什麼是關鍵詞辨識?
關鍵詞辨識會偵測音訊數據流內的單字或短詞組。 這項技術也稱為關鍵詞找出。
關鍵詞辨識最常見的使用案例是虛擬助理的語音啟用。 例如,“Hey Cortana” 是 Cortana 助理的關鍵詞。 在辨識關鍵詞時,會執行案例特定的動作。針對虛擬助理案例,常見的結果動作是關鍵詞後面的音訊語音識別。
一般而言,虛擬助理一律會接聽。 關鍵詞辨識可作為用戶的隱私權界限。 關鍵詞需求可作為防止不相關的用戶音訊跨越本機裝置到雲端的閘道。
為了平衡精確度、延遲和計算複雜度,關鍵詞辨識會實作為多階段系統。 對於第一個以外的所有階段,只有在音訊之前階段辨識感興趣的關鍵詞時,才會處理音訊。
目前的系統是使用跨越邊緣和雲端的多個階段所設計:
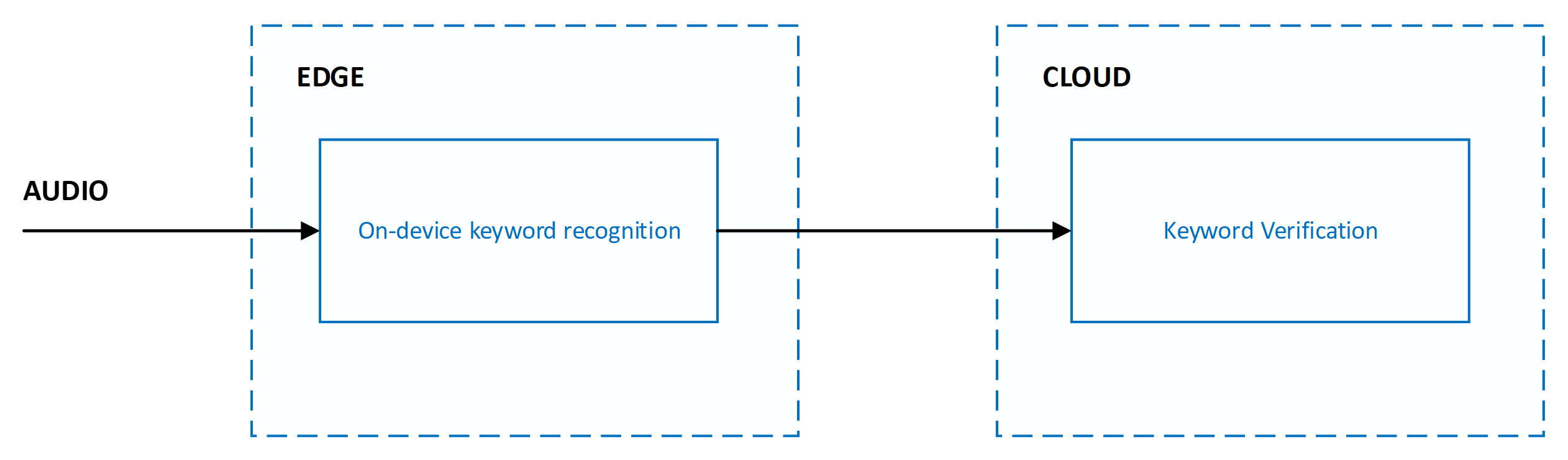
關鍵詞辨識的正確性是透過下列計量來測量:
- 正確接受率:測量系統在用戶說話時辨識關鍵詞的能力。 正確的接受率也稱為真正率。
- 誤接受率:測量系統篩選出不是使用者口說關鍵詞的音訊的能力。 False 接受率也稱為誤判率。
目標是將正確的接受率最大化,同時將 False 接受率降至最低。 目前的系統是設計來偵測關鍵詞或詞組前面有少量的無聲。 不支援偵測句子或語句中間的關鍵詞。
裝置型號的自定義關鍵詞
使用Speech Studio上的自訂關鍵字入口網站,您可以指定任何單字或簡短片語,以產生在邊緣執行的關鍵詞辨識模型。 您可以選擇正確的發音,進一步個人化關鍵詞模型。
定價
使用自定義關鍵詞來產生模型不需要任何成本,包括基本和進階模型。 搭配語音轉換文字等其他語音服務功能使用時,使用語音 SDK 在裝置上執行模型也不需要任何成本。
模型類型
您可以使用自定義關鍵詞,為任何關鍵詞產生兩種類型的裝置上模型。
| 模型類型 | 描述 |
|---|---|
| 基本 | 最適合示範或快速原型設計用途。 模型會以通用基底模型產生,最多可能需要 15 分鐘的時間才能就緒。 模型可能沒有最佳精確度特性。 |
| 進階 | 最適合用於產品整合目的。 模型是透過使用模擬定型數據來調整通用基底模型來產生,以改善精確度特性。 模型最多可能需要 48 小時的時間才能準備好。 |
注意
您可以在關鍵字辨識區域支援檔案中檢視支援進階模型類型的區域清單。
這兩種模型類型都不需要您上傳定型數據。 自定義關鍵詞會完整處理數據產生和模型定型。
發音
當您建立新的模型時,自定義關鍵詞會自動產生所提供關鍵詞的可能發音。 您可以接聽每個發音,並選擇最接近您預期使用者說關鍵詞方式的所有變化。 不應該選取所有其他發音。
請務必仔細考慮您選取的發音,以確保最佳的正確性特性。 例如,如果您選擇的發音比您需要的更多,您可能會得到較高的 false 接受率。 如果您選擇的發音太少,其中未涵蓋所有預期的變化,您可能會得到較低的正確接受率。
測試模型
自定義關鍵詞產生裝置上的模型之後,即可直接在入口網站上測試模型。 您可以使用入口網站直接進入瀏覽器並取得關鍵字辨識結果。
關鍵字驗證
關鍵詞驗證是一種雲端服務,可減少從在 Azure 上執行健全模型的裝置模型接受 false 的效果。 關鍵詞驗證不需要微調或定型,即可使用您的關鍵詞。 累加模型更新會持續部署到服務,以改善精確度和延遲,而且對用戶端應用程式而言是透明的。
定價
關鍵字驗證一律會與語音轉換文字合併使用。 除了語音轉換文字的成本之外,使用關鍵字驗證不需要任何費用。
關鍵字驗證和語音轉換文字
使用關鍵字驗證時,一律會與語音轉換文字合併使用。 這兩個服務會以平行方式執行,這表示音訊會傳送至這兩個服務以進行同時處理。
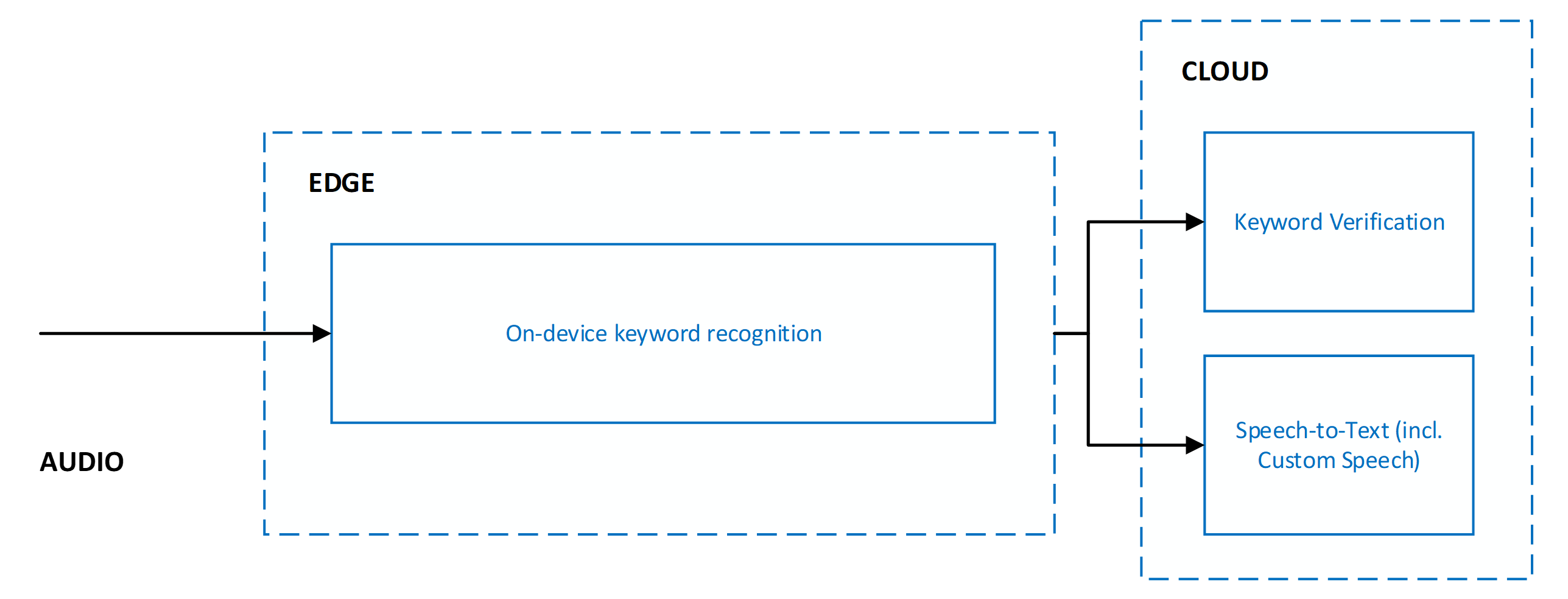
以平行方式執行關鍵字驗證和語音轉換文字會產生下列優點:
- 語音轉換文字結果沒有其他延遲:平行執行表示關鍵字驗證不會增加延遲。 用戶端照樣能迅速收到語音轉換文字的結果。 如果關鍵字驗證判斷關鍵字不存在於音訊中,則會終止語音轉換文字處理。 此動作可防止不必要的語音轉換文字處理。 網路和雲端模型處理會增加使用者感知的語音啟用延遲。 如需詳細資訊,請參閱 建議 和指導方針。
- 語音轉換文字結果中的強制關鍵字前置詞:語音轉換文字處理可確保傳送至用戶端的結果前面會加上關鍵字。 此行為可提高遵循關鍵字語音的語音轉換文字結果中的正確性。
- 增加語音轉換文字的逾時:由於音訊開頭有預期的關鍵字,語音轉換文字可讓您在決定語音結束和終止語音轉換文字處理之前,在關鍵字之後最多五秒鐘的較長暫停。 此行為可確保已針對分段命令(關鍵詞暫停><命令>)和鏈結命令(<<關鍵詞<>><命令>)正確處理用戶體驗。
關鍵詞驗證回應和延遲考慮
針對服務的每個要求,關鍵詞驗證會傳回兩個回應的其中一個:已接受或拒絕。 處理延遲會根據關鍵詞的長度和預期包含 關鍵詞的音訊區段長度而有所不同。 處理延遲不包含用戶端與語音服務之間的網路成本。
| 關鍵詞驗證回應 | 描述 |
|---|---|
| 已接受 | 表示服務認為關鍵詞存在於作為要求一部分提供的音訊數據流中。 |
| 已拒絕 | 表示服務認為關鍵詞不存在於要求中提供的音訊數據流中。 |
拒絕的案例通常會產生較高的延遲,因為服務處理的音訊比接受的案例還多。 根據預設,關鍵詞驗證會處理最多兩秒的音訊來搜尋關鍵詞。 如果在兩秒內找不到 關鍵詞,服務就會逾時,併發出拒絕回應給客戶端的訊號。
從自定義關鍵詞搭配裝置上的模型使用關鍵詞驗證
語音 SDK 可透過關鍵字驗證和語音轉換文字,順暢地使用藉由自訂關鍵字產生的裝置上模型。 它會以透明方式處理:
- 根據裝置上模型的結果,對關鍵詞驗證和語音辨識進行音訊檢查。
- 將 關鍵詞傳達至關鍵詞驗證。
- 將更多元數據傳達至雲端,以協調端對端案例。
您不需要明確指定任何組態參數。 所有必要的信息都會從自定義關鍵詞產生的裝置上模型自動擷取。
此處連結的範例和教學課程示範如何使用語音 SDK:
語音 SDK 整合和案例
語音 SDK 可讓您輕鬆使用使用自定義關鍵詞和關鍵詞驗證所產生的個人化裝置上關鍵詞辨識模型。 為了確保您的產品需求可以符合,SDK 支援下列兩個案例:
| 案例 | 描述 | 範例 |
|---|---|---|
| 使用語音轉換文字進行端對端關鍵字辨識 | 最適合使用自定義裝置上關鍵詞模型的產品,其中包含關鍵詞驗證和語音轉換文字。 此案例最常見。 | |
| 離線關鍵詞辨識 | 最適合沒有網路連線能力的產品,這些產品使用自定義關鍵詞的自定義裝置上關鍵詞模型。 |