在本文中,您會了解如何以量化方式測量並改善基礎語音轉換文字模型或您自己的自訂模型的正確性。 需要音訊 + 人工標記的轉錄資料,才能測試正確性。 您應該提供 30 分鐘到 5 小時的代表性音訊。
重要事項
進行測試時,系統會執行轉錄。 因為每個服務供應項目和訂用帳戶層級的定價有所不同,所以請務必牢記這一點。 如需 最新細節,請務必參考官方 Foundry Tools 價格。
建立測試
小提示
將你自訂的語音模型從 Speech Studio 帶到 Microsoft Foundry 入口網站。 在 Microsoft Foundry 入口網站中,你可以連接現有的語音資源,繼續上次的作業。 如需連線到現有語音資源的詳細資訊,請參閱連線到現有的語音資源。
您可以藉由建立測試來測試自訂模型的正確性。 測試需要音訊檔案的集合及其對應的轉錄。 您可以比較語音轉換文字基礎模型與自訂模型或其他自訂模型的正確性。 取得測試結果之後,請評估相較於語音辨識結果的字組錯誤率 (WER)。
上傳定型和測試數據集之後,您可以建立測試。
若要測試微調的自訂語音模型,請遵循下列步驟:
從左窗格中選取 [ 微調 ],然後選取 [AI 服務微調]。
請選取您根據《如何啟動自訂語音微調》一文中指示啟動的自訂語音微調任務 (依模型名稱)。
選取 [測試模型>+ 建立測試]。
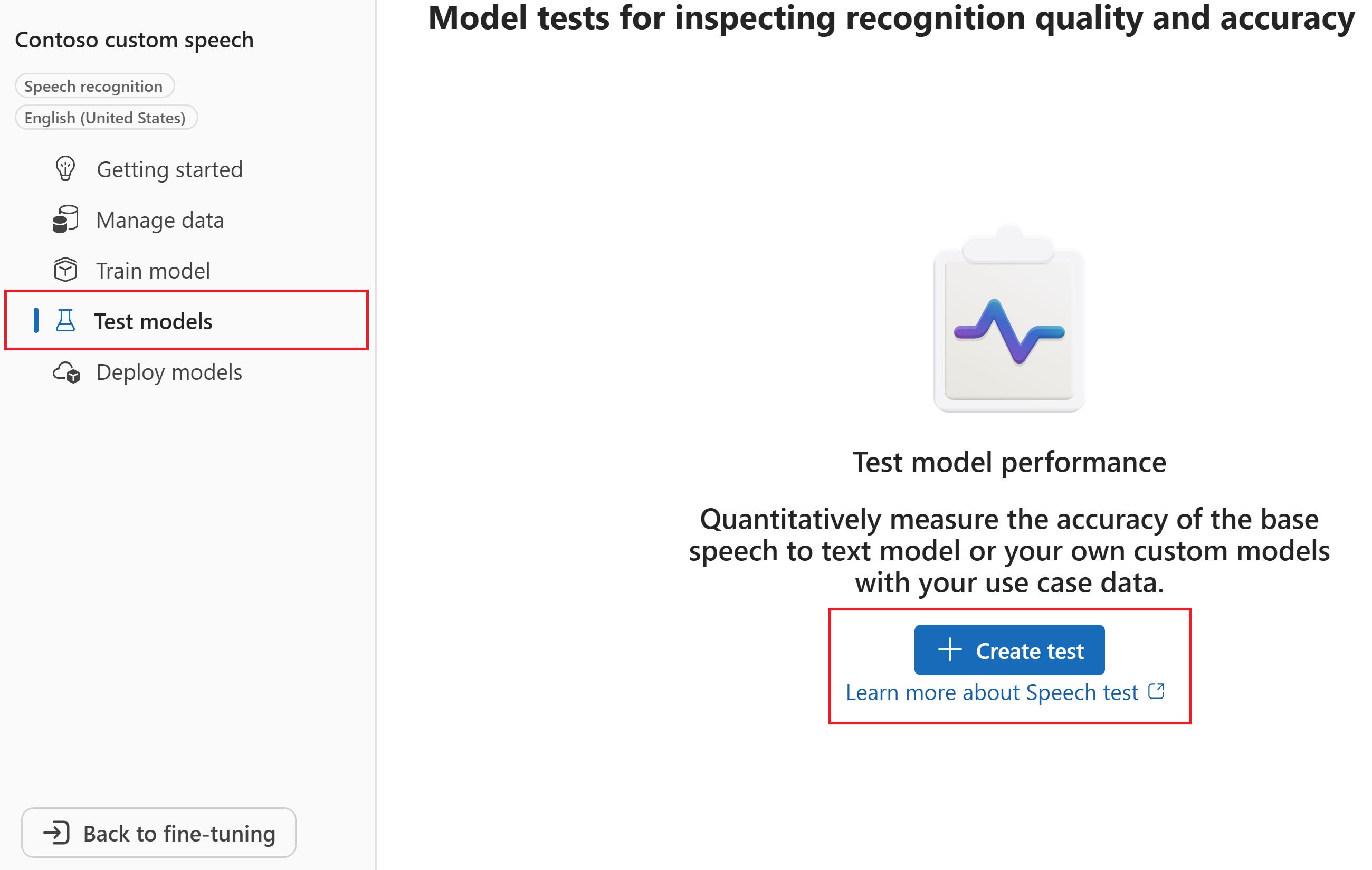
在 [建立新的測試] 精靈中,選取測試類型。 針對精確度(量化)測試,選取 [評估精確度] [音訊 + 文字記錄數據]。 然後選取下一步。
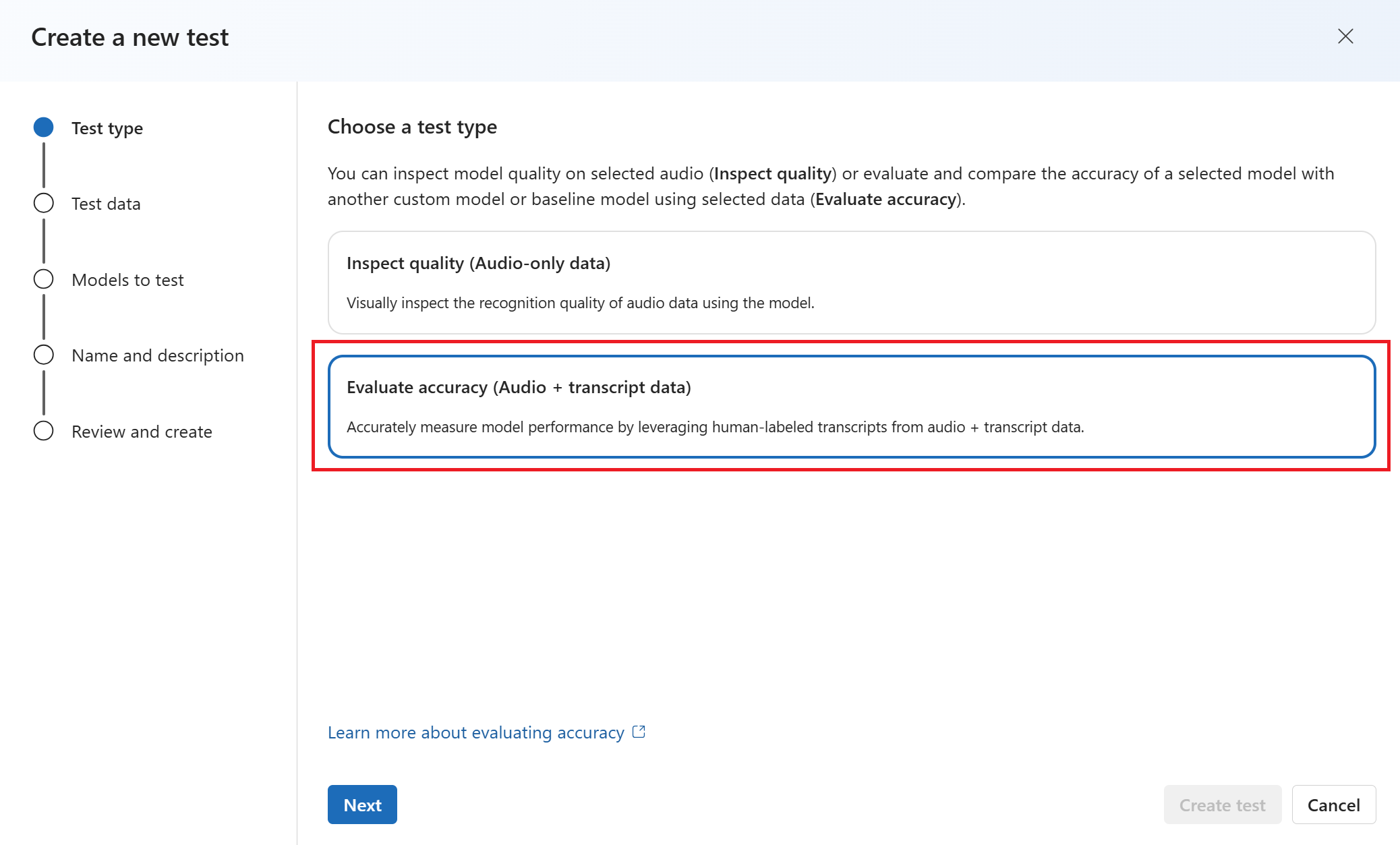
選取您要用於測試的資料。 然後選取下一步。
最多選取兩個模型來評估和比較準確度。 在此範例中,我們會選取我們定型的模型和基本模型。 然後選取下一步。
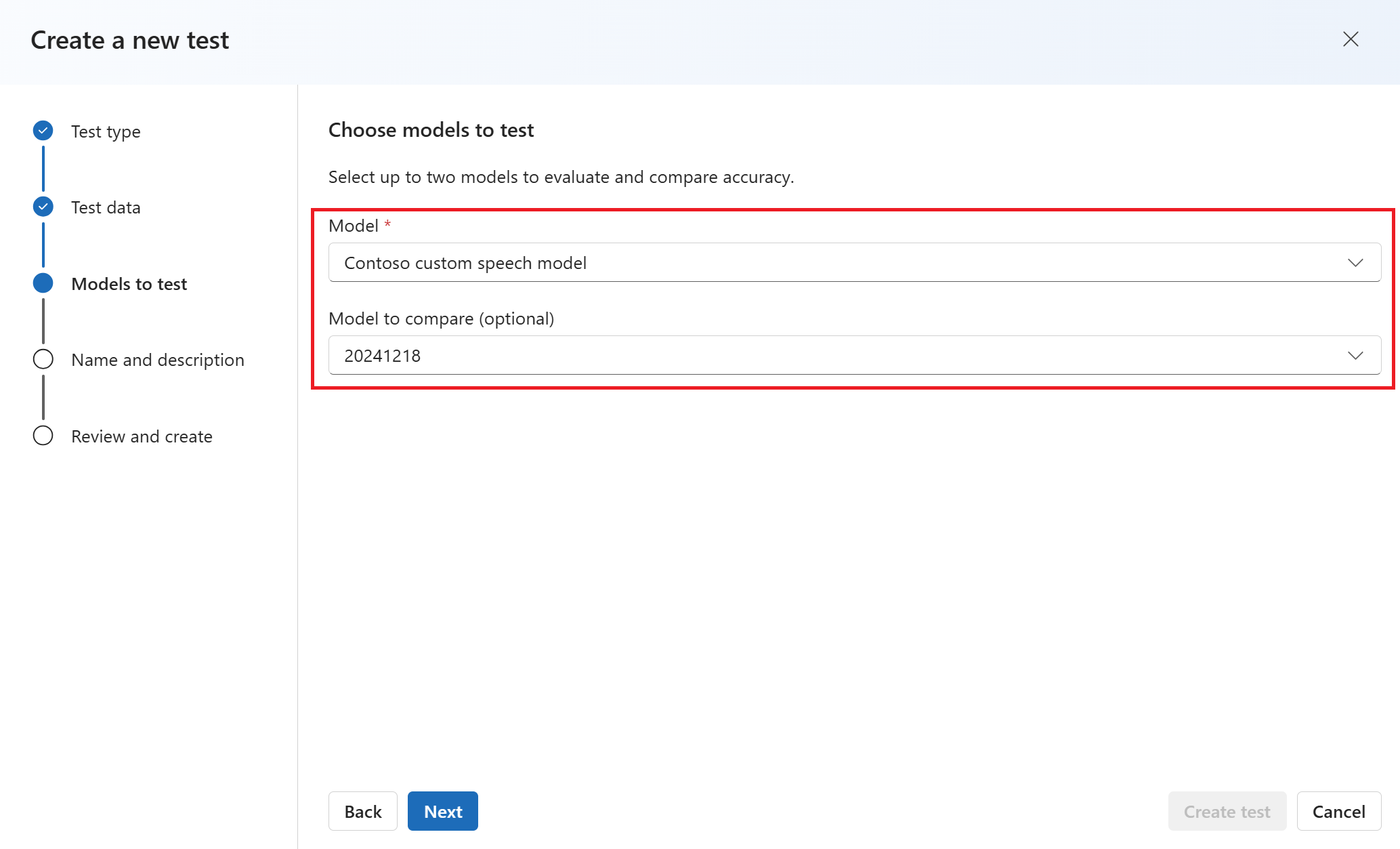
輸入測試的名稱和描述。 然後選取下一步。
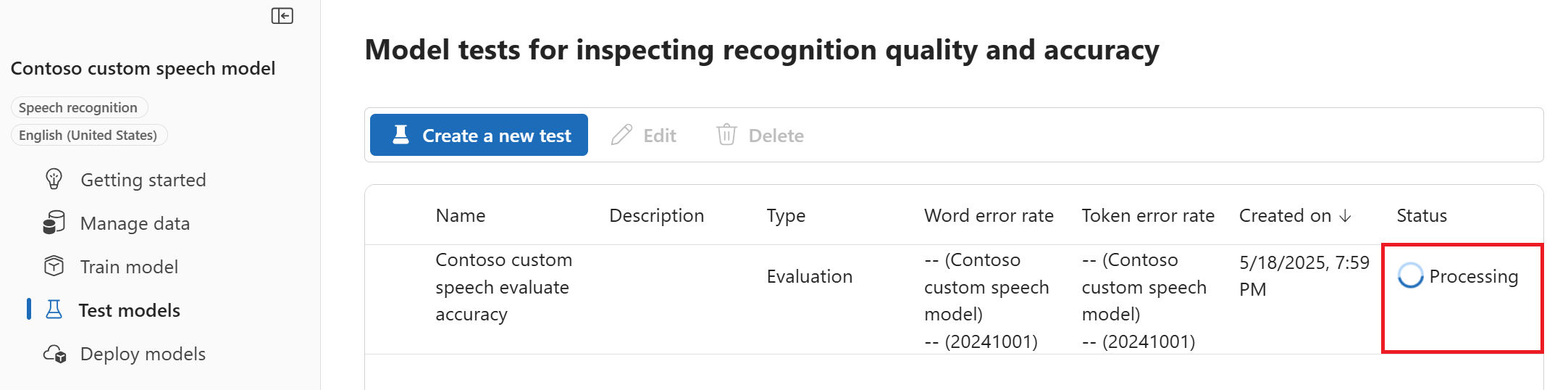
檢閱設定並選取 [建立測試]。 您會回到 [測試模型] 頁面。 資料的狀態為 [處理中]。




請遵循下列步驟來建立精確度測試:
登入 Speech Studio。
選取 [自訂語音]> 您的專案名稱 > [測試模型]。
選取 [建立新的測試]。
選取 [評估正確性]> [下一步]。
選取一個音訊 + 人工標記的轉錄資料集,然後選取 [下一步]。 如果沒有可用的資料集,請取消設定,然後移至 [語音資料集] 功能表以上傳資料集。
附註
請務必選取與您用於模型不同的原音資料集。 此方法可以提供更實際的方式來了解模型的效能。
選取最多兩個要評估的模型,然後選取 [下一步]。
輸入測試名稱和描述,然後選取 [下一步]。
檢閱測試詳細資料,然後選取 [儲存並關閉]。
繼續之前,請確定您已安裝並設定 語音 CLI 。
若要建立測試,請使用 spx csr evaluation create 命令。 根據下列指示來建構要求參數:
- 將
project屬性設定為現有項目的識別碼。 建議使用此功能project,方便你在 Microsoft Foundry 入口網站中管理自訂語音的微調。 若要取得專案識別碼,請參閱 取得 REST API 檔的專案識別碼 。 - 將必要的
model1屬性設定為您所要測試模型的識別碼。 - 將必要的
model2屬性設定為您想要測試的另一個模型的識別碼。 如果您不想比較兩個模型,請針對model1和model2使用相同的模型。 - 將所需的
dataset屬性設定為您要用於測試的資料集識別碼。 -
language設定 屬性,否則語音 CLI 預設會設定 「en-US」。 此參數應該是資料集內容的地區設定。 稍後無法變更此地區設定。 Speech CLI 的language屬性對應於 JSON 要求和回應中的locale屬性。 - 設定必要的
name屬性。 這個參數就是 Microsoft Foundry 入口網站中顯示的名稱。 Speech CLI 的name屬性對應於 JSON 要求和回應中的displayName屬性。
以下是建立測試的範例語音 CLI 命令:
spx csr evaluation create --api-version v3.2 --project aaaabbbb-0000-cccc-1111-dddd2222eeee --dataset bbbbcccc-1111-dddd-2222-eeee3333ffff --model1 ccccdddd-2222-eeee-3333-ffff4444aaaa --model2 ddddeeee-3333-ffff-4444-aaaa5555bbbb --name "My Evaluation" --description "My Evaluation Description"
重要事項
您必須設定 --api-version v3.2。 語音 CLI 使用 REST API,但尚未支援比 v3.2 更高版本。
您應該會收到下列格式的回應本文:
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/eeeeffff-4444-aaaa-5555-bbbb6666cccc",
"model1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/ddddeeee-3333-ffff-4444-aaaa5555bbbb"
},
"model2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/ddddeeee-3333-ffff-4444-aaaa5555bbbb"
},
"dataset": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/bbbbcccc-1111-dddd-2222-eeee3333ffff"
},
"transcription2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/ffffaaaa-5555-bbbb-6666-cccc7777dddd"
},
"transcription1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/ffffaaaa-5555-bbbb-6666-cccc7777dddd"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/aaaabbbb-0000-cccc-1111-dddd2222eeee"
},
"links": {
"files": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/dda6e880-6ccd-49dc-b277-137565cbaa38/files"
},
"properties": {
"wordErrorRate1": -1.0,
"sentenceErrorRate1": -1.0,
"sentenceCount1": -1,
"wordCount1": -1,
"correctWordCount1": -1,
"wordSubstitutionCount1": -1,
"wordDeletionCount1": -1,
"wordInsertionCount1": -1,
"wordErrorRate2": -1.0,
"sentenceErrorRate2": -1.0,
"sentenceCount2": -1,
"wordCount2": -1,
"correctWordCount2": -1,
"wordSubstitutionCount2": -1,
"wordDeletionCount2": -1,
"wordInsertionCount2": -1
},
"lastActionDateTime": "2024-07-14T21:31:14Z",
"status": "NotStarted",
"createdDateTime": "2024-07-14T21:31:14Z",
"locale": "en-US",
"displayName": "My Evaluation",
"description": "My Evaluation Description",
"customProperties": {
"testingKind": "Evaluation"
}
}
回應本文中最上層 self 屬性是評估的 URI。 使用此 URI 來取得專案和測試結果的詳細資料。 您也可以使用此 URI 來更新或刪除評估。
如需使用評估的語音 CLI 說明,請執行下列命令:
spx help csr evaluation
若要建立測試,請使用語音轉換文字 REST API 的 Evaluations_Create 作業。 根據下列指示來建構要求本文:
- 將
project屬性設定為現有項目的識別碼。 建議使用此功能project,方便你在 Microsoft Foundry 入口網站中管理自訂語音的微調。 若要取得專案識別碼,請參閱 取得 REST API 檔的專案識別碼 。 - 在
testingKind內將Evaluation屬性設定為customProperties。 如果您未指定Evaluation,則會將測試視為品質檢查測試。 無論testingKind屬性是否設定為Evaluation或Inspection或者未設定,你都可以透過 API 存取準確度分數,但無法在 Microsoft Foundry 入口網站中取得。 - 將必要的
model1屬性設定為您想要測試之模型的 URI。 - 將必要的
model2屬性設定為您想要測試的另一個模型的 URI。 如果您不想比較兩個模型,請針對model1和model2使用相同的模型。 - 將必要的
dataset屬性設定為您想要用於測試的資料集的 URI。 - 設定必要的
locale屬性。 此屬性應該是資料集內容的地區設定。 稍後無法變更此地區設定。 - 設定必要的
displayName屬性。 這個屬性就是 Microsoft Foundry 入口網站中顯示的名稱。
使用 URI 提出 HTTP POST 要求,如下列範例所示。 以您的語音資源金鑰取代 YourSpeechResoureKey、以您的語音資源區域取代 YourServiceRegion,並設定要求本文屬性,如前所述。
curl -v -X POST -H "Ocp-Apim-Subscription-Key: YourSpeechResoureKey" -H "Content-Type: application/json" -d '{
"model1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/ddddeeee-3333-ffff-4444-aaaa5555bbbb"
},
"model2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/ddddeeee-3333-ffff-4444-aaaa5555bbbb"
},
"dataset": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/bbbbcccc-1111-dddd-2222-eeee3333ffff"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/aaaabbbb-0000-cccc-1111-dddd2222eeee"
},
"displayName": "My Evaluation",
"description": "My Evaluation Description",
"customProperties": {
"testingKind": "Evaluation"
},
"locale": "en-US"
}' "https://YourServiceRegion.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations"
您應該會收到下列格式的回應本文:
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/eeeeffff-4444-aaaa-5555-bbbb6666cccc",
"model1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/ddddeeee-3333-ffff-4444-aaaa5555bbbb"
},
"model2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/ddddeeee-3333-ffff-4444-aaaa5555bbbb"
},
"dataset": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/bbbbcccc-1111-dddd-2222-eeee3333ffff"
},
"transcription2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/ffffaaaa-5555-bbbb-6666-cccc7777dddd"
},
"transcription1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/ffffaaaa-5555-bbbb-6666-cccc7777dddd"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/aaaabbbb-0000-cccc-1111-dddd2222eeee"
},
"links": {
"files": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/dda6e880-6ccd-49dc-b277-137565cbaa38/files"
},
"properties": {
"wordErrorRate1": -1.0,
"sentenceErrorRate1": -1.0,
"sentenceCount1": -1,
"wordCount1": -1,
"correctWordCount1": -1,
"wordSubstitutionCount1": -1,
"wordDeletionCount1": -1,
"wordInsertionCount1": -1,
"wordErrorRate2": -1.0,
"sentenceErrorRate2": -1.0,
"sentenceCount2": -1,
"wordCount2": -1,
"correctWordCount2": -1,
"wordSubstitutionCount2": -1,
"wordDeletionCount2": -1,
"wordInsertionCount2": -1
},
"lastActionDateTime": "2024-07-14T21:31:14Z",
"status": "NotStarted",
"createdDateTime": "2024-07-14T21:31:14Z",
"locale": "en-US",
"displayName": "My Evaluation",
"description": "My Evaluation Description",
"customProperties": {
"testingKind": "Evaluation"
}
}
回應本文中最上層 self 屬性是評估的 URI。 使用此 URI 來取得評估專案和測試結果的詳細資料。 您也可以使用此 URI 來更新或刪除評估。
取得測試結果
您應該取得測試結果,並評估相較於語音辨識結果的字組錯誤率 (WER)。
當測試狀態為 [成功] 時,您可以檢視結果。 選取測試以檢視結果。
遵循下列步驟來取得測試結果:
- 登入 Speech Studio。
- 選取 [自訂語音]> 您的專案名稱 > [測試模型]。
- 依測試名稱選取連結。
- 測試完成之後,如設定為 [成功] 的狀態所指出,您應該會看到結果,其中包含每個測試模型的 WER 數字。
此頁面會列出資料集中的所有語句和辨識結果,以及來自所提交資料集的轉錄。 您可以切換各種錯誤類型,包括插入、刪除和替代。 透過聆聽音訊並比較每個資料行中的辨識結果,您可以決定哪個模型符合您的需求,以及需要額外定型和改進的地方。
繼續之前,請確定您已安裝並設定 語音 CLI 。
若要取得測試結果,請使用 spx csr evaluation status 命令。 根據下列指示來建構要求參數:
- 將必要的
evaluation屬性設定為您要取得測試結果之評估的識別碼。
以下是取得測試結果的範例語音 CLI 命令:
spx csr evaluation status --api-version v3.2 --evaluation aaaabbbb-6666-cccc-7777-dddd8888eeee
重要事項
您必須設定 --api-version v3.2。 語音 CLI 使用 REST API,但尚未支援比 v3.2 更高版本。
回應本文中會傳回字組錯誤率和更多詳細資料。
您應該會收到下列格式的回應本文:
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/eeeeffff-4444-aaaa-5555-bbbb6666cccc",
"model1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/ddddeeee-3333-ffff-4444-aaaa5555bbbb"
},
"model2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/ddddeeee-3333-ffff-4444-aaaa5555bbbb"
},
"dataset": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/bbbbcccc-1111-dddd-2222-eeee3333ffff"
},
"transcription2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/ffffaaaa-5555-bbbb-6666-cccc7777dddd"
},
"transcription1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/ffffaaaa-5555-bbbb-6666-cccc7777dddd"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/aaaabbbb-0000-cccc-1111-dddd2222eeee"
},
"links": {
"files": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/dda6e880-6ccd-49dc-b277-137565cbaa38/files"
},
"properties": {
"wordErrorRate1": 0.028900000000000002,
"sentenceErrorRate1": 0.667,
"tokenErrorRate1": 0.12119999999999999,
"sentenceCount1": 3,
"wordCount1": 173,
"correctWordCount1": 170,
"wordSubstitutionCount1": 2,
"wordDeletionCount1": 1,
"wordInsertionCount1": 2,
"tokenCount1": 165,
"correctTokenCount1": 145,
"tokenSubstitutionCount1": 10,
"tokenDeletionCount1": 1,
"tokenInsertionCount1": 9,
"tokenErrors1": {
"punctuation": {
"numberOfEdits": 4,
"percentageOfAllEdits": 20.0
},
"capitalization": {
"numberOfEdits": 2,
"percentageOfAllEdits": 10.0
},
"inverseTextNormalization": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
},
"lexical": {
"numberOfEdits": 12,
"percentageOfAllEdits": 12.0
},
"others": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
}
},
"wordErrorRate2": 0.028900000000000002,
"sentenceErrorRate2": 0.667,
"tokenErrorRate2": 0.12119999999999999,
"sentenceCount2": 3,
"wordCount2": 173,
"correctWordCount2": 170,
"wordSubstitutionCount2": 2,
"wordDeletionCount2": 1,
"wordInsertionCount2": 2,
"tokenCount2": 165,
"correctTokenCount2": 145,
"tokenSubstitutionCount2": 10,
"tokenDeletionCount2": 1,
"tokenInsertionCount2": 9,
"tokenErrors2": {
"punctuation": {
"numberOfEdits": 4,
"percentageOfAllEdits": 20.0
},
"capitalization": {
"numberOfEdits": 2,
"percentageOfAllEdits": 10.0
},
"inverseTextNormalization": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
},
"lexical": {
"numberOfEdits": 12,
"percentageOfAllEdits": 12.0
},
"others": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
}
}
},
"lastActionDateTime": "2024-07-14T21:31:22Z",
"status": "Succeeded",
"createdDateTime": "2024-07-14T21:31:14Z",
"locale": "en-US",
"displayName": "My Evaluation",
"description": "My Evaluation Description",
"customProperties": {
"testingKind": "Evaluation"
}
}
如需使用評估的語音 CLI 說明,請執行下列命令:
spx help csr evaluation
若要取得測試結果,請從使用語音轉換文字 REST API 的 Evaluations_Get 作業開始。
使用 URI 提出 HTTP GET 要求,如下列範例所示。 以您的評估識別碼取代 YourEvaluationId、以您的語音資源金鑰取代 YourSpeechResoureKey,並以您的語音資源區域取代 YourServiceRegion。
curl -v -X GET "https://YourServiceRegion.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/YourEvaluationId" -H "Ocp-Apim-Subscription-Key: YourSpeechResoureKey"
回應本文中會傳回字組錯誤率和更多詳細資料。
您應該會收到下列格式的回應本文:
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/eeeeffff-4444-aaaa-5555-bbbb6666cccc",
"model1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/ddddeeee-3333-ffff-4444-aaaa5555bbbb"
},
"model2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/ddddeeee-3333-ffff-4444-aaaa5555bbbb"
},
"dataset": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/bbbbcccc-1111-dddd-2222-eeee3333ffff"
},
"transcription2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/ffffaaaa-5555-bbbb-6666-cccc7777dddd"
},
"transcription1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/ffffaaaa-5555-bbbb-6666-cccc7777dddd"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/aaaabbbb-0000-cccc-1111-dddd2222eeee"
},
"links": {
"files": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/dda6e880-6ccd-49dc-b277-137565cbaa38/files"
},
"properties": {
"wordErrorRate1": 0.028900000000000002,
"sentenceErrorRate1": 0.667,
"tokenErrorRate1": 0.12119999999999999,
"sentenceCount1": 3,
"wordCount1": 173,
"correctWordCount1": 170,
"wordSubstitutionCount1": 2,
"wordDeletionCount1": 1,
"wordInsertionCount1": 2,
"tokenCount1": 165,
"correctTokenCount1": 145,
"tokenSubstitutionCount1": 10,
"tokenDeletionCount1": 1,
"tokenInsertionCount1": 9,
"tokenErrors1": {
"punctuation": {
"numberOfEdits": 4,
"percentageOfAllEdits": 20.0
},
"capitalization": {
"numberOfEdits": 2,
"percentageOfAllEdits": 10.0
},
"inverseTextNormalization": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
},
"lexical": {
"numberOfEdits": 12,
"percentageOfAllEdits": 12.0
},
"others": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
}
},
"wordErrorRate2": 0.028900000000000002,
"sentenceErrorRate2": 0.667,
"tokenErrorRate2": 0.12119999999999999,
"sentenceCount2": 3,
"wordCount2": 173,
"correctWordCount2": 170,
"wordSubstitutionCount2": 2,
"wordDeletionCount2": 1,
"wordInsertionCount2": 2,
"tokenCount2": 165,
"correctTokenCount2": 145,
"tokenSubstitutionCount2": 10,
"tokenDeletionCount2": 1,
"tokenInsertionCount2": 9,
"tokenErrors2": {
"punctuation": {
"numberOfEdits": 4,
"percentageOfAllEdits": 20.0
},
"capitalization": {
"numberOfEdits": 2,
"percentageOfAllEdits": 10.0
},
"inverseTextNormalization": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
},
"lexical": {
"numberOfEdits": 12,
"percentageOfAllEdits": 12.0
},
"others": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
}
}
},
"lastActionDateTime": "2024-07-14T21:31:22Z",
"status": "Succeeded",
"createdDateTime": "2024-07-14T21:31:14Z",
"locale": "en-US",
"displayName": "My Evaluation",
"description": "My Evaluation Description",
"customProperties": {
"testingKind": "Evaluation"
}
}
評估字組錯誤率 (WER)
測量模型正確性的產業標準是字組錯誤率 (WER)。 WER 會計算辨識期間所識別的錯誤字組數目,並將總和除以人工標記的轉錄 (N) 中提供的字組總數。
未正確識別的字組分為三種類別:
- 插入 (I):未在假設轉錄內容中正確新增的字組
- 刪除 (D):未在假設轉錄內容中偵測到的字組
- 替代 (S):已在參考和假設之間替代的字組
在 Microsoft Foundry 入口網站 和 Speech Studio 中,商數會乘以 100 並以百分比顯示。 語音 CLI 和 REST API 結果不會乘以 100。
$$ WER = {{I+D+S} N}\over\times 100 $$
以下範例顯示相較於與人工標記的轉錄,未正確識別的字組:

語音辨識結果可能發生如下錯誤:
- 插入 (I):已新增字組 "a"
- 刪除 (D):已刪除字組 "are"
- 替代 (S):已將 "Jones" 字組替代為 "John"
前述範例的字組錯誤率是 60%。
如果您想要在本機複寫 WER 測量,您可以使用 NIST 評分工具組 (SCTK) 提供的 sclite 工具。
解決錯誤並改善 WER
您可以使用機器辨識結果中的 WER 計算,來評估與應用程式、工具或產品搭配使用的模型品質。 5-10% 的 WER 被視為品質良好,並可立即使用。 20% 的 WER 是可接受的,但您可能會想要考慮其他定型。 30% 以上的 WER 表示品質不佳,需要自訂和定型。
錯誤的分佈方式很重要。 遇到許多刪除錯誤時,通常是由於弱式音訊信號強度所致。 若要解決此問題,您必須收集接近來源的音訊資料。 插入錯誤表示音訊是在嘈雜的環境中錄製,並且可能存在串音,從而導致辨識問題。 當提供了不足的網域特定字詞範例,作為人工標記的轉錄內容或相關文字時,通常會遇到替代錯誤。
藉由分析個別檔案,您可以判斷哪種類型的錯誤存在,以及哪些錯誤是特定檔案特有的。 了解檔案層級的問題可協助您設定改善的目標。
評估權杖錯誤率 (TER)
除了文字錯誤率之外,您也可以使用權杖錯誤率 (TER) 的延伸測量來評估最終端對端顯示格式的品質。 除了語彙格式 (That will cost $900. 而非 that will cost nine hundred dollars),TER 還會考慮標點符號、大寫和 ITN 等顯示格式層面。 深入了解使用語音轉換文字顯示輸出格式設定。
TER 會計算辨識期間所識別的錯誤權杖數目,並將總和除以人工標記的轉錄 (N) 中提供的權杖總數。
$$ TER = {{I+D+S} N}\over\times 100 $$
TER 計算的公式也類似於 WER。 唯一的差別在於 TER 是根據權杖層級而不是字組層級來計算。
- 插入 (I):未在假設轉錄內容中正確新增的權杖
- 刪除 (D):未在假設轉錄內容中偵測到的權杖
- 替代 (S):已在參考和假設之間替代的權杖
在真實案例中,您可以分析 WER 和 TER 結果,以取得所需的改善。
附註
若要測量 TER,您必須確定音訊 + 文字記錄測試資料包含顯示格式的文字記錄,例如標點符號、大寫和 ITN。
範例案例結果
語音辨識案例會依音訊品質和語言 (詞彙和說話風格) 而有所不同。 下表將檢查四個常見的案例:
| 狀況 | 音訊品質 | 詞彙 | 說話風格 |
|---|---|---|---|
| 客服中心 | 低,8 kHz,可能是 1 個音訊通道上有 2 個人,可以壓縮 | 狹隘,網域和產品特有的 | 對話,結構鬆散 |
| 語音助理,例如 Cortana 或快速視窗 | 高,16 kHz | 大量實體 (歌曲名稱、產品、位置) | 清楚陳述的字組和片語 |
| 聽寫 (即時訊息、筆記、搜尋) | 高,16 kHz | 各式各樣 | 做筆記 |
| 影片隱藏式輔助字幕 | 各式各樣,包括不同的麥克風使用、添加的的音樂 | 各式各樣,來自會議、朗誦演講、音樂歌詞 | 閱讀、準備或結構鬆散 |
不同的案例會產生不同的品質結果。 下表會檢查這四個案例中的內容如何以 WER 進行評估。 此表格顯示每個案例中最常見的錯誤類型。 插入、替代和刪除錯誤率可協助您判斷要新增哪些資料類型來改善模型。
| 狀況 | 語音辨識品質 | 插入錯誤 | 刪除錯誤 | 替代錯誤 |
|---|---|---|---|---|
| 客服中心 | 中 (< 30% WER) |
低,但其他人在背景中交談時除外 | 可以很高。 話務中心可能嘈雜,而且重疊的喇叭可能會使模型混淆 | 中。 產品和人名可能會導致這些錯誤 |
| 語音助理 | 高 (可以是 < 10% WER) |
低 | 低 | 中,因為歌名、產品名稱或位置 |
| 聽寫 | 高 (可以是 < 10% WER) |
低 | 低 | 高 |
| 影片隱藏式輔助字幕 | 取決於影片類型 (可以是 < 50% WER) | 低 | 由於音樂、噪音、麥克風品質,因此可能很高 | Jargon 可能會導致這些錯誤 |