項是 DynamicRange 時套用。 如果您使用查詢來取出來源資料,請在 WHERE 子句中加上 ?AdfRangePartitionLowbound。 如需範例,請參閱平行複製適用於 PostgreSQL 的 Azure 資料庫一節。 |
No |
範例:
"activities":[
{
"name": "CopyFromAzurePostgreSql",
"type": "Copy",
"inputs": [
{
"referenceName": "<AzurePostgreSql input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "AzurePostgreSqlSource",
"query": "<custom query e.g. SELECT * FROM mytable>"
},
"sink": {
"type": "<sink type>"
}
}
}
]
以適用於 PostgreSQL 的 Azure 資料庫作為接收器
若要將資料複製到適用於 PostgreSQL 的 Azure 資料庫,複製活動 sink 區段中支援下列屬性:
| 屬性 | 描述 | 必要 |
|---|---|---|
| type | 複製活動接收的類型必須設為 AzurePostgreSQLSink。 | Yes |
| preCopyScript | 每次執行中,在將資料寫入到適用於 PostgreSQL 的 Azure DB 之前,先指定一個供「複製活動」執行的 SQL 查詢。 您可以使用此屬性來清除預先載入的資料。 | No |
| writeMethod | 用來將資料寫入適用於 PostgreSQL 的 Azure 資料庫的方法。 允許的值為:CopyCommand (預設,其效能較佳)、BulkInsert。 |
No |
| writeBatchSize | 每個批次載入適用於 PostgreSQL 的 Azure 資料庫的資料列數目。 允許的值為代表資料列數目的整數。 |
否 (預設為 1,000,000) |
| writeBatchTimeout | 在逾時前等待批次插入作業完成的時間。 允許的值為:時間範圍字串。 範例是 00:30:00 (30 分鐘)。 |
否 (預設為 00:30:00) |
範例:
"activities":[
{
"name": "CopyToAzureDatabaseForPostgreSQL",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Azure PostgreSQL output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "AzurePostgreSQLSink",
"preCopyScript": "<custom SQL script>",
"writeMethod": "CopyCommand",
"writeBatchSize": 1000000
}
}
}
]
從適用於 PostgreSQL 的 Azure 資料庫平行複製資料
在複製活動中,適用於 PostgreSQL 的 Azure 資料庫連接器提供內建的資料分割,以平行複製資料。 您可以在複製活動的 [來源] 索引標籤上找到資料分割選項。

當您啟用分割複本時,複製活動會平行查詢適用於 PostgreSQL 的 Azure 資料庫來源,以依分割區來載入資料。 平行程度由複製活動的 parallelCopies 設定所控制。 例如,如果您將 parallelCopies 設定為四,服務會根據您指定的分割區選項和設定,同時產生並執行四個查詢,而每個查詢會從適用於 PostgreSQL 的 Azure 資料庫資料庫取擷取一部分資料。
建議您啟用平行複製與資料分割,特別是從適用於 PostgreSQL 的 Azure 資料庫資料庫載入大量資料時。 以下針對各種情節的建議設定。 將資料複製到以檔案為基礎的資料存放區時,建議分成多個檔案來寫入資料夾 (僅指定資料夾名稱),這樣效能會比寫入單一檔案更好。
| 案例 | 建議的設定 |
|---|---|
| 使用實體分割區從大型資料表完整載入。 | 分割選項:資料表的實體分割區。 在執行期間,服務會自動偵測實體分割區,並依分割區複製資料。 |
| 從大型資料表完整載入,不含實體分割區,同時在資料分割時包含整數資料行。 | 分割選項:動態範圍分割。 分割資料行:指定用來分割資料的資料行。 如果未指定,則會使用主索引鍵資料行。 |
| 使用自訂查詢載入大量資料,包含實體分割區。 | 分割選項:資料表的實體分割區。 查詢: SELECT * FROM ?AdfTabularPartitionName WHERE <your_additional_where_clause>。分割區名稱:指定要從中複製資料的分割區名稱。 如果未指定,服務會自動偵測您在 PostgreSQL 資料集中指定的資料表上的實體分割區。 在執行期間,服務會以實際的分割區名稱取代 ?AdfTabularPartitionName,並傳送至適用於 PostgreSQL 的 Azure 資料庫。 |
| 使用自訂查詢載入大量資料,不含實體分割區,同時包含整數資料行用於資料分割。 | 分割選項:動態範圍分割。 查詢: SELECT * FROM ?AdfTabularPartitionName WHERE ?AdfRangePartitionColumnName <= ?AdfRangePartitionUpbound AND ?AdfRangePartitionColumnName >= ?AdfRangePartitionLowbound AND <your_additional_where_clause>。分割資料行:指定用來分割資料的資料行。 您可以按照整數或日期/日期時間資料類型的資料行來分割。 分割上限和分割下限:指定您是否想要篩選分割資料行,只取出下限範圍和上限範圍之間的資料。 在執行期間,服務會將 ?AdfRangePartitionColumnName、?AdfRangePartitionUpbound 和 ?AdfRangePartitionLowbound 取代為每個分割區的實際資料行名稱和值範圍,並傳送至適用於 PostgreSQL 的 Azure 資料庫。 例如,如果分割資料行 "ID" 已設定下限 1 和上限 80,而平行複製設定為 4,則服務會分成 4 個分割區來取出資料。 識別碼的範圍分別為 [1,20]、[21, 40]、[41, 60] 和 [61, 80]。 |
使用分割區選項載入資料的最佳做法:
- 選擇獨特的資料行作為分割資料行 (例如主索引鍵或唯一索引鍵) 以避免資料扭曲。
- 如果資料表有內建分割區,請使用分割選項「資料表的實體分割區」,以獲得更佳的效能。
- 如果您使用 Azure Integration Runtime 來複製資料,您可以設定較大的「資料整合單位 (DIU)」(>4) 來利用更多運算資源。 檢查該處適用的案例。
- 「複製平行處理原則的程度」會控制分割區數目,將此數目設定過大有時會損害效能,建議將此數目設定為 (DIU 或自我裝載 IR 節點數目) * (2 到 4)。
範例:使用實體分割區從大型資料表完整載入
"source": {
"type": "AzurePostgreSqlSource",
"partitionOption": "PhysicalPartitionsOfTable"
}
範例:使用動態範圍分割進行查詢
"source": {
"type": "AzurePostgreSqlSource",
"query": "SELECT * FROM <TableName> WHERE ?AdfDynamicRangePartitionCondition AND <your_additional_where_clause>",
"partitionOption": "DynamicRange",
"partitionSettings": {
"partitionColumnName": "<partition_column_name>",
"partitionUpperBound": "<upper_value_of_partition_column (optional) to decide the partition stride, not as data filter>",
"partitionLowerBound": "<lower_value_of_partition_column (optional) to decide the partition stride, not as data filter>"
}
}
對應資料流程屬性
在對應資料流程中轉換資料時,您可以從適用於 PostgreSQL 的 Azure DB 分析讀取和寫入資料表。 如需詳細資訊,請參閱對應資料流程中的來源轉換和接收轉換。 您可以選擇使用適用於 PostgreSQL 的 Azure 資料庫資料集或內嵌資料集做為來源和接收器類型。
來源轉換
下表列出適用於 PostgreSQL 的 Azure 資料庫來源所支援的屬性。 您可以在 [來源選項] 索引標籤中編輯這些屬性。
| 名稱 | 描述 | 必要 | 允許的值 | 資料流程指令碼屬性 |
|---|---|---|---|---|
| Table | 如果您選取 [資料表] 作為輸入,資料流程會從資料集中指定的資料表擷取所有資料。 | No | - | (僅限內嵌資料集) tableName |
| 查詢 | 如果您選取 [查詢] 作為輸入,請指定要從來源擷取資料的 SQL 查詢,這會覆寫您在資料集中指定的任何資料表。 使用查詢也是減少測試或查閱資料行的絕佳方式。 不支援 Order By 子句,但您可以設定完整的 SELECT FROM 陳述式。 您也可使用使用者定義的資料表函數。 select * from udfGetData() 是 SQL 中的 UDF,您可以在資料流程中用於傳回資料表。 查詢範例: select * from mytable where customerId > 1000 and customerId < 2000 或 select * from "MyTable"。 請注意,在 PostgreSQL 中,如果未加上引號,實體名稱會被視為不區分大小寫。 |
No | String | query |
| 結構描述名稱 | 如果您選取 [預存程序] 作為輸入,請指定預存程序的結構描述名稱,或選取 [重新整理] 以要求服務探索結構描述名稱。 | No | String | schemaName |
| 預存程序 | 如果您選取 [預存程序] 作為輸入,請指定要從來源資料表讀取資料的預存程序名稱,或選取 [重新整理] 以要求服務探索程序名稱。 | 是 (如果您選取 [預存程序] 作為輸入) | String | procedureName |
| 程序參數 | 如果您選取 [預存程序] 作為輸入,請指定儲存程序的輸入參數 (依照程序中設定的順序),或選取 [匯入] 以使用表單 @paraName 來匯入所有程序參數。 |
No | 陣列 | 輸入 |
| 批次大小 | 指定批次大小,以將大量資料分成多個批次。 | No | 整數 | batchSize |
| 隔離等級 | 選擇下列其中一個隔離等級: - 讀取認可 - 讀取未認可 (預設值) - 可重複讀取 - 可序列化 - 無 (忽略隔離等級) |
No | READ_COMMITTED READ_UNCOMMITTED REPEATABLE_READ SERIALIZABLE NONE |
isolationLevel |
適用於 PostgreSQL 的 Azure 資料庫來源指令碼範例
您使用適用於 PostgreSQL 的 Azure 資料庫做為來源類型時,相關聯的資料流程指令碼為:
source(allowSchemaDrift: true,
validateSchema: false,
isolationLevel: 'READ_UNCOMMITTED',
query: 'select * from mytable',
format: 'query') ~> AzurePostgreSQLSource
接收轉換
下表列出適用於 PostgreSQL 的 Azure 資料庫接收器所支援的屬性。 您可以在 [接收器選項] 索引標籤中編輯這些屬性。
| 名稱 | 描述 | 必要 | 允許的值 | 資料流程指令碼屬性 |
|---|---|---|---|---|
| 更新方法 | 指定您的資料庫目的地所允許的作業。 預設僅允許插入。 若要更新、upsert 或刪除資料列,必須使用 [變更資料列轉換] 來標記這些動作的資料列。 |
Yes | true 或 false |
deletable insertable updateable upsertable |
| 索引鍵資料行 | 對於更新、更新插入和刪除,必須設定索引鍵資料行以決定要變更哪一個資料列。 您挑選作為索引鍵的資料行名稱,將會在後續更新、更新插入、刪除時使用。 因此,您必須挑選存在於接收器對應中的資料行。 |
No | 陣列 | 金鑰 |
| 略過寫入索引鍵資料行 | 如果您不想將值寫入索引鍵資料行,請選取 [跳過寫入索引鍵資料行]。 | No | true 或 false |
skipKeyWrites |
| 資料表動作 | 決定在寫入之前,是否要重新建立或移除目的地資料表中的所有資料列。 - 無:不會對資料表執行任何動作。 - 重新建立:將會捨棄並重新建立資料表。 如果要動態建立新的資料表,則為必要。 - 截斷:將會移除目標資料表中的所有資料列。 |
No | true 或 false |
recreate truncate |
| 批次大小 | 指定要在每個批次中寫入的資料列數目。 較大的批次大小會改善壓縮和記憶體優化,但會導致在快取資料時發生記憶體例外狀況的風險。 | No | 整數 | batchSize |
| 選取使用者資料庫結構描述 | 根據預設,系統會在接收結構描述下建立暫存資料表,並將其作為暫存處理序。 或者,您也可以取消核取 [使用接收結構描述] 選項,改為指定一個結構描述名稱,讓 Data Factory 可用來建立暫存表格以便載入上游資料,並在完成時自動將其清除。 請確定您的資料庫中具有建立資料表的權限,以及改變結構描述的權限。 | No | String | stagingSchemaName |
| 前置和後置 SQL 指令碼 | 指定將在寫入至您的接收器資料庫之前 (前置處理) 和之後 (後置處理) 將執行的多行 SQL 指令碼。 | No | String | preSQLs postSQLs |
提示
- 建議將含有多個命令的單一批次指令碼分成多個批次。
- 只有傳回簡單更新計數的資料定義語言 (DDL) 和資料操作語言 (DML) 陳述式可以當作批次的一部份來執行。 若要深入了解,請參閱執行批次作業
啟用累加擷取:使用此選項可告訴 ADF 只處理自上次執行管線後變更的資料列。
累加資料行:使用累加擷取功能時,您必須選擇想要在來源資料表中用作浮水印的日期/時間或數值資料行。
從頭開始讀取:使用累加擷取設定此選項,會指示 ADF 在第一次執行管線時讀取所有資料列,並開啟累加擷取。
適用於 PostgreSQL 的 Azure 資料庫接收器指令碼範例
您使用適用於 PostgreSQL 的 Azure 資料庫做為接收器類型時,相關聯的資料流程指令碼為:
IncomingStream sink(allowSchemaDrift: true,
validateSchema: false,
deletable:false,
insertable:true,
updateable:true,
upsertable:true,
keys:['keyColumn'],
format: 'table',
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> AzurePostgreSQLSink
查閱活動屬性
如需屬性的詳細資訊,請參閱查閱活動。
相關內容
如需複製活動支援作為來源和接收器的資料存放區清單,請參閱支援的資料存放區。