快速入門:建立自訂關鍵字
參考文件 | 套件 (NuGet) | GitHub 上的其他範例
在本快速入門中,您將瞭解如何使用自訂關鍵字的基本概念。 關鍵字是一個單字或簡短的片語,讓您的產品可語音啟用。 您會在 Speech Studio 中建立關鍵字模型。 然後,將您在應用程式中搭配語音 SDK 使用的模型檔案匯出。
必要條件
- Azure 訂用帳戶。 您可以免費建立一個訂用帳戶。
- 在 Azure 入口網站上建立語音資源。
- 取得語音資源金鑰和區域。 部署語音資源之後,選取 [移至資源] 以檢視和管理索引鍵。
在 Speech Studio 中建立關鍵字
在您可以使用自訂關鍵字之前,您必須使用 Speech Studio 上的自訂關鍵字頁面建立關鍵字。 提供關鍵字之後,系統會產生可搭配.table語音 SDK 使用的檔案。
重要
自訂關鍵字模型和所產生的 .table 檔案只能在 Speech Studio 中建立。
您無法從 SDK 或使用 REST 呼叫建立自訂關鍵字。
前往 Speech Studio 並登入。 如果您沒有語音訂閱,請前往建立語音服務。
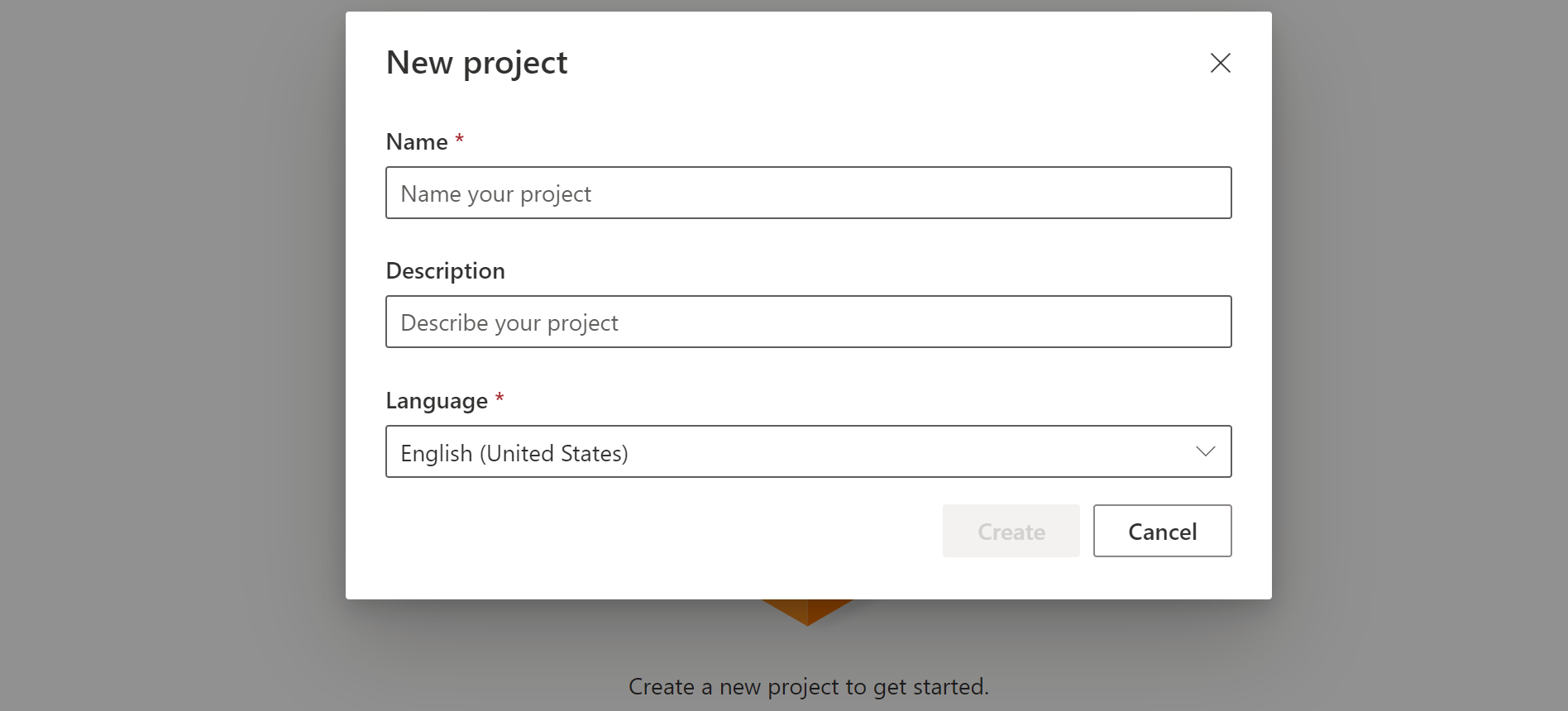
在自訂關鍵字頁面上,選取 [建立新專案]。
輸入自訂關鍵字專案的名稱、描述和語言。 您只能為每個專案選擇一個語言,而且目前僅支援英文 (美國) 和中文 (簡體中文)。
從清單中選取您的專案名稱。
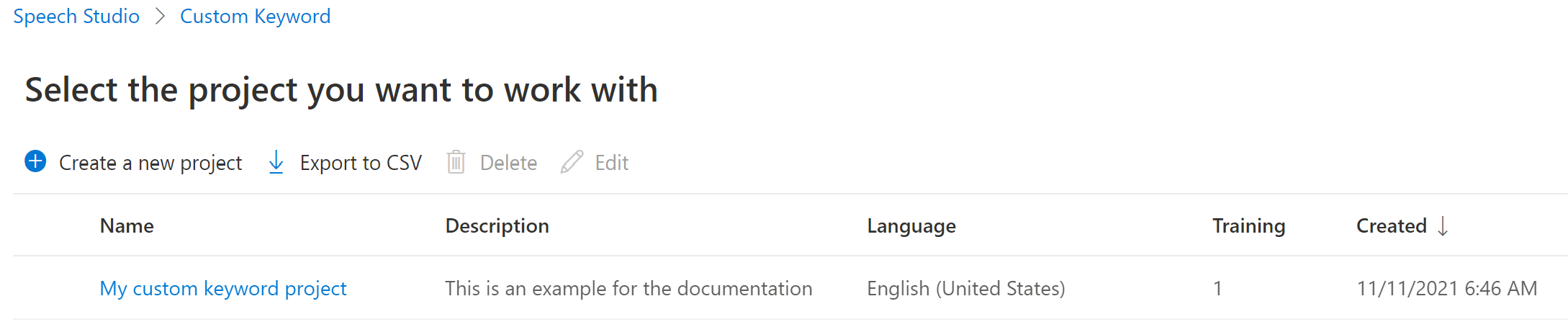
若要為虛擬助理建立自訂關鍵字,請選取 [建立新模型]。
輸入您選擇的模型 [名稱]、[描述] 和 [關鍵字],然後選取 [下一步]。 請參閱選擇有效關鍵字的 指導方針。
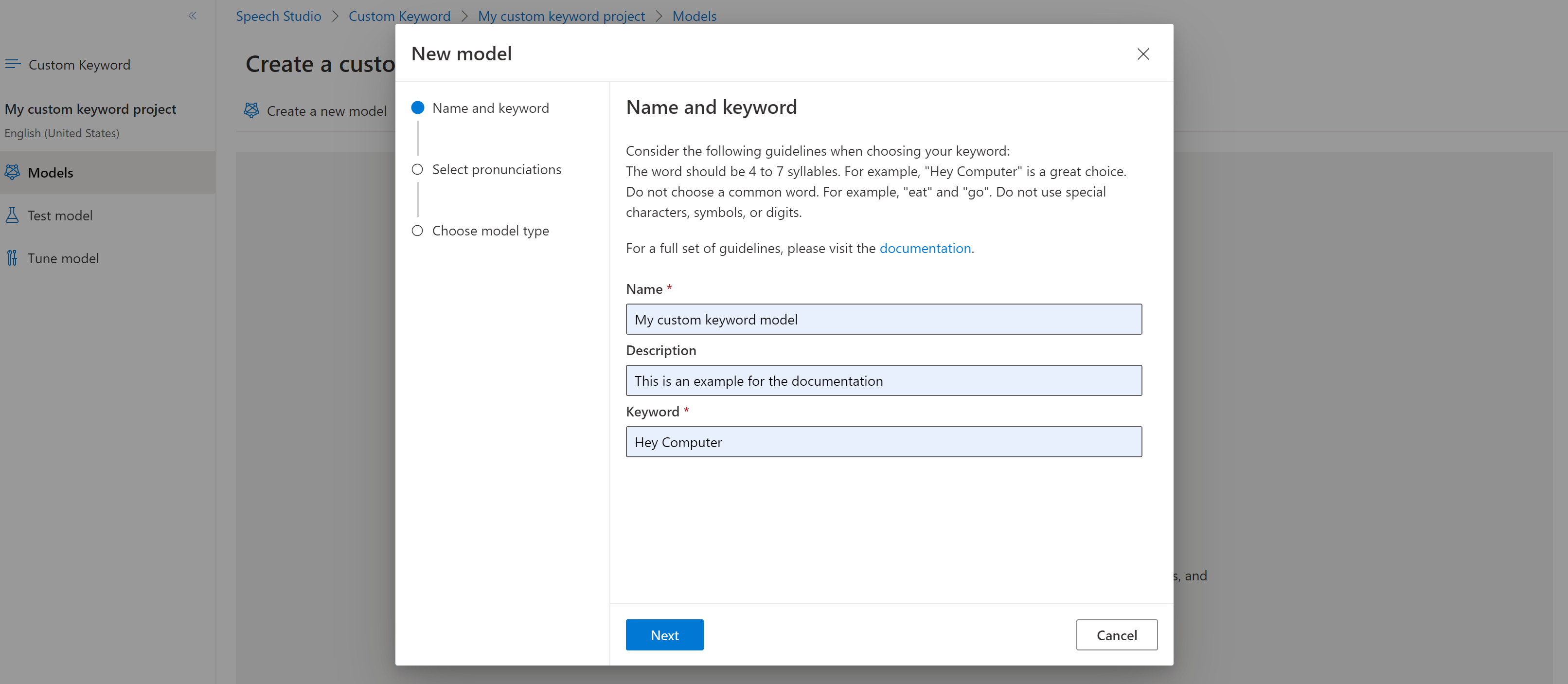
入口網站會建立關鍵字的候選發音。 選取 [播放] 按鈕,聆聽每個候選並移除任何不正確發音旁的勾選。選取所有您預期使用者會說出的關鍵字發音,然後選取 [下一步] 開始產生關鍵字模型。

選取模型類型,然後選取 [建立]。 您可以在關鍵字辨識區域支援檔中,查看支援進階模型類型的區域清單。
產生模型最多可能需要 30 分鐘。 當模型完成時,關鍵字清單會從 [正在處理] 變更為 [成功]。
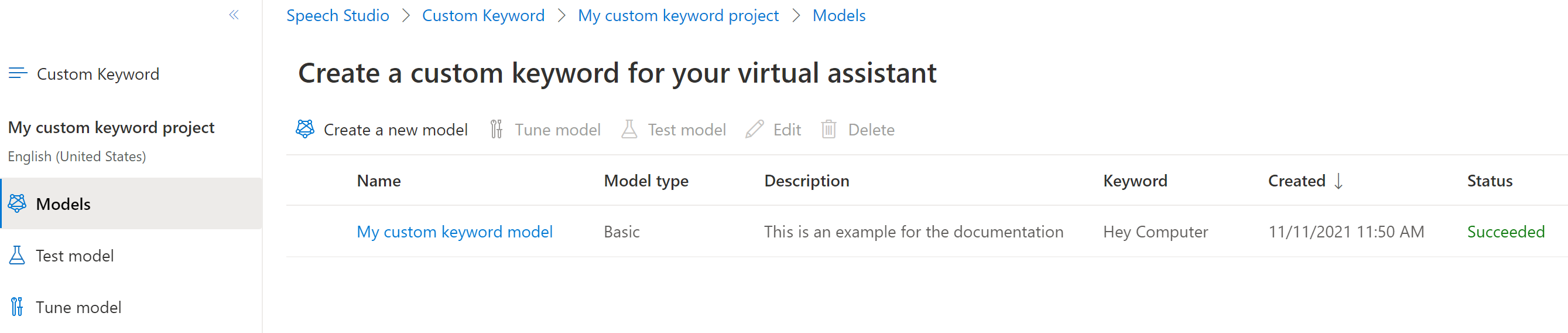
從左側的可摺疊功能表中,選取 [調整],以調整及下載您的模型。 下載的檔案是
.zip封存。 將封存解壓縮,您會看到副檔名為.table的檔案。 您可以使用.table檔案搭配 SDK,因此請務必記下其路徑。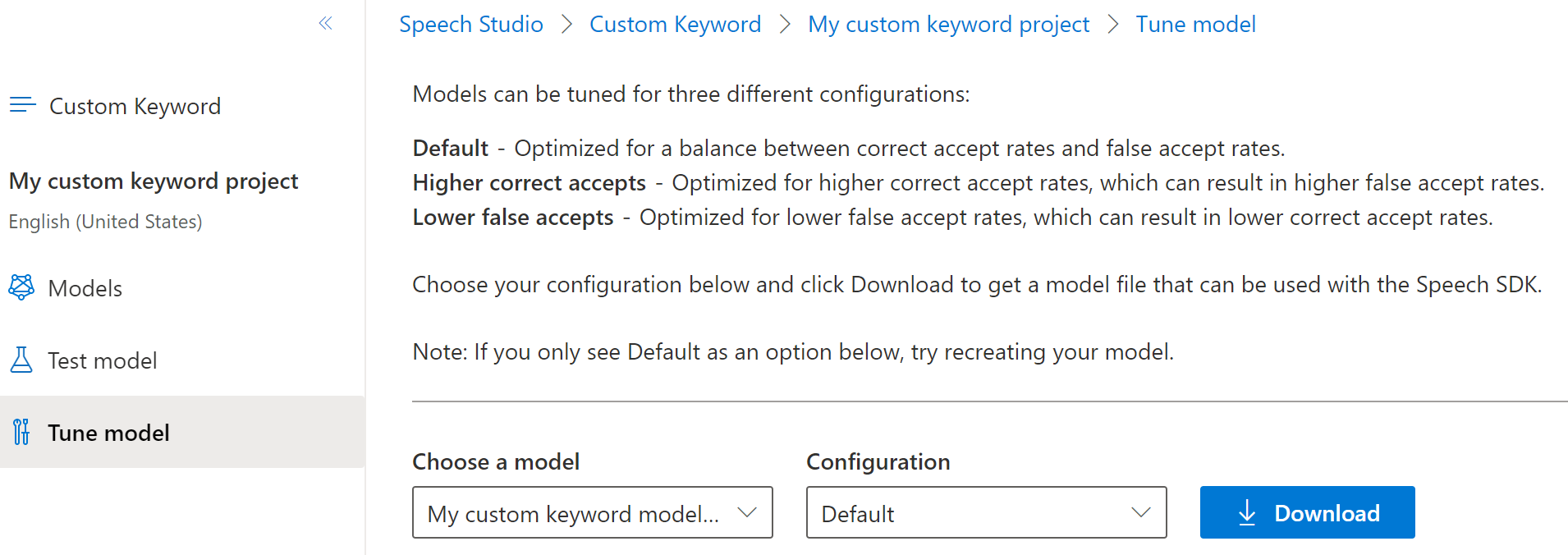
使用搭配語音 SDK 的關鍵字模型
首先,使用 FromFile() 靜態函式載入關鍵字模型檔案,此函式會傳回 KeywordRecognitionModel。 使用路徑前往您從 Speech Studio 下載的 .table 檔案。 此外,您可以使用預設的麥克風建立 AudioConfig,然後使用音訊設定來具現化新的 KeywordRecognizer。
using Microsoft.CognitiveServices.Speech;
using Microsoft.CognitiveServices.Speech.Audio;
var keywordModel = KeywordRecognitionModel.FromFile("your/path/to/Activate_device.table");
using var audioConfig = AudioConfig.FromDefaultMicrophoneInput();
using var keywordRecognizer = new KeywordRecognizer(audioConfig);
重要
如果您偏好透過 AudioConfig.fromStreamInput() 方法直接使用音訊樣本來測試關鍵詞模型,請確定您在第一個關鍵字之前使用至少 1.5 秒無聲的範例。 這旨在為關鍵字辨識引擎提供足夠的時間來初始化,並在偵測第一個關鍵字之前取得接聽狀態。
接下來,藉由傳遞您的模型物件,透過對 RecognizeOnceAsync() 的一次呼叫來執行關鍵字識別。 這個方法會啟動一個持續的關鍵字辨識工作階段,直到辨識出關鍵字為止。 因此,您通常會在多執行緒應用程式中使用此設計模式,或在可能會無限期等候喚醒字的使用案例中使用此設計模式。
KeywordRecognitionResult result = await keywordRecognizer.RecognizeOnceAsync(keywordModel);
注意
此處所示的範例使用本機關鍵詞辨識,因為它不需要驗證內容的 SpeechConfig 物件,也不會與後端連線。 不過,您可以使用直接後端連接來同時執行關鍵字辨識和驗證。
連續辨識
語音 SDK 中的其他類別可使用關鍵字辨識來支援連續辨識 (語音和意圖辨識)。 SDK 可讓您使用一般用於連續辨識的相同程式碼,並且能夠參考您關鍵字模型的 .table 檔案。
若為語音轉換文字,請依照辨識語音指南中所示的相同設計模式來設定連續辨識。 然後,以 recognizer.StartKeywordRecognitionAsync(KeywordRecognitionModel) 將呼叫取代為 recognizer.StartContinuousRecognitionAsync(),並傳遞您的 KeywordRecognitionModel 物件。 若要使用關鍵字辨識來停止連續辨識,請使用 recognizer.StopKeywordRecognitionAsync(),而不是 recognizer.StopContinuousRecognitionAsync()。
意圖辨識使用與 StartKeywordRecognitionAsync 和 StopKeywordRecognitionAsync 函式相同的模式。
參考文件 | 套件 (NuGet) | GitHub 上的其他範例
適用於 C++ 的語音 SDK 支援關鍵字辨識,但這裡尚未包含指南。 請選取另一種程式設計語言來開始使用並了解概念,或參閱本文開頭連結的 C++ 參考和範例。
author: eric-urban ms.service: azure-ai-speech ms.topic: include ms.date: 9/12/2024 ms.author: eur
- Azure 訂用帳戶。 您可以免費建立一個訂用帳戶。
- 在 Azure 入口網站上建立語音資源。
- 取得語音資源金鑰和區域。 部署語音資源之後,選取 [移至資源] 以檢視和管理索引鍵。
在 Speech Studio 中建立關鍵字
在您可以使用自訂關鍵字之前,您必須使用 Speech Studio 上的自訂關鍵字頁面建立關鍵字。 提供關鍵字之後,系統會產生可搭配.table語音 SDK 使用的檔案。
重要
自訂關鍵字模型和所產生的 .table 檔案只能在 Speech Studio 中建立。
您無法從 SDK 或使用 REST 呼叫建立自訂關鍵字。
前往 Speech Studio 並登入。 如果您沒有語音訂閱,請前往建立語音服務。
在自訂關鍵字頁面上,選取 [建立新專案]。
輸入自訂關鍵字專案的名稱、描述和語言。 您只能為每個專案選擇一個語言,而且目前僅支援英文 (美國) 和中文 (簡體中文)。
從清單中選取您的專案名稱。
若要為虛擬助理建立自訂關鍵字,請選取 [建立新模型]。
輸入您選擇的模型 [名稱]、[描述] 和 [關鍵字],然後選取 [下一步]。 請參閱選擇有效關鍵字的 指導方針。
入口網站會建立關鍵字的候選發音。 選取 [播放] 按鈕,聆聽每個候選並移除任何不正確發音旁的勾選。選取所有您預期使用者會說出的關鍵字發音,然後選取 [下一步] 開始產生關鍵字模型。
選取模型類型,然後選取 [建立]。 您可以在關鍵字辨識區域支援檔中,查看支援進階模型類型的區域清單。
產生模型最多可能需要 30 分鐘。 當模型完成時,關鍵字清單會從 [正在處理] 變更為 [成功]。
從左側的可摺疊功能表中,選取 [調整],以調整及下載您的模型。 下載的檔案是
.zip封存。 將封存解壓縮,您會看到副檔名為.table的檔案。 您可以使用.table檔案搭配 SDK,因此請務必記下其路徑。
使用搭配語音 SDK 的關鍵字模型
請參閱參考文件,以搭配 Go SDK 使用您的自訂關鍵字模型。
適用於 JAVA 的語音 SDK 支援關鍵字辨識,但這裡尚未包含指南。 請選取另一種程式設計語言來開始使用並了解概念,或參閱本文開頭連結的 JAVA 參考和範例。
參考文件 | 套件 (npm) | GitHub 上的其他範例 | 程式庫原始程式碼
適用於 JavaScript 的語音 SDK 不支援關鍵字辨識。 請選取另一種程式設計語言,或本文開頭連結的 JavaScript 參考和範例。
參考文件 | 套件 (下載) | GitHub 上的其他範例
在本快速入門中,您將瞭解如何使用自訂關鍵字的基本概念。 關鍵字是一個單字或簡短的片語,讓您的產品可語音啟用。 您會在 Speech Studio 中建立關鍵字模型。 然後,將您在應用程式中搭配語音 SDK 使用的模型檔案匯出。
必要條件
- Azure 訂用帳戶。 您可以免費建立一個訂用帳戶。
- 在 Azure 入口網站上建立語音資源。
- 取得語音資源金鑰和區域。 部署語音資源之後,選取 [移至資源] 以檢視和管理索引鍵。
在 Speech Studio 中建立關鍵字
在您可以使用自訂關鍵字之前,您必須使用 Speech Studio 上的自訂關鍵字頁面建立關鍵字。 提供關鍵字之後,系統會產生可搭配.table語音 SDK 使用的檔案。
重要
自訂關鍵字模型和所產生的 .table 檔案只能在 Speech Studio 中建立。
您無法從 SDK 或使用 REST 呼叫建立自訂關鍵字。
前往 Speech Studio 並登入。 如果您沒有語音訂閱,請前往建立語音服務。
在自訂關鍵字頁面上,選取 [建立新專案]。
輸入自訂關鍵字專案的名稱、描述和語言。 您只能為每個專案選擇一個語言,而且目前僅支援英文 (美國) 和中文 (簡體中文)。
從清單中選取您的專案名稱。
若要為虛擬助理建立自訂關鍵字,請選取 [建立新模型]。
輸入您選擇的模型 [名稱]、[描述] 和 [關鍵字],然後選取 [下一步]。 請參閱選擇有效關鍵字的 指導方針。
入口網站會建立關鍵字的候選發音。 選取 [播放] 按鈕,聆聽每個候選並移除任何不正確發音旁的勾選。選取所有您預期使用者會說出的關鍵字發音,然後選取 [下一步] 開始產生關鍵字模型。
選取模型類型,然後選取 [建立]。 您可以在關鍵字辨識區域支援檔中,查看支援進階模型類型的區域清單。
產生模型最多可能需要 30 分鐘。 當模型完成時,關鍵字清單會從 [正在處理] 變更為 [成功]。
從左側的可摺疊功能表中,選取 [調整],以調整及下載您的模型。 下載的檔案是
.zip封存。 將封存解壓縮,您會看到副檔名為.table的檔案。 您可以使用.table檔案搭配 SDK,因此請務必記下其路徑。
使用搭配語音 SDK 的關鍵字模型
欲搭配 Objective C SDK 使用您的自訂關鍵字模型,請參閱 GitHub 上的範例。
參考文件 | 套件 (下載) | GitHub 上的其他範例
在本快速入門中,您將瞭解如何使用自訂關鍵字的基本概念。 關鍵字是一個單字或簡短的片語,讓您的產品可語音啟用。 您會在 Speech Studio 中建立關鍵字模型。 然後,將您在應用程式中搭配語音 SDK 使用的模型檔案匯出。
必要條件
- Azure 訂用帳戶。 您可以免費建立一個訂用帳戶。
- 在 Azure 入口網站上建立語音資源。
- 取得語音資源金鑰和區域。 部署語音資源之後,選取 [移至資源] 以檢視和管理索引鍵。
在 Speech Studio 中建立關鍵字
在您可以使用自訂關鍵字之前,您必須使用 Speech Studio 上的自訂關鍵字頁面建立關鍵字。 提供關鍵字之後,系統會產生可搭配.table語音 SDK 使用的檔案。
重要
自訂關鍵字模型和所產生的 .table 檔案只能在 Speech Studio 中建立。
您無法從 SDK 或使用 REST 呼叫建立自訂關鍵字。
前往 Speech Studio 並登入。 如果您沒有語音訂閱,請前往建立語音服務。
在自訂關鍵字頁面上,選取 [建立新專案]。
輸入自訂關鍵字專案的名稱、描述和語言。 您只能為每個專案選擇一個語言,而且目前僅支援英文 (美國) 和中文 (簡體中文)。
從清單中選取您的專案名稱。
若要為虛擬助理建立自訂關鍵字,請選取 [建立新模型]。
輸入您選擇的模型 [名稱]、[描述] 和 [關鍵字],然後選取 [下一步]。 請參閱選擇有效關鍵字的 指導方針。
入口網站會建立關鍵字的候選發音。 選取 [播放] 按鈕,聆聽每個候選並移除任何不正確發音旁的勾選。選取所有您預期使用者會說出的關鍵字發音,然後選取 [下一步] 開始產生關鍵字模型。
選取模型類型,然後選取 [建立]。 您可以在關鍵字辨識區域支援檔中,查看支援進階模型類型的區域清單。
產生模型最多可能需要 30 分鐘。 當模型完成時,關鍵字清單會從 [正在處理] 變更為 [成功]。
從左側的可摺疊功能表中,選取 [調整],以調整及下載您的模型。 下載的檔案是
.zip封存。 將封存解壓縮,您會看到副檔名為.table的檔案。 您可以使用.table檔案搭配 SDK,因此請務必記下其路徑。
使用搭配語音 SDK 的關鍵字模型
欲搭配 Objective C SDK 使用您的自訂關鍵字模型,請參閱 GitHub 上的範例。 雖然我們目前沒有同位的 Swift 樣本,但概念很類似。
注意
如果您要在iOS上的 Swift 應用程式中使用關鍵詞辨識,請注意,在Speech Studio中建立的新關鍵詞模型需要使用來自的語音 SDK xcframework 套件組合 https://aka.ms/csspeech/iosbinaryembedded 或專案中的 MicrosoftCognitiveServicesSpeechEmbedded-iOS Pod。
參考文件 | 套件 (PyPi) | GitHub 上的其他範例
在本快速入門中,您將瞭解如何使用自訂關鍵字的基本概念。 關鍵字是一個單字或簡短的片語,讓您的產品可語音啟用。 您會在 Speech Studio 中建立關鍵字模型。 然後,將您在應用程式中搭配語音 SDK 使用的模型檔案匯出。
必要條件
- Azure 訂用帳戶。 您可以免費建立一個訂用帳戶。
- 在 Azure 入口網站上建立語音資源。
- 取得語音資源金鑰和區域。 部署語音資源之後,選取 [移至資源] 以檢視和管理索引鍵。
在 Speech Studio 中建立關鍵字
在您可以使用自訂關鍵字之前,您必須使用 Speech Studio 上的自訂關鍵字頁面建立關鍵字。 提供關鍵字之後,系統會產生可搭配.table語音 SDK 使用的檔案。
重要
自訂關鍵字模型和所產生的 .table 檔案只能在 Speech Studio 中建立。
您無法從 SDK 或使用 REST 呼叫建立自訂關鍵字。
前往 Speech Studio 並登入。 如果您沒有語音訂閱,請前往建立語音服務。
在自訂關鍵字頁面上,選取 [建立新專案]。
輸入自訂關鍵字專案的名稱、描述和語言。 您只能為每個專案選擇一個語言,而且目前僅支援英文 (美國) 和中文 (簡體中文)。
從清單中選取您的專案名稱。
若要為虛擬助理建立自訂關鍵字,請選取 [建立新模型]。
輸入您選擇的模型 [名稱]、[描述] 和 [關鍵字],然後選取 [下一步]。 請參閱選擇有效關鍵字的 指導方針。
入口網站會建立關鍵字的候選發音。 選取 [播放] 按鈕,聆聽每個候選並移除任何不正確發音旁的勾選。選取所有您預期使用者會說出的關鍵字發音,然後選取 [下一步] 開始產生關鍵字模型。
選取模型類型,然後選取 [建立]。 您可以在關鍵字辨識區域支援檔中,查看支援進階模型類型的區域清單。
產生模型最多可能需要 30 分鐘。 當模型完成時,關鍵字清單會從 [正在處理] 變更為 [成功]。
從左側的可摺疊功能表中,選取 [調整],以調整及下載您的模型。 下載的檔案是
.zip封存。 將封存解壓縮,您會看到副檔名為.table的檔案。 您可以使用.table檔案搭配 SDK,因此請務必記下其路徑。
使用搭配語音 SDK 的關鍵字模型
欲搭配 Python SDK 使用您的自訂關鍵字模型,請參閱 GitHub 上的範例。
語音轉換文字 REST API 參考 | 適用於簡短音訊的語音轉換文字 REST API 參考 | GitHub 上的其他範例
語音轉換文字 REST API 不支援關鍵字辨識。 請選取另一種程式設計語言,或本文開頭連結的參考和範例。
語音 CLI 支援關鍵字辨識,但這裡尚未包含指南。 請選取另一種程式設計語言,以開始使用並了解概念。