什麼是影像分析?
Azure AI 視覺影像分析服務可以從影像中擷取各式各樣的視覺特徵。 例如,它可判斷影像是否包含成人內容、尋找特定的品牌或物件,或尋找人臉。
最新版本的影像分析 4.0 目前已正式發行,提供同步 OCR 和人員偵測等新功能。 建議您今後使用此版本。
您可以透過用戶端程式庫 SDK 或直接呼叫 REST API 來使用影像分析。 請遵循快速入門開始作業。
或者您可以使用 Vision Studio 在瀏覽器中快速輕鬆地試用影像分析的功能。
此文件包含下列類型的文章:
- 快速入門是逐步指示,可讓您呼叫服務並在短時間內取得結果。
- 操作指南包含以更具體或自訂的方式使用服務的指示。
- 概念性文章提供服務功能和特徵的深入說明。
- 教學課程是篇幅較長的指南,示範如何在更廣泛的商務解決方案中使用此服務作為元件。
如需更為結構化的方法,請遵循影像分析的定型課程模組。
影像分析版本
重要
選取最符合您需求的影像分析 API 版本。
| 版本 | 可用的功能 | 建議 |
|---|---|---|
| 4.0 版 | 讀取文字、標題、密集標題、標籤、物件偵測、自訂影像分類/物件偵測、人員、智慧裁剪 | 更好的模型;如果支援您的使用案例,請使用 4.0 版。 |
| 3.2 版 | 標籤、物件、描述、品牌、臉部、影像類型、色彩配置、地標、名人、成人內容、智慧裁剪 | 更廣泛的功能;如果您的使用案例尚未在 4.0 版中受到支援,請使用 3.2 版 |
如果影像分析 4.0 API 支援您的使用案例,則建議您使用。 如果您的使用案例尚未受到 4.0 支援,請使用 3.2 版。
如果您想要進行圖像描述且您的視覺資源位於支援的 Azure 區域之外,您也必須使用 3.2 版。 影像分析 4.0 中的圖像描述功能僅支援特定 Azure 區域。 3.2 版中的影像標題適用於所有 Azure AI 視覺區域。 請參閱區域可用性 (英文)。
分析影像
您可以分析影像,以提供與其視覺特徵和特性有關的深入解析。 清單中的所有功能皆由分析影像 API 所提供。 請遵循快速入門以開始使用。
| 名稱 | 描述 | 概念頁面 |
|---|---|---|
| 模型自訂 (僅限 v4.0 預覽版) | 您可以建立和定型自訂模型,以執行影像分類或物件偵測。 攜帶您自己的影像、使用自訂標籤進行標記,而影像分析會定型針對使用案例自訂的模型。 | 模型自訂 |
| 讀取影像中的文字 (僅限 v4.0) | 影像分析 4.0 預覽版提供從影像擷取可閱讀文字的功能。 相較於非同步電腦視覺 3.2 Read API,新版本在整合的效能增強同步 API 中,提供熟悉的 Read OCR 引擎,可以在單一 API 呼叫中輕鬆取得 OCR 以及其他見解。 | 影像的 OCR |
| 偵測影像中的人員 (僅限 v4.0) | 影像分析的 4.0 版提供偵測出現在影像中人員的功能。 系統會傳回每個所偵測到人員的週框方塊座標,以及信賴分數。 | 人員偵測 |
| 產生影像標題 | 以一般人看得懂的標題,使用完整的句子產生整個影像的描述。 電腦視覺的演算法會根據在影像中識別出來的物件產生標題。 4.0 版影像標題模型是更進階的實作,可搭配更廣泛的輸入影像使用。 這僅適用於特定地理區域。 請參閱區域可用性 (英文)。 4.0 版也可讓您使用密集標題,這會產生影像中所找到個別物件的詳細標題。 API 會以像素為單位傳回影像中所找到每個物件的週框方塊,並加上標題。 您可以使用這項功能來產生影像個別部分的描述。 
|
產生影像標題 (v3.2) (v4.0) |
| 偵測物件 | 物件偵測與標記功能類似,但 API 會傳回每個所套用標記的週框方塊座標。 例如,如果影像包含狗、貓或人物,「偵測」作業就會列出這些物件及其在影像中的座標。 您可以使用此功能來處理影像中物件間的進一步關聯性。 當影像中有多個相同標記的執行個體時,此功能也會讓您知道。 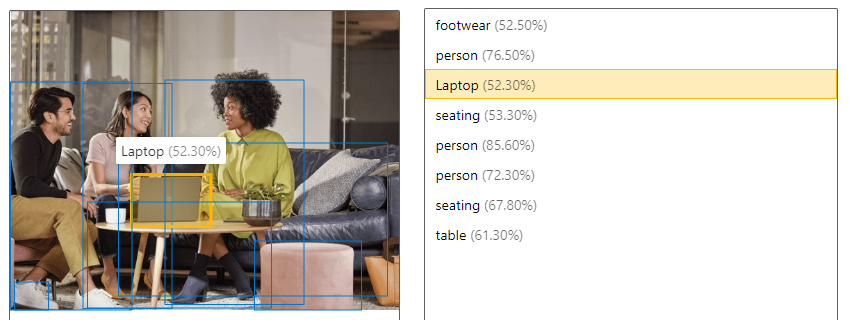
|
偵測物件 (v3.2) (v4.0) |
| 標記視覺特徵 | 從一組數千個可辨識的物件、生物、景象和動作,識別及標記影像中的視覺特徵。 若標記不明確或不屬於常識,API 回應會提供提示來釐清標記的內容。 標記並未限定於主體 (例如前景中的人物),而是包含周遭環境 (室內或室外)、家具、工具、植物、動物、配件和小工具等。
|
標記視覺特徵 (v3.2) (v4.0) |
| 取得關注區域 / 智慧型裁切 | 分析影像內容,以傳回符合指定外觀比例的關注區域座標。 電腦視覺會傳回該區域的周框方塊座標,讓呼叫端的應用程式可以視需要修改原始影像。 4.0 版智慧裁剪模型是更進階的實作,可搭配更廣泛的輸入影像使用。 這僅適用於特定地理區域。 請參閱區域可用性 (英文)。 |
產生縮圖 (v3.2) (v4.0 預覽版) |
| 偵測品牌 (僅限 v3.2) | 從擁有數千個全球商標的資料庫中,識別影像或視訊內的商業品牌。 例如,您可以使用這項功能探索哪些品牌在社交媒體最受歡迎或在媒體產品位置中最常見。 | 偵測品牌 |
| 分類影像 (僅限 v3.2) | 使用具有父/子承襲階層的類別分類法來識別及分類整個影像。 類別可單獨使用,或與我們新的標記模型搭配使用。 目前,英文是唯一支援影像標記和分類的語言。 |
將影像分類 |
| 偵測臉部 (僅限 v3.2) | 偵測影像中的臉部,並提供與每個偵測到的臉部有關的資訊。 Azure AI 視覺會針對每個偵測到的臉部傳回座標、矩形、性別和年齡。 您也可以使用專用的臉部 API 來達成這些目的。 這可以提供更詳細的分析,例如臉部識別和姿勢偵測。 |
偵測臉部 |
| 偵測影像類型 (僅限 v3.2) | 偵測影像的關於特性,例如影像是否為線條繪圖,或影像為美工圖案的可能性。 | 偵測影像類型 |
| 偵測特定領域內容 (僅限 v3.2) | 使用領域模型可偵測及識別影像中的特定領域內容,例如名人和地標。 例如,如果影像包含人物,Azure AI 視覺即可使用名人領域模型,判斷影像中偵測到的人物是否為知名人士。 | 偵測特定領域內容 |
| 偵測色彩配置 (僅限 v3.2) | 分析影像中的用色方式。 Azure AI 視覺可判斷影像是黑白還是彩色,如果是彩色影像,則會找出主色和輔色。 | 偵測色彩配置 |
| 調節影像中的內容 (僅限 v3.2) | 您可以使用 Azure AI 視覺在影像中偵測成人內容,並傳回不同分類的信賴分數。 為內容加上旗標的閾值可用滑動標尺來設定,以配合您的喜好設定。 | 偵測成人內容 |
提示
您可以透過 Azure OpenAI 服務,使用影像分析的讀取文字和物件偵測功能。 GPT-4 Turbo with Vision 模型可讓您與 AI 助理聊天以分析您共用的影像,而視覺增強選項會使用影像分析來提供 AI 助理更多關於影像的詳細資料 (可讀取的文字和物件位置)。 如需詳細資訊,請參閱 GPT-4 Turbo with Vision 快速入門。
產品辨識 (僅限 v4.0 預覽版)
產品辨識 API 可讓您分析零售商店中的貨架相片。 您可以偵測產品是否存在,並取得其週框方塊座標。 將其與模型自訂搭配使用,定型模型以識別您的特定產品。 您也可以比較產品辨識結果與商店的貨架圖文件。
多模式內嵌 (僅限 v4.0)
多模式內嵌 API 可讓您向量化影像和文字查詢。 其會將影像轉換成多維度向量空間中的座標。 然後,傳入的文字查詢也可以轉換成向量,且影像可以根據語意接近程度來比對文字。 這可讓使用者使用文字搜尋一組影像,而不需要使用影像標籤或其他中繼資料。 語意接近程度通常會在搜尋中產生更好的結果。
2024-02-01 API 包含多語言模型,可支援 102 種語言的文字搜尋。 原始的僅限英文模型仍可供使用,但無法與相同搜尋索引中的新模型結合。 如果您使用僅限英文的模型向量化文字和影像,則這些向量與多語言文字和影像向量不相容。
這些 API 僅適用於特定地理區域。 請參閱區域可用性 (英文)。
背景移除 (僅限 v4.0 預覽版)
影像分析 4.0 (預覽版) 可讓您移除影像的背景。 這項功能可以輸出透明背景所偵測前景物件的影像,或輸出顯示所偵測前景物件的不透明度的灰階 Alpha 遮罩影像。
| 原始影像 | 已移除背景 | 透明圖層遮罩 |
|---|---|---|

|

|

|
服務限制
輸入需求
影像分析僅適用於符合下列需求的影像:
- 影像必須以 JPEG、PNG、GIF、BMP、WEBP、ICO、TIFF 或 MPO 格式呈現
- 影像的檔案大小必須小於 20 MB
- 影像的維度必須大於 50 x 50 像素,且小於 16,000 x 16,000 像素
提示
多模式內嵌的輸入需求不同,這些需求列於多模式內嵌中
語言支援
提供不同語言的不同影像分析功能。 請參閱語言支援頁面。
區域可用性
若要使用影像分析 API,您必須在支援的區域中建立 Azure AI 視覺資源。 下列區域提供影像分析功能:
| 區域 | 分析影像 (不包含 4.0 Captions) |
分析影像 (包含 4.0 Captions) |
產品辨識 | 多模式內嵌 | 背景移除 |
|---|---|---|---|---|---|
| 美國東部 | ✅ | ✅ | ✅ | ✅ | ✅ |
| 美國西部 | ✅ | ✅ | ✅ | ✅ | |
| 美國西部 2 | ✅ | ✅ | ✅ | ||
| 法國中部 | ✅ | ✅ | ✅ | ✅ | |
| 北歐 | ✅ | ✅ | ✅ | ✅ | |
| 西歐 | ✅ | ✅ | ✅ | ✅ | |
| 瑞典中部 | ✅ | ✅ | |||
| 瑞士北部 | ✅ | ✅ | |||
| 澳大利亞東部 | ✅ | ✅ | |||
| 東南亞 | ✅ | ✅ | ✅ | ✅ | |
| 東亞 | ✅ | ✅ | |||
| 南韓中部 | ✅ | ✅ | ✅ | ✅ | |
| 日本東部 | ✅ | ✅ |
資料隱私權和安全性
和所有 Azure AI 服務一樣,使用 Azure AI 視覺服務的開發人員應該要了解 Microsoft 對於客戶資料的政策。 請參閱 Microsoft 信任中心上的 Azure AI 服務頁面以深入了解。
下一步
遵循慣用開發語言的快速入門指南來開始使用影像分析:
意見反應
即將登場:在 2024 年,我們將逐步淘汰 GitHub 問題作為內容的意見反應機制,並將它取代為新的意見反應系統。 如需詳細資訊,請參閱:https://aka.ms/ContentUserFeedback。
提交並檢視相關的意見反應