重要
LUIS 將於 2025 年 10 月 1 日淘汰。 自 2023 年 4 月 1 日起,您無法建立新的 LUIS 資源。 建議移轉 LUIS 應用程式至交談語言理解,以享有產品持續支援和多語言功能的優點。
交談語言理解 (CLU) 適用於語音 SDK 版本 1.25 或更新的 C# 和 C++。 請參閱使用語音 SDK 和 CLU 辨識意圖的快速入門。
參考文件 | 套件 (NuGet) | GitHub 上的其他範例
在本快速入門中,您將使用語音 SDK 和 Language Understanding (LUIS)服務來辨識從麥克風擷取之音訊資料的意圖。 具體而言,您將使用語音 SDK 來擷取語音,並使用 LUIS 中預先建置的網域來識別家庭自動化的意圖,例如開燈和關燈。
必要條件
建立意圖辨識的 LUIS 應用程式
若要完成意圖辨識快速入門,您必須使用 LUIS 預覽入口網站建立 LUIS 帳戶和專案。 本快速入門需要區域中有意圖辨識的 LUIS 訂閱。 「不需要」語音服務訂用帳戶。
您的首要工作,是使用 LUIS 預覽入口網站建立 LUIS 帳戶和應用程式。 您所建立的 LUIS 應用程式將使用預先建置的網域進行家庭自動化,以提供意圖、實體和範例表達。 完成之後,您會擁有在雲端中執行的 LUIS 端點,供您使用語音 SDK 進行呼叫。
請依照下列指示建立 LUIS 應用程式:
完成作業後,您將需要四項資訊:
- 將語音預備切換為開啟以重新發佈
- 您的 LUIS 主要金鑰
- 您的 LUIS 位置
- 您的 LUIS 應用程式識別碼
您可以在此處透過 LUIS 預覽入口網站找到這些資訊:
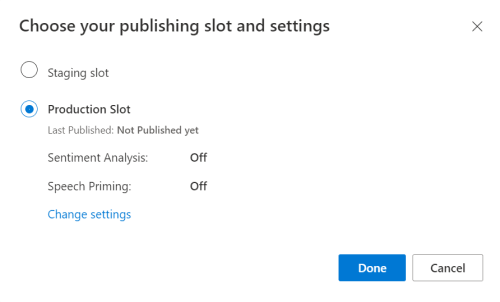
從 LUIS 預覽入口網站中選取您的應用程式,然後選取 [發佈] 按鈕。
選取 [生產] 位置,如果您使用
en-US,請選取 [變更設定],然後將 [語音預備] 選項切換至 [開啟] 位置。 然後,選取 [發佈] 按鈕。重要
強烈建議您使用語音預備,因為其可以改善語音辨識的精確度。
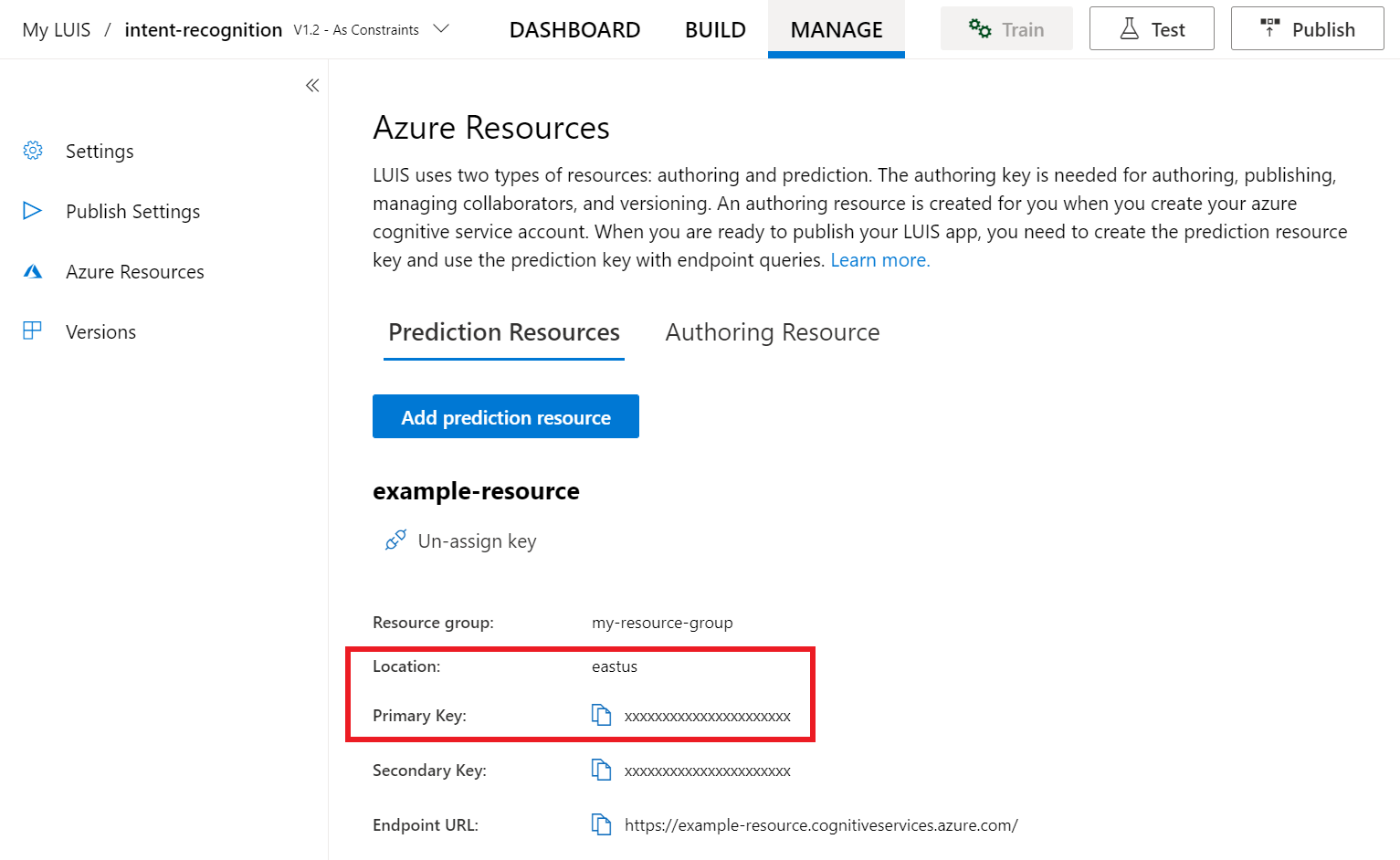
在 LUIS 預覽入口網站中選取 [管理],然後選取 [Azure 資源]。 在此頁面上,您可以找到您 LUIS 預測資源的 LUIS 金鑰和位置 (有時也稱為「區域」)。
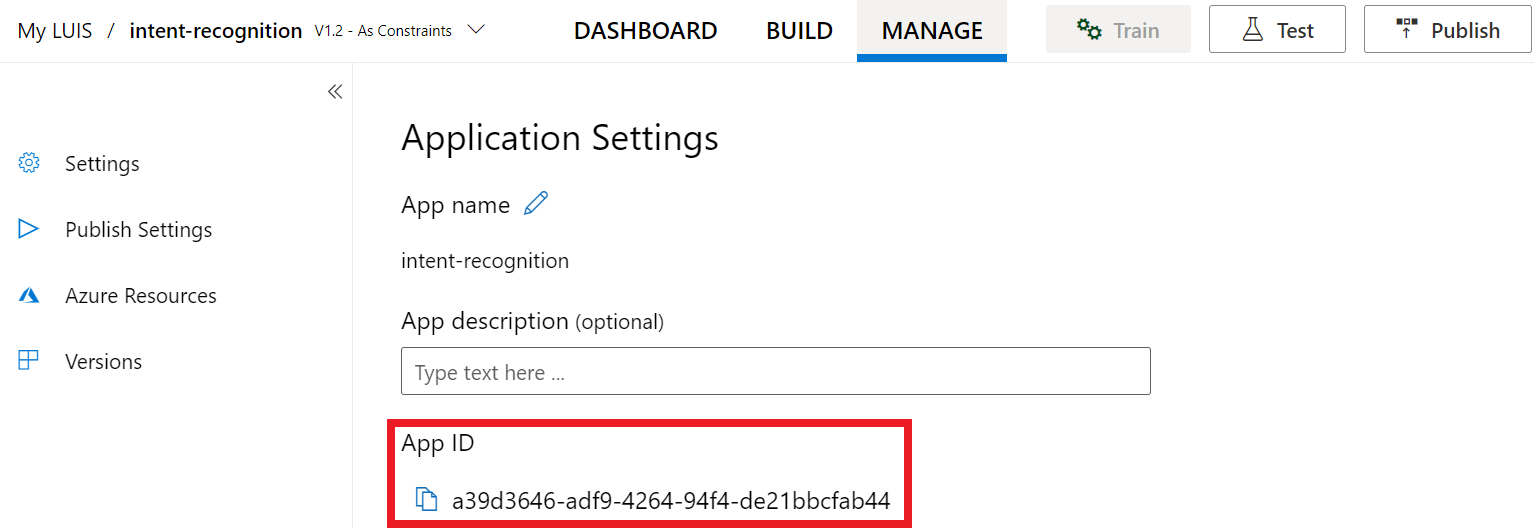
取得金鑰和位置之後,您將需要應用程式識別碼。 選取設定。 您可在此頁面取得您的應用程式識別碼。
在 Visual Studio 中開啟您的專案
然後,在 Visual Studio 中開啟專案。
- 啟動 Visual Studio 2019。
- 載入您的專案,並開啟
Program.cs。
從重複使用程式碼開始著手
我們將新增程式碼,作為專案的基本架構。 請注意,您已建立名為 RecognizeIntentAsync() 的非同步方法。
using System;
using System.Threading.Tasks;
using Microsoft.CognitiveServices.Speech;
using Microsoft.CognitiveServices.Speech.Intent;
namespace helloworld
{
class Program
{
public static async Task RecognizeIntentAsync()
{
}
static async Task Main()
{
await RecognizeIntentAsync();
Console.WriteLine("Please press <Return> to continue.");
Console.ReadLine();
}
}
}
建立語音設定
您必須先建立使用 LUIS 預測資源金鑰和位置的組態,才能夠初始化 IntentRecognizer 物件。
重要
您的入門金鑰和撰寫金鑰將無法使用。 您必須使用您先前建立的預測金鑰和位置。 如需詳細資訊,請參閱建立意圖辨識的 LUIS 應用程式。
在 RecognizeIntentAsync() 方法中插入此程式碼。 請務必更新這些值:
- 將
"YourLanguageUnderstandingSubscriptionKey"取代為您的 LUIS 預測金鑰。 - 將
"YourLanguageUnderstandingServiceRegion"取代為您的 LUIS 位置。 使用區域中的 [區域識別碼]。
提示
如果您在尋找這些值時需要協助,請參閱建立意圖辨識的 LUIS 應用程式。
重要
完成時,請記得從程式碼中移除金鑰,且不要公開張貼金鑰。 在生產環境中,請使用安全的方式來儲存和存取您的認證,例如 Azure Key Vault。 如需詳細資訊,請參閱 Azure AI 服務安全性一文。
var config = SpeechConfig.FromSubscription(
"YourLanguageUnderstandingSubscriptionKey",
"YourLanguageUnderstandingServiceRegion");
此範例會使用 FromSubscription() 方法來建置 SpeechConfig。 如需可用方法的完整清單,請參閱 SpeechConfig 類別 \(英文\)。
語音 SDK 預設為使用 en-us 當作語言來辨識,如需有關選擇來源語言的詳細資訊,請參閱如何辨識語音。
初始化 IntentRecognizer
現在,我們將建立一個 IntentRecognizer。 這個物件是在 using 陳述式內建立的,可確保適當釋放未受控資源。 將此程式碼插入您的語音設定下方的 RecognizeIntentAsync() 方法中。
// Creates an intent recognizer using microphone as audio input.
using (var recognizer = new IntentRecognizer(config))
{
}
新增 LanguageUnderstandingModel 和意圖
您必須將 LanguageUnderstandingModel 與意圖辨識器建立關聯,並新增您要辨識的意圖。 我們將使用預先建置之網域中的意圖來進行家庭自動化。 在上一節的 using 陳述式中插入此程式碼。 請務必將 "YourLanguageUnderstandingAppId" 取代為您的 LUIS 應用程式識別碼。
提示
如果您在尋找此值時需要協助,請參閱建立意圖辨識的 LUIS 應用程式。
// Creates a Language Understanding model using the app id, and adds specific intents from your model
var model = LanguageUnderstandingModel.FromAppId("YourLanguageUnderstandingAppId");
recognizer.AddIntent(model, "YourLanguageUnderstandingIntentName1", "id1");
recognizer.AddIntent(model, "YourLanguageUnderstandingIntentName2", "id2");
recognizer.AddIntent(model, "YourLanguageUnderstandingIntentName3", "any-IntentId-here");
這個範例會使用 AddIntent() 函式來個別新增意圖。 如果要從模型新增所有意圖,請使用 AddAllIntents(model) 並傳遞模型。
辨識意圖
從 IntentRecognizer 物件,您將呼叫 RecognizeOnceAsync() 方法。 此方法可讓語音服務知道您要傳送單一片語以進行辨識,且一旦識別出該片語即停止辨識語音。
在 using 陳述式中,將下列程式碼新增至您的模型下方。
// Starts recognizing.
Console.WriteLine("Say something...");
// Starts intent recognition, and returns after a single utterance is recognized. The end of a
// single utterance is determined by listening for silence at the end or until a maximum of about 30
// seconds of audio is processed. The task returns the recognition text as result.
// Note: Since RecognizeOnceAsync() returns only a single utterance, it is suitable only for single
// shot recognition like command or query.
// For long-running multi-utterance recognition, use StartContinuousRecognitionAsync() instead.
var result = await recognizer.RecognizeOnceAsync();
顯示辨識結果 (或錯誤)
當語音服務傳回辨識結果時,建議您對其執行一些動作。 為了簡單起見,我們將結果列印到主控台。
在 using 陳述式中的 RecognizeOnceAsync() 下方,新增此程式碼:
// Checks result.
switch (result.Reason)
{
case ResultReason.RecognizedIntent:
Console.WriteLine($"RECOGNIZED: Text={result.Text}");
Console.WriteLine($" Intent Id: {result.IntentId}.");
var json = result.Properties.GetProperty(PropertyId.LanguageUnderstandingServiceResponse_JsonResult);
Console.WriteLine($" Language Understanding JSON: {json}.");
break;
case ResultReason.RecognizedSpeech:
Console.WriteLine($"RECOGNIZED: Text={result.Text}");
Console.WriteLine($" Intent not recognized.");
break;
case ResultReason.NoMatch:
Console.WriteLine($"NOMATCH: Speech could not be recognized.");
break;
case ResultReason.Canceled:
var cancellation = CancellationDetails.FromResult(result);
Console.WriteLine($"CANCELED: Reason={cancellation.Reason}");
if (cancellation.Reason == CancellationReason.Error)
{
Console.WriteLine($"CANCELED: ErrorCode={cancellation.ErrorCode}");
Console.WriteLine($"CANCELED: ErrorDetails={cancellation.ErrorDetails}");
Console.WriteLine($"CANCELED: Did you update the subscription info?");
}
break;
}
檢查您的程式碼
此時,您的程式碼應會如下所示:
注意
我們已在此版本中新增一些註解。
//
// Copyright (c) Microsoft. All rights reserved.
// Licensed under the MIT license. See LICENSE.md file in the project root for full license information.
//
// <skeleton_1>
using System;
using System.Threading.Tasks;
using Microsoft.CognitiveServices.Speech;
using Microsoft.CognitiveServices.Speech.Intent;
namespace helloworld
{
class Program
{
public static async Task RecognizeIntentAsync()
{
// </skeleton_1>
// Creates an instance of a speech config with specified subscription key
// and service region. Note that in contrast to other services supported by
// the Cognitive Services Speech SDK, the Language Understanding service
// requires a specific subscription key from https://www.luis.ai/.
// The Language Understanding service calls the required key 'endpoint key'.
// Once you've obtained it, replace with below with your own Language Understanding subscription key
// and service region (e.g., "westus").
// The default language is "en-us".
// <create_speech_configuration>
var config = SpeechConfig.FromSubscription(
"YourLanguageUnderstandingSubscriptionKey",
"YourLanguageUnderstandingServiceRegion");
// </create_speech_configuration>
// <create_intent_recognizer_1>
// Creates an intent recognizer using microphone as audio input.
using (var recognizer = new IntentRecognizer(config))
{
// </create_intent_recognizer_1>
// <add_intents>
// Creates a Language Understanding model using the app id, and adds specific intents from your model
var model = LanguageUnderstandingModel.FromAppId("YourLanguageUnderstandingAppId");
recognizer.AddIntent(model, "YourLanguageUnderstandingIntentName1", "id1");
recognizer.AddIntent(model, "YourLanguageUnderstandingIntentName2", "id2");
recognizer.AddIntent(model, "YourLanguageUnderstandingIntentName3", "any-IntentId-here");
// </add_intents>
// To add all of the possible intents from a LUIS model to the recognizer, uncomment the line below:
// recognizer.AddAllIntents(model);
// <recognize_intent>
// Starts recognizing.
Console.WriteLine("Say something...");
// Starts intent recognition, and returns after a single utterance is recognized. The end of a
// single utterance is determined by listening for silence at the end or until a maximum of about 30
// seconds of audio is processed. The task returns the recognition text as result.
// Note: Since RecognizeOnceAsync() returns only a single utterance, it is suitable only for single
// shot recognition like command or query.
// For long-running multi-utterance recognition, use StartContinuousRecognitionAsync() instead.
var result = await recognizer.RecognizeOnceAsync();
// </recognize_intent>
// <print_results>
// Checks result.
switch (result.Reason)
{
case ResultReason.RecognizedIntent:
Console.WriteLine($"RECOGNIZED: Text={result.Text}");
Console.WriteLine($" Intent Id: {result.IntentId}.");
var json = result.Properties.GetProperty(PropertyId.LanguageUnderstandingServiceResponse_JsonResult);
Console.WriteLine($" Language Understanding JSON: {json}.");
break;
case ResultReason.RecognizedSpeech:
Console.WriteLine($"RECOGNIZED: Text={result.Text}");
Console.WriteLine($" Intent not recognized.");
break;
case ResultReason.NoMatch:
Console.WriteLine($"NOMATCH: Speech could not be recognized.");
break;
case ResultReason.Canceled:
var cancellation = CancellationDetails.FromResult(result);
Console.WriteLine($"CANCELED: Reason={cancellation.Reason}");
if (cancellation.Reason == CancellationReason.Error)
{
Console.WriteLine($"CANCELED: ErrorCode={cancellation.ErrorCode}");
Console.WriteLine($"CANCELED: ErrorDetails={cancellation.ErrorDetails}");
Console.WriteLine($"CANCELED: Did you update the subscription info?");
}
break;
}
// </print_results>
// <create_intent_recognizer_2>
}
// </create_intent_recognizer_2>
// <skeleton_2>
}
static async Task Main()
{
await RecognizeIntentAsync();
Console.WriteLine("Please press <Return> to continue.");
Console.ReadLine();
}
}
}
// </skeleton_2>
建置並執行您的應用程式
現在您已準備好使用語音服務來建立應用程式,並測試我們的語音辨識。
- 編譯程式碼 - 從 Visual Studio 的功能表列中,選擇 [建置]>[建置解決方案]。
- 啟動應用程式 - 從功能表列中,選擇 [偵錯]>[開始偵錯],或按 F5。
- 開始辨識 - 它會提示您說英文片語。 您的語音會傳送至語音服務、轉譯為文字,並在主控台中轉譯。
參考文件 | 套件 (NuGet) | GitHub 上的其他範例
在本快速入門中,您將使用語音 SDK 和 Language Understanding (LUIS)服務來辨識從麥克風擷取之音訊資料的意圖。 具體而言,您將使用語音 SDK 來擷取語音,並使用 LUIS 中預先建置的網域來識別家庭自動化的意圖,例如開燈和關燈。
必要條件
建立意圖辨識的 LUIS 應用程式
若要完成意圖辨識快速入門,您必須使用 LUIS 預覽入口網站建立 LUIS 帳戶和專案。 本快速入門需要區域中有意圖辨識的 LUIS 訂閱。 「不需要」語音服務訂用帳戶。
您的首要工作,是使用 LUIS 預覽入口網站建立 LUIS 帳戶和應用程式。 您所建立的 LUIS 應用程式將使用預先建置的網域進行家庭自動化,以提供意圖、實體和範例表達。 完成之後,您會擁有在雲端中執行的 LUIS 端點,供您使用語音 SDK 進行呼叫。
請依照下列指示建立 LUIS 應用程式:
完成作業後,您將需要四項資訊:
- 將語音預備切換為開啟以重新發佈
- 您的 LUIS 主要金鑰
- 您的 LUIS 位置
- 您的 LUIS 應用程式識別碼
您可以在此處透過 LUIS 預覽入口網站找到這些資訊:
從 LUIS 預覽入口網站中選取您的應用程式,然後選取 [發佈] 按鈕。
選取 [生產] 位置,如果您使用
en-US,請選取 [變更設定],然後將 [語音預備] 選項切換至 [開啟] 位置。 然後,選取 [發佈] 按鈕。重要
強烈建議您使用語音預備,因為其可以改善語音辨識的精確度。
在 LUIS 預覽入口網站中選取 [管理],然後選取 [Azure 資源]。 在此頁面上,您可以找到您 LUIS 預測資源的 LUIS 金鑰和位置 (有時也稱為「區域」)。
取得金鑰和位置之後,您將需要應用程式識別碼。 選取設定。 您可在此頁面取得您的應用程式識別碼。
在 Visual Studio 中開啟您的專案
然後,在 Visual Studio 中開啟專案。
- 啟動 Visual Studio 2019。
- 載入您的專案,並開啟
helloworld.cpp。
從重複使用程式碼開始著手
我們將新增程式碼,作為專案的基本架構。 請注意,您已建立名為 recognizeIntent() 的非同步方法。
#include "stdafx.h"
#include <iostream>
#include <speechapi_cxx.h>
using namespace std;
using namespace Microsoft::CognitiveServices::Speech;
using namespace Microsoft::CognitiveServices::Speech::Intent;
void recognizeIntent()
{
}
int wmain()
{
try
{
recognizeIntent();
}
catch (exception e)
{
cout << e.what();
}
cout << "Please press a key to continue.\n";
cin.get();
return 0;
}
建立語音設定
您必須先建立使用 LUIS 預測資源金鑰和位置的組態,才能夠初始化 IntentRecognizer 物件。
重要
您的入門金鑰和撰寫金鑰將無法使用。 您必須使用您先前建立的預測金鑰和位置。 如需詳細資訊,請參閱建立意圖辨識的 LUIS 應用程式。
在 recognizeIntent() 方法中插入此程式碼。 請務必更新這些值:
- 將
"YourLanguageUnderstandingSubscriptionKey"取代為您的 LUIS 預測金鑰。 - 將
"YourLanguageUnderstandingServiceRegion"取代為您的 LUIS 位置。 使用區域中的 [區域識別碼]。
提示
如果您在尋找這些值時需要協助,請參閱建立意圖辨識的 LUIS 應用程式。
重要
完成時,請記得從程式碼中移除金鑰,且不要公開張貼金鑰。 在生產環境中,請使用安全的方式來儲存和存取您的認證,例如 Azure Key Vault。 如需詳細資訊,請參閱 Azure AI 服務安全性一文。
auto config = SpeechConfig::FromSubscription(
"YourLanguageUnderstandingSubscriptionKey",
"YourLanguageUnderstandingServiceRegion");
此範例會使用 FromSubscription() 方法來建置 SpeechConfig。 如需可用方法的完整清單,請參閱 SpeechConfig 類別 \(英文\)。
語音 SDK 預設為使用 en-us 當作語言來辨識,如需有關選擇來源語言的詳細資訊,請參閱如何辨識語音。
初始化 IntentRecognizer
現在,我們將建立一個 IntentRecognizer。 將此程式碼插入您的語音設定下方的 recognizeIntent() 方法中。
// Creates an intent recognizer using microphone as audio input.
auto recognizer = IntentRecognizer::FromConfig(config);
新增 LanguageUnderstandingModel 和意圖
您必須將 LanguageUnderstandingModel 與意圖辨識器建立關聯,並新增您要辨識的意圖。 我們將使用預先建置之網域中的意圖來進行家庭自動化。
在 IntentRecognizer 下方插入此程式碼。 請務必將 "YourLanguageUnderstandingAppId" 取代為您的 LUIS 應用程式識別碼。
提示
如果您在尋找此值時需要協助,請參閱建立意圖辨識的 LUIS 應用程式。
// Creates a Language Understanding model using the app id, and adds specific intents from your model
auto model = LanguageUnderstandingModel::FromAppId("YourLanguageUnderstandingAppId");
recognizer->AddIntent(model, "YourLanguageUnderstandingIntentName1", "id1");
recognizer->AddIntent(model, "YourLanguageUnderstandingIntentName2", "id2");
recognizer->AddIntent(model, "YourLanguageUnderstandingIntentName3", "any-IntentId-here");
這個範例會使用 AddIntent() 函式來個別新增意圖。 如果要從模型新增所有意圖,請使用 AddAllIntents(model) 並傳遞模型。
辨識意圖
從 IntentRecognizer 物件,您將呼叫 RecognizeOnceAsync() 方法。 此方法可讓語音服務知道您要傳送單一片語以進行辨識,且一旦識別出該片語即停止辨識語音。 為了簡單起見,我們將等待傳回的結果完成。
在您的模型下插入此程式碼:
cout << "Say something...\n";
// Starts intent recognition, and returns after a single utterance is recognized. The end of a
// single utterance is determined by listening for silence at the end or until a maximum of about 30
// seconds of audio is processed. The task returns the recognition text as result.
// Note: Since RecognizeOnceAsync() returns only a single utterance, it is suitable only for single
// shot recognition like command or query.
// For long-running multi-utterance recognition, use StartContinuousRecognitionAsync() instead.
auto result = recognizer->RecognizeOnceAsync().get();
顯示辨識結果 (或錯誤)
當語音服務傳回辨識結果時,建議您對其執行一些動作。 為了簡單起見,我們將結果列印到主控台。
在 auto result = recognizer->RecognizeOnceAsync().get(); 下方插入此程式碼:
// Checks result.
if (result->Reason == ResultReason::RecognizedIntent)
{
cout << "RECOGNIZED: Text=" << result->Text << std::endl;
cout << " Intent Id: " << result->IntentId << std::endl;
cout << " Intent Service JSON: " << result->Properties.GetProperty(PropertyId::LanguageUnderstandingServiceResponse_JsonResult) << std::endl;
}
else if (result->Reason == ResultReason::RecognizedSpeech)
{
cout << "RECOGNIZED: Text=" << result->Text << " (intent could not be recognized)" << std::endl;
}
else if (result->Reason == ResultReason::NoMatch)
{
cout << "NOMATCH: Speech could not be recognized." << std::endl;
}
else if (result->Reason == ResultReason::Canceled)
{
auto cancellation = CancellationDetails::FromResult(result);
cout << "CANCELED: Reason=" << (int)cancellation->Reason << std::endl;
if (cancellation->Reason == CancellationReason::Error)
{
cout << "CANCELED: ErrorCode=" << (int)cancellation->ErrorCode << std::endl;
cout << "CANCELED: ErrorDetails=" << cancellation->ErrorDetails << std::endl;
cout << "CANCELED: Did you update the subscription info?" << std::endl;
}
}
檢查您的程式碼
此時,您的程式碼應會如下所示:
注意
我們已在此版本中新增一些註解。
//
// Copyright (c) Microsoft. All rights reserved.
// Licensed under the MIT license. See LICENSE.md file in the project root for full license information.
//
// <skeleton_1>
#include "stdafx.h"
#include <iostream>
#include <speechapi_cxx.h>
using namespace std;
using namespace Microsoft::CognitiveServices::Speech;
using namespace Microsoft::CognitiveServices::Speech::Intent;
void recognizeIntent()
{
// </skeleton_1>
// Creates an instance of a speech config with specified subscription key
// and service region. Note that in contrast to other services supported by
// the Cognitive Services Speech SDK, the Language Understanding service
// requires a specific subscription key from https://www.luis.ai/.
// The Language Understanding service calls the required key 'endpoint key'.
// Once you've obtained it, replace with below with your own Language Understanding subscription key
// and service region (e.g., "westus").
// The default recognition language is "en-us".
// <create_speech_configuration>
auto config = SpeechConfig::FromSubscription(
"YourLanguageUnderstandingSubscriptionKey",
"YourLanguageUnderstandingServiceRegion");
// </create_speech_configuration>
// <create_intent_recognizer>
// Creates an intent recognizer using microphone as audio input.
auto recognizer = IntentRecognizer::FromConfig(config);
// </create_intent_recognizer>
// <add_intents>
// Creates a Language Understanding model using the app id, and adds specific intents from your model
auto model = LanguageUnderstandingModel::FromAppId("YourLanguageUnderstandingAppId");
recognizer->AddIntent(model, "YourLanguageUnderstandingIntentName1", "id1");
recognizer->AddIntent(model, "YourLanguageUnderstandingIntentName2", "id2");
recognizer->AddIntent(model, "YourLanguageUnderstandingIntentName3", "any-IntentId-here");
// </add_intents>
// To add all of the possible intents from a LUIS model to the recognizer, uncomment the line below:
// recognizer->AddAllIntents(model);
// <recognize_intent>
cout << "Say something...\n";
// Starts intent recognition, and returns after a single utterance is recognized. The end of a
// single utterance is determined by listening for silence at the end or until a maximum of about 30
// seconds of audio is processed. The task returns the recognition text as result.
// Note: Since RecognizeOnceAsync() returns only a single utterance, it is suitable only for single
// shot recognition like command or query.
// For long-running multi-utterance recognition, use StartContinuousRecognitionAsync() instead.
auto result = recognizer->RecognizeOnceAsync().get();
// </recognize_intent>
// <print_results>
// Checks result.
if (result->Reason == ResultReason::RecognizedIntent)
{
cout << "RECOGNIZED: Text=" << result->Text << std::endl;
cout << " Intent Id: " << result->IntentId << std::endl;
cout << " Intent Service JSON: " << result->Properties.GetProperty(PropertyId::LanguageUnderstandingServiceResponse_JsonResult) << std::endl;
}
else if (result->Reason == ResultReason::RecognizedSpeech)
{
cout << "RECOGNIZED: Text=" << result->Text << " (intent could not be recognized)" << std::endl;
}
else if (result->Reason == ResultReason::NoMatch)
{
cout << "NOMATCH: Speech could not be recognized." << std::endl;
}
else if (result->Reason == ResultReason::Canceled)
{
auto cancellation = CancellationDetails::FromResult(result);
cout << "CANCELED: Reason=" << (int)cancellation->Reason << std::endl;
if (cancellation->Reason == CancellationReason::Error)
{
cout << "CANCELED: ErrorCode=" << (int)cancellation->ErrorCode << std::endl;
cout << "CANCELED: ErrorDetails=" << cancellation->ErrorDetails << std::endl;
cout << "CANCELED: Did you update the subscription info?" << std::endl;
}
}
// </print_results>
// <skeleton_2>
}
int wmain()
{
try
{
recognizeIntent();
}
catch (exception e)
{
cout << e.what();
}
cout << "Please press a key to continue.\n";
cin.get();
return 0;
}
// </skeleton_2>
建置並執行您的應用程式
現在您已準備好使用語音服務來建立應用程式,並測試我們的語音辨識。
- 編譯程式碼 - 從 Visual Studio 的功能表列中,選擇 [建置]>[建置解決方案]。
- 啟動應用程式 - 從功能表列中,選擇 [偵錯]>[開始偵錯],或按 F5。
- 開始辨識 - 它會提示您說英文片語。 您的語音會傳送至語音服務、轉譯為文字,並在主控台中轉譯。
在本快速入門中,您將使用語音 SDK 和 Language Understanding (LUIS)服務來辨識從麥克風擷取之音訊資料的意圖。 具體而言,您將使用語音 SDK 來擷取語音,並使用 LUIS 中預先建置的網域來識別家庭自動化的意圖,例如開燈和關燈。
必要條件
您也需要為您的開發環境安裝語音 SDK 並建立空白範例專案。
建立意圖辨識的 LUIS 應用程式
若要完成意圖辨識快速入門,您必須使用 LUIS 預覽入口網站建立 LUIS 帳戶和專案。 本快速入門需要區域中有意圖辨識的 LUIS 訂閱。 「不需要」語音服務訂用帳戶。
您的首要工作,是使用 LUIS 預覽入口網站建立 LUIS 帳戶和應用程式。 您所建立的 LUIS 應用程式將使用預先建置的網域進行家庭自動化,以提供意圖、實體和範例表達。 完成之後,您會擁有在雲端中執行的 LUIS 端點,供您使用語音 SDK 進行呼叫。
請依照下列指示建立 LUIS 應用程式:
完成作業後,您將需要四項資訊:
- 將語音預備切換為開啟以重新發佈
- 您的 LUIS 主要金鑰
- 您的 LUIS 位置
- 您的 LUIS 應用程式識別碼
您可以在此處透過 LUIS 預覽入口網站找到這些資訊:
從 LUIS 預覽入口網站中選取您的應用程式,然後選取 [發佈] 按鈕。
選取 [生產] 位置,如果您使用
en-US,請選取 [變更設定],然後將 [語音預備] 選項切換至 [開啟] 位置。 然後,選取 [發佈] 按鈕。重要
強烈建議您使用語音預備,因為其可以改善語音辨識的精確度。
在 LUIS 預覽入口網站中選取 [管理],然後選取 [Azure 資源]。 在此頁面上,您可以找到您 LUIS 預測資源的 LUIS 金鑰和位置 (有時也稱為「區域」)。
取得金鑰和位置之後,您將需要應用程式識別碼。 選取設定。 您可在此頁面取得您的應用程式識別碼。
打開您的專案
- 開啟您慣用的 IDE。
- 載入您的專案,並開啟
Main.java。
從重複使用程式碼開始著手
我們將新增程式碼,作為專案的基本架構。
package speechsdk.quickstart;
import com.microsoft.cognitiveservices.speech.*;
import com.microsoft.cognitiveservices.speech.intent.*;
/**
* Quickstart: recognize speech using the Speech SDK for Java.
*/
public class Main {
/**
* @param args Arguments are ignored in this sample.
*/
public static void main(String[] args) {
} catch (Exception ex) {
System.out.println("Unexpected exception: " + ex.getMessage());
assert(false);
System.exit(1);
}
}
}
建立語音設定
您必須先建立使用 LUIS 預測資源金鑰和位置的組態,才能夠初始化 IntentRecognizer 物件。
將此程式碼插入 main() 的 Try / Catch 區塊中。 請務必更新這些值:
- 將
"YourLanguageUnderstandingSubscriptionKey"取代為您的 LUIS 預測金鑰。 - 將
"YourLanguageUnderstandingServiceRegion"取代為您的 LUIS 位置。 使用區域中的 [區域識別碼]。
提示
如果您在尋找這些值時需要協助,請參閱建立意圖辨識的 LUIS 應用程式。
重要
完成時,請記得從程式碼中移除金鑰,且不要公開張貼金鑰。 在生產環境中,請使用安全的方式來儲存和存取您的認證,例如 Azure Key Vault。 如需詳細資訊,請參閱 Azure AI 服務安全性一文。
// Replace below with with specified subscription key (called 'endpoint key' by the Language Understanding service)
String languageUnderstandingSubscriptionKey = "YourLanguageUnderstandingSubscriptionKey";
// Replace below with your own service region (e.g., "westus").
String languageUnderstandingServiceRegion = "YourLanguageUnderstandingServiceRegion";
// Creates an instance of intent recognizer with a given speech configuration.
// Recognizer is created with the default microphone audio input and default language "en-us".
try (SpeechConfig config = SpeechConfig.fromSubscription(languageUnderstandingSubscriptionKey, languageUnderstandingServiceRegion);
此範例會使用 FromSubscription() 方法來建置 SpeechConfig。 如需可用方法的完整清單,請參閱 SpeechConfig 類別 \(英文\)。
語音 SDK 預設為使用 en-us 當作語言來辨識,如需有關選擇來源語言的詳細資訊,請參閱如何辨識語音。
初始化 IntentRecognizer
現在,我們將建立一個 IntentRecognizer。 將此程式碼插入您的語音設定的下方。
IntentRecognizer recognizer = new IntentRecognizer(config)) {
新增 LanguageUnderstandingModel 和意圖
您必須將 LanguageUnderstandingModel 與意圖辨識器建立關聯,並新增您要辨識的意圖。 我們將使用預先建置之網域中的意圖來進行家庭自動化。
在 IntentRecognizer 下方插入此程式碼。 請務必將 "YourLanguageUnderstandingAppId" 取代為您的 LUIS 應用程式識別碼。
提示
如果您在尋找此值時需要協助,請參閱建立意圖辨識的 LUIS 應用程式。
// Creates a language understanding model using the app id, and adds specific intents from your model
LanguageUnderstandingModel model = LanguageUnderstandingModel.fromAppId("YourLanguageUnderstandingAppId");
recognizer.addIntent(model, "YourLanguageUnderstandingIntentName1", "id1");
recognizer.addIntent(model, "YourLanguageUnderstandingIntentName2", "id2");
recognizer.addIntent(model, "YourLanguageUnderstandingIntentName3", "any-IntentId-here");
這個範例會使用 addIntent() 函式來個別新增意圖。 如果要從模型新增所有意圖,請使用 addAllIntents(model) 並傳遞模型。
辨識意圖
從 IntentRecognizer 物件,您將呼叫 recognizeOnceAsync() 方法。 此方法可讓語音服務知道您要傳送單一片語以進行辨識,且一旦識別出該片語即停止辨識語音。
在您的模型下插入此程式碼:
System.out.println("Say something...");
// Starts recognition. It returns when the first utterance has been recognized.
IntentRecognitionResult result = recognizer.recognizeOnceAsync().get();
顯示辨識結果 (或錯誤)
當語音服務傳回辨識結果時,建議您對其執行一些動作。 為了簡單起見,我們將結果列印到主控台。
在您對 recognizeOnceAsync() 的呼叫下插入此程式碼。
// Checks result.
if (result.getReason() == ResultReason.RecognizedIntent) {
System.out.println("RECOGNIZED: Text=" + result.getText());
System.out.println(" Intent Id: " + result.getIntentId());
System.out.println(" Intent Service JSON: " + result.getProperties().getProperty(PropertyId.LanguageUnderstandingServiceResponse_JsonResult));
}
else if (result.getReason() == ResultReason.RecognizedSpeech) {
System.out.println("RECOGNIZED: Text=" + result.getText());
System.out.println(" Intent not recognized.");
}
else if (result.getReason() == ResultReason.NoMatch) {
System.out.println("NOMATCH: Speech could not be recognized.");
}
else if (result.getReason() == ResultReason.Canceled) {
CancellationDetails cancellation = CancellationDetails.fromResult(result);
System.out.println("CANCELED: Reason=" + cancellation.getReason());
if (cancellation.getReason() == CancellationReason.Error) {
System.out.println("CANCELED: ErrorCode=" + cancellation.getErrorCode());
System.out.println("CANCELED: ErrorDetails=" + cancellation.getErrorDetails());
System.out.println("CANCELED: Did you update the subscription info?");
}
}
檢查您的程式碼
此時,您的程式碼應會如下所示:
注意
我們已在此版本中新增一些註解。
//
// Copyright (c) Microsoft. All rights reserved.
// Licensed under the MIT license. See LICENSE.md file in the project root for full license information.
//
// <skeleton_1>
package speechsdk.quickstart;
import com.microsoft.cognitiveservices.speech.*;
import com.microsoft.cognitiveservices.speech.intent.*;
/**
* Quickstart: recognize speech using the Speech SDK for Java.
*/
public class Main {
/**
* @param args Arguments are ignored in this sample.
*/
public static void main(String[] args) {
// </skeleton_1>
// <create_speech_configuration>
// Replace below with with specified subscription key (called 'endpoint key' by the Language Understanding service)
String languageUnderstandingSubscriptionKey = "YourLanguageUnderstandingSubscriptionKey";
// Replace below with your own service region (e.g., "westus").
String languageUnderstandingServiceRegion = "YourLanguageUnderstandingServiceRegion";
// Creates an instance of intent recognizer with a given speech configuration.
// Recognizer is created with the default microphone audio input and default language "en-us".
try (SpeechConfig config = SpeechConfig.fromSubscription(languageUnderstandingSubscriptionKey, languageUnderstandingServiceRegion);
// </create_speech_configuration>
// <create_intent_recognizer>
IntentRecognizer recognizer = new IntentRecognizer(config)) {
// </create_intent_recognizer>
// <add_intents>
// Creates a language understanding model using the app id, and adds specific intents from your model
LanguageUnderstandingModel model = LanguageUnderstandingModel.fromAppId("YourLanguageUnderstandingAppId");
recognizer.addIntent(model, "YourLanguageUnderstandingIntentName1", "id1");
recognizer.addIntent(model, "YourLanguageUnderstandingIntentName2", "id2");
recognizer.addIntent(model, "YourLanguageUnderstandingIntentName3", "any-IntentId-here");
// </add_intents>
// To add all of the possible intents from a LUIS model to the recognizer, uncomment the line below:
// recognizer.addAllIntents(model);
// <recognize_intent>
System.out.println("Say something...");
// Starts recognition. It returns when the first utterance has been recognized.
IntentRecognitionResult result = recognizer.recognizeOnceAsync().get();
// </recognize_intent>
// <print_result>
// Checks result.
if (result.getReason() == ResultReason.RecognizedIntent) {
System.out.println("RECOGNIZED: Text=" + result.getText());
System.out.println(" Intent Id: " + result.getIntentId());
System.out.println(" Intent Service JSON: " + result.getProperties().getProperty(PropertyId.LanguageUnderstandingServiceResponse_JsonResult));
}
else if (result.getReason() == ResultReason.RecognizedSpeech) {
System.out.println("RECOGNIZED: Text=" + result.getText());
System.out.println(" Intent not recognized.");
}
else if (result.getReason() == ResultReason.NoMatch) {
System.out.println("NOMATCH: Speech could not be recognized.");
}
else if (result.getReason() == ResultReason.Canceled) {
CancellationDetails cancellation = CancellationDetails.fromResult(result);
System.out.println("CANCELED: Reason=" + cancellation.getReason());
if (cancellation.getReason() == CancellationReason.Error) {
System.out.println("CANCELED: ErrorCode=" + cancellation.getErrorCode());
System.out.println("CANCELED: ErrorDetails=" + cancellation.getErrorDetails());
System.out.println("CANCELED: Did you update the subscription info?");
}
}
// </print_result>
// <skeleton_2>
} catch (Exception ex) {
System.out.println("Unexpected exception: " + ex.getMessage());
assert(false);
System.exit(1);
}
}
}
// </skeleton_2>
建置並執行您的應用程式
按 F11 鍵,或選取 [執行]>[偵錯]。 系統將會辨識接下來 15 秒來自您麥克風的語音輸入,並記錄在主控台視窗中。
參考文件 | 套件 (npm) | GitHub 上的其他範例 | 程式庫原始程式碼
在本快速入門中,您將使用語音 SDK 和 Language Understanding (LUIS)服務來辨識從麥克風擷取之音訊資料的意圖。 具體而言,您將使用語音 SDK 來擷取語音,並使用 LUIS 中預先建置的網域來識別家庭自動化的意圖,例如開燈和關燈。
必要條件
您也需要為您的開發環境安裝語音 SDK 並建立空白範例專案。
建立意圖辨識的 LUIS 應用程式
若要完成意圖辨識快速入門,您必須使用 LUIS 預覽入口網站建立 LUIS 帳戶和專案。 本快速入門需要區域中有意圖辨識的 LUIS 訂閱。 「不需要」語音服務訂用帳戶。
您的首要工作,是使用 LUIS 預覽入口網站建立 LUIS 帳戶和應用程式。 您所建立的 LUIS 應用程式將使用預先建置的網域進行家庭自動化,以提供意圖、實體和範例表達。 完成之後,您會擁有在雲端中執行的 LUIS 端點,供您使用語音 SDK 進行呼叫。
請依照下列指示建立 LUIS 應用程式:
完成作業後,您將需要四項資訊:
- 將語音預備切換為開啟以重新發佈
- 您的 LUIS 主要金鑰
- 您的 LUIS 位置
- 您的 LUIS 應用程式識別碼
您可以在此處透過 LUIS 預覽入口網站找到這些資訊:
從 LUIS 預覽入口網站中選取您的應用程式,然後選取 [發佈] 按鈕。
選取 [生產] 位置,如果您使用
en-US,請選取 [變更設定],然後將 [語音預備] 選項切換至 [開啟] 位置。 然後,選取 [發佈] 按鈕。重要
強烈建議您使用語音預備,因為其可以改善語音辨識的精確度。
在 LUIS 預覽入口網站中選取 [管理],然後選取 [Azure 資源]。 在此頁面上,您可以找到您 LUIS 預測資源的 LUIS 金鑰和位置 (有時也稱為「區域」)。
取得金鑰和位置之後,您將需要應用程式識別碼。 選取設定。 您可在此頁面取得您的應用程式識別碼。
從重複使用程式碼開始著手
我們將新增程式碼,作為專案的基本架構。
<!DOCTYPE html>
<html>
<head>
<title>Microsoft Azure AI Speech SDK JavaScript Quickstart</title>
<meta charset="utf-8" />
</head>
<body style="font-family:'Helvetica Neue',Helvetica,Arial,sans-serif; font-size:13px;">
</body>
</html>
新增 UI 元素
現在,我們將為輸入方塊新增一些基本 UI、參考語音 SDK 的 JavaScript,並取得授權權杖 (如果有的話)。
重要
完成時,請記得從程式碼中移除金鑰,且不要公開張貼金鑰。 在生產環境中,請使用安全的方式來儲存和存取您的認證,例如 Azure Key Vault。 如需詳細資訊,請參閱 Azure AI 服務安全性一文。
<body style="font-family:'Helvetica Neue',Helvetica,Arial,sans-serif; font-size:13px;">
<div id="content" style="display:none">
<table width="100%">
<tr>
<td></td>
<td><h1 style="font-weight:500;">Microsoft Azure AI Speech SDK JavaScript Quickstart</h1></td>
</tr>
<tr>
<td align="right"><a href="/azure/ai-services/speech-service/overview" target="_blank">Subscription</a>:</td>
<td><input id="subscriptionKey" type="text" size="40" value="subscription"></td>
</tr>
<tr>
<td align="right">Region</td>
<td><input id="serviceRegion" type="text" size="40" value="YourServiceRegion"></td>
</tr>
<tr>
<td align="right">Application ID:</td>
<td><input id="appId" type="text" size="60" value="YOUR_LANGUAGE_UNDERSTANDING_APP_ID"></td>
</tr>
<tr>
<td></td>
<td><button id="startIntentRecognizeAsyncButton">Start Intent Recognition</button></td>
</tr>
<tr>
<td align="right" valign="top">Input Text</td>
<td><textarea id="phraseDiv" style="display: inline-block;width:500px;height:200px"></textarea></td>
</tr>
<tr>
<td align="right" valign="top">Result</td>
<td><textarea id="statusDiv" style="display: inline-block;width:500px;height:100px"></textarea></td>
</tr>
</table>
</div>
<script src="microsoft.cognitiveservices.speech.sdk.bundle.js"></script>
<script>
// Replace the URL with a valid endpoint to retrieve
// authorization tokens for your Speech resource.
var authorizationEndpoint = "token.php";
function RequestAuthorizationToken() {
if (authorizationEndpoint) {
var a = new XMLHttpRequest();
a.open("GET", authorizationEndpoint);
a.setRequestHeader("Content-Type", "application/x-www-form-urlencoded");
a.send("");
a.onload = function() {
var token = JSON.parse(atob(this.responseText.split(".")[1]));
serviceRegion.value = token.region;
authorizationToken = this.responseText;
subscriptionKey.disabled = true;
subscriptionKey.value = "using authorization token (hit F5 to refresh)";
console.log("Got an authorization token: " + token);
}
}
}
</script>
<script>
// status fields and start button in UI
var phraseDiv;
var statusDiv;
var startIntentRecognizeAsyncButton;
// subscription key, region, and appId for LUIS services.
var subscriptionKey, serviceRegion, appId;
var authorizationToken;
var SpeechSDK;
var recognizer;
document.addEventListener("DOMContentLoaded", function () {
startIntentRecognizeAsyncButton = document.getElementById("startIntentRecognizeAsyncButton");
subscriptionKey = document.getElementById("subscriptionKey");
serviceRegion = document.getElementById("serviceRegion");
appId = document.getElementById("appId");
phraseDiv = document.getElementById("phraseDiv");
statusDiv = document.getElementById("statusDiv");
startIntentRecognizeAsyncButton.addEventListener("click", function () {
startIntentRecognizeAsyncButton.disabled = true;
phraseDiv.innerHTML = "";
statusDiv.innerHTML = "";
});
if (!!window.SpeechSDK) {
SpeechSDK = window.SpeechSDK;
startIntentRecognizeAsyncButton.disabled = false;
document.getElementById('content').style.display = 'block';
document.getElementById('warning').style.display = 'none';
// in case we have a function for getting an authorization token, call it.
if (typeof RequestAuthorizationToken === "function") {
RequestAuthorizationToken();
}
}
});
</script>
建立語音設定
您必須先建立使用語音資源密鑰和訂用帳戶區域的組態,才能初始化 SpeechRecognizer 物件。 在 startRecognizeOnceAsyncButton.addEventListener() 方法中插入此程式碼。
注意
語音 SDK 預設為使用 en-us 當作語言來辨識,如需有關選擇來源語言的詳細資訊,請參閱如何辨識語音。
// if we got an authorization token, use the token. Otherwise use the provided subscription key
var speechConfig;
if (authorizationToken) {
speechConfig = SpeechSDK.SpeechConfig.fromAuthorizationToken(authorizationToken, serviceRegion.value);
} else {
if (subscriptionKey.value === "" || subscriptionKey.value === "subscription") {
alert("Please enter your Microsoft Azure AI Speech subscription key!");
return;
}
startIntentRecognizeAsyncButton.disabled = false;
speechConfig = SpeechSDK.SpeechConfig.fromSubscription(subscriptionKey.value, serviceRegion.value);
}
speechConfig.speechRecognitionLanguage = "en-US";
建立音訊設定
現在,您必須建立指向輸入裝置的 AudioConfig 物件。 將此程式碼插入您的語音設定下方的 startIntentRecognizeAsyncButton.addEventListener() 方法中。
var audioConfig = SpeechSDK.AudioConfig.fromDefaultMicrophoneInput();
初始化 IntentRecognizer
現在,讓我們使用稍早建立的 IntentRecognizer 和 SpeechConfig 物件來建立 AudioConfig 物件。 在 startIntentRecognizeAsyncButton.addEventListener() 方法中插入此程式碼。
recognizer = new SpeechSDK.IntentRecognizer(speechConfig, audioConfig);
新增 LanguageUnderstandingModel 和意圖
您必須將 LanguageUnderstandingModel 與意圖辨識器建立關聯,並新增您要辨識的意圖。 我們將使用預先建置之網域中的意圖來進行家庭自動化。
在 IntentRecognizer 下方插入此程式碼。 請務必將 "YourLanguageUnderstandingAppId" 取代為您的 LUIS 應用程式識別碼。
if (appId.value !== "" && appId.value !== "YOUR_LANGUAGE_UNDERSTANDING_APP_ID") {
var lm = SpeechSDK.LanguageUnderstandingModel.fromAppId(appId.value);
recognizer.addAllIntents(lm);
}
注意
語音 SDK 僅支援 LUIS v2.0 端點。 您必須手動修改在範例查詢欄位中找到的 v3.0 端點 URL,以使用 v2.0 URL 模式。 LUIS v2.0 端點一律會遵循下列其中一種模式:
https://{AzureResourceName}.cognitiveservices.azure.com/luis/v2.0/apps/{app-id}?subscription-key={subkey}&verbose=true&q=https://{Region}.api.cognitive.microsoft.com/luis/v2.0/apps/{app-id}?subscription-key={subkey}&verbose=true&q=
辨識意圖
從 IntentRecognizer 物件,您將呼叫 recognizeOnceAsync() 方法。 此方法可讓語音服務知道您要傳送單一片語以進行辨識,且一旦識別出該片語即停止辨識語音。
將此程式碼插入到模型新增底下:
recognizer.recognizeOnceAsync(
function (result) {
window.console.log(result);
phraseDiv.innerHTML = result.text + "\r\n";
statusDiv.innerHTML += "(continuation) Reason: " + SpeechSDK.ResultReason[result.reason];
switch (result.reason) {
case SpeechSDK.ResultReason.RecognizedSpeech:
statusDiv.innerHTML += " Text: " + result.text;
break;
case SpeechSDK.ResultReason.RecognizedIntent:
statusDiv.innerHTML += " Text: " + result.text + " IntentId: " + result.intentId;
// The actual JSON returned from Language Understanding is a bit more complex to get to, but it is available for things like
// the entity name and type if part of the intent.
statusDiv.innerHTML += " Intent JSON: " + result.properties.getProperty(SpeechSDK.PropertyId.LanguageUnderstandingServiceResponse_JsonResult);
phraseDiv.innerHTML += result.properties.getProperty(SpeechSDK.PropertyId.LanguageUnderstandingServiceResponse_JsonResult) + "\r\n";
break;
case SpeechSDK.ResultReason.NoMatch:
var noMatchDetail = SpeechSDK.NoMatchDetails.fromResult(result);
statusDiv.innerHTML += " NoMatchReason: " + SpeechSDK.NoMatchReason[noMatchDetail.reason];
break;
case SpeechSDK.ResultReason.Canceled:
var cancelDetails = SpeechSDK.CancellationDetails.fromResult(result);
statusDiv.innerHTML += " CancellationReason: " + SpeechSDK.CancellationReason[cancelDetails.reason];
if (cancelDetails.reason === SpeechSDK.CancellationReason.Error) {
statusDiv.innerHTML += ": " + cancelDetails.errorDetails;
}
break;
}
statusDiv.innerHTML += "\r\n";
startIntentRecognizeAsyncButton.disabled = false;
},
function (err) {
window.console.log(err);
phraseDiv.innerHTML += "ERROR: " + err;
startIntentRecognizeAsyncButton.disabled = false;
});
檢查您的程式碼
<!DOCTYPE html>
<html>
<head>
<title>Microsoft Cognitive Services Speech SDK JavaScript Quickstart</title>
<meta charset="utf-8" />
</head>
<body style="font-family:'Helvetica Neue',Helvetica,Arial,sans-serif; font-size:13px;">
<div id="warning">
<h1 style="font-weight:500;">Speech Recognition Speech SDK not found (microsoft.cognitiveservices.speech.sdk.bundle.js missing).</h1>
</div>
<div id="content" style="display:none">
<table width="100%">
<tr>
<td></td>
<td><h1 style="font-weight:500;">Microsoft Cognitive Services Speech SDK JavaScript Quickstart</h1></td>
</tr>
<tr>
<td align="right"><a href="https://docs.microsoft.com/azure/cognitive-services/speech-service/quickstarts/intent-recognition?pivots=programming-language-csharp#create-a-luis-app-for-intent-recognition" target="_blank">LUIS Primary Key</a>:</td>
<td><input id="subscriptionKey" type="text" size="40" value="subscription"></td>
</tr>
<tr>
<td align="right">LUIS Location</td>
<td><input id="serviceRegion" type="text" size="40" value="YourServiceRegion"></td>
</tr>
<tr>
<td align="right">LUIS App ID:</td>
<td><input id="appId" type="text" size="60" value="YOUR_LANGUAGE_UNDERSTANDING_APP_ID"></td>
</tr>
<tr>
<td></td>
<td><button id="startIntentRecognizeAsyncButton">Start Intent Recognition</button></td>
</tr>
<tr>
<td align="right" valign="top">Input Text</td>
<td><textarea id="phraseDiv" style="display: inline-block;width:500px;height:200px"></textarea></td>
</tr>
<tr>
<td align="right" valign="top">Result</td>
<td><textarea id="statusDiv" style="display: inline-block;width:500px;height:100px"></textarea></td>
</tr>
</table>
</div>
<!-- Speech SDK reference sdk. -->
<script src="https://aka.ms/csspeech/jsbrowserpackageraw"></script>
<!-- Speech SDK USAGE -->
<script>
// status fields and start button in UI
var phraseDiv;
var statusDiv;
var startIntentRecognizeAsyncButton;
// subscription key and region for speech services.
var subscriptionKey, serviceRegion, appId;
var SpeechSDK;
var recognizer;
document.addEventListener("DOMContentLoaded", function () {
startIntentRecognizeAsyncButton = document.getElementById("startIntentRecognizeAsyncButton");
subscriptionKey = document.getElementById("subscriptionKey");
serviceRegion = document.getElementById("serviceRegion");
appId = document.getElementById("appId");
phraseDiv = document.getElementById("phraseDiv");
statusDiv = document.getElementById("statusDiv");
startIntentRecognizeAsyncButton.addEventListener("click", function () {
startIntentRecognizeAsyncButton.disabled = true;
phraseDiv.innerHTML = "";
statusDiv.innerHTML = "";
let audioConfig = SpeechSDK.AudioConfig.fromDefaultMicrophoneInput();
if (subscriptionKey.value === "" || subscriptionKey.value === "subscription") {
alert("Please enter your Microsoft Cognitive Services Speech subscription key!");
startIntentRecognizeAsyncButton.disabled = false;
return;
}
var speechConfig = SpeechSDK.SpeechConfig.fromSubscription(subscriptionKey.value, serviceRegion.value);
speechConfig.speechRecognitionLanguage = "en-US";
recognizer = new SpeechSDK.IntentRecognizer(speechConfig, audioConfig);
// Set up a Language Understanding Model from Language Understanding Intelligent Service (LUIS).
// See https://www.luis.ai/home for more information on LUIS.
if (appId.value !== "" && appId.value !== "YOUR_LANGUAGE_UNDERSTANDING_APP_ID") {
var lm = SpeechSDK.LanguageUnderstandingModel.fromAppId(appId.value);
recognizer.addAllIntents(lm);
}
recognizer.recognizeOnceAsync(
function (result) {
window.console.log(result);
phraseDiv.innerHTML = result.text + "\r\n";
statusDiv.innerHTML += "(continuation) Reason: " + SpeechSDK.ResultReason[result.reason];
switch (result.reason) {
case SpeechSDK.ResultReason.RecognizedSpeech:
statusDiv.innerHTML += " Text: " + result.text;
break;
case SpeechSDK.ResultReason.RecognizedIntent:
statusDiv.innerHTML += " Text: " + result.text + " IntentId: " + result.intentId;
// The actual JSON returned from Language Understanding is a bit more complex to get to, but it is available for things like
// the entity name and type if part of the intent.
statusDiv.innerHTML += " Intent JSON: " + result.properties.getProperty(SpeechSDK.PropertyId.LanguageUnderstandingServiceResponse_JsonResult);
phraseDiv.innerHTML += result.properties.getProperty(SpeechSDK.PropertyId.LanguageUnderstandingServiceResponse_JsonResult) + "\r\n";
break;
case SpeechSDK.ResultReason.NoMatch:
var noMatchDetail = SpeechSDK.NoMatchDetails.fromResult(result);
statusDiv.innerHTML += " NoMatchReason: " + SpeechSDK.NoMatchReason[noMatchDetail.reason];
break;
case SpeechSDK.ResultReason.Canceled:
var cancelDetails = SpeechSDK.CancellationDetails.fromResult(result);
statusDiv.innerHTML += " CancellationReason: " + SpeechSDK.CancellationReason[cancelDetails.reason];
if (cancelDetails.reason === SpeechSDK.CancellationReason.Error) {
statusDiv.innerHTML += ": " + cancelDetails.errorDetails;
}
break;
}
statusDiv.innerHTML += "\r\n";
startIntentRecognizeAsyncButton.disabled = false;
},
function (err) {
window.console.log(err);
phraseDiv.innerHTML += "ERROR: " + err;
startIntentRecognizeAsyncButton.disabled = false;
});
});
if (!!window.SpeechSDK) {
SpeechSDK = window.SpeechSDK;
startIntentRecognizeAsyncButton.disabled = false;
document.getElementById('content').style.display = 'block';
document.getElementById('warning').style.display = 'none';
}
});
</script>
</body>
</html>
建立權杖來源 (選擇性)
如果想要在 Web 伺服器上裝載網頁,可以選擇性提供示範應用程式的權杖來源。 如此一來,您的語音資源密鑰絕不會離開您的伺服器,同時允許使用者在不輸入任何授權碼的情況下使用語音功能。
建立名為 token.php 的新檔案。 在此範例中,我們會假設您的 Web 伺服器支援 PHP 指令碼語言並且已啟用 cURL。 輸入下列程式碼:
<?php
header('Access-Control-Allow-Origin: ' . $_SERVER['SERVER_NAME']);
// Replace with your own subscription key and service region (e.g., "westus").
$subscriptionKey = 'YourSpeechResoureKey';
$region = 'YourServiceRegion';
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, 'https://' . $region . '.api.cognitive.microsoft.com/sts/v1.0/issueToken');
curl_setopt($ch, CURLOPT_POST, 1);
curl_setopt($ch, CURLOPT_POSTFIELDS, '{}');
curl_setopt($ch, CURLOPT_HTTPHEADER, array('Content-Type: application/json', 'Ocp-Apim-Subscription-Key: ' . $subscriptionKey));
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
echo curl_exec($ch);
?>
注意
授權權杖的存留期是有限的。 這個簡化範例不會說明如何自動重新整理授權權杖。 如果您是使用者,可以手動重新載入或按 F5 以重新整理頁面。
在本機建置並執行範例
若要啟動應用程式,請按兩下 index.html 檔案或使用最愛的網頁瀏覽器開啟 index.html。 其會顯示一個簡單的 GUI,可讓您輸入 LUIS 金鑰、LUIS 區域以及 LUIS 應用程式識別碼。 輸入這些欄位之後,您可以按一下適當的按鈕,使用麥克風來觸發辨識。
注意
此方法無法在 Safari 瀏覽器上運作。 在 Safari 上,範例網頁必須裝載在 Web 伺服器上;Safari 不允許從本機檔案載入的網站使用麥克風。
透過 Web 伺服器建置並執行範例
若要啟動應用程式,請開啟您最愛的網頁瀏覽器並將其指向資料夾裝載所在的公用 URL、輸入您的 LUIS 區域以及 LUIS 應用程式識別碼,然後使用麥克風觸發辨識。 如果已設定,其便會從權杖來源取得權杖,並開始辨識語音命令。
參考文件 | 套件 (PyPi) | GitHub 上的其他範例
在本快速入門中,您將使用語音 SDK 和 Language Understanding (LUIS)服務來辨識從麥克風擷取之音訊資料的意圖。 具體而言,您將使用語音 SDK 來擷取語音,並使用 LUIS 中預先建置的網域來識別家庭自動化的意圖,例如開燈和關燈。
必要條件
您也需要為您的開發環境安裝語音 SDK 並建立空白範例專案。
建立意圖辨識的 LUIS 應用程式
若要完成意圖辨識快速入門,您必須使用 LUIS 預覽入口網站建立 LUIS 帳戶和專案。 本快速入門需要區域中有意圖辨識的 LUIS 訂閱。 「不需要」語音服務訂用帳戶。
您的首要工作,是使用 LUIS 預覽入口網站建立 LUIS 帳戶和應用程式。 您所建立的 LUIS 應用程式將使用預先建置的網域進行家庭自動化,以提供意圖、實體和範例表達。 完成之後,您會擁有在雲端中執行的 LUIS 端點,供您使用語音 SDK 進行呼叫。
請依照下列指示建立 LUIS 應用程式:
完成作業後,您將需要四項資訊:
- 將語音預備切換為開啟以重新發佈
- 您的 LUIS 主要金鑰
- 您的 LUIS 位置
- 您的 LUIS 應用程式識別碼
您可以在此處透過 LUIS 預覽入口網站找到這些資訊:
從 LUIS 預覽入口網站中選取您的應用程式,然後選取 [發佈] 按鈕。
選取 [生產] 位置,如果您使用
en-US,請選取 [變更設定],然後將 [語音預備] 選項切換至 [開啟] 位置。 然後,選取 [發佈] 按鈕。重要
強烈建議您使用語音預備,因為其可以改善語音辨識的精確度。
在 LUIS 預覽入口網站中選取 [管理],然後選取 [Azure 資源]。 在此頁面上,您可以找到您 LUIS 預測資源的 LUIS 金鑰和位置 (有時也稱為「區域」)。
取得金鑰和位置之後,您將需要應用程式識別碼。 選取設定。 您可在此頁面取得您的應用程式識別碼。
打開您的專案
- 開啟您慣用的 IDE。
- 建立新的專案,並建立名為
quickstart.py的檔案,然後加以開啟。
從重複使用程式碼開始著手
我們將新增程式碼,作為專案的基本架構。
import azure.cognitiveservices.speech as speechsdk
print("Say something...")
建立語音設定
您必須先建立使用 LUIS 預測資源金鑰和位置的組態,才能夠初始化 IntentRecognizer 物件。
在 quickstart.py 中插入此程式碼。 請務必更新這些值:
- 將
"YourLanguageUnderstandingSubscriptionKey"取代為您的 LUIS 預測金鑰。 - 將
"YourLanguageUnderstandingServiceRegion"取代為您的 LUIS 位置。 使用區域中的 [區域識別碼]。
提示
如果您在尋找這些值時需要協助,請參閱建立意圖辨識的 LUIS 應用程式。
重要
完成時,請記得從程式碼中移除金鑰,且不要公開張貼金鑰。 在生產環境中,請使用安全的方式來儲存和存取您的認證,例如 Azure Key Vault。 如需詳細資訊,請參閱 Azure AI 服務安全性一文。
# Set up the config for the intent recognizer (remember that this uses the Language Understanding key, not the Speech Services key)!
intent_config = speechsdk.SpeechConfig(
subscription="YourLanguageUnderstandingSubscriptionKey",
region="YourLanguageUnderstandingServiceRegion")
此範例使用 LUIS 金鑰和區域建構 SpeechConfig 物件。 如需可用方法的完整清單,請參閱 SpeechConfig 類別 \(英文\)。
語音 SDK 預設為使用 en-us 當作語言來辨識,如需有關選擇來源語言的詳細資訊,請參閱如何辨識語音。
初始化 IntentRecognizer
現在,我們將建立一個 IntentRecognizer。 將此程式碼插入您的語音設定的下方。
# Set up the intent recognizer
intent_recognizer = speechsdk.intent.IntentRecognizer(speech_config=intent_config)
新增 LanguageUnderstandingModel 和意圖
您必須將 LanguageUnderstandingModel 與意圖辨識器建立關聯,並新增您要辨識的意圖。 我們將使用預先建置之網域中的意圖來進行家庭自動化。
在 IntentRecognizer 下方插入此程式碼。 請務必將 "YourLanguageUnderstandingAppId" 取代為您的 LUIS 應用程式識別碼。
提示
如果您在尋找此值時需要協助,請參閱建立意圖辨識的 LUIS 應用程式。
# set up the intents that are to be recognized. These can be a mix of simple phrases and
# intents specified through a LanguageUnderstanding Model.
model = speechsdk.intent.LanguageUnderstandingModel(app_id="YourLanguageUnderstandingAppId")
intents = [
(model, "HomeAutomation.TurnOn"),
(model, "HomeAutomation.TurnOff"),
("This is a test.", "test"),
("Switch to channel 34.", "34"),
("what's the weather like", "weather"),
]
intent_recognizer.add_intents(intents)
這個範例會使用 add_intents() 函式來新增明確定義的意圖清單。 如果要從模型新增所有意圖,請使用 add_all_intents(model) 並傳遞模型。
辨識意圖
從 IntentRecognizer 物件,您將呼叫 recognize_once() 方法。 此方法可讓語音服務知道您要傳送單一片語以進行辨識,且一旦識別出該片語即停止辨識語音。
在您的模型下插入此程式碼。
intent_result = intent_recognizer.recognize_once()
顯示辨識結果 (或錯誤)
當語音服務傳回辨識結果時,建議您對其執行一些動作。 為了簡單起見,我們將結果列印到主控台。
在您對 recognize_once() 的呼叫下方,新增此程式碼。
# Check the results
if intent_result.reason == speechsdk.ResultReason.RecognizedIntent:
print("Recognized: \"{}\" with intent id `{}`".format(intent_result.text, intent_result.intent_id))
elif intent_result.reason == speechsdk.ResultReason.RecognizedSpeech:
print("Recognized: {}".format(intent_result.text))
elif intent_result.reason == speechsdk.ResultReason.NoMatch:
print("No speech could be recognized: {}".format(intent_result.no_match_details))
elif intent_result.reason == speechsdk.ResultReason.Canceled:
print("Intent recognition canceled: {}".format(intent_result.cancellation_details.reason))
if intent_result.cancellation_details.reason == speechsdk.CancellationReason.Error:
print("Error details: {}".format(intent_result.cancellation_details.error_details))
檢查您的程式碼
此時,您的程式碼應會如下所示。
注意
我們已在此版本中新增一些註解。
# Copyright (c) Microsoft. All rights reserved.
# Licensed under the MIT license. See LICENSE.md file in the project root for full license information.
# <skeleton>
import azure.cognitiveservices.speech as speechsdk
print("Say something...")
# </skeleton>
"""performs one-shot intent recognition from input from the default microphone"""
# <create_speech_configuration>
# Set up the config for the intent recognizer (remember that this uses the Language Understanding key, not the Speech Services key)!
intent_config = speechsdk.SpeechConfig(
subscription="YourLanguageUnderstandingSubscriptionKey",
region="YourLanguageUnderstandingServiceRegion")
# </create_speech_configuration>
# <create_intent_recognizer>
# Set up the intent recognizer
intent_recognizer = speechsdk.intent.IntentRecognizer(speech_config=intent_config)
# </create_intent_recognizer>
# <add_intents>
# set up the intents that are to be recognized. These can be a mix of simple phrases and
# intents specified through a LanguageUnderstanding Model.
model = speechsdk.intent.LanguageUnderstandingModel(app_id="YourLanguageUnderstandingAppId")
intents = [
(model, "HomeAutomation.TurnOn"),
(model, "HomeAutomation.TurnOff"),
("This is a test.", "test"),
("Switch to channel 34.", "34"),
("what's the weather like", "weather"),
]
intent_recognizer.add_intents(intents)
# </add_intents>
# To add all of the possible intents from a LUIS model to the recognizer, uncomment the line below:
# intent_recognizer.add_all_intents(model)
# Starts intent recognition, and returns after a single utterance is recognized. The end of a
# single utterance is determined by listening for silence at the end or until a maximum of about 30
# seconds of audio is processed. It returns the recognition text as result.
# Note: Since recognize_once() returns only a single utterance, it is suitable only for single
# shot recognition like command or query.
# For long-running multi-utterance recognition, use start_continuous_recognition() instead.
# <recognize_intent>
intent_result = intent_recognizer.recognize_once()
# </recognize_intent>
# <print_results>
# Check the results
if intent_result.reason == speechsdk.ResultReason.RecognizedIntent:
print("Recognized: \"{}\" with intent id `{}`".format(intent_result.text, intent_result.intent_id))
elif intent_result.reason == speechsdk.ResultReason.RecognizedSpeech:
print("Recognized: {}".format(intent_result.text))
elif intent_result.reason == speechsdk.ResultReason.NoMatch:
print("No speech could be recognized: {}".format(intent_result.no_match_details))
elif intent_result.reason == speechsdk.ResultReason.Canceled:
print("Intent recognition canceled: {}".format(intent_result.cancellation_details.reason))
if intent_result.cancellation_details.reason == speechsdk.CancellationReason.Error:
print("Error details: {}".format(intent_result.cancellation_details.error_details))
# </print_results>
建置並執行您的應用程式
從主控台或在您的 IDE 中執行範例:
python quickstart.py
系統將會辨識接下來 15 秒來自您麥克風的語音輸入,並記錄在主控台視窗中。
參考文件 | 套件 (Go) | GitHub 上的其他範例
語音 SDK for Go 不支援意圖辨識。 請選取其他程式設計語言,或本文開頭的 Go 參考和樣本連結。
參考文件 | 套件 (下載) | GitHub 上的其他範例
適用於 Objective-C 的語音 SDK 支援意圖辨識,但這裡尚未包含指南。 請選取另一種程式設計語言來開始使用並了解概念,或參閱本文開頭連結的 Objective-C 參考和範例。
參考文件 | 套件 (下載) | GitHub 上的其他範例
適用於 Swift 的語音 SDK 支援意圖辨識,但這裡尚未包含指南。 請選取另一種程式設計語言來開始使用並了解概念,或參閱本文開頭連結的 Swift 參考和範例。
語音轉換文字 REST API 參考 | 適用於簡短音訊的語音轉換文字 REST API 參考 | GitHub 上的其他範例
您可以使用 REST API 進行意圖辨識,但這裡尚未包含指南。 請選取另一種程式設計語言來開始使用並了解概念。
語音命令列介面 (CLI) 支援意圖辨識,但這裡尚未包含指南。 請選取另一種程式設計語言來開始使用並了解概念,或如需 CLI 的詳細資訊,請參閱語音 CLI 概觀。