疑難排解 Azure Databricks 中的效能瓶頸
注意
本文依賴 GitHub 上託管的開源程式庫:https://github.com/mspnp/spark-monitoring。
原始程式庫支援 Azure Databricks Runtimes 10.x (Spark 3.2.x) 及更早版本。
Databricks 已在 l4jv2 分支上提供了更新版本以支援 Azure Databricks Runtimes 11.0 (Spark 3.3.x) 及以上版本:https://github.com/mspnp/spark-monitoring/tree/l4jv2。
請注意,由於 Databricks Runtime 使用不同的記錄系統,11.0 版本無法與舊版相容。 請務必針對 Databricks Runtime 使用正確的版本。 該程式庫和 GitHub 存放庫處於維護模式。 沒有進一步發行的計劃,並且將盡力提供問題支援。 有關用於監視和記錄 Azure Databricks 環境程式庫或路線圖的其他問題,請聯絡 azure-spark-monitoring-help@databricks.com。
本文介紹如何使用監視儀表板來尋找 Azure Databricks 上 Spark 作業的效能瓶頸。
Azure Databricks 是一項以 Apache Spark 為基礎的分析服務,可輕鬆快速開發和部署巨量資料分析。 在執行生產 Azure Databricks 工作負載時,監視和排除效能問題至關重要。 若要找出常見的效能問題,使用根據遙測資料的監控視覺效果會很有幫助。
必要條件
若要設定本文中所示的 Grafana 儀表板:
使用 Azure Databricks 監視程式庫設定 Databricks 叢集,以將遙測資料傳送至 Log Analytics 工作區。 有關詳細資訊,請參閱「GitHub 讀我檔案」。
在虛擬機器中部署 Grafana。 如需詳細資訊,請參閱「使用儀表板視覺化 Azure Databricks 指標」。
部署的 Grafana 儀表板包括一組時間序列視覺效果。 每個圖表都是與 Apache Spark 作業、作業階段,以及構成每個階段的工作相關的指標時間序列圖。
Azure Databricks 效能概觀
Azure Databricks 是以 Apache Spark 為基礎,其為一般用途的分散式運算系統。 應用程式程式碼,又稱為作業,會在 Apache Spark 叢集上執行,由叢集管理器進行協調。 一般來說,作業是最高等級的計算單位。 作業代表 Spark 應用程式執行的完整操作。 典型的操作包括從來源讀取資料、套用資料轉換,以及將結果寫入儲存體或另一個目的地。
工作分為幾個階段。 作業會按順序推進各個階段,這代表後面的階段必須等待前面的階段完成。 階段包含可以在 Spark 叢集的多個節點上並行執行的相同工作群組。 工作是在資料子集上發生的最細粒度的執行單元。
接下來的部分介紹了一些對於效能故障排除有用的儀表板視覺效果。
作業和階段延遲
作業延遲是作業執行從開始到完成的持續時間。 它會顯示為每個叢集和應用程式識別碼的作業執行的百分位數,以允許極端值的視覺效果。 下圖顯示了第 90 個百分位數達到 50 秒的作業歷史記錄,儘管第 50 個百分位數一直在 10 秒左右。
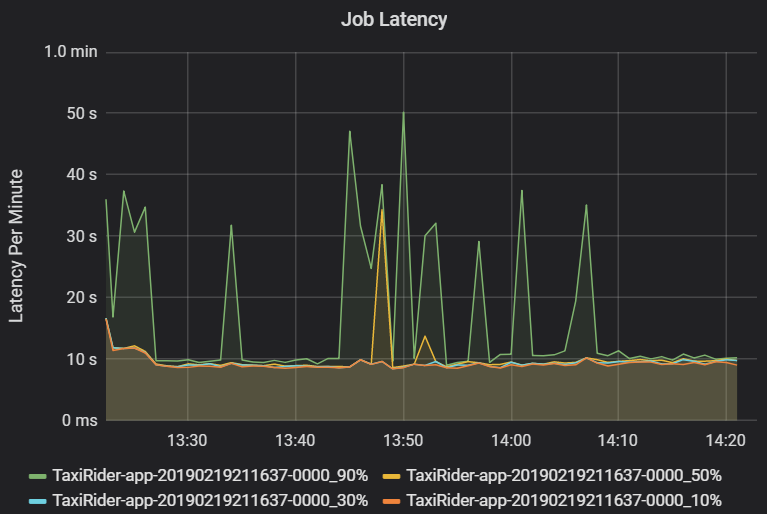
按照叢集和應用程式調查作業執行情況,尋找延遲峰值。 一旦找出出具有高延遲的叢集和應用程式,就可以繼續調查階段延遲。
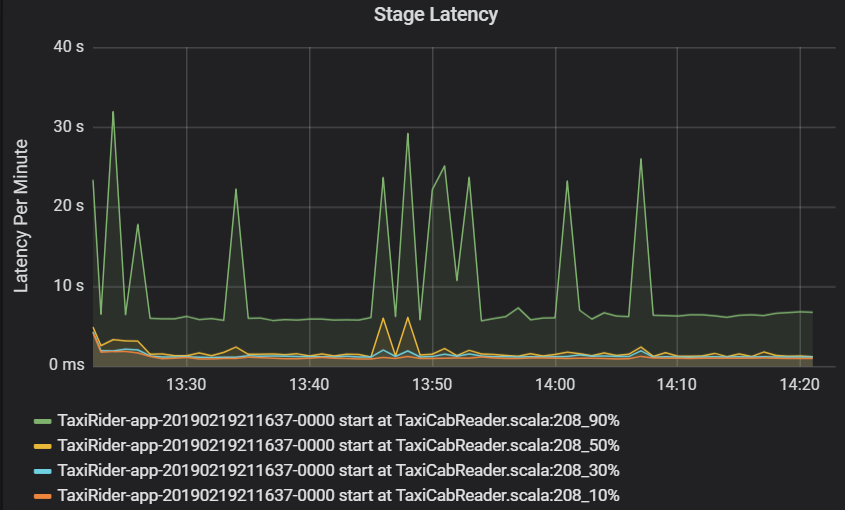
階段延遲也會以百分位數顯示,以便視覺化極端值。 階段延遲根據叢集、應用程式和階段名稱進行分類。 在圖表中找出工作延遲的尖峰,以確定哪些工作阻礙了階段的完成。
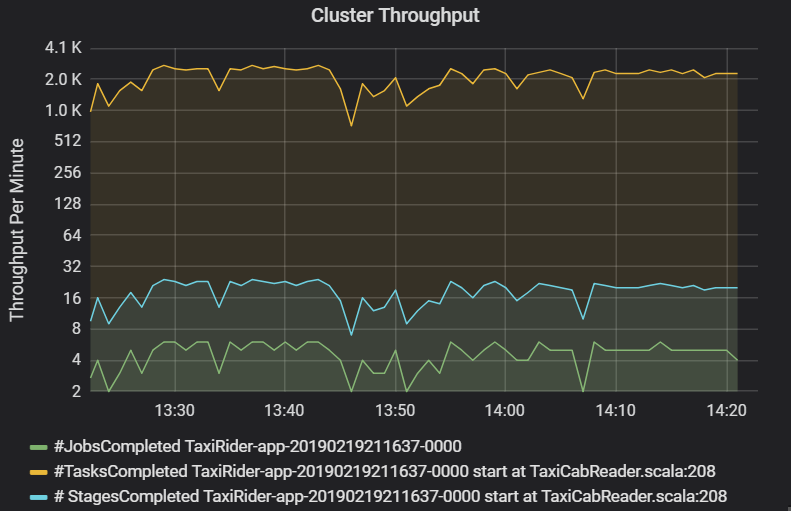
叢集輸送量圖表會顯示每分鐘完成的作業、階段和工作數量。 這有助於您了解每個作業的相對階段和工作數量,從而掌握工作負載。 在這裡,您可以看到每分鐘的作業數量在 2 到 6 之間,而階段數量約為每分鐘 12 - 24 個。
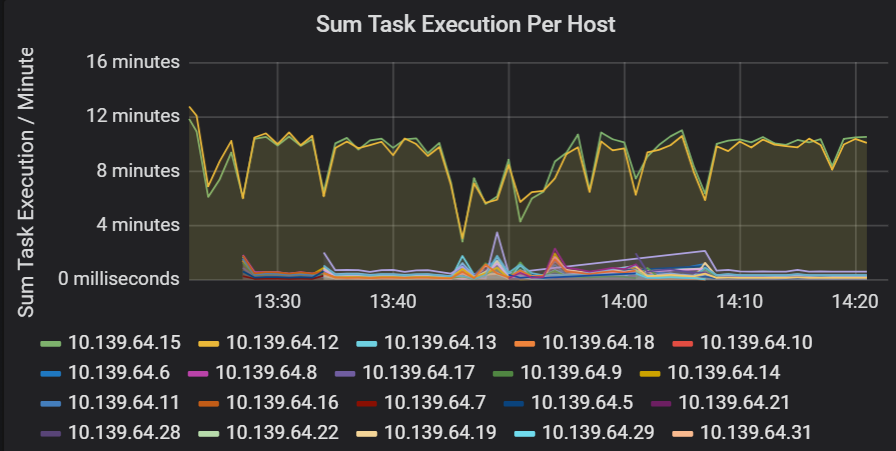
工作執行延遲的總和
此視覺效果顯示叢集上每個主機的工作執行延遲總和。 使用此圖表可以偵測由於叢集上的主機速度減慢,或每個執行程式的工作分配不當而導致執行緩慢的工作。 在下圖中,大多數主機的總時間約為 30 秒。 然而,其中兩個主機的總和約在 10 分鐘左右。 主機執行緩慢或每個執行程式的工作數量分配不當。
每個執行程式的工作數量表明,有兩個執行程式分配的工作數量不成比例,導致瓶頸。
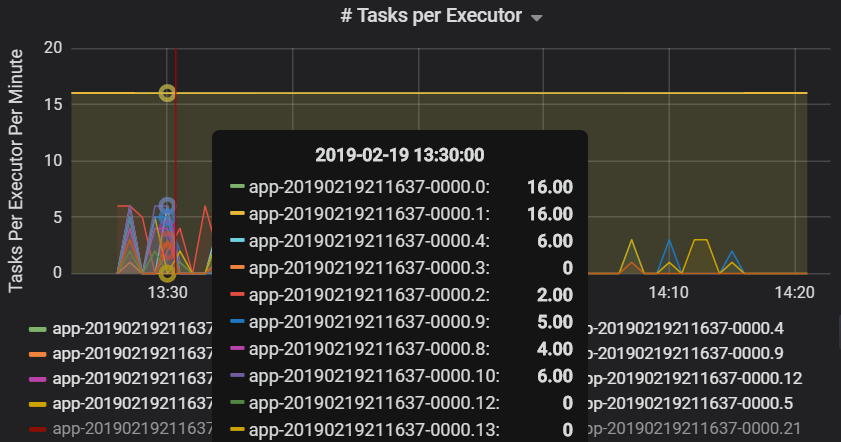
每個階段的工作指標
工作指標視覺效果顯示了工作執行的成本明細。 你可以使用它來查看在序列化和還原序列化等工作上花費的相對時間。 這些資料可能會顯示最佳化的機會,例如,透過使用廣播變數來避免傳送資料。 工作指標還顯示工作的隨機資料大小,以及隨機讀取和寫入時間。 如果這些值很高,則表示大量資料正在網路上傳輸。
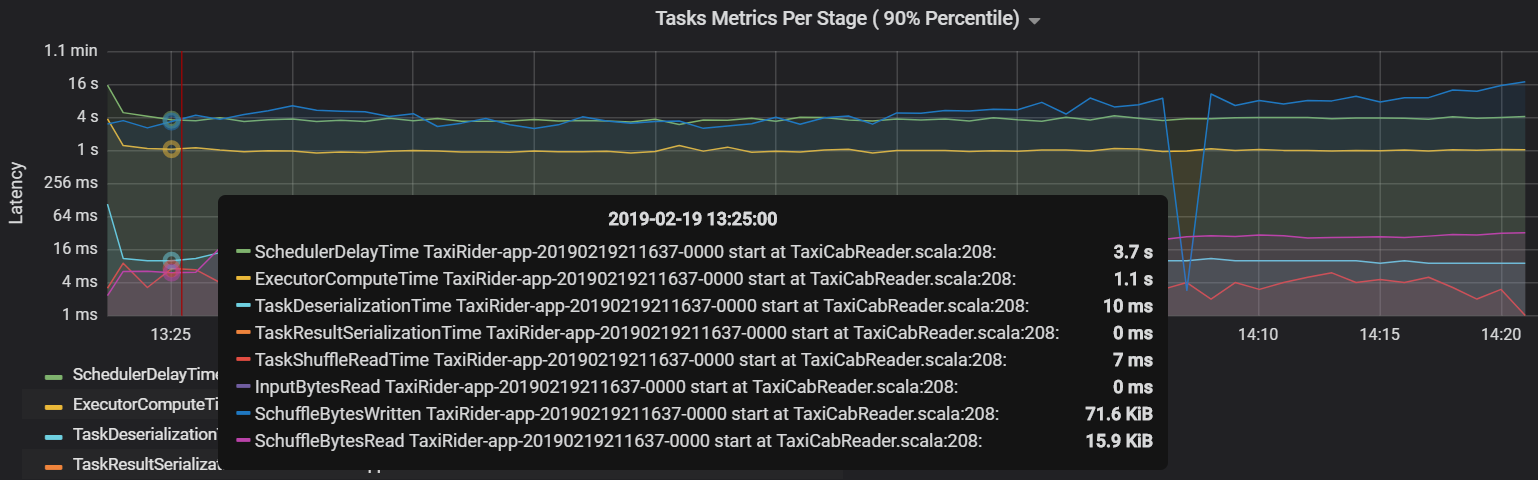
另一個工作指標是排程器延遲,它會衡量排程工作所需的時間。 理想情況下,與執行程式計算時間 (實際執行工作所花費的時間) 相比,該值應該較低。
下圖顯示了超過執行程式計算時間 (1.1 秒) 的排程器延遲時間 (3.7 秒)。 這代表等待排程工作的時間比實際工作的時間還要多。
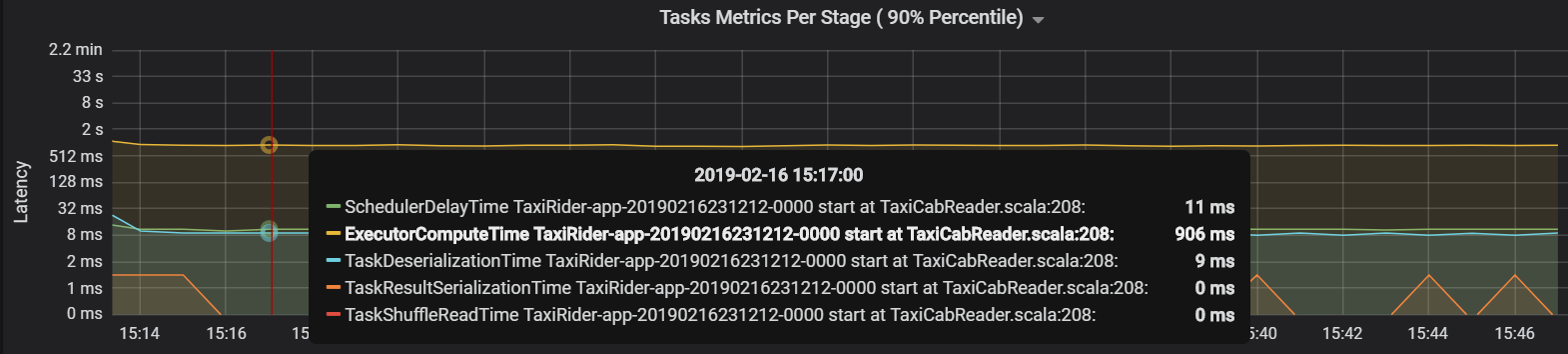
在這種情況下,問題是由於分區太多而導致了大量的額外負荷。 減少分區數量可以降低排程器延遲時間。 下圖顯示大部分時間都花在執行工作上。
串流輸送量和延遲
串流輸送量與結構化串流直接相關。 有兩個與串流輸送量相關的重要指標:每秒輸入列數和每秒處理列數。 如果每秒輸入列數超過每秒處理列數,則表示串流處理系統落後。 此外,如果輸入資料來自「事件中樞」或 Kafka,則每秒輸入列數應與前端的資料擷取速率保持一致。
兩個作業可能具有相似的叢集輸送量,但串流指標卻截然不同。 以下螢幕擷取畫面顯示了兩種不同的工作負載。 它們在叢集輸送量 (每分鐘的工作、階段和工作數量) 方面相似。 但第二次執行的處理速度為每秒 12,000 列,而第一次為每秒 4,000 列。
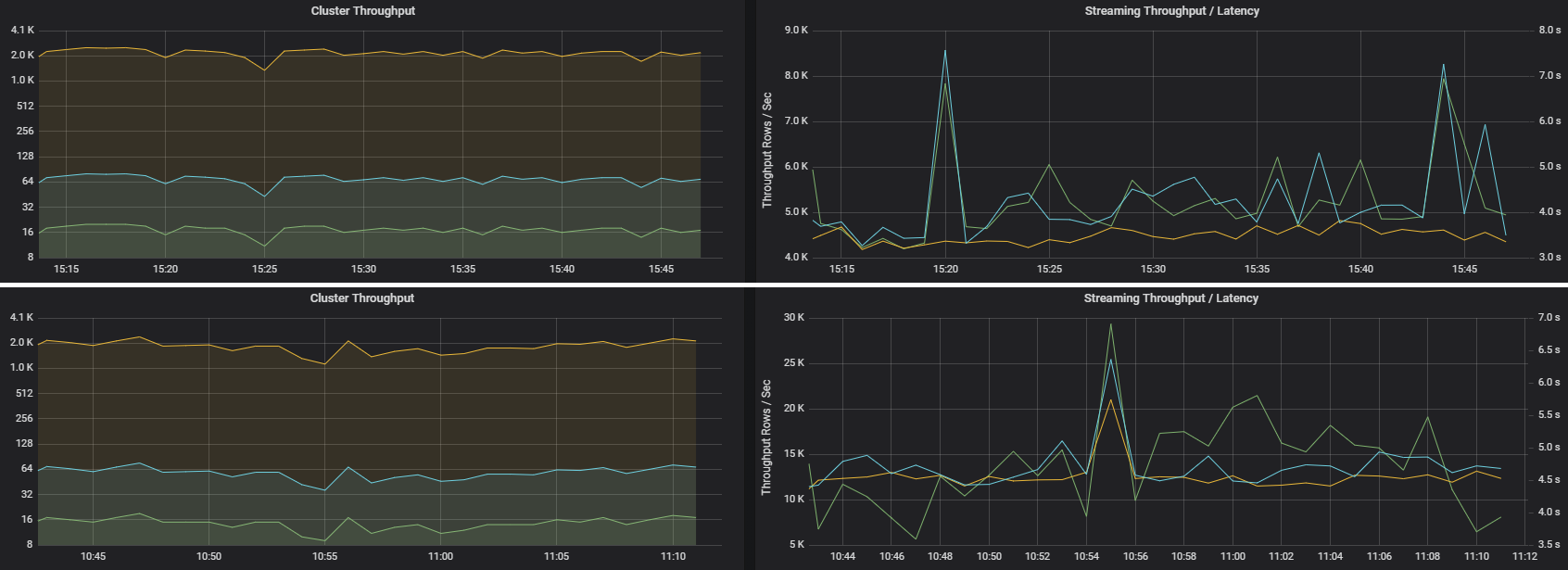
串流輸送量通常比叢集輸送量更能反映業務指標,因為它衡量的是已處理的資料記錄數量。
每個執行程式的資源使用量
這些指標有助於了解每個執行程式執行的工作。
百分比指標衡量執行程式在各種事務上花費的時間,並以所花費的時間與執行程式總體計算時間的比例表示。 計量包括:
- % 序列化時間
- % 還原序列化時間
- % CPU 執行程式時間
- % JVM 時間
這些視覺效果顯示了每個指標對整體執行程式處理的貢獻程度。
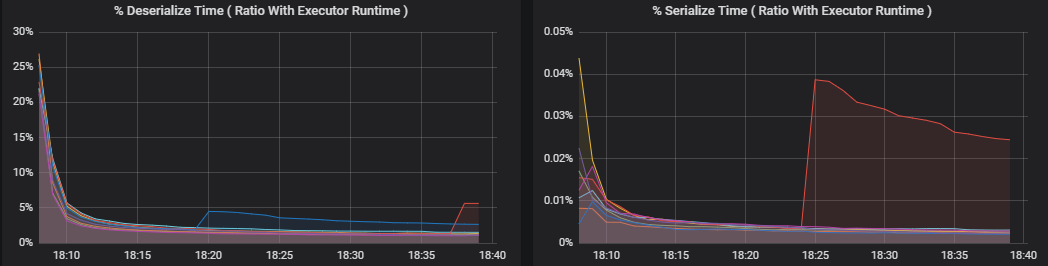
隨機指標是與執行程式之間的隨機打亂資料相關的指標。
- 隨機 I/O
- 隨機記憶體
- 檔案系統使用量
- 磁碟使用量
常見的效能瓶頸
Spark 中兩個常見的效能瓶頸是工作落後者和非最佳隨機分區計數。
工作落後者
作業中的各階段會循序執行 (較早的階段會阻礙之後的階段)。 如果有一項工作執行隨機分割區的速度較其他工作緩慢,則叢集中的所有工作都必須等待緩慢的工作趕上,階段才能結束。 發生這種情況的原因如下:
主機或主機群組執行速度緩慢。 症狀:工作、階段或作業延遲較高,叢集輸送量較低。 每個主機的工作延遲總和不會均勻分佈。 然而,資源使用量將均勻分佈在執行程式之間。
工作需要執行昂貴的彙總 (資料扭曲)。 症狀:工作延遲高、階段延遲高、作業延遲高或叢集輸送量低,但每個主機的延遲總和分佈均勻。 資源使用量將均勻分佈在執行程式之間。
如果分區大小不等,較大的分區可能會導致工作執行不平衡 (分區扭曲)。 症狀:該執行程式的資源使用量比叢集上執行的其他執行程式較高。 在該執行程式上執行的所有工作都將變得緩慢,並阻礙管道中的階段執行。 這些階段稱為階段障礙。
非最佳的隨機分區數量。
在結構化串流處理查詢中,將工作指派給執行程式對於叢集來說是一項資源密集型操作。 如果隨機資料不是最佳大小,則工作的延遲量將會對輸送量和延遲產生負面影響。 如果分區太少,叢集中的核心將無法充分利用,從而導致處理效率低下。 相反,如果分區太多,少量工作就會產生大量的管理額外負荷。
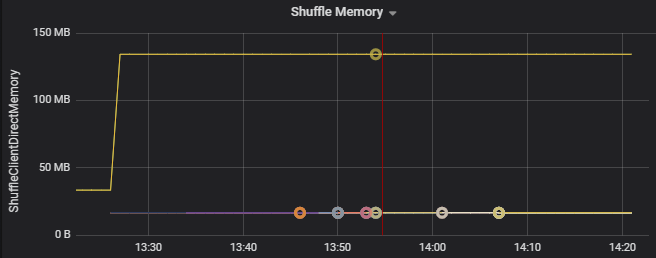
使用資源使用量指標來解決叢集上執行程式的分區扭曲和錯誤分配問題。 如果某個分區扭曲,則該執行程式的資源使用量將會高於叢集上執行的其他執行程式。
例如,以下圖表顯示前兩個執行程式的隨機記憶體使用量,是其他執行程式的 90 倍。
下一步
- 在 Azure Log Analytics 工作區中監視 Azure Databricks
- 學習途徑:使用 Azure Databricks 建立和操作機器學習解決方案
- Azure Databricks 文件
- Azure 監視器概觀