適用於:![]() Azure SQL 受控執行個體
Azure SQL 受控執行個體
本文提供容錯移轉群組功能的概觀,以及與 Azure SQL 受控執行個體搭配使用的最佳做法和建議。 容錯移轉群組功能可讓您管理 SQL 受控執行個體中所有使用者資料庫的複寫和容錯移轉至另一個 Azure 區域。
若要開始,請查看 設定 Azure SQL 受控執行個體的容錯群組。
概觀
容錯移轉群組功能可讓您管理使用者資料庫從一個 SQL 受控執行個體到不同 Azure 區域中另一個 SQL 受控執行個體的複寫和容錯移轉。 容錯移轉群組旨在簡化異地複寫資料庫的大規模部署和管理。
如需詳細資訊,請參閱 Azure SQL 受控執行個體的高可用性。 如需異地容錯移轉的 RPO 和 RTO,請參閱商務持續性概觀。
端點重新導向
故障轉移群組提供異地故障轉移期間保持不變的讀寫和只讀接聽程式端點。 您不需要在異地容錯移轉之後變更應用程式的連接字串,因為連線會自動路由至目前的主要節點。 地理容錯移轉會將群組中所有次要資料庫切換到主要角色。 異地容錯移轉完成後,DNS 記錄會自動更新以將端點重新導向至新的區域。
卸載唯讀工作負載
若要減少到主要資料庫的流量,您也可以使用容錯移轉群組中的次要資料庫,以卸載唯讀工作負載。 請使用唯讀接聽程式將唯讀流量導向可讀取的次要資料庫。
恢復應用程式
若要實現完整的商務持續性,新增區域資料庫備援只是解決方案的一部分。 在災難性失敗後要端對端復原應用程式 (服務) 需要復原構成服務的所有元件和任何相依的服務。 這些元件的範例包括用戶端軟體 (例如自訂 JavaScript 的瀏覽器)、web 前端、儲存體和 DNS。 所有元件都必須對相同的失敗具有恢復功能,並且在應用程式的復原時間目標 (RTO) 內可供使用。 因此,您需要識別所有相依服務並了解其提供的保證與功能。 然後,您必須採取充分的步驟以確保您的服務在所依賴服務的故障轉移期間都能正常運作。
容錯移轉原則
故障切換群組支援兩個故障切換策略:
-
客戶管理 (建議) - 當客戶發現非預期的中斷影響到故障移轉群組中的一個或多個資料庫時,可以執行群組的故障移轉。 使用 PowerShell、Azure CLI 或 REST API 等命令列工具時,客戶管理的故障轉移策略值是
manual。 -
由 Microsoft 管理 - 如果發生影響主要區域的廣泛中斷,Microsoft 會針對所有影響的容錯移轉群組啟動容錯移轉,這些群組的容錯移轉原則設定為由 Microsoft 管理。 不會針對區域中個別或部分的容錯移轉群組啟動 Microsoft 受管的容錯移轉。 使用 PowerShell、Azure CLI 或 Rest API 等命令行工具時,Microsoft 受管的容錯移轉原則值是
automatic。
每個容錯移轉原則都有一組獨特的使用案例,以及容錯移轉範圍和資料遺失的對應預期,如下表摘要所示:
| 容錯移轉原則 | 容錯移轉範圍 | 使用案例 | 潛在資料遺失 |
|---|---|---|---|
| 由客戶管理 (建議使用) |
容錯移轉群組 | 容錯移轉群組中的一或多個資料庫發生中斷,並變得無法使用。 您可以選擇故障轉移。 | 是 |
| 由 Microsoft 管理 | 區域中的所有容錯移轉群組 | 區域中的廣泛中斷會導致資料庫無法使用,而 Microsoft Azure SQL 服務小組決定觸發強制容錯移轉。 只有在您想要將災害復原責任委派給 Microsoft,且應用程式可容忍至少一小時以上的 RTO 時間 (停機時間),才使用此選項。 Microsoft 受控容錯移轉可能只會在極端情況下執行。 強烈建議使用 客戶管理的故障轉移策略。 |
是 |
由客戶管理
在極少數情況下,內建 可用性或高可用性 不足以緩解中斷,而且容錯移轉群組中的資料庫可能會在使用資料庫之應用程式的服務等級協定 (SLA) 無法接受的持續時間內無法使用。 資料庫可能會因區域性問題影響少數幾個資料庫而無法使用,也可能是因資料中心、可用性區域或區域層級的問題導致無法使用。 在上述任何一種情況中,若要恢復業務連續性,您可以進行強制故障轉移。
強烈建議您將容錯移轉原則設定為客戶管理,因為此方式可讓您控制何時起始容錯移轉和還原商務持續性。 當您發現非預期的中斷影響到容錯移轉群組中的一個或多個資料庫時,您可以啟動容錯移轉。
由 Microsoft 管理
使用由 Microsoft 管理的容錯移轉策略,將災害復原的責任委派給 Azure SQL 服務。 若要讓 Azure SQL 服務啟動強制故障轉移,則必須符合下列條件:
- 由自然災害事件、組態變更、軟體錯誤或硬體元件故障所導致的區域層級中斷,以及區域中的許多資料庫都會受到影響。
- 寬限期已過期。 由於驗證中斷的規模以及緩解中斷取決於人為動作,因此寬限期不能設定為低於一小時。
符合這些條件時,Azure SQL 服務會對區域中所有已將容錯移轉原則設定為 Microsoft 管理的容錯移轉群組起始強制容錯移轉。
重要
使用客戶管理的故障轉移策略來測試和實作災難復原計劃。 請勿依賴 Microsoft 管理的容錯移轉,這可能只會在極端情況下被 Microsoft 所執行。 Microsoft 受控容錯移轉會針對區域中所有容錯移轉群組起始,其容錯移轉原則設定為 Microsoft 受控。 無法針對個別的容錯移轉群組啟動。 如果您需要選擇性地對您的容錯移轉群組進行切換,請使用客戶管理的容錯移轉策略。
僅在下列情況下,將故障移轉政策設為由 Microsoft 管理:
- 您想要將災害復原責任委派給 Azure SQL 服務。
- 應用程式可容忍您的資料庫至少一小時以上無法使用。
- 在寬限期到期後一段時間觸發強制容錯移轉是可以接受的,因為強制容錯移轉的實際時間可能會有很大差異。
- 無論容錯移轉群組中所有資料庫的區域備援配置或可用性狀態為何,接受它們全部進行容錯移轉是可以的。 雖然針對區域備援設定的資料庫能夠從區域性失敗中復原,而且可能不會受中斷影響,但如果資料庫是具有 Microsoft 管理的容錯移轉原則的容錯移轉群組一部分,則其仍然可以容錯移轉。
- 可以接受在切換群組中進行強制切換資料庫,這樣做時不考慮應用程式對其他 Azure 服務或其所使用的元件的相依性,可能會導致應用程式效能下降或無法使用。
- 因為無法控制強制容錯移轉的確切時間,因此可以接受產生未知的資料遺失量,並忽略次要資料庫的同步處理狀態。
- 容錯移轉群組中的主要和次要副本具有相同的服務層級、運算層和運算規模。
當 Microsoft 觸發容錯移轉時,會將作業名稱為容錯移轉 Azure SQL 容錯移轉群組的項目新增至 Azure 監視器活動記錄。 項目包含 [資源] 底下的容錯移轉群組名稱,而 [事件起始者] 會顯示單一連字號 (-) 以指出容錯移轉是由 Microsoft 起始的。 您也可以在 Azure 入口網站中新主要伺服器或執行個體的 [活動記錄] 頁面上找到此資訊。
術語和功能
容錯移轉群組 (FOG)
容錯移轉群組可讓 SQL 受控執行個體內的所有使用者資料庫以單位的形式容錯移轉至另一個 Azure 區域,以防主要 SQL 受控執行個體因主要區域中斷而無法使用。 SQL 受控執行個體的容錯移轉群組包含該執行個體中的所有使用者資料庫,因此在一個執行個體上只能設定一個容錯移轉群組。
重要
容錯移轉群組的名稱在
.database.windows.net網域內必須是全域唯一的。主要
在故障轉移群組中裝載主要資料庫的 SQL 受控執行個體。
次要
在容錯移轉群組中裝載次要資料庫的 SQL 受控執行個體。 次要資料庫和主要資料庫不能位於相同的 Azure 區域。
重要
如果資料庫包含記憶體內部 OLTP 物件,則主要資料庫和次要異地複寫執行個體必須具有相符的服務層級,因為記憶體內部 OLTP 物件位於記憶體中。 異地複寫執行個體的較低服務層級會導致記憶體不足問題。 如果發生此情況,次要複本可能無法復原資料庫,導致次要資料庫與異地次要資料庫上的記憶體內部 OLTP 物件無法使用。 因此,這也可能導致容錯移轉失敗。 若要避免此情況,請確定異地次要執行個體的服務層級符合主要資料庫的服務層級。 服務層級升級通常涉及大量資料的處理,且需要一段時間才能完成。
容錯移轉 (無資料遺失)
故障轉移將在主要資料庫和次要資料庫之間進行資料同步,然後將次要資料庫切換為主要角色。 這可確保不會遺失資料。 只有在主要資料庫可供存取時,才能進行容錯移轉。 故障轉移會用於下列場景:
- 在資料遺失不可接受時,在生產環境中執行災害復原 (DR) 演練
- 將工作負載重新放置到不同的區域
- 在中斷情況趨緩 (容錯回復) 後,將工作負載傳回到主要區域
強制故障移轉 (潛在資料遺失)
強制容錯移轉會立即將次要資料庫切換為主要角色,而不會等待從主要資料庫傳播最近的變更。 此作業會導致潛在資料遺失。 強制容錯移轉是主要資料庫無法存取時,用來作為中斷期間的恢復方法。 中斷緩解時,舊的主要資料庫會自動重新連接,並成為新的次要資料庫。 可以執行容錯移轉以回復,讓副本回復到其原始的主要和次要角色。
資料遺失的寬限期
由於使用非同步複寫會將資料複寫至次要,因此具有 Microsoft 管理的容錯移轉原則的群組的強制容錯移轉可能會導致資料遺失。 您可以自訂容錯移轉原則,以符合應用程式對資料遺失的容忍度。 藉由設定
GracePeriodWithDataLossHours,您可以控制 Azure SQL 服務在起始強制容錯移轉之前的等候時間,這會導致資料遺失。
DNS 區域
建立新的 SQL 受控執行個體時自動產生的唯一識別碼。 系統會佈建此執行個體的多網域 (SAN) 憑證,用來向相同 DNS 區域中任何執行個體的用戶端連線進行驗證。 相同容錯移轉群組的兩個 SQL 受控執行個體必須共用同一個 DNS 區域。
容錯移轉群組讀寫監聽器
指向目前主要伺服器的 DNS CNAME 記錄。 系統會在建立容錯移轉群組時自動建立,並允許讀寫工作負載在容錯移轉之後主要資料庫變更時,以透明的方式重新連線至主要資料庫。 在 SQL 受控執行個體上建立容錯移轉群組時,監聽程式 URL 的 DNS CNAME 記錄會被建立為
<fog-name>.<zone_id>.database.windows.net。故障移轉群組唯讀聆聽程式
指向目前次要伺服器的 DNS CNAME 記錄。 其是在容錯移轉群組建立時自動建立,並允許唯讀 SQL 工作負載在容錯移轉之後次要資料庫變更時,以透明的方式連線到次要資料庫。 在 SQL 受控執行個體上建立容錯移轉群組時,監聽程式 URL 的 DNS CNAME 記錄會被建立為
<fog-name>.secondary.<zone_id>.database.windows.net。 根據預設,唯讀監聽器的備援切換已停用,這是為了確保當次要資料庫離線時,不影響主要資料庫的效能。 不過,這也表示在次要資料庫復原之前,唯讀工作階段將無法連線。
容錯移轉群組結構
容錯移轉群組必須在主要執行個體上設定,並將它連線到不同 Azure 區域中的次要執行個體。 主要執行個體上的所有使用者資料庫都會複寫至次要執行個體。 系統資料庫如 master 和 msdb 不會被複製。
下圖說明使用 SQL 受控執行個體和容錯移轉群組的異地備援雲端應用程式一般設定:
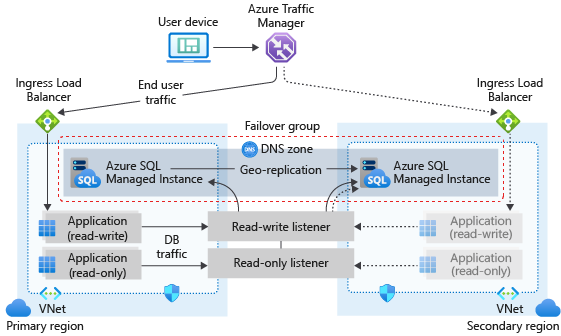
如果您的應用程式使用 SQL 受控執行個體作為資料層,請在設計業務持續性時遵循本文中概述的一般指導和最佳做法。
建立地理次要執行個體
若要確保容錯移轉之後與主要 SQL 受控執行個體的連線不中斷,主要和次要執行個體都必須位於相同的 DNS 區域中。 它保證相同的 SAN 多網域憑證可以用來驗證用戶端連線到容錯移轉群組中的任一個執行個體。 當您的應用程式準備好進行生產環境部署時,請在不同區域中建立次要 SQL 受控執行個體,並確保其與主要 SQL 受控執行個體共用 DNS 區域。 您可以在建立執行個體時指定選用參數來執行此動作。 如果您使用 PowerShell 或 REST API,則選擇性參數的名稱是 DNSZonePartner。 Azure 入口網站中對應的選擇性欄位名稱是主要受控執行個體。
重要
在子網路中建立的第一個 SQL 受控執行個體會決定相同子網路中所有後續執行個體的 DNS 區域。 這表示來自相同子網路的兩個執行個體不能屬於不同的 DNS 區域。
如需在與主要執行個體相同的 DNS 區域中建立次要 SQL 受控執行個體的詳細資訊,請參閱設定 Azure SQL 受控執行個體的容錯移轉群組。
使用配對的區域
基於效能考量,將兩個 SQL 受控執行個體部署至 配對區域 。 相較於未配對的區域,配對區域中的 SQL 受控執行個體容錯移轉群組會有更好的效能。
Azure SQL 受控執行個體遵循一項安全部署實務,其中 Azure 配對的區域通常不會同時進行部署。 不過,無法預測哪個區域先升級,因此無法保證部署順序。 有時候,您的主執行個體會先升級,而有時候則是次要執行個體會先升級。
如果 Azure SQL 受控執行個體屬於容錯移轉群組的一部分,且群組中的執行個體不在 Azure 配對區域中,請為您的主要和次要資料庫選取不同的維護時段排程。 例如,為您的異地次要資料庫選取 [工作日] 維護時段,為您的異地主要資料庫選取 [週末] 維護時段。
啟用並最佳化執行個體間的異地複寫流量
必須建立並維護托管主要和次要實例的虛擬網路子網之間的連接,以確保異地複寫流量的不中斷流動。 有多種方式可在執行個體之間提供連線,您可以根據網路拓撲和原則進行選擇:
全域虛擬網路對等互連 (VNet 對等互連)是用於在容錯移轉群組中的兩個執行個體之間建立連線的建議方式。 其會使用 Microsoft 骨幹基礎結構,在對等互連的虛擬網路之間提供低延遲、高頻寬的私人連線。 對等互連的虛擬網路之間所進行的通訊不需要公用網際網路、閘道或其他加密措施。
初始播種
在 SQL 受控執行個體之間建立容錯移轉群組時,在資料複寫開始之前,會有初始植入階段。 初始植入階段這部分是最長且最昂貴的作業。 初始資料植入完成後,數據會同步,而只有後續的數據更動會被複製。 完成初始植入所需的時間取決於資料大小、複寫的資料庫數目、主要資料庫上的工作負載強度,以及裝載主要和次要執行個體之虛擬網路之間的連結速度,這主要取決於建立連線的方式。 在正常情況下,並且使用建議的全球虛擬網路對等互連來建立連線時,SQL 受管執行個體的寫入速度每小時最多可達 360 GB。 平行對一批使用者資料庫執行種子作業,但不一定同時對所有資料庫執行。 如果執行個體上裝載多個資料庫,可能需要以多個批次進行。
如果兩個執行個體之間的連線速度低於必要的標準,則初始化的時間可能會受到明顯的影響。 您可以使用指定的植入速度、資料庫數目、資料總大小和連結速度來估計初始植入階段在資料複寫開始之前需要多長時間。 例如,針對一個 100-GB 的資料庫,如果連結可以每小時推送 84 GB,且沒有植入其他資料庫,則初始植入階段大約需要 1.2 小時的時間。 如果連結每小時只能傳送 10 GB,則植入一個 100-GB 的資料庫,大約需要 10 小時。 如果有多個資料庫需要複寫,初始化會平行執行。 當與緩慢的鏈結速度結合時,初始植入階段可能需要相當長的時間,特別是當來自所有資料庫的資料平行植入超過可用的連結頻寬時。
重要
初始播種階段可能需要幾天的時間,速度極低或繁忙的連線。 在此情況下,建立容錯移轉群組可能會逾時。建立容錯移轉群組將在六天後自動取消。
管理地理容錯移轉至異地次要執行個體
容錯移轉群組管理主要 SQL 受控實例上所有資料庫的地理容錯移轉。 建立群組時,執行個體上的每個資料庫都會自動異地複寫至異地次要執行個體。 您無法使用容錯移轉群組來起始資料庫子集的部分容錯移轉。
重要
如果資料庫在主要 SQL 受控執行個體上卸除,它也會自動卸除在異地次要 SQL 受控執行個體上。
使用讀寫監聽器(主要 MI)
針對讀寫工作負載,請使用 <fog-name>.zone_id.database.windows.net 作為伺服器名稱。 連線會自動導向至主要資料庫。 在容錯移轉之後,此名稱不會變更。 異地故障切換涉及更新 DNS 記錄,因此,只有在用戶端 DNS 快取重新整理之後,新的用戶端連線才會路由至新的主要伺服器。 因為次要執行個體與主要執行個體共用 DNS 區域,因此用戶端應用程式將能夠使用相同的伺服器端 SAN 憑證重新連線到該區域。 必須先終止現有的用戶端連線,然後才能重新建立以路由傳送至新的主要伺服器。 讀寫接聽程式和唯讀接聽程式無法通過SQL 受控執行個體的公用端點到達。
使用唯讀監聽器(次要受控執行個體)
如果您有邏輯上隔離且容忍資料延遲的唯讀工作負載,這些工作負載可以在地理備援次要資料庫上執行。 若要直接連線到地理次要複本,請使用 <fog-name>.secondary.<zone_id>.database.windows.net 作為伺服器名稱。
在業務關鍵層中,SQL 受控執行個體支援使用唯讀副本來卸載唯讀查詢工作負載,可以在連接字串中使用ApplicationIntent=ReadOnly 參數。 當您已設定異地複寫的次要執行個體時,可以使用此功能連接至主要位置或異地複寫位置中的唯讀複本:
- 若要連線至主要位置的唯讀複本,請使用
ApplicationIntent=ReadOnly和<fog-name>.<zone_id>.database.windows.net。 - 若要連線至次要位置的唯讀備份,請使用
ApplicationIntent=ReadOnly和<fog-name>.secondary.<zone_id>.database.windows.net。
無法透過 SQL 受控執行個體的公用端點存取讀寫監聽程式和唯讀監聽程式。
容錯移轉後效能可能降低
一般的 Azure 應用程式會使用多個 Azure 服務,並由多個元件組成。 群組的異地容錯移轉會根據 Azure SQL 元件的狀態而觸發。 中斷可能不會影響主要區域中的其他 Azure 服務,而且其元件可能仍可在該區域中使用。 主要資料庫切換至次要區域之後,相依元件之間的延遲會增加。 確保次要區域中所有應用程式元件的備援,並將應用程式元件與資料庫一起容錯移轉,以便較高的跨區域延遲不會影響應用程式的效能。
強制故障切換後可能出現資料遺失
如果主要區域發生中斷,最近的交易可能尚未複寫至地理次要區域,而且如果執行強制故障切換,可能會遺失資料。
DNS 更新
當故障轉移啟動後,將立即執行讀寫監聽器的 DNS 更新。 這項作業將不會導致資料遺失。 不過,在一般情況下,切換資料庫角色的程序最多可能需要五分鐘。 在完成之前,新的主要執行個體中的某些資料庫仍會處於唯讀模式。 如果是使用 PowerShell 啟動容錯移轉,則切換主要副本角色的作業會是同步的。 如果是使用 Azure 入口網站來起始,UI 會指出完成狀態。 如果使用 REST API 來起始,請使用標準 Azure Resource Manager 的輪詢機制來監視完成情況。
重要
使用手動規劃的容錯移轉,在導致異地複寫容錯移轉的中斷緩解時,將主要資料庫移回原始位置。
使用無需授權的災害復原複本來節省成本
您可以將次要 SQL 受控執行個體設定為僅用於災害復原 (DR) ,以節省 SQL Server 授權成本。 若要進行此設定,請參閱為 Azure SQL 受控執行個體設定免授權待命複本。
只要次要執行個體未用於讀取工作負載,Microsoft 就會提供任意數目的虛擬核心,以配合主要執行個體。 您仍須支付次要執行個體所使用的計算和儲存體。 容錯移轉群組僅支援一個複本,且複本必須是可讀取的複本,或指定為僅限 DR 的複本。
啟用依賴於系統資料庫中物件的情境
系統資料庫不會複寫到容錯移轉群組中的次要執行個體。 若要啟用相依於系統資料庫中物件的案例,請務必在次要執行個體上建立相同的物件。 讓它們與主要執行個體保持同步。
例如,如果您打算在次要執行個體上使用相同的登入,請務必使用相同的 SID建立它們。
-- Code to create login on the secondary instance
CREATE LOGIN foo WITH PASSWORD = '<enterStrongPasswordHere>', SID = <login_sid>;
若要深入瞭解,請參閱登入與代理作業的複製。
同步執行個體屬性和保留原則的實例之間
主伺服器當中的執行個體在容錯移轉群組內與 Azure 資源保持獨立,對主執行個體配置的更動不會自動複寫至次要執行個體。 請務必在主要 和 次要執行個體上執行所有相關變更。 例如,如果您在主要執行個體上變更備份儲存備援或長期備份保留政策,請務必在次要執行個體上也變更它。
調整執行個體
主要和次要執行個體的組態應該相同。 這包括計算大小、儲存體大小和服務層級。 如果您需要變更故障轉移群組的組態,可以對應地將每個執行個體縮放為相同的組態。 若要進一步了解,請檢閱故障切換群組中的擴展執行個體。
防止重要資料遺失
由於廣域網路有高度延遲情況,因此異地複寫會採用非同步複寫機制。 如果主要資料庫故障,則非同步複寫無可避免會遺失一些資料。 若要瞭解如何保護資料,請檢閱防止資料遺失。
容錯移轉群組狀態
容錯移轉群組會報告其狀態,說明資料複寫的目前狀態:
- 種子:初始種子會在建立容錯移轉群組之後進行,直到所有使用者資料庫都在次要執行個體上初始化為止。 當容錯移轉群組處於 種子 狀態時,無法執行容錯移轉,因為使用者資料庫尚未複製到次要副本。
- 同步處理中:容錯移轉群組的一般狀態。 這表示主要執行個體上的資料變更會以非同步方式複寫至次要執行個體。 此狀態不保證資料會隨時完全同步處理。 由於容錯移轉群組中不同執行個體之間的複寫程序具有非同步性質,因此主要資料庫的資料變更可能尚未同步至次要資料庫。 當容錯移轉群組處於 「同步化」 狀態時,可以起始自動及手動容錯移轉。
- 容錯移轉進行中:此狀態表示自動或手動啟動的容錯移轉正在進行中。 當容錯移轉群組處於此狀態時,無法起始容錯移轉群組的變更或其他容錯移轉。
故障恢復
當故障轉移群組設定為由 Microsoft 管理的故障轉移原則時,將根據定義的寬限期,在災害情況下強制故障轉移至地理次要伺服器。 故障恢復至舊主伺服器必須手動執行。
功能互通性
備份
在下列案例中會進行完整備份:
- 在開始進行初始植入之前,當您建立容錯移轉群組時。
- 故障切換後。
完整備份是無法略過或延遲的資料操作大小,而且可能需要一些時間才能完成。 完成所需的時間取決於資料大小、資料庫數目,以及主資料庫上的工作負載強度。 完整備份可能會明顯延遲初始植入,而且可以在容錯移轉後不久延遲或防止新實例上的容錯移轉作業。
請考量下列各項:
- 在容錯移轉群組中,只有當次要執行個體在容錯移轉後成為主要執行個體或該容錯移轉群組被卸除時,裝載在次要執行個體上的資料庫才會備份。
- 在容錯移轉之後,資料庫變更為主要角色,或在卸除容錯移轉群組之後變成獨立角色之後,會自動起始完整資料庫備份,以協助時間點還原。
- 資料庫無法從執行個體還原至該執行個體是容錯移轉群組中次要複本的時間點。 若要還原至某個時間點,您必須從該時間點期間的主要執行個體還原資料庫。
- 若要在相同的 SQL 受控執行個體配對上重新建立已卸除的容錯移轉群組,必須在卸除容錯移轉群組之後,從預期的次要資料庫中移除所有使用者資料庫。 只有在所有擱置的備份作業完成後,才會完全移除資料庫,包括未進行的完整備份 (這是資料大小作業)。 在卸除具有非常大型資料庫的容錯移轉群組後,可能需要額外的時間來清理次要執行個體,因為每個資料庫可能有尚未完成的完整備份作業正在進行。
完整備份是無法略過或延遲的資料作業大小,而且可能需要一些時間才能完成。 完成所需的時間取決於資料大小、資料庫數目,以及主資料庫上的工作負載強度。 完整備份可能會明顯延遲初始植入,並可能延遲或阻止在容錯移轉後不久對新執行個體進行容錯移轉操作。
日誌回放服務
在完成切換步驟之前,使用記錄重新執行服務(LRS)移轉至 Azure SQL 受控執行個體的資料庫無法新增至容錯移轉群組。 使用 LRS 進行移轉的資料庫將處於還原狀態,直到完成切換,而處於還原狀態的資料庫無法加入容錯移轉群組。 嘗試建立具有還原狀態之資料庫的容錯移轉群組會延遲建立容錯移轉群組,直到資料庫還原完成為止。
事務複製
支援在容錯移轉群組中的執行個體使用異動複寫。 不過,如果您在將 SQL 受控執行個體新增至容錯移轉群組之前設定複寫,則當您開始建立容錯移轉群組時,複寫會暫停。 複寫監視器顯示的狀態為Replicated transactions are waiting for the next log backup or for mirroring partner to catch up。 成功建立容錯移轉群組之後,複寫便會繼續。
如果發行者或經銷商 SQL 受控執行個體在容錯移轉群組中,則在發生容錯移轉之後,SQL 受控執行個體系統管理員必須在舊的主要資料庫上清除所有發行集,並在新的主要資料庫上重新設定。 請檢閱異動複寫指南,了解此案例中所需的活動步驟。
權限和限制
以程式設計方式管理容錯移轉群組
您也可以使用 Azure PowerShell、Azure CLI 和 REST API,以程式設計方式管理容錯移轉群組。 檢閱 設定容錯移轉群組 以深入了解。
災害復原演練
建議進行災難備援演練的方法是使用手動故障轉移,詳情請參閱以下教學課程:測試故障轉移。
不建議使用強制故障轉移來執行演練,因為此作業不會提供防止資料遺失的防護措施。 不過,起始強制容錯移轉之前,確保符合下列條件,即可達到資料不遺失的強制容錯移轉:
- 工作負載會在主要 SQL 受控執行個體上停止。
- 所有長時間執行的交易都已完成。
- 與主要 SQL 受控執行個體的所有用戶端連線都已中斷連線。
-
故障轉移群組狀態於主要與次要實例
Synchronizing存在。
請確定兩個 SQL 受控執行個體已切換角色。 此外,容錯移轉群組狀態已從 「容錯移轉進行中」 切換為 「正在同步處理」 ,然後選擇性地建立與新主要 SQL 受控執行個體的連線並啟動讀寫工作負載。
若要將資料無損容錯回復至原始 SQL 受控執行個體角色, 強烈建議使用手動計劃性容錯移轉,而不是強制容錯移轉。
如果使用強制容錯回復:
- 請遵循與資料不遺失容錯移轉相同的步驟。
- 如果先前的強制故障轉移在兩個 SQL 管理實例上都未成功,強制回撤預期會失敗。 在執行強制回退前,請確保
Synchronizing實例的故障轉移群組狀態都成立。 - 如果在初始強制容錯移轉完成 後不久 執行強制容錯回復,則預期容錯回復執行時間會較長,因為它必須等待完成先前主要 SQL 受控執行個體上的未完成自動備份作業。
- 從主要角色轉換至次要角色的執行個體上,任何未完成的自動備份作業都可能影響此執行個體上的資料庫可用性。
- 請使用故障轉移群組狀態來判斷這兩個實例是否都已成功變更其角色,並準備好接受客戶端連線。