使用 Power Fx 開放原始碼低程式碼公式,您可以將更強大、更靈活的 AI 模型整合新增到 Power App 中。 AI 模型預測公式可以與畫布應用程式中的任何控制項整合。 例如,您可以偵測文字輸入控制項中文字的語言,並將結果輸出至標籤控制項,如下面的使用具有控制項的模型一節所示。
需求
若要在 AI Builder 模型中使用 Power Fx,您必須:
使用資料庫存取 Microsoft Power Platform 環境。
AI Builder 授權 (試用版或付費版)。 若要深入了解,請移至 AI Builder 授權。
選取畫布應用程式中的模型
若要使用具有 Power Fx 的 AI 模型,您需要建立一個畫布應用程式,選擇控制項,並將運算式指派給控制項屬性。
Note
如需可使用的 AI Builder 模型清單,請參閱 AI 模型和商務案例。 您也可以使用使用自己的模型函數,來使用 Microsoft Azure 機器學習中內建的模型。
建立應用程式。 其他資訊:從頭開始建立空白畫布應用程式。
選取資料>添加資料>AI 模型。
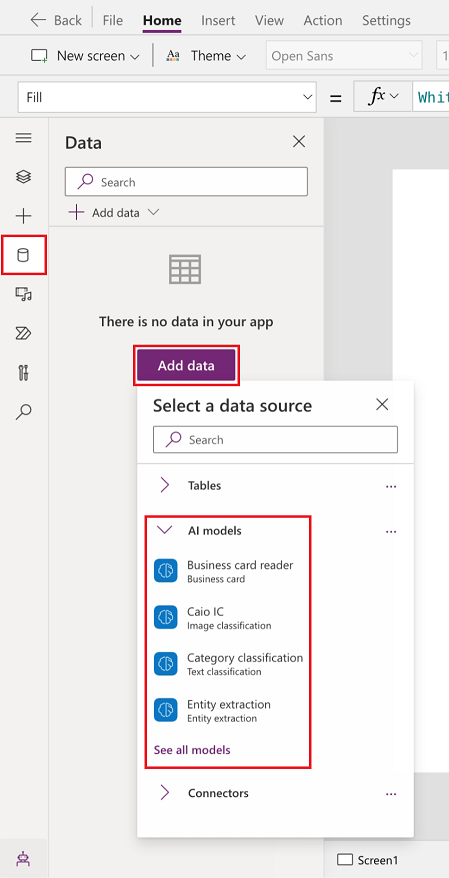
選取一個或多個要新增的模型。
如果您在該清單中沒看見您的模型,則您可能無權在 Power Apps 中使用它。 連絡您的管理員以解決這個問題。
使用具有控制項的模型
現在您已將 AI 模型新增至您的畫布應用程式,讓我們看看如何從控制項呼叫 AI Builder 模型。
在以下範例中,我們將建立一個可偵測使用者在應用程式中輸入之語言的應用程式。
建立應用程式。 其他資訊:從頭開始建立空白畫布應用程式。
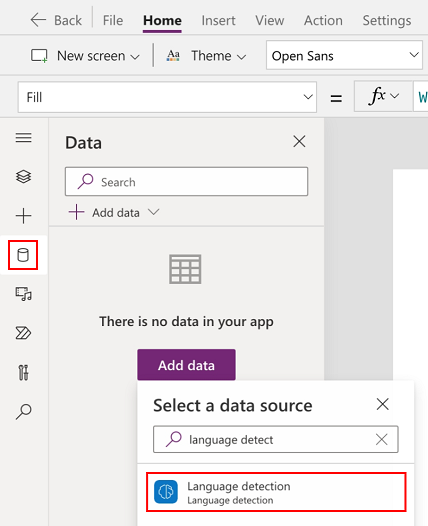
選取資料>添加資料>AI 模型。
搜尋並選取語言偵測 AI 模型。
Note
跨環境移動應用程式時,您必須在新環境中再次手動將模型新增到應用程式。
從左窗格選取 +,然後選取 Text input 控制項。
重複前一個步驟以新增 Text label 控制項。
將文字標籤重新命名為語言。
在「語言」標籤旁邊,新增另一個文字標籤。
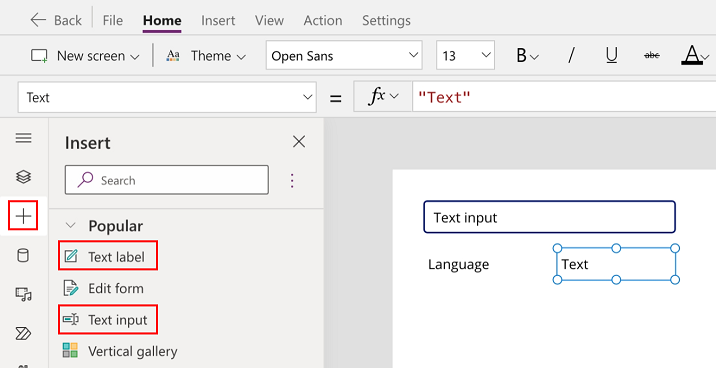
選取上一步中新增的文字標籤。
在文字標籤的 Text 屬性的資料編輯列中輸入以下公式。
'Language detection'.Predict(TextInput1.Text).Language標籤會根據您的地區設定變更為語言代碼。 在此範例中是 en (英文)。
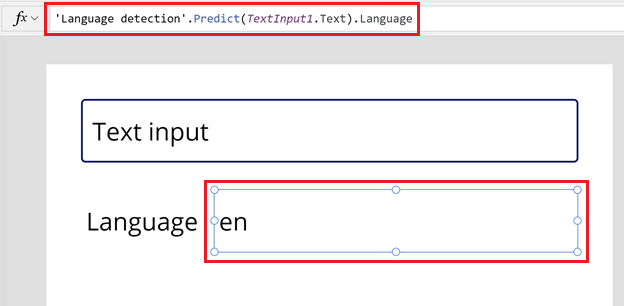
從畫面右上角選取播放按鈕來預覽應用程式。
在文字方塊中,輸入
bonjour。 請注意,法國 (fr) 的語言會顯示在文字方塊下方。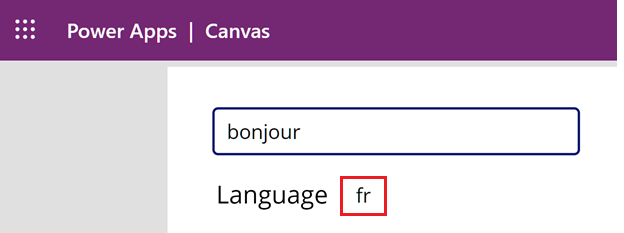
同樣地,請嘗試其他語言文字。 例如,輸入
guten tag會將偵測到的語言變更為德文語言 de。
最佳作法
嘗試使用按鈕而不是文字輸入上的 OnChange 動作從單一動作 (例如 OnClick) 觸發模型預測,以確保有效使用 AI Builder 點數。
為了節省時間和資源,請儲存模型呼叫的結果,以便在多個地方使用它。 您可以將輸出儲存至全域變數中。 儲存模型結果後,您可以在應用程式的其他地方使用該語言在兩個不同的標籤中顯示已識別的語言及其信賴度分數。
Set(lang, 'Language detection'.Predict("bonjour").Language)
依模型類型輸入和輸出
本節提供依模型類型為自訂和預建模型的輸入和輸出。
自訂模型
| 模型類型 | 語法 | 輸出 |
|---|---|---|
| 類別分類 | 'Custom text classification model name'.Predict(Text: String, Language?: Optional String) |
{AllClasses: {Name: String, Confidence: Number}[],TopClass: {Name: String,Confidence: Number}} |
| 實體擷取 | 'Custom entity extraction model name’.Predict(Text: String,Language?:String(Optional)) |
{Entities:[{Type: "name",Value: "Bill", StartIndex: 22, Length: 4, Confidence: .996, }, { Type: "name", Value: "Gwen", StartIndex: 6, Length: 4, Confidence: .821, }]} |
| 物件偵測 | 'Custom object detection model name'.Predict(Image: Image) |
{ Objects: { Name: String, Confidence: Number, BoundingBox: { Left: Number, Top: Number, Width: Number, Height: Number }}[]} |
預建模型
注意
預建模型名稱會顯示在環境的地區設定中。 下列範例顯示英文語言 (en) 的模型名稱。
| 模型類型 | 語法 | 輸出 |
|---|---|---|
| 名片讀取器 | ‘Business card reader’.Predict( Document: Base64 encoded image ) |
{ Fields: { FieldName: { FieldType: "text", Value: { Text: String, BoundingBox: { Top: Number, Left: Number, Height: Number, Width: Number }}}}} |
| 類別分類 | 'Category classification'.Predict( Text: String,Language?: Optional String, ) |
{ AllClasses: { Name: String, Confidence: Number }[], TopClass: { Name: String, Confidence: Number }} |
| 身分證件讀取器 | ‘Identity document reader’.Predict( Document: Base64 encoded image ) |
{ Context: { Type: String, TypeConfidence: Number }, Fields: { FieldName: { FieldType: "text", Confidence: Number, Value: { Text: String, BoundingBox: { Top: Number, Left: Number, Height: Number, Width: Number }}}}} |
| 發票處理 | ‘Invoice processing’.Predict( Document: Base64 encoded image ) |
{ Fields: { FieldName: { FieldType: "text" | "date" | "number", Confidence: Number,Value: { Text: String, [Date: Date] | [Number: Number], BoundingBox: { Top: Number, Left: Number, Height: Number, Width: Number } } } }, Tables: { Items: { Rows: { FieldName: { FieldType: "text" | "date" | "number", Confidence: Number, Key: { Name: String, }, Value: { Text: String, [Date: Date] | [Number: Number], BoundingBox: { Top: Number, Left: Number, Height: Number, Width: Number } } } }[] } }} |
| 關鍵片語擷取 | 'Key phrase extraction'.Predict(Text: String, Language?: Optional String)) |
{ Phrases: String[]} |
| 語言偵測 | 'Language Detection'.Predict(Text: String) |
{ Language: String, Confidence: Number} |
| 收據處理 | ‘Receipt processing’.Predict( Document: Base64 encoded image) |
{ Context: { Type: String, TypeConfidence: Number }, Fields: { FieldName: { FieldType: "text" | "date" | "number", Confidence: Number, Value: { Text: String, [Date: Date] | [Number: Number], BoundingBox: { Top: Number, Left: Number, Height: Number, Width: Number } } } }, Tables: {Items: {Rows: {FieldName: { FieldType: "text" | "date" | "number", Confidence: Number, Key: { Name: String, }, Value: { Text: String, [Date: Date] | [Number: Number], BoundingBox: { Top: Number, Left: Number, Height: Number, Width: Number } } } }[] } } } |
| 人氣分析 | 'Sentiment analysis'.Predict( Text: String, Language?: Optional String ) |
{ Document: { AllSentiments: [ { Name: "Positive", Confidence: Number }, { Name: "Neutral", Confidence: Number }, { Name: "Negative", Confidence: Number } ], TopSentiment: { Name: "Positive" | "Neutral" | "Negative", Confidence: Number } } Sentences: { StartIndex: Number, Length: Number, AllSentiments: [ { Name: "Positive", Confidence: Number }, { Name: "Neutral", Confidence: Number }, { Name: "Negative", Confidence: Number } ], TopSentiment: { Name: "Positive" | "Neutral" | "Negative", Confidence: Number } }[]} |
| 文字辨識 | 'Text recognition'.Predict( Document: Base64 encoded image) |
{Pages: {Page: Number,Lines: { Text: String, BoundingBox: { Left: Number, Top: Number, Width: Number, Height: Number }, Confidence: Number }[] }[]} |
| 文字翻譯 | 'Text translation'.Predict( Text: String, TranslateTo?: String, TranslateFrom?: String) |
{ Text: String, // Translated text DetectedLanguage?: String, DetectedLanguageConfidence: Number} } |
範例
每個模型都使用預測動詞來叫用。 例如,語言偵測模型會將文字當做輸入,並傳回可能語言的資料表 (依該語言的分數排序)。 分數表示模型與其預測的信賴度。
| 輸入 | 輸出 |
|---|---|
'Language detection'.Predict("bonjour") |
{ Language: “fr”, Confidence: 1} |
‘Text Recognition’.Predict(Image1.Image) |
{ Pages: [ {Page: 1, Lines: [ { Text: "Contoso account", BoundingBox: { Left: .15, Top: .05, Width: .8, Height: .10 }, Confidence: .97 }, { Text: "Premium service", BoundingBox: { Left: .15, Top: .20, Width: .8, Height: .10 }, Confidence: .96 }, { Text: "Paid in full", BoundingBox: { Left: .15, Top: .35, Width: .8, Height: .10 }, Confidence: .99 } } ] } |