make-series 運算符
沿著指定的座標軸建立一系列指定的匯總值。
語法
T | make-series [MakeSeriesParameters] [數據行 =] 匯總 [ = default DefaultValue] [, ...] on AxisColumn [ start] [to from end] step [ [Column =] step GroupExpression [,by ...]]
深入瞭解 語法慣例。
參數
| 姓名 | 類型 | 必要 | 描述 |
|---|---|---|---|
| 資料行 | string |
結果數據行的名稱。 預設為衍生自表達式的名稱。 | |
| DefaultValue | 純量 | 要使用的預設值,而不是不存在的值。 如果沒有具有 AxisColumn 和 GroupExpression 特定值的數據列,則會將數位的對應專案指派為 DefaultValue。 預設值為 0。 | |
| 彙總 | string |
✔️ | 使用資料列名稱做為自變數的 聚合函數呼叫,例如 count() 或 avg()。 請參閱聚合函數清單。 只有傳回數值結果的 make-series 聚合函數可以搭配 運算符使用。 |
| AxisColumn | string |
✔️ | 將排序數列的數據行。 通常數據行值的類型為 datetime 或 timespan ,但接受所有數值類型。 |
| start | 純量 | ✔️ | 要建置之每個數列的 AxisColumn 低限值。 如果未 指定 start ,則會是每個數列中具有數據的第一個量化或步驟。 |
| end | 純量 | ✔️ | AxisColumn 的高系結非內含值。 時間序列的最後一個索引小於這個值,而且會開始加上小於結尾之步驟的整數倍數。 如果未 指定 end ,則會是每個數列有數據的最後一個量化或步驟的上限。 |
| 步 | 純量 | ✔️ | AxisColumn 陣列的兩個連續元素之間的差異或間隔大小。 如需可能的時間間隔清單,請參閱 時間範圍。 |
| GroupExpression | 提供一組相異值之數據行的表達式。 一般而言,它是已經提供一組限制值的數據行名稱。 | ||
| MakeSeriesParameters | 以名稱=值的形式控制行為之零個或多個空格分隔參數。 請參閱 支援的make series 參數。 |
注意
開始、結束和步驟參數可用來建置 AxisColumn 值的陣列。 陣列是由開始和結尾之間的值所組成,而步驟值代表一個陣列元素到下一個陣列元素之間的差異。 所有 匯總 值都會分別排序為此陣列。
支援的數列參數
| 名稱 | 描述 |
|---|---|
kind |
當make-series運算子的輸入是空的時,會產生默認結果。 值:nonempty |
hint.shufflekey=<key> |
查詢 shufflekey 會使用索引鍵來分割數據,在叢集節點上共用查詢負載。 請參閱 隨機查詢 |
注意
make-series 所產生的陣列僅限於1048576值(2^20)。 嘗試產生具有make-series的較大陣列會導致錯誤或截斷的陣列。
替代語法
T | make-series [數據行 = ] 匯總 [ =default DefaultValue] [, ...] on AxisColumnrange(in start, stop, step) [ [byColumn =] GroupExpression [, ...]]
從替代語法產生的數列,在兩個方面與主要語法不同:
- 停止值是內含的。
- 量化索引軸是以 bin() 產生,而不是bin_at(),這表示 開始 可能不會包含在產生的數列中。
建議使用make-series的主要語法,而不是替代語法。
傳回
輸入數據列會排列成具有相同表達式值和 AxisColumn,步驟,開始)表達式的by群組。bin_at( 然後會針對每個群組計算指定的聚合函數,為每個群組產生一個數據列。 結果包含數據 by 行、 AxisColumn 資料 行,以及每個計算匯總至少一個數據行。 (不支援對多個數據行或非數值結果的匯總。
這個中繼結果具有與 AxisColumn,步驟,開始)值相異組合bin_at(by的數據列數目。
最後,中繼結果中的數據列會排列成具有相同表達式值的 by 群組,而所有匯總值都會排列成陣列(類型的值 dynamic )。 針對每個匯總,有一個數據行包含具有相同名稱的陣列。 最後一個數據行是陣列,其中包含根據指定步驟量化的AxisColumn值。
注意
雖然您可以同時為匯總和群組表達式提供任意表達式,但使用簡單數據行名稱會更有效率。
聚合函數清單
| 函式 | 描述 |
|---|---|
| avg() | 傳回整個群組的平均值 |
| avgif() | 傳回具有群組述詞的平均值 |
| count() | 傳回群組的計數 |
| countif() | 傳回具有群組述詞的計數 |
| dcount() | 傳回群組元素的近似相異計數 |
| dcountif() | 傳回具有群組述詞的近似相異計數 |
| max() | 傳回整個群組的最大值 |
| maxif() | 傳回具有群組述詞的最大值 |
| min() | 傳回整個群組的最小值 |
| minif() | 傳回具有群組述詞的最小值 |
| percentile() | 傳回整個群組的百分位數值 |
| take_any() | 傳回群組的隨機非空白值 |
| stdev() | 傳回整個群組的標準偏差 |
| sum() | 傳回群組內專案的總和 |
| sumif() | 傳回具有群組述詞的專案總和 |
| 變異數() | 傳回整個群組的變異數 |
數列分析函式清單
| 函式 | 描述 |
|---|---|
| series_fir() | 套用 有限脈衝響應 篩選器 |
| series_iir() | 套用 無限脈衝響應 篩選 |
| series_fit_line() | 尋找直線,這是輸入的最佳近似值 |
| series_fit_line_dynamic() | 尋找最接近輸入的線條,並傳回動態物件 |
| series_fit_2lines() | 尋找兩行,這是輸入的最佳近似值 |
| series_fit_2lines_dynamic() | 尋找兩行是輸入的最佳近似值,並傳回動態物件 |
| series_outliers() | 評分數列中的異常點數 |
| series_periods_detect() | 尋找時間序列中存在的最重要期間 |
| series_periods_validate() | 檢查時間序列是否包含指定長度的定期模式 |
| series_stats_dynamic() | 傳回具有一般統計數據的多個數據行(min/max/variance/stdev/average) |
| series_stats() | 產生具有一般統計數據的動態值(min/max/variance/stdev/average) |
如需數列分析函式的完整清單,請參閱: 數列處理函式
數列插補函數清單
| 函式 | 描述 |
|---|---|
| series_fill_backward() | 在數列中執行遺漏值的回溯填入 |
| series_fill_const() | 以指定的常數值取代數列中的遺漏值 |
| series_fill_forward() | 執行數列中遺漏值的正向填滿插補點 |
| series_fill_linear() | 執行數列中遺漏值的線性插補 |
- 注意:插補函式預設會假設
null為遺漏值。 因此,如果您想要針對數列使用插補函數,請在 中make-series指定default=double(null)。
範例
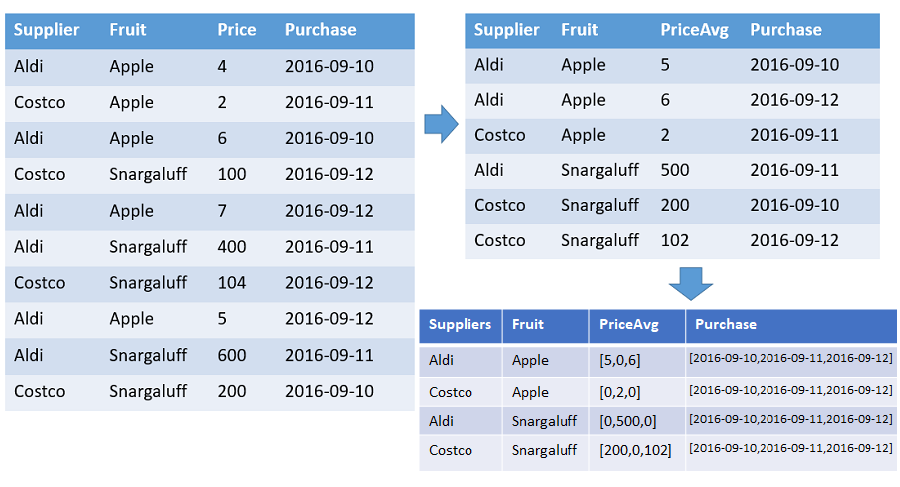
數據表,顯示每個供應商依指定範圍的時間戳排序之每個水果的數位和平均價格陣列。 每個不同水果和供應商組合的輸出中有一個數據列。 輸出數據行會顯示水果、供貨商和陣列:count、average 和整個時間軸(從 2016-01-01 到 2016-01-10)。 所有陣列都會依個別時間戳排序,而且所有間距都會填入預設值 (在此範例中為0)。 所有其他輸入數據行都會被忽略。
T | make-series PriceAvg=avg(Price) default=0
on Purchase from datetime(2016-09-10) to datetime(2016-09-13) step 1d by Supplier, Fruit
let data=datatable(timestamp:datetime, metric: real)
[
datetime(2016-12-31T06:00), 50,
datetime(2017-01-01), 4,
datetime(2017-01-02), 3,
datetime(2017-01-03), 4,
datetime(2017-01-03T03:00), 6,
datetime(2017-01-05), 8,
datetime(2017-01-05T13:40), 13,
datetime(2017-01-06), 4,
datetime(2017-01-07), 3,
datetime(2017-01-08), 8,
datetime(2017-01-08T21:00), 8,
datetime(2017-01-09), 2,
datetime(2017-01-09T12:00), 11,
datetime(2017-01-10T05:00), 5,
];
let interval = 1d;
let stime = datetime(2017-01-01);
let etime = datetime(2017-01-10);
data
| make-series avg(metric) on timestamp from stime to etime step interval
| avg_metric | timestamp |
|---|---|
| [ 4.0, 3.0, 5.0, 0.0, 10.5, 4.0, 3.0, 8.0, 6.5 ] | [ "2017-01-01T00:00:00.0000000Z", "2017-01-02T00:00:00.0000000Z", "2017-01-03T00:00:00.0000000Z", "2017-01-04T00:00:00.0000000Z", "2017-01-05T00:00:00.0000000Z", "2017-01-06T00:00:00.0000000Z", "2017-01-07T00:00:00.0000000Z", "2017-01-08T00:00:00.0000000Z", "2017-01-09T00:00:00.0000000Z" ] |
當 的輸入 make-series 是空的時,的預設行為 make-series 會產生空的結果。
let data=datatable(timestamp:datetime, metric: real)
[
datetime(2016-12-31T06:00), 50,
datetime(2017-01-01), 4,
datetime(2017-01-02), 3,
datetime(2017-01-03), 4,
datetime(2017-01-03T03:00), 6,
datetime(2017-01-05), 8,
datetime(2017-01-05T13:40), 13,
datetime(2017-01-06), 4,
datetime(2017-01-07), 3,
datetime(2017-01-08), 8,
datetime(2017-01-08T21:00), 8,
datetime(2017-01-09), 2,
datetime(2017-01-09T12:00), 11,
datetime(2017-01-10T05:00), 5,
];
let interval = 1d;
let stime = datetime(2017-01-01);
let etime = datetime(2017-01-10);
data
| take 0
| make-series avg(metric) default=1.0 on timestamp from stime to etime step interval
| count
輸出
| 計數 |
|---|
| 0 |
使用 kind=nonempty in make-series 會產生預設值的非空白結果:
let data=datatable(timestamp:datetime, metric: real)
[
datetime(2016-12-31T06:00), 50,
datetime(2017-01-01), 4,
datetime(2017-01-02), 3,
datetime(2017-01-03), 4,
datetime(2017-01-03T03:00), 6,
datetime(2017-01-05), 8,
datetime(2017-01-05T13:40), 13,
datetime(2017-01-06), 4,
datetime(2017-01-07), 3,
datetime(2017-01-08), 8,
datetime(2017-01-08T21:00), 8,
datetime(2017-01-09), 2,
datetime(2017-01-09T12:00), 11,
datetime(2017-01-10T05:00), 5,
];
let interval = 1d;
let stime = datetime(2017-01-01);
let etime = datetime(2017-01-10);
data
| take 0
| make-series kind=nonempty avg(metric) default=1.0 on timestamp from stime to etime step interval
輸出
| avg_metric | timestamp |
|---|---|
| [ 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0 ] |
[ “2017-01-01T00:00:00.0000000Z”, “2017-01-02T00:00:00.0000000Z”, “2017-01-03T00:00:00.0000000Z”, “2017-01-04T00:00:00.0000000Z”, “2017-01-05T00:00:00.0000000Z”, “2017-01-06T00:00:00.0000000Z”, “2017-01-07T00:00:00.0000000Z”, “2017-01-08T00:00:00.0000000Z”, “2017-01-09T00:00:00.0000000Z” ] |
意見反應
即將登場:在 2024 年,我們將逐步淘汰 GitHub 問題作為內容的意見反應機制,並將它取代為新的意見反應系統。 如需詳細資訊,請參閱:https://aka.ms/ContentUserFeedback。
提交並檢視相關的意見反應