資料流程寫入至接收器時,任何自訂資料分割都會在寫入之前立即發生。 如同來源,在大部分情況下,建議您保留 [使用目前的分割] 作為選取的分割選項。 分割資料的寫入速度會比未分割資料還要快,即使未分割目的地也是一般。 以下是各種接收器類型的個別考量。
Azure SQL Database 接收
使用 Azure SQL Database 時,預設分割在大部分情況下應都能運作。 接收器可能會有太多分割區,而 SQL 資料庫無法處理。 如果您發生這種情況,則請減少 SQL Database 接收器所輸出的分割區數目。
根據來源中遺漏的資料列刪除接收中資料列的最佳做法
以下影片逐步解說如何使用資料流程搭配存在、改變資料列和接收器轉換,以達成此常見模式:
錯誤資料列處理對效能的影響
當您在接收轉換中啟用錯誤資料列處理 (「繼續發生錯誤」) 時,服務會在將相容資料列寫入目的地資料表之前採取額外的步驟。 這個額外步驟會有一個較小的效能懲罰 (對於此步驟而言,可能會新增 5% 的範圍),如果您將選項設定為同時將不相容的資料列寫入記錄檔,還會新增額外較小的效能打擊。
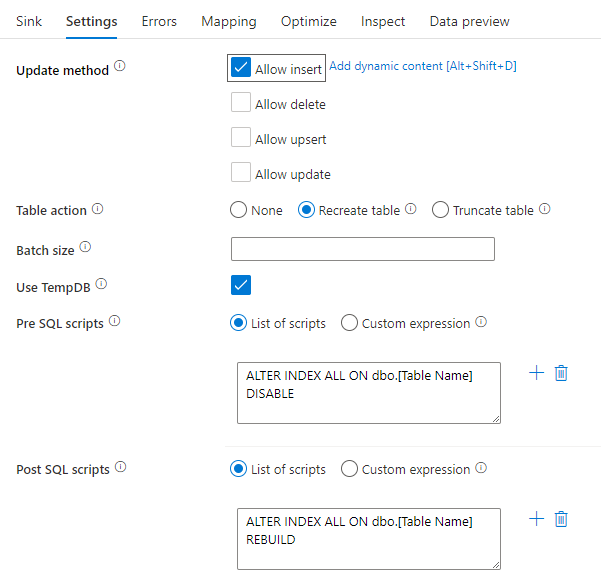
使用 SQL 指令碼停用索引
在 SQL 資料庫中載入之前停用索引,可以大幅改善資料表的寫入效能。 在寫入 SQL 接收之前,請先執行下列命令。
ALTER INDEX ALL ON dbo.[Table Name] DISABLE
寫入完成後,請使用下列命令重建索引:
ALTER INDEX ALL ON dbo.[Table Name] REBUILD
這兩者都可以在對應資料流程中使用 Azure SQL Database 或 Synapse 接收器內的預先和後置 SQL 指令碼,以原生方式完成。
警告
停用索引時,資料流程會有效地控制資料庫,而且查詢目前不太可能成功。 因此,許多 ETL 作業會在午夜觸發,以避免發生此衝突。 如需詳細資訊,請參閱停用 SQL 索引的限制式
相應增加資料庫
在您的管線執行之前,您可以為來源及接收 Azure SQL DB 和 DW 排定調整大小作業來增加輸送量,並在達到 DTU 限制時將 Azure 節流降至最低。 當您的管線執行完成之後,請將您的資料庫大小調整回正常執行比率。
Azure Synapse Analytics 接收
寫入至 Azure Synapse Analytics 時,請確定 [啟用暫存] 設定為 true。 這可讓服務使用 SQL COPY 命令來寫入,以有效地大量載入資料。 在使用暫存時,您將需要參考 Azure Data Lake Storage gen2 或 Azure Blob 儲存體帳戶來暫存資料。
除了暫存以外,相同的最佳做法與 Azure SQL Database 一樣適用於 Azure Synapse。
檔案型接收
雖然資料流程支援各種檔案類型,但建議使用 Spark 原生 Parquet 格式,以獲得最佳讀取和寫入時間。
如果資料平均分散,則 [使用目前的分割] 會是寫入檔案的最快速分割選項。
檔案名稱選項
寫入檔案時,您可以選擇命名選項,而每個選項都會影響效能。
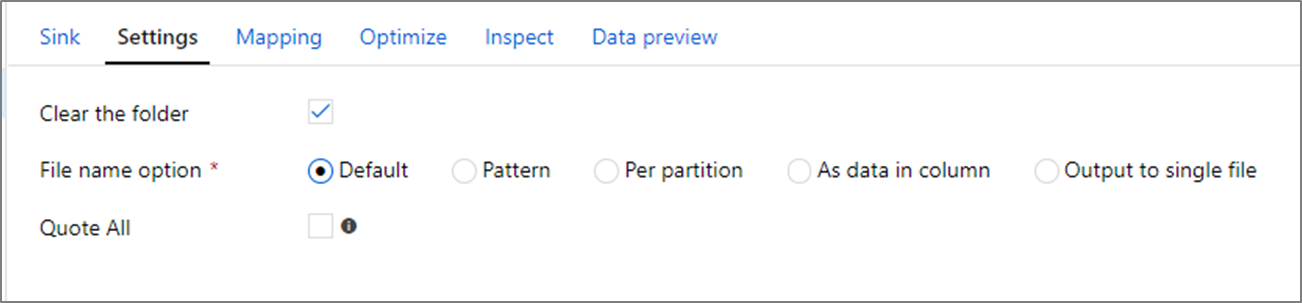
選取 [預設] 選項時的寫入速度最快。 每個分割區都會與具有 Spark 預設名稱的檔案相等。 如果您只是從資料的資料夾讀取,則這會很有用。
設定命名「模式」會將每個分割區檔案重新命名為更方便使用者使用的名稱。 此作業會在寫入之後發生,且比選擇預設值稍微慢一點。
每個分割可讓您手動命名每個個別的分割。
如果資料行對應至您想要輸出資料的方式,您可以選取 [將檔案命名為資料行資料]。 這會重排資料,如果資料行未平均分散,則可能會影響效能。
如果資料行對應至您想要產生資料夾名稱的方式,請選取 [將資料夾命名為資料行資料]。
輸出至單一檔案會將所有資料合併成單一分割。 這會導致較長的寫入時間,特別是大型資料集。 除非有明確的商務使用原因,否則不建議使用此選項。
Azure Cosmos DB 接受
當您寫入至 Azure Cosmos DB 時,改變資料流程執行期間的輸送量和批次大小可以改善效能。 這些變更只會在資料流程活動執行期間生效,並在結論之後返回原始收集組。
批次大小:通常,從預設批次大小開始就已足夠。 若要進一步調整此值,請計算資料的粗略物件大小,並確定物件大小 * 批次大小小於 2MB。 如果如此,請增加批次大小以取得更高的輸送量。
輸送量:請在這裡設定較高的輸送量設定,以允許文件更快速地寫入 Azure Cosmos DB。 請記住,高輸送量設定會產生較高的 RU 成本。
寫入輸送量預算:使用小於每分鐘 RU 總計的值。 如果您的資料流程具有大量的 Spark 分割區,則設定預算輸送量會允許在這些分割區之間達到更好的平衡。
相關內容
請參閱其他與效能相關的資料流程文章: