本文提供針對自動化駕駛系統開發離線數據作業和數據管理 (DataOps) 的解決方案和指引。 DataOps 解決方案是以自主車輛作業 (AVOps) 設計指南中所述的架構為基礎所建置。 DataOps 是AVOps的其中一個建置組塊。 其他建置組塊包括機器學習作業 (MLOps)、驗證作業 (ValOps)、DevOps 和集中式 AVOps 函式。
Apache、Apache® Spark 和 Apache Parquet 是 美國 和/或其他國家/地區的 Apache Software Foundation 註冊商標或商標。 Apache Software Foundation 不會隱含使用這些標記。
架構

資料流程
測量數據源自車輛的數據流。 來源包括相機、車輛遙測和雷達、超聲波和雷射雷達感測器。 車輛中的數據記錄器會將測量數據儲存在記錄器儲存裝置上。 記錄器記憶體數據會上傳至登陸數據湖。 Azure 數據箱或 Azure Stack Edge 之類的服務,或 Azure ExpressRoute 之類的專用聯機會將數據內嵌至 Azure。 以下列格式測量數據位於 Azure Data Lake 儲存體:測量數據格式第 4 版(MDF4)、技術數據管理系統 (TDMS) 和 rosbag。 上傳的數據會輸入名為 Landing 的專用記憶體帳戶,該帳戶會指定用來接收和驗證數據。
Azure Data Factory 管線會依排程的間隔觸發,以處理登陸記憶體帳戶中的數據。 管線會處理下列步驟:
- 執行數據品質檢查,例如總和檢查碼。 此步驟會移除低質量的數據,讓只有高質量數據通過下一個階段。 Azure App 服務 可用來執行質量檢查碼。 視為不完整的數據會封存以供日後處理。
- 針對歷程追蹤,請使用App Service呼叫元數據 API。 此步驟會更新儲存在 Azure Cosmos DB 中的元數據,以建立新的數據流。 針對每個度量,會有原始數據流。
- 將數據複製到 Data Lake 儲存體 中名為 Raw 的記憶體帳戶。
- 呼叫元數據 API,將數據流標示為完整,讓其他元件和服務可以取用數據流。
- 封存度量,並從登陸記憶體帳戶中移除它們。
Data Factory 和 Azure Batch 會處理原始區域中的數據,以擷取下游系統可取用的資訊:
- Batch 會從源檔中的主題讀取數據,並將數據輸出至個別資料夾中選取的主題。
- 由於原始區域中的檔案大小可能超過 2 GB,因此會在每個檔案上執行平行處理擷取函式。 這些功能會擷取圖像處理、雷射雷達、雷達和 GPS 數據。 它們也會執行元數據處理。 Data Factory 和 Batch 提供一種方式,以可調整的方式執行平行處理原則。
- 數據會向下取樣,以減少需要加上標籤和批註的數據量。
如果來自車輛記錄器的數據未跨各種感測器同步處理,則會觸發 Data Factory 管線來同步處理數據以建立有效的數據集。 同步處理演算法會在 Batch 上執行。
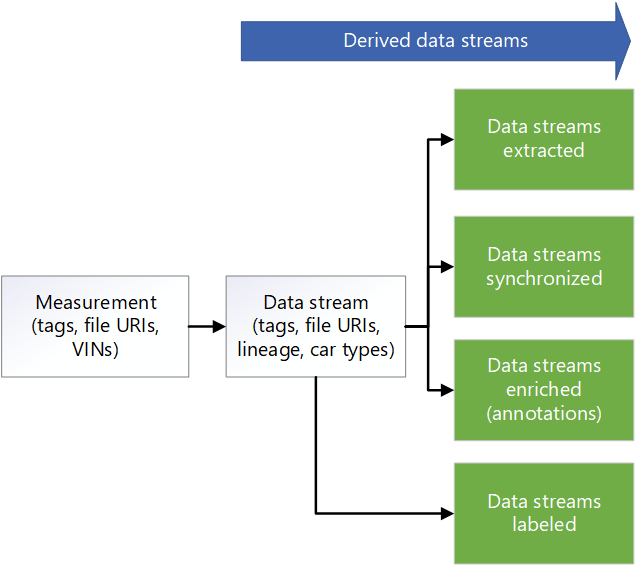
Data Factory 管線會執行 以擴充數據。 增強功能的範例包括遙測、車輛記錄器數據和其他數據,例如天氣、地圖或對象數據。 擴充的數據有助於提供數據科學家在演算法開發中使用的深入解析,例如。 產生的數據會保留在與同步處理數據的 Apache Parquet 檔案中。 擴充數據的元數據會儲存在 Azure Cosmos DB 的元數據存放區中。
第三方合作夥伴會執行手動或自動套用標籤。 數據會透過 Azure Data Share 與第三方合作夥伴共用,並整合在 Microsoft Purview 中。 Data Share 會使用名為 Labeled in Data Lake 儲存體 的專用記憶體帳戶,將已標記的數據傳回給組織。
Data Factory 管線會執行場景偵測。 場景元數據會保留在元數據存放區中。 場景數據會儲存為 Parquet 或 Delta 檔案中的物件。
除了擴充數據的元數據和偵測到的場景,Azure Cosmos DB 中的元數據存放區也會儲存測量的元數據,例如磁碟驅動器數據。 此存放區也包含數據譜系的元數據,因為它會經歷擷取、縮小取樣、同步處理、擴充和場景偵測的程式。 元數據 API 可用來存取度量、譜系和場景數據,以及查閱儲存數據的位置。 因此,元數據 API 會作為儲存層管理員。 它會將數據分散到記憶體帳戶。 它也提供開發人員使用元數據型搜尋來取得數據位置的方式。 因此,元數據存放區是集中式元件,可跨解決方案的數據流提供可追蹤性和譜系。
Azure Databricks 和 Azure Synapse Analytics 可用來與元數據 API 連線,並存取 Data Lake 儲存體 並研究數據。
元件
- 數據箱 提供一種方式,以快速、便宜且可靠的方式,將數據送入和移出 Azure。 在此解決方案中,數據箱可用來透過區域貨運公司將收集到的車輛數據傳輸到 Azure。
- Azure Stack Edge 裝置會在邊緣位置提供 Azure 功能。 Azure 功能的範例包括計算、記憶體、網路和硬體加速機器學習。
- ExpressRoute 會透過私人連線,將內部部署網路延伸至 Microsoft 雲端。
- Data Lake 儲存體 會以其原生原始格式保存大量數據。 在此情況下,Data Lake 儲存體 會根據階段來儲存數據,例如未經處理或擷取。
- Data Factory 是完全受控、無伺服器的解決方案,可用於建立和排程擷取、轉換、載入(ETL)和擷取、載入、轉換 (ELT) 工作流程。 在這裡,Data Factory 會透過 批次計算 執行 ETL,並建立資料驅動工作流程,以協調數據移動和轉換數據。
- Batch 會在 Azure 中有效率地執行大規模的平行和高效能運算 (HPC) 批次作業。 此解決方案會使用 Batch 來執行大規模的應用程式,以執行數據整頓、篩選和準備數據,以及擷取元數據等工作。
- Azure Cosmos DB 是全域散發的多模型資料庫。 在這裡,它會儲存元數據結果,例如預存的度量。
- Data Share 與具有增強安全性的合作夥伴組織共享數據。 藉由使用就地共用,數據提供者可以共用其所在位置的數據,而不需要複製數據或擷取快照集。 在此解決方案中,Data Share 會與標籤公司共享數據。
- Azure Databricks 提供一組工具來大規模維護企業級數據解決方案。 對於大量車輛數據的長時間執行作業,這是必要專案。 數據工程師會使用 Azure Databricks 作為分析工作臺。
- Azure Synapse Analytics 可縮短跨數據倉儲和巨量數據系統深入解析的時間。
- Azure 認知搜尋 提供數據目錄搜尋服務。
- App Service 提供無伺服器型 Web 應用程式服務。 在此情況下,App Service 會裝載元數據 API。
- Microsoft Purview 提供跨組織的數據控管。
- Azure Container Registry 是一項服務,可建立容器映像的受控登錄。 此解決方案會使用 Container Registry 來儲存用於處理主題的容器。
- Application Insights 是 Azure 監視器的延伸模組,可提供應用程式效能管理。 在此案例中,Application Insights 可協助您建置測量擷取的可檢視性:您可以使用 Application Insights 來記錄自定義事件、自定義計量和其他資訊,同時解決方案會處理每個測量來擷取。 您也可以在記錄分析上建置查詢,以取得每個測量的詳細資訊。
案例詳細資料
為自主車輛設計強大的 DataOps 架構對於使用您的數據、追蹤其譜系,以及在整個組織中提供它至關重要。 如果沒有設計完善的 DataOps 程式,自動駕駛汽車產生的大量數據可能會變得難以管理。
當您實作有效的 DataOps 策略時,可協助確保數據已正確儲存、易於存取,而且具有明確的譜系。 您也可以輕鬆地管理和分析數據,進而做出更明智的決策並改善車輛效能。
有效率的 DataOps 程式可讓您輕鬆地在整個組織中散發數據。 然後,各種小組可以存取優化作業所需的資訊。 DataOps 可讓您輕鬆地共同作業並共用深入解析,這有助於改善組織的整體效率。
自主車輛內容中數據作業的典型挑戰包括:
- 管理來自研發車輛的每日 TB 規模或 PB 級測量數據量。
- 例如,跨多個小組和合作夥伴的數據共用和共同作業,用於標記、批註和質量檢查。
- 安全性關鍵感知堆疊的可追蹤性和譜系,可擷取版本設定和測量數據的譜系。
- 元數據和數據探索可改善語意分割、影像分類和對象偵測模型。
此 AVOps DataOps 解決方案提供如何解決這些挑戰的指引。
潛在使用案例
此解決方案可讓汽車原始設備製造商(OEM)、第 1 層廠商和獨立軟體供應商 (ISV) 受益,以開發自動化駕駛解決方案。
同盟數據作業
在實作AVOps的組織中,由於AVOps所需的複雜度,多個小組會參與DataOps。 例如,一個小組可能負責數據收集和數據擷取。 另一個小組可能負責對 Lidar 數據進行數據管理。 因此,數據網格架構的下列原則對於DataOps而言很重要:
- 面向領域的數據擁有權和架構分散。 一個專用小組負責一個數據網域,提供該網域的數據產品,例如已標記的數據集。
- 數據做為產品。 每個數據域在 Data Lake 實作的記憶體容器上都有各種區域。 有區域可供內部使用。 另外還有一個區域,其中包含其他數據網域或外部使用量的已發佈數據產品,以避免數據重複。
- 以自助數據作為平臺,以啟用自主、面向領域的數據小組。
- 同盟治理,可啟用需要集中式元數據存放區和數據目錄的AVOps數據網域之間的互操作性和存取。 例如,標籤數據域可能需要存取數據收集網域。
如需數據網格實作的詳細資訊,請參閱 雲端規模分析。
AVOps 數據網域的範例結構
下表提供建構 AVOps 數據域的一些想法:
| 數據域 | 已發佈的數據產品 | 解決方案步驟 |
|---|---|---|
| 資料集合 | 上傳和驗證的度量檔案 | 登陸和原始 |
| 擷取的影像 | 選取和擷取的影像或畫面、雷射雷達和雷達數據 | 提取 |
| 擷取的雷達或雷射雷達 | 選取和擷取的雷射雷達和雷達數據 | 提取 |
| 擷取的遙測 | 選取和擷取汽車遙測數據 | 提取 |
| 標記 | 加上標籤的數據集 | 標記 |
| 重新計算 | 根據重複的模擬執行產生的關鍵效能指標 (KPI) | 重新計算 |
每個AVOps數據網域都是根據藍圖結構來設定。 該結構包含Data Factory、Data Lake 儲存體、資料庫、Batch 和 Apache Spark 執行時間,透過 Azure Databricks 或 Azure Synapse Analytics。
元數據和數據探索
每個數據域都是分散的,並個別管理其對應的AVOps數據產品。 若要進行集中數據探索,並了解數據產品的位置,需要兩個元件:
- 元數據存放區,保存已處理度量檔案和數據流的相關元數據,例如視訊序列。 此元件會使用需要編製索引的註釋來探索和追蹤數據,例如搜尋未標記檔案的元數據。 例如,您可能想要元數據存放區傳回特定車輛標識碼 (VIN) 的所有框架,或具有行人或其他擴充型物件的框架。
- 數據目錄,顯示歷程、AVOps 數據網域之間的相依性,以及AVOps資料迴圈涉及哪些資料存放區。 數據目錄的範例是 Microsoft Purview。
您可以使用 Azure 數據總管或 Azure 認知搜尋 來擴充以 Azure Cosmos DB 為基礎的元數據存放區。 您的選擇取決於數據探索所需的最終案例。 使用 Azure 認知搜尋 進行語意搜尋功能。
下列元數據模型圖表顯示一般統一元數據模型,用於數個AVOps數據迴圈要素:
資料共用
數據共用是AVOps數據迴圈中的常見案例。 使用 包括數據網域與外部共用之間的數據共用,例如整合標籤合作夥伴。 Microsoft Purview 提供下列功能,可在數據迴圈中有效率地共享數據:
卷標數據交換的建議格式包括 內容 (COCO) 數據集 中的通用物件,以及 自動化和測量系統標準化協會 (ASAM) OpenLABEL 數據集。
在此解決方案中,標記的數據集會用於MLOps程式,以建立特殊演算法,例如感知和感測器融合模型。 演算法可以偵測環境中的場景和物件,例如換車車道、封鎖道路、行人交通、紅綠燈和交通標誌。
資料管線
在此 DataOps 解決方案中,數據管線中不同階段之間的數據移動是自動化的。 透過這種方法,此程式可提供效率、延展性、一致性、重現性、適應性和錯誤處理優點。 它加強整體開發過程,加快進展,支援自主駕駛技術的安全有效部署。
下列各節說明如何在階段之間實作數據移動,以及如何建構記憶體帳戶。
階層式資料夾結構
組織良好的資料夾結構是自主驅動開發中數據管線的重要元件。 這種結構提供數據檔的系統化且容易導覽的排列方式,有助於有效率的數據管理和擷取。
在此解決方案中 ,原始 資料夾中的數據具有下列階層式結構:
region/raw/<measurement-ID>/<data-stream-ID>/YYYY/MM/DD
擷取區域記憶體帳戶中的數據會使用類似的階層式結構:
region/extracted/<measurement-ID>/<data-stream-ID>/YYYY/MM/DD
藉由使用類似的階層式結構,您可以利用 Data Lake 儲存體 的階層命名空間功能。 階層式結構有助於建立可調整且符合成本效益的物件記憶體。 這些結構也會改善物件搜尋和擷取的效率。 依年份分割和 VIN 可讓您輕鬆地從特定車輛搜尋相關影像。 在數據湖中,會為每個感測器建立儲存容器,例如相機、GPS 裝置或雷射雷達或雷達感測器。
將記憶體帳戶登陸至原始記憶體帳戶
Data Factory 管線會根據排程觸發。 觸發管線之後,數據會從登陸記憶體帳戶複製到原始記憶體帳戶。

管線會擷取所有度量資料夾,並逐一查看它們。 在每次測量時,解決方案都會執行下列活動:
函式會驗證度量。 函式會從度量指令清單擷取指令清單檔案。 然後,函式會檢查度量資料夾中是否有目前度量的所有 MDF4、TDMS 和 rosbag 度量檔案。 如果驗證成功,函式會繼續進行下一個活動。 如果驗證失敗,函式會略過目前的度量,並移至下一個度量資料夾。
Web API 呼叫會針對建立度量的 API 進行,而來自度量指令清單 JSON 檔案的 JSON 承載會傳遞至 API。 如果呼叫成功,則會剖析回應以擷取度量標識碼。 如果呼叫失敗,測量會移至錯誤處理時的錯誤活動。
注意
此 DataOps 解決方案是以您限制應用程式服務要求數目的假設為基礎所建置。 如果您的解決方案可能會提出不確定的要求數目,請考慮 速率限制模式。
Web API 呼叫會透過建立必要的 JSON 承載來建立數據流的 API。 如果呼叫成功,則會剖析回應以擷取數據流標識碼和數據流位置。 如果呼叫失敗,度量就會移至錯誤活動。
進行 Web API 呼叫,將資料流的狀態更新為
Start Copy。 如果呼叫成功,複製活動會將度量檔案複製到數據流位置。 如果呼叫失敗,度量就會移至錯誤活動。Data Factory 管線會叫用 Batch,將測量檔案從登陸記憶體帳戶複製到原始記憶體帳戶。 協調器應用程式的複製模組會為每個度量建立具有下列工作的作業:
- 將度量檔案複製到原始記憶體帳戶。
- 將度量檔案複製到封存記憶體帳戶。
- 從登陸記憶體帳戶中移除度量檔案。
注意
在這些工作中,Batch 會使用協調器集區和 AzCopy 工具來複製和移除數據。 AzCopy 會使用 SAS 令牌來執行複製或移除工作。 SAS 令牌會儲存在金鑰保存庫中,並使用、
archivesaskey和rawsaskey一詞landingsaskey來參考。進行 Web API 呼叫,將資料流的狀態更新為
Copy Complete。 如果呼叫成功,順序會繼續進行下一個活動。 如果呼叫失敗,度量就會移至錯誤活動。度量檔案會從登陸記憶體帳戶移至登陸封存。 此活動可以透過凍結複製管線將其移回登陸記憶體帳戶,以重新執行特定度量。 此區域的生命週期管理已開啟,因此會自動刪除或封存此區域中的度量。
如果測量發生錯誤,度量就會移至錯誤區域。 您可以從該處移至登陸記憶體帳戶,以再次執行。 或者,生命週期管理可以自動刪除或封存測量。
請注意下列幾點:
- 這些管線會根據排程觸發。 這種方法有助於改善管線執行的可追蹤性,並避免不必要的執行。
- 每個管線都會設定為一個併行值,以確保任何先前的執行會在下一個排程的執行開始之前完成。
- 每個管線都會設定為平行複制度量。 例如,如果排程的執行會挑選 10 個度量來複製,管線步驟可以同時執行所有 10 個度量。
- 如果管線花費的時間超過預期的完成時間,每個管線都會設定為在 [監視] 中產生警示。
- 錯誤活動會在後續的可檢視性案例中實作。
- 生命週期管理會自動刪除部分度量,例如遺漏 rosbag 檔案的度量。
批次設計
所有擷取邏輯都會封裝在不同的容器映射中,每個擷取程式各有一個容器。 Batch 會在從度量檔案擷取資訊時平行執行容器工作負載。

Batch 會使用協調器集區和執行集區來處理工作負載:
- 協調器集區具有沒有容器運行時間支援的Linux節點。 集區會執行 Python 程式代碼,此程式代碼會使用 Batch API 來建立執行集區的作業和工作。 此集區也會監視這些工作。 Data Factory 會叫用協調器集區,以協調擷取數據的容器工作負載。
- 執行集區具有具有容器運行時間的Linux節點,以支援執行中的容器工作負載。 在此集區中,作業和工作會透過協調器集區排程。 執行集區中處理所需的所有容器映像都會使用 JFrog 推送至容器登錄。 執行集區已設定為連線到此登錄,並提取所需的映像。
儲存體 在批次節點上透過NFS 3.0 掛接數據以及節點上執行的容器,來讀取和寫入數據的帳戶。 這種方法可協助批次節點和容器快速處理數據,而不需要將數據文件下載到批次節點。
注意
批次和記憶體帳戶必須位於相同的虛擬網路中,才能掛接。
從 Data Factory 叫用 Batch
在擷取管線中,觸發程式會傳遞元數據檔案的路徑,以及管線參數中的原始數據流路徑。 Data Factory 會使用查閱活動來剖析指令清單檔案中的 JSON。 您可以剖析管線變數,從原始數據流路徑擷取原始數據流標識碼。
Data Factory 會呼叫 API 來建立數據流。 API 會傳回所擷取數據流的路徑。 擷取的路徑會新增至目前物件,而 Data Factory 會在附加擷取的數據流路徑之後,透過自定義活動叫用 Batch:
{
"measurementId":"210b1ba7-9184-4840-a1c8-eb£397b7c686",
"rawDataStreamPath":"raw/2022/09/30/KA123456/210b1ba7-9184-4840-
alc8-ebf39767c68b/57472a44-0886-475-865a-ca32{c851207",
"extractedDatastreamPath":"extracted/2022/09/30/KA123456
/210bIba7-9184-4840-a1c8-ebf39767c68b/87404c9-0549-4a18-93ff-d1cc55£d8b78",
"extractedDataStreamId":"87404bc9-0549-4a18-93ff-d1cc55fd8b78"
}
逐步擷取程式

Data Factory 會排程具有一項工作的工作,讓協調器集區處理擷取的度量。 Data Factory 會將下列資訊傳遞給協調器集區:
- 度量標識碼
- 需要擷取之 MDF4、TDMS 或 rosbag 類型的測量檔案位置
- 所擷取內容的儲存位置目的地路徑
- 擷取的數據流標識碼
協調器集區會叫用 API 來更新資料流,並將其狀態設定為
Processing。協調器集區會為每個度量檔案建立屬於測量一部分的作業。 每個作業都包含下列工作:
Task 目的 注意 驗證 驗證是否可以從度量檔案擷取數據。 所有其他工作都相依於此工作。 處理元數據 從度量檔案衍生元數據,並使用 API 更新檔案的元數據來擴充檔案的元數據。 過程 StructuredTopics從指定的度量檔案擷取結構化數據。 要從中擷取結構化數據的主題清單會以組態物件的形式傳遞。 過程 CameraTopics從指定的度量檔案擷取影像數據。 要擷取影像的主題清單會以組態物件的形式傳遞。 過程 LidarTopics從指定的測量檔案擷取鐳射雷達數據。 要從中擷取 lidar 資料的主題清單會以組態物件的形式傳遞。 過程 CANTopics從指定的測量檔案擷取控制器局域網路 (CAN) 數據。 要從中擷取資料的主題清單會以組態物件的形式傳遞。 協調器集區會監視每個工作的進度。 在所有測量檔案完成所有作業之後,集區會叫用 API 來更新資料流,並將其狀態設定為
Completed。協調器會正常結束。
注意
每個工作都是個別的容器映像,其邏輯會針對其用途適當地定義。 工作接受組態物件做為輸入。 例如,輸入會指定要寫入輸出的位置,以及要處理的測量檔案。 主題類型的陣列,例如
sensor_msgs/Image,是輸入的另一個範例。 因為所有其他工作都相依於驗證工作,所以會為其建立相依工作。 所有其他工作都可以獨立處理,而且可以平行執行。
考量
這些考量能實作 Azure Well-Architected Framework 的要素,其為一組指導原則,可以用來改善工作負載的品質。 如需詳細資訊,請參閱 Microsoft Azure Well-Architected Framework (部分機器翻譯)。
可靠性
可靠性可確保您的應用程式符合您對客戶的承諾。 如需詳細資訊,請參閱可靠性要素的概觀 (部分機器翻譯)。
- 在您的解決方案中,請考慮使用 Azure 可用性區域,這是相同 Azure 區域內的唯一實體位置。
- 規劃災害復原和帳戶 故障轉移。
安全性
安全性可提供保證,以避免刻意攻擊和濫用您寶貴的資料和系統。 如需詳細資訊,請參閱安全性要素的概觀。
請務必了解汽車 OEM 與 Microsoft 之間的責任劃分。 在車輛中,OEM 擁有整個堆疊,但隨著數據移至雲端,某些責任會傳輸到 Microsoft。 Azure 平臺即服務 (PaaS) 層會在實體堆疊上提供內建安全性,包括作業系統。 您可以將下列功能新增至現有的基礎結構安全性元件:
- 使用 Microsoft Entra 身分識別和 Microsoft Entra 條件式存取原則的身分識別和 存取 管理。
- 使用 Azure 原則的基礎結構治理。
- 使用 Microsoft Purview 的數據控管。
- 使用原生 Azure 記憶體和資料庫服務的待用數據加密。 如需詳細資訊,請參閱 數據保護考慮。
- 保護密碼編譯金鑰和秘密。 請針對此目的使用 Azure 金鑰保存庫。
成本最佳化
成本優化會探討減少不必要的費用並提升營運效率的方法。 如需詳細資訊,請參閱成本最佳化要素的概觀。
針對為自動車輛操作 DataOps 的 OEM 和第 1 層供應商,主要考慮是營運成本。 此解決方案會使用下列作法來協助將成本優化:
- 利用 Azure 提供的各種選項來裝載應用程式程式代碼。 此解決方案使用 App Service 和 Batch。 如需如何為您的部署選擇正確服務的指引,請參閱 選擇 Azure 計算服務。
- 使用 Azure 儲存體 就地數據共用。
- 使用 生命週期管理將成本優化。
- 使用 保留實例節省App Service的成本。
參與者
本文由 Microsoft 維護。 原始投稿人如下。
主要作者:
- 里安松村 |資深項目經理
- Jochen Schroeer |首席架構師(服務線路行動性)
- Brij Singh |首席軟體工程師
- Ginette Vellera |資深軟體工程主管
若要查看非公用LinkedIn配置檔,請登入LinkedIn。
下一步
- 什麼是 Azure Batch?
- 什麼是 Azure Data Factory?
- Azure Data Lake Storage Gen2 簡介
- 歡迎使用 Azure Cosmos DB
- App Service 概觀
- 什麼是 Azure Data Share?
- 什麼是 Azure 數據箱?
- Azure Stack Edge 檔
- 什麼是 Azure ExpressRoute?
- 什麼是 Azure Machine Learning 服務?
- 什麼是 Azure Databricks?(機器翻譯)
- 什麼是 Azure Synapse Analytics?
- Azure 監視器概觀
- ROS 記錄檔 (rosbags)
- 自主車輛的大型數據作業平臺